학습목표
경사하강법(Gradient descent)에 대해 더 자세히 알아본다.
핵심키워드
가설 함수(Hypothesis Function)
평균 제곱 오차(Mean Squared Error)
경사하강법(Gradient descent)
최고의 모델
-
H(x) = x
-
W =1이 가장 좋은 숫자

! pip install torchvision
import numpy as np
import torch
# Dummy data : Input = Output
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])
#Simpler Hypothesis Function
W = torch.zeros(1, requires_grad = True)
# b = torch.zeros(1, requires_grad = True)
hypothesis = x_train * W
print(hypothesis)
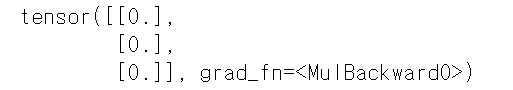
Cost function: Intuition
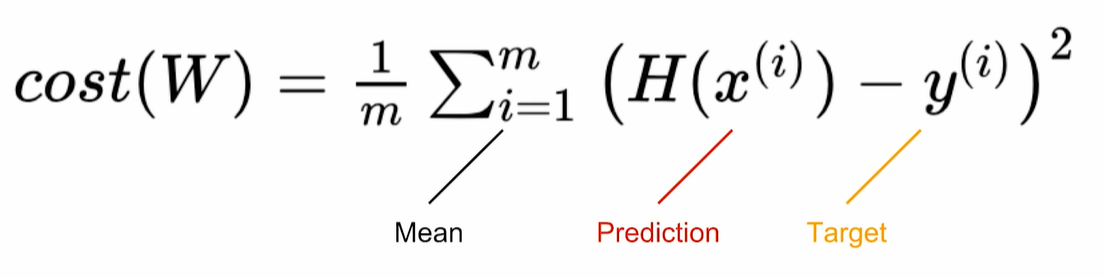
위의 함수를 통해서 모델 예측값이 실제 데이터와 얼마나 다른지 나타낼 수 있게 성능 점검이 가능합니다.
-
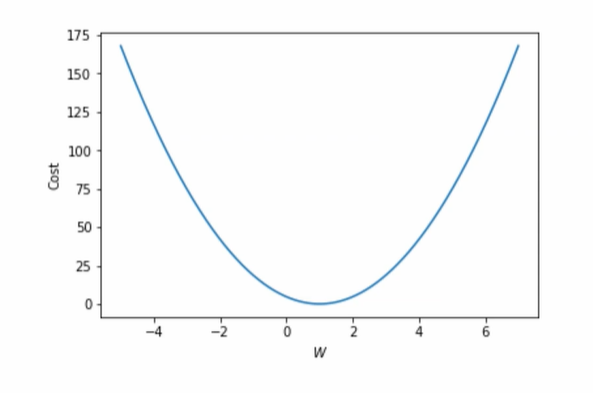
W = 1, cost = 0
-
1에서 멀어질수록 높아진다.
-
cost가 낮을수록 학습이 잘된 것이다
Cost function: MSE
cost = torch.mean((hypothesis - y_train) ** 2)
print(cost)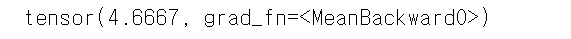
Gradient Descent: Intuition
-
곡선으로 내려가기
-
기울기가 크면 더 멀리
-
Gradient 계산

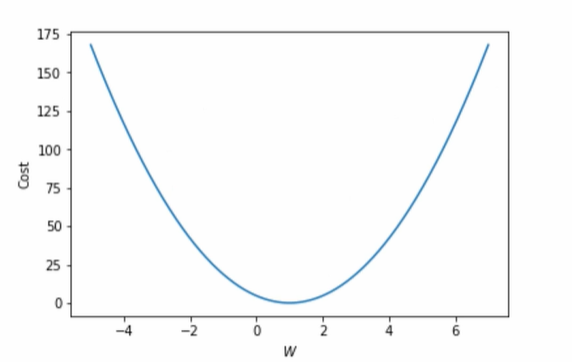
이를 통해 cost function최소화
-
기울기 음수, W 키우기
-
기울기 양수, W 감소
-
기울기 가파름, cost크므로 W크게 바꾸기
-
기울기가 평평할수록, cost는 0에 가까우므로 W를 조금 바꾸기
Gradient Descent: The Math
간단한 미분

Gradient Descent: Code

- 알파는 lr
gradient = 2 * torch.mean((W * x_train - y_train) * x_train)
lr = 0.1
W = torch.tensor([1.0, 2.0, 3.0]) # leaf variable
W -= lr * gradient
#에러: 값을 지정하지 않고 빼려고 했기 때문입니다.
#RuntimeError: a leaf Variable that requires grad is being used in an in-place operation.
#해결: 값을 지정하니 됨
print(W)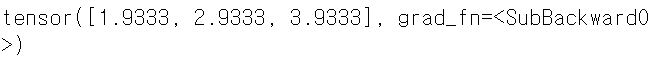
GD with torch.optim
-
torch.optim를 이용하여 GD하기
- Optimizer정의
- optimizer.zero_grad()로 gradient = 0초기화
- cost.backward()로 gradient계산
- optimizer.step()으로 gd
#optimizer설정(학습 가능한 변수와 learning weight알아야함)
W = torch.tensor([1.0, 2.0, 3.0]) # leaf variable
optimizer = torch.optim.SGD([W], lr=0.15)
#cost로 H(x)계산
#W의 gradient저장
#W의 값을 gradient에 맞게 업데이트
optimizer.zero_grad() # optimizer저장되어 있는 모든 학습 가능한 변수의 gradient를 0으로 초기화
cost.backward() #cost function미분 후 각 변수의 gradient채우기
optimizer.step() #저장된 gradient값으로 gd실행
print(W)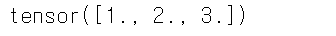
Pytorch는 leaf variable이 없으면 optimizer도 안된다.
Deeper Look at GD (Full code)
! pip install torchvision
! pip install --upgrade pip
import numpy as np
import torch
#데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])
#모델 초기화
W = torch.zeros(1)
#lr설정
lr = 0.1
nb_epochs = 10 #데이터 학습 횟수
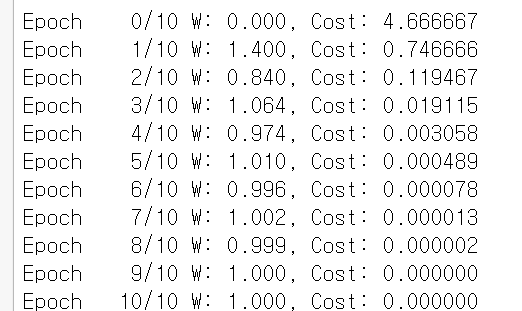
for epoch in range(nb_epochs + 1):
#학습하면서, 1에 수렴하는 W와 줄어드는 cost
#H(x)계산
hypothesis = x_train * W
#cost gradient 계산
cost = torch.mean((hypothesis - y_train) ** 2)
gradient = torch.sum((W * x_train - y_train) * x_train)
print('Epoch {:4d}/{} W: {:.3f}, Cost: {:.6f}'.format(
epoch, nb_epochs, W.item(), cost.item()
))
# cost gradient로 H(x)계산
W -= lr * gradient
#Full Code with torch.optim
#데이터
a_train = torch.FloatTensor([[1], [2], [3]])
b_train = torch.FloatTensor([[1], [2], [3]])
#모델 초기화
w = torch.zeros(1)
#lr설정
lr = 0.1
nb_epochs = 20 #데이터 학습 횟수
for epoch in range(nb_epochs + 1):
#학습하면서, 1에 수렴하는 W와 줄어드는 cost
#H(x)계산
hypothesis = a_train * w
#cost gradient 계산
cost = torch.mean((hypothesis - b_train) ** 2)
gradient = torch.sum((w * a_train - b_train) * a_train)
print('Epoch {:4d}/{} w: {:.3f}, Cost: {:.6f}'.format(
epoch, nb_epochs, w.item(), cost.item()
))
# cost gradient로 H(x)계산
w -= lr * gradient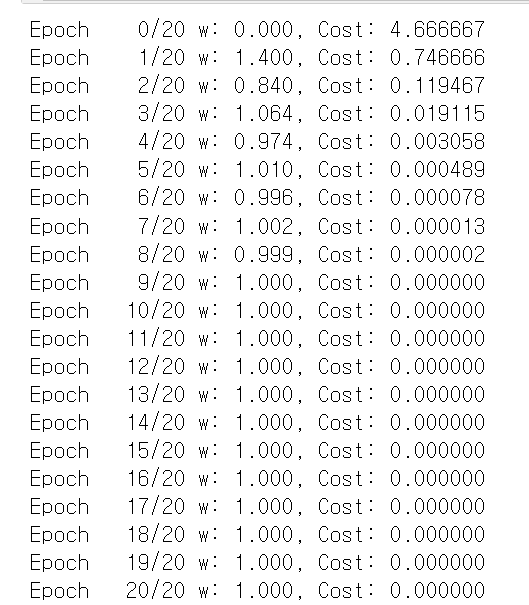

성장을 도울 아카이빙 블로그