Double_linked_list

단일 연결 리스트와 달리 head와 tail를 가지고 각 노드는 앞 과 뒤 노드의 정보를 가지고 있기에 양쪽으로 접근이 가능합니다. 그래서 양방향 연결 리스트라고 불리게 되었습니다.
활용
*삽입
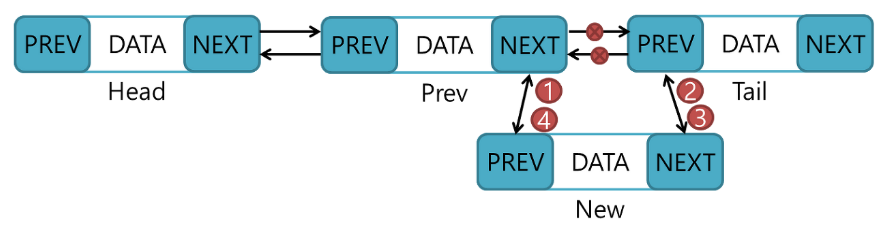
삽입할 노드(new_node)의 prev는 이전 노드를 가리킵니다.
삽입할 노드의 다음은 삽입할 노드의 뒤 노드를 가리킵니다.
뒤의 노드 prev가 삽입할 노드를 가리키고 앞 노드의 next 또한 삽입 노드를 가리킵니다.
양방향 연길 리시트는 오른차순으로 구성되는 것을 베이스로 깝니다.
특정 노드를 기준으로 데이터를 삽입하는 것 또한 순서는 동일합니다.
*삭제
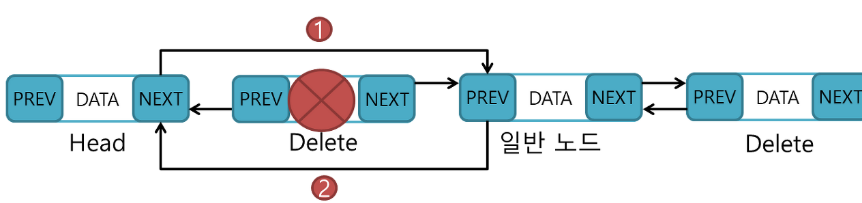
첫 노드를 제거한다고 생각을 해야합니다(헤드 삭제X)
헤드의 NEXT가 삭제할 노드의 뒷 노드를 가리키고 뒷 노드의 prev는 헤드를 가리킵니다.
삭제할 노드 메모리 해제
특정 노드 삭제
삭제할 노드가 유일한 노드인 경우
삭제할 노드가 Head인 경우
삭제할 노드가 Tail인 경우
삭제할 노드가 일반 노드인 경우
CODE
#Node를 클래스 작성하면 편리합니다.
#왜냐하면, 초기화나 할당을 계속 안해도 됩니다. 이것이 상속과 클래스의 장점이죠
#이번 실습에서 중요한 것은 양방향 연결 리스트에서 previous와 next가 어떻게 연결이 되는가 입니다.
#모든 값의 시작은 초기화입니다. 그래야 저희가 원하는 값을 넣기 편하거든요
class Node: #파이썬답게 class 이름을 명시적으로 node로 지정
def __init__(self, data, prev_=None, next_=None): #prev_ and next_를 초기화를 시킵니다.
self.data = data #할당
self.prev = prev_ # 할당
self.next = next_ #힐딩
#클래스로 DoubleLinkedList 구현 코드 짜기
class DoubleLinkedList:
def __init__(self):
self.head = Node(None) #head는 더미노드이기에 초기화를 시킵니다. *더미노드: Node가 없는 것
self.tail = Node(None) #tail는 더미노드이기에 초기화를 시킵니다.
self._size = 0# size도 시작이면 0이겠죠?
self.head.next = self.tail #head의 next는 tail입니다. 연결리스트 구조를 보시면 헤드 - 테일이 기본 구조입니다. 여기서 점점 길어지긴 하지만요
self.tail.prev = self.head #tail의 previous는 head입니다.
def size(self): #size(길이)에 관련한 함수입니다.
return self._size # 0을 반환합니다.
def add(self, data): # Node가 추가되는 함수
last = self.tail.prev # last는 head
new_node = Node(data, last, self.tail) #새롭게 들어올 노드가 들어올 수 있도록 초기화
last.next = new_node# head 다음에 node가 추가됩니다
self.tail.prev = new_node # 구조의 변화: 헤드 - new_node - 테일로 바뀌었습니다. node가 추가되었기 때문이지요
self._size += 1 # 새로운 node가 들어오고 구조의 길이도 늘었으니 사이즈를 증가해야겠죠?! 그것을 의미합니다.
def insert(self, index, data): # 원하는 인덱스 위치에 값을 넣는 insert 구현 함수
if index > self._size or index < 0: #index의 위치가 사이즈보다 크거나 0보다 작을 경우
raise RuntimeError("Index out of error") # 인덱스가 범위를 넘었다는 에러 호출
prev, current = None, None #초기화
i = 0 # 초기화
if index < self._size // 2: #index가 전체 사이즈의 절반보다 작다면(절반으로 지정한 이유는 양방향으로 숫자 삽입이 가능하기 때문이다)
prev = self.head # 더미노드(head)
current = self.head.next # tail부터 숫자 넣기
while i < index: # i가 index보다 클 때까지 돌린다
prev = prev.next # prev다음으로 이동
current = current.next # current다음으로 이동
i +=1 #1 증가
else: #index >= self._size //2
current = self.tail # current의 노드엔 아무것도 없다
prev = self.tail.prev # prev의 노드엔 아무것도 없다
while i < (self._size - index): #i가 >= (self._size - index)가 될 때까지 돌려짐
current = current.prev #current는 이전 걸로 이동
prev = prev.prev #이전의 이전걸로 이동
i += 1 #1 증가
new_node = Node(data,prev, current) # 새로운 노드가 class None 할당
current.prev = new_node # current에 새로운 노드 할당
prev.next = new_node # previous에 새로운 노드 할당
self._size += 1 # size 증가
def clear(self): #clear함수:다 지워버린다.
self._size = 0 # size를 0으로 초기화
self.head.next = self.tail # size가 초기화 되었으므로 head의 다음은 tail
self.head.prev = None # preivous는 아무것도 없다
self.head.next = None # head의 다음도 없다
self.tail.prev = self.head #tail의 이전은 head다
def delete(self, data): #data를 삭제하는 함수
prev = self.head #현재 previous는 헤드이다 왜냐하면 기본 구조인 head-tail이기 때문입니ㅏㄷ.
current = prev.next # current는 Previous의 다음. head - previous - current - tail
while current is not None: #current가 None이 되면 멈춘다.
if current.data == data: # 만약 현재의 data가 data라면
prev.next = current.next #previous는 current의 다음인 next에 할당
current.next.prev = prev # next의 이전은 current가 아닌 previous
current.next = None #next = None
current.prev = None # previous =None
self._size -= 1 # current가 사라졌으므로 사이즈 감소
return True # 이것이 잘 수행되었다면 true
#이 부분이 previous가 current의 삭제로 next로 연결 되었을 때 생기는 변화
prev = prev.next # prev는 current
current = current.next #current 는 previous가 되는
return False # 위의 것들이 수행이 안되면 False출력
def delete_by_index(self, index):#index를 사용하여 값 삭제
if index >= self._size or index < 0: #index가 size보다 이상이거나 0보다 작다면
raise RuntimeError("Index out of error") # 인덱스가 범위를 벗어났다는 에러 호출
prev_, current_, next_ = None, None, None # 싹 다 초기화!! 하는 이유는 여러 구현 시도를 하려면 비어 있는 상태가 편합니다.
# 우리가 짐을 쌓기 전에 상자에 불필요한 물건이 없는지 확인 후에 담는 것처럼요
i = 0 # 초기화
if index < self._size // 2: #인덱스가 사이즈의 절반보다 작다면?
prev_ = self.head #prev_의 node 초기화
current_ = self.head.next # node 초기화(헤드 다음 노드 없다)
while i < index: # i가 인덱스보다 이상일 때까지 실행
prev_ = prev_.next #prev는 current가 된다
current_ = current_.next #current는 next가 된다
i += 1 # i 증가 , 하나씩 밀리기 때문
prev_.next = current_.next # next가 동일해짐: head - prev -(current) - next- tail구조
current_.next.prev = prev_ # head - prev -(current) - next- tail구조 이런 구조화
current_.next = None #초기화
current_.prev = None#초기화
else: # 인덱스가 사이즈의 절반보다 이상
current_ = self.tail.prev # 구조: head- prev - current - (next) - tail
next_ = self.tail # 구조: head- prev - current - (next) - tail
while i < (self._size - index -1): # i >= (self._size - index -1)될 떄까지 실행
next_ = next_.prev # next가 사라지니 이전인 current에 적용
current_ = current_.prev # current가 사라지니 이전인 previous적용
next_.prev = current_.prev # next_ = current_
current_.prev.next = next_ # 뒤로 갔다 앞으로 가는 느낌
current_.next = None #초가화
current_.prev = None #초가화
self._size -= 1 #next가 줄었기에 사이즈 감소
return True #이것이 실행되면 true출력
def get(self, index): #index가 인자인 get 힘수
if index >= self._size or index < 0: # index가 사이즈보다 크거나 0보다 작다면
raise RuntimeError("Index out of error") # 인덱스 범위 에러 호출
i = 0 #i=0으로 초기화
current = None # current도 초기화
if index < self.size //2: # index가 절반보다 이상이라면
current = self.head.next # current는 head의 다음
while i < index: # i가 인덱스보다 작다면
current = current.next #current는 next
i += 1# i는 1 증가
else: #index절반 미만이라면
current = self.head.prev # current가 head전
while i < (self._size - index -1):
current = current.prev # current는 preivious
i += 1 # i는 1 증가
return current.data
def index_of(self, data): #index 증감 함수
current = self.head.next #current가 head의 다음
index = 0 #index=0으로 초기화
while current != None: # cuurent가 None이 될 때까지 순환
if current.data != None and current.data == data: ##current가 none가 아니고 데이터가 있다면
return index #index 출력
current = current.next #current가 next라면
index += 1 #인덱스의 위치가 1 증가
return -1 # -1 반환
def is_empty(self): #비어있을 경우 함수
return self.head.next == self.tail #head 다음이 tail
def contains(self, data): #data포함이 되었을 때 함수
current = self.head.next #head다음이 current인 구조 head- current - tail
while current != None: # current가 None일 때까지 구햔
if current.data != None and current.data == data: #current가 none가 아니고 데이터가 있다면
return True # true출력
current = current.next #current가 next라먄
return False #false 출력
#직접 코드를 구현한 DoubleLinkedList에 실제 값을 넣어서 실행시키기
if __name__ == "__main__": #이 파일의 이름이 main.py일 것이기에 터미널 실행을 위한 것입니다.
l = DoubleLinkedList() # DoubleLinkedList()을 매번 치긴 너무 기니 하나의 문자 l(ist)로 축약
for elem in [3,2,4,1,4]: # [3,2,4,1,4]들이 elem에 하나씩 들어가서 출력 add 함수 구현
print(f'l.add({elem})')
l.add(elem)
print(f"l.size(): {l.size()}") #총 size출력, size함수 구현
print("======================") # 줄바꿈
for elem in [3,2,4,1,4,100]: #[3,2,4,1,4,100]에서 하나씩 호출
print(f"l.contains({elem}): {l.contains(elem)}") #contains함수 구현
print(f"l.index_of({elem}): {l.index_of(elem)}") #idex_of 함수 구현
print("=======================") #줄 바꿈
for elem in [4,5,100]: # [4,5,100]에서 하나씩 출력
print(f"l.delete({elem}): {l.delete(elem)}") #delete 함수 구현
print(f"l.size(): {l.delete(elem)}") #delete가 잘 되는지 확인
print(f"l.size(): {l.size()}") # 사이즈 확인
print(f"l.insert(0, 100) ") #어느 위치에 insert할지 명시
l.insert(0, 100)
print(f"l.insert(2,101) :") # 어느 위치에 insert할지 명시
l.insert(2,101)
#insert적용하여 숫자를 tail부터 넣음
for elem in [3,2,4,5,1,4,100,101]: # insert해야 하는 거 추가 후 일일이 빼기
print(f"l.contains({elem}): {l.contains(elem)}") # 구현 결과 contains함수 구현
print(f"l.index_of({elem}): {l.index_of(elem)}") # index_of 함수 구현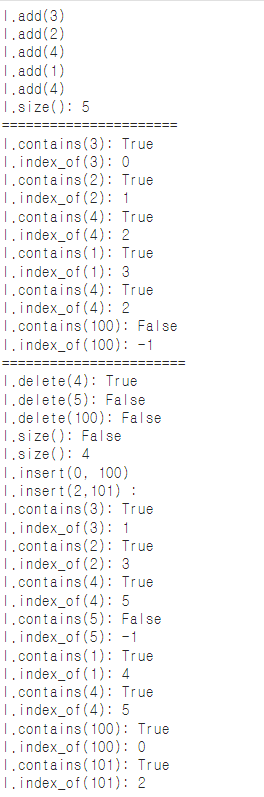

성장을 도울 아카이빙 블로그