Binary features
v = metadata[(metadata.type == 'binary') & (metadata.preserve)].index
trainset[v].describe() target ps_ind_06_bin ps_ind_07_bin ps_ind_08_bin ps_ind_09_bin ps_ind_10_bin ps_ind_11_bin ps_ind_12_bin ps_ind_13_bin ps_ind_16_bin ps_ind_17_bin ps_ind_18_bin ps_calc_15_bin ps_calc_16_bin ps_calc_17_bin ps_calc_18_bin ps_calc_19_bin ps_calc_20_bin
count 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000 595212.000000
mean 0.036448 0.393742 0.257033 0.163921 0.185304 0.000373 0.001692 0.009439 0.000948 0.660823 0.121081 0.153446 0.122427 0.627840 0.554182 0.287182 0.349024 0.153318
std 0.187401 0.488579 0.436998 0.370205 0.388544 0.019309 0.041097 0.096693 0.030768 0.473430 0.326222 0.360417 0.327779 0.483381 0.497056 0.452447 0.476662 0.360295
min 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
25% 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
50% 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000 0.000000 0.000000 0.000000 1.000000 1.000000 0.000000 0.000000 0.000000
75% 0.000000 1.000000 1.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000 0.000000 0.000000 0.000000 1.000000 1.000000 1.000000 1.000000 0.000000
max 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000bin_col = [col for col in trainset.columns if '_bin' in col]
zero_list = []
one_list = []
for col in bin_col:
zero_list.append((trainset[col]==0).sum()/trainset.shape[0]*100)
one_list.append((trainset[col]==1).sum()/trainset.shape[0]*100)
plt.figure()
fig,ax = plt.subplots(figsize=(6,6))
#Bar plot
p1 = sns.barplot(ax=ax, x=bin_col, y=zero_list, color="blue")
p2 = sns.barplot(ax=ax, x=bin_col, y=one_list, bottom =zero_list, color="red")
plt.ylabel("Percent of zero/one [%]", fontsize=12)
plt.xlabel("Binary features", fontsize=12)
locs, labels = plt.xticks()
plt.setp(labels, rotation=90)
plt.tick_params(axis='both', which='major', labelsize=12)
plt.legend((p1,p2), ('Zero', 'One'))
plt.show();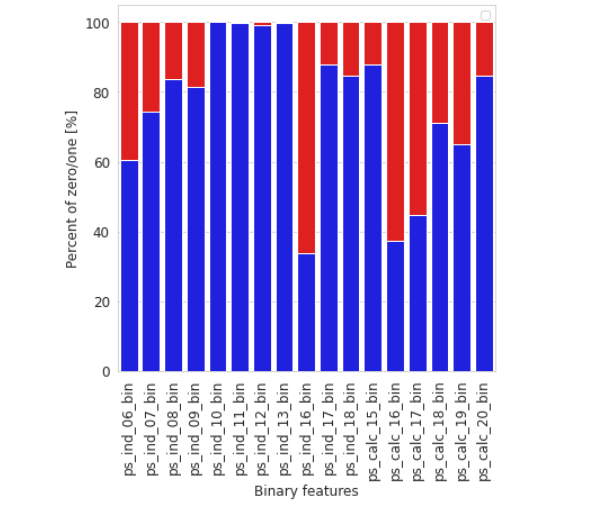
var = metadata[(metadata.type =='binary') & (metadata.preserve)].index
var = [col for col in trainset.columns if '_bin' in col]
i = 0
t1 = trainset.loc[trainset['target'] != 0]
t0 = trainset.loc[trainset['target'] == 0]
sns.set_style('whitegrid')
plt.figure()
fig, ax = plt.subplots(6,3, figsize=(12,24))
for feature in var:
i += 1
plt.subplot(6,3,i)
sns.kdeplot(t1[feature], bw=0.5, label='target = 1')
sns.kdeplot(t0[feature], bw=0.5, label='target = 0')
plt.ylabel('Density plot', fontsize=12)
plt.xlabel(feature, fontsize=12)
locs, labels = plt.xticks()
plt.tick_params(axis='both', which='major', labelsize=12)
plt.show()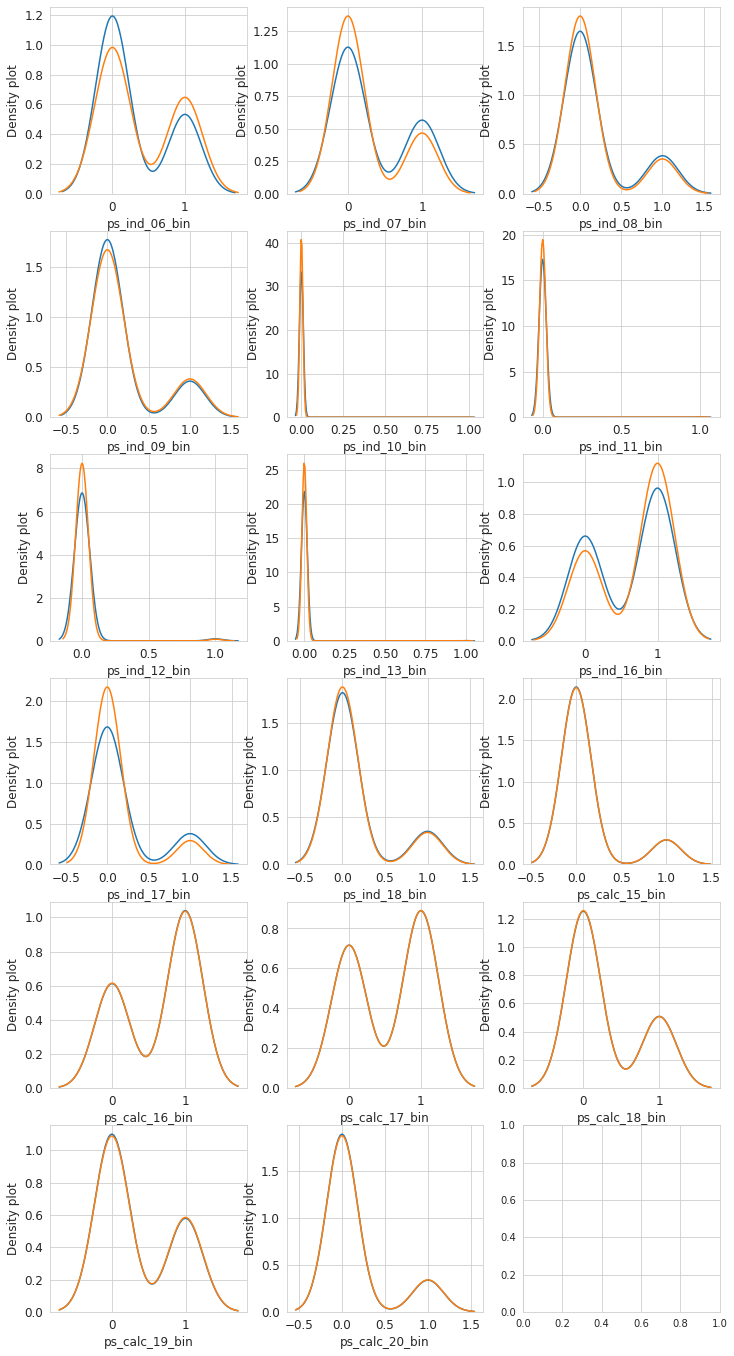
Categorical features
var = metadata[(metadata.type == 'categorical') & (metadata.preserve)].index
for feature in var:
fig, ax = plt.subplots(figsize=(6,6))
# Calculate the percentage of target=1 per category value
cat_perc = trainset[[feature, 'target']].groupby([feature],as_index=False).mean()
cat_perc.sort_values(by='target', ascending=False, inplace=True)
# Bar plot
# Order the bars descending on target mean
sns.barplot(ax=ax,x=feature, y='target', data=cat_perc, order=cat_perc[feature])
plt.ylabel('Percent of target with value 1 [%]', fontsize=12)
plt.xlabel(feature, fontsize=12)
plt.tick_params(axis='both', which='major', labelsize=12)
plt.show();
var = metadata[(metadata.type == 'categorical') & (metadata.preserve)].index
i = 0
t1 = trainset.loc[trainset['target'] != 0]
t0 = trainset.loc[trainset['target'] == 0]
sns.set_style('whitegrid')
plt.figure()
fig, ax = plt.subplots(4,4,figsize=(16,16))
for feature in var:
i += 1
plt.subplot(4,4,i)
sns.kdeplot(t1[feature], bw=0.5,label="target = 1")
sns.kdeplot(t0[feature], bw=0.5,label="target = 0")
plt.ylabel('Density plot', fontsize=12)
plt.xlabel(feature, fontsize=12)
locs, labels = plt.xticks()
plt.tick_params(axis='both', which='major', labelsize=12)
plt.show();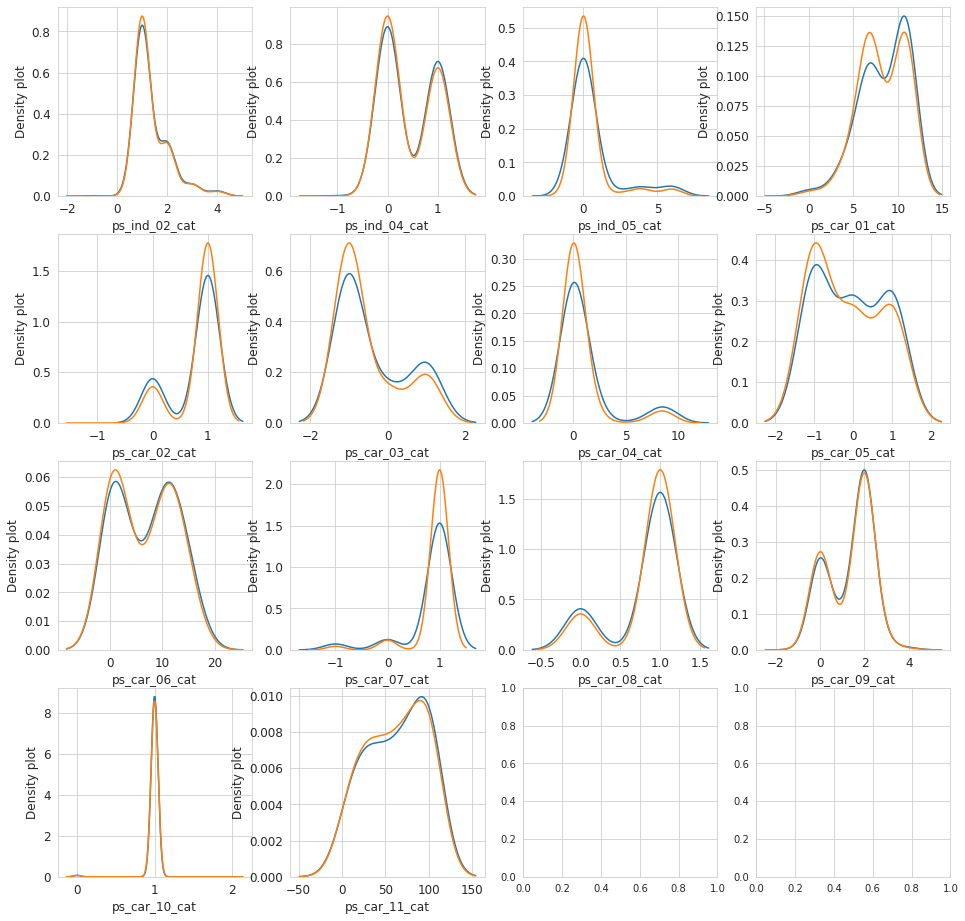
Data unbalance between train and test data
var = metadata[(metadata.category == 'registration') & (metadata.preserve)].index
#Bar plot
sns.set_style('whitegrid')
plt.figure()
fig, ax = plt.subplots(1,3,figsize=(12,4))
i = 0
for feature in var:
i = i + 1
plt.subplot(1,3,i)
sns.kdeplot(trainset[feature], bw=0.5, label="train")
sns.kdeplot(testset[feature], bw=0.5, label='test')
plt.ylabel('Distribution', fontsize=12)
plt.xlabel(feature, fontsize=12)
locs, labels = plt.xticks()
plt.tick_params(axis='both', which='major', labelsize=12)
plt.show();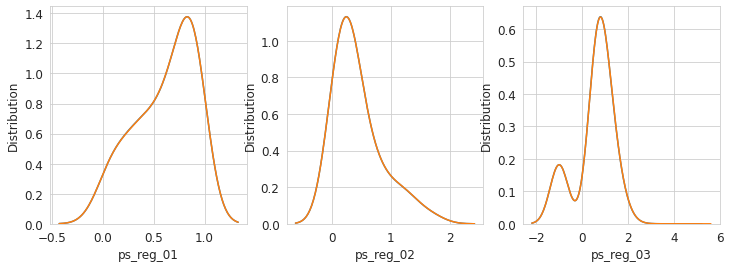
var = metadata[(metadata.category =='car') & (metadata.preserve)].index
#Bar plot
sns.set_style('whitegrid')
plt.figure()
fig, ax = plt.subplots(4,4,figsize=(20,16))
i = 0
for feature in var:
i = i + 1
plt.subplot(4,4,i)
sns.kdeplot(trainset[feature], bw=0.5, label='train')
sns.kdeplot(testset[feature], bw=0.5, label='test')
plt.ylabel('Distribution', fontsize=12)
plt.xlabel(feature, fontsize=12)
locs, labels = plt.xticks()
#plt.setp(labels, rotation=90)
plt.tick_params(axis='both', which='major', labelsize=12)
plt.show();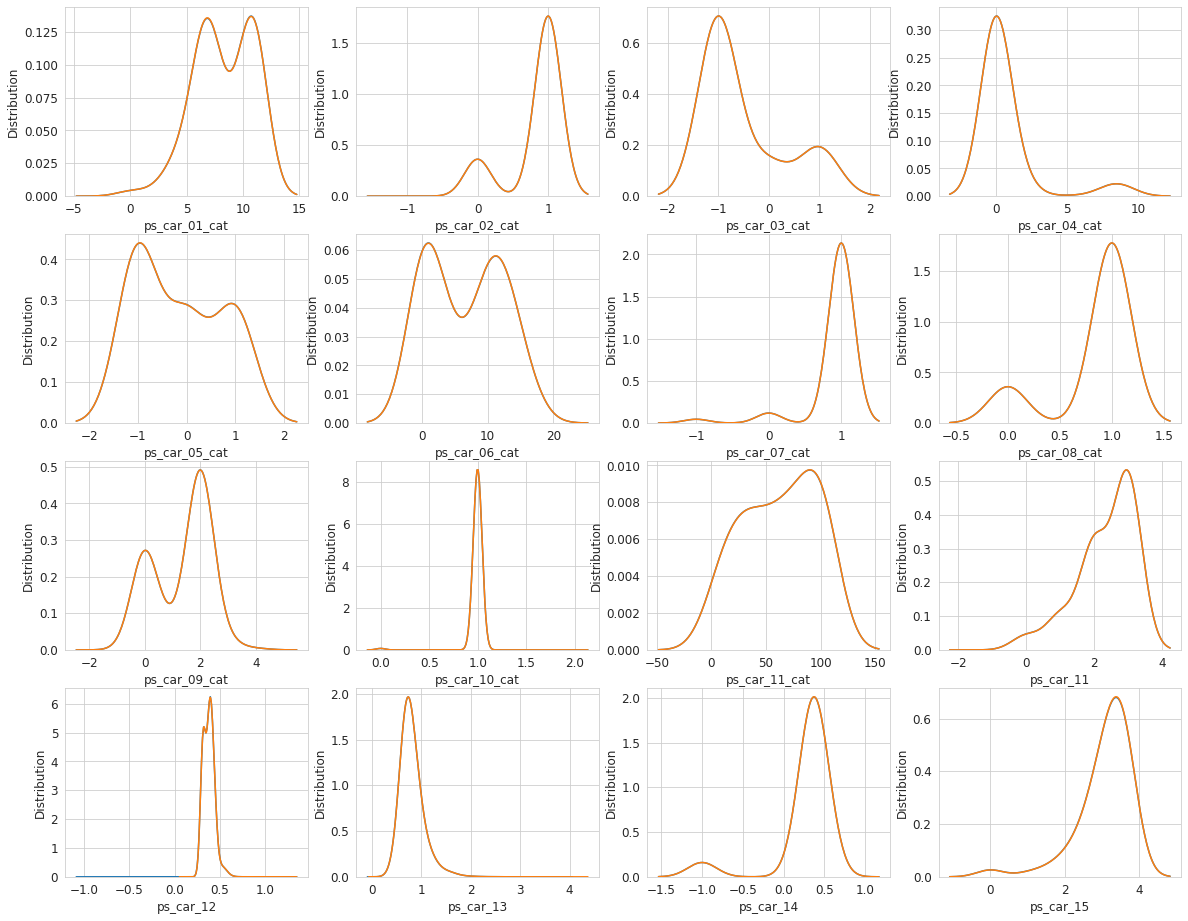
var = metadata[(metadata.category == 'individual') & (metadata.preserve)].index
# Bar plot
sns.set_style('whitegrid')
plt.figure()
fig, ax = plt.subplots(5,4,figsize=(20,16))
i = 0
for feature in var:
i = i + 1
plt.subplot(5,4,i)
sns.kdeplot(trainset[feature], bw=0.5, label="train")
sns.kdeplot(testset[feature], bw=0.5, label="test")
plt.ylabel('Distribution', fontsize=12)
plt.xlabel(feature, fontsize=12)
locs, labels = plt.xticks()
#plt.setp(labels, rotation=90)
plt.tick_params(axis='both', which='major', labelsize=12)
plt.show();
var = metadata[(metadata.category == 'calculated') & (metadata.preserve)].index
# Bar plot
sns.set_style('whitegrid')
plt.figure()
fig, ax = plt.subplots(5,4,figsize=(20,16))
i = 0
for feature in var:
i = i + 1
plt.subplot(5,4,i)
sns.kdeplot(trainset[feature], bw=0.5, label="train")
sns.kdeplot(testset[feature], bw=0.5, label="test")
plt.ylabel('Distribution', fontsize=12)
plt.xlabel(feature, fontsize=12)
locs, labels = plt.xticks()
#plt.setp(labels, rotation=90)
plt.tick_params(axis='both', which='major', labelsize=12)
plt.show();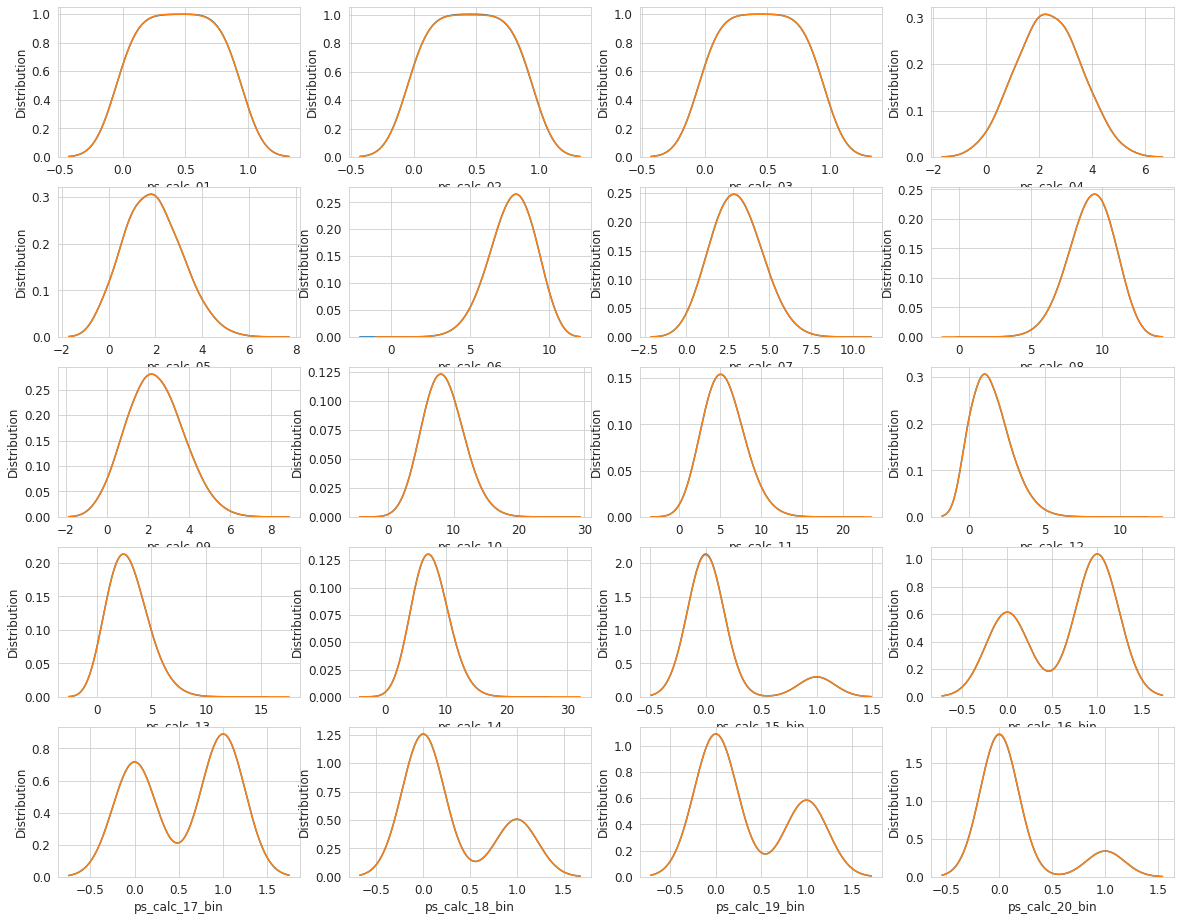

성장을 도울 아카이빙 블로그