Survived 파악
- 생존자의 현황 파악
train['Survived'].value_counts()
0 549 # 사망
1 342 # 생존
Name: Survived. dtype: int64missingno 사용 보기
- 최초로 데이터 전체를 시각화
missingno.matrix(data, figsize = (15,8))
data.isnull().sum() #비어 있는 값들을 체크해 본다.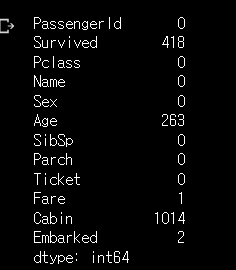
항목의 종류 파악
항목의 종류
- 범주형 항목 (Categorical Features)
범주형 항목은 법주형 변수로 된 항목으로 범주형 변수는 둘 이상의 결과 요소가 있는 변수이며 해당 기능의 각 값을 범주별로 분류 할 수 있습니다.
예를 들어 성별은 두 가지 범주 (남성과 여성)의 범주 형 변수입니다.
이산형 변수(discrete variable) = 범주형 변수 (categorical variable) 의 하나로 명목 변수 norminal variable 라고도합니다.
데이터 셋에서 명목 항목 : Sex, Embark 이며 우리는 Name, Ticket 등을 이로 변환해야 할 것 같습니다.
- Ordinal Variable :
순위 변수는 범주 형의 하나지만 그 차이점은 값 사이의 상대 순서(=서열) 또는 정렬이 가능하다는 것입니다.
데이터 셋에서 순위 항목 : PClass 이며 우리는 Cabin을 이 범주로 변환해서 사용해야 할 것 같습니다.
- 연속형 항목 (Continuous Features):
서로 연속된 값을 가진 변수를 가진 항목이며 여기에서 우리는 연령을 대표적인 것으로 볼 수 있습니다.
Age, SipSp, Parch, Fare는 interval variable로 만들어 이에 적용해야 할 것 같습니다.
- 항목이 범주형인지 연속형인지 등을 파악
-
아래의 항목에서 열의 이름을 볼 수 있습니다.
Variable 정의 Key survival 생존 여부 0 = No, 1 = Yes pclass 선실 등급 1 = 1st, 2 = 2nd, 3 = 3rd sex 성별 Age 나이 sibsp 형재 자매의 수/ 배우자 등이 승선한 경우 수 parch 부모나 자식과 같이 탄 경우 수 ticket 표 번호 fare 요금 cabin 선실 번호 embarked 승선한 항구 C = Cherbourg, Q = Queenstown, S = Southampton
항목 상관관계 보기
- 히트맵으로 각 항목의 상관관계 보기
# Co-relation 매트릭스
corr = data.corr()
# 마스크 셋업
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# 그래프 셋업
plt.figure(figsize=(14, 8))
# 그래프 타이틀
plt.title('Overall Correlation of Titanic Features', fontsize=18)
# Co-relation 매트릭스 런칭
sns.heatmap(corr, mask=mask, annot=False,cmap='RdYlGn', linewidths=0.2, annot_kws={'size':20})
plt.show()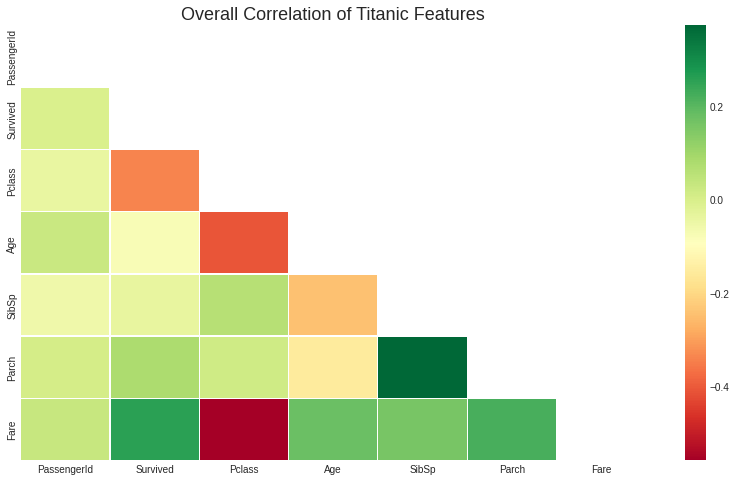

성장을 도울 아카이빙 블로그