코드:링크텍스트
CGAN
Review GAN
-
특징
-
조건이 없는 생성모델
-
내가 원하는 종류의 이미지를 바로 생성하지 못함
-
-
목적함수
-
Generator :
- 가짜 데이터를 진짜 데이터라고 예측하도록 학습시킨다.
- 최소화 관점으로 학습
-
Discriminator :
- 최대화 관점으로 학습
- 진짜 데이터를 진짜 답게 가짜 데이터를 가짜답게 정확히 예측하도록 학습
-
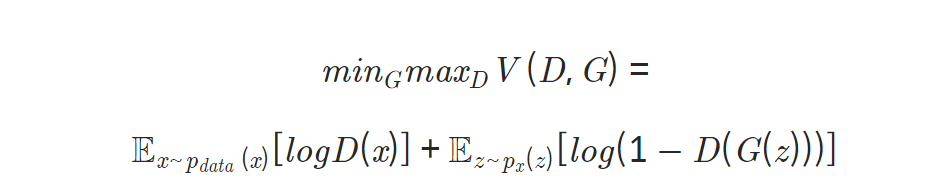
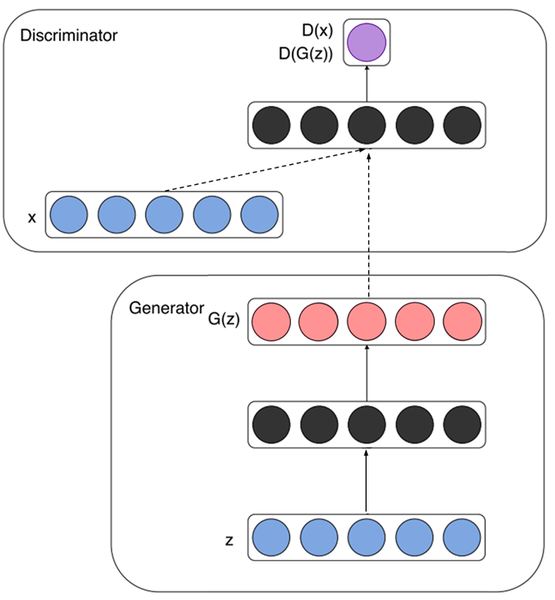
- z: 임의의 노이즈, D: Discriminator, G: Generator
-
Feed forward
-
Generator
- 노이즈 z(파란색)가 입력되고 represenation(검은색)으로 변환 후 가짜 데이터 G(z)인 빨간색을 생성한다.
-
Discriminator
- 실제 데이터 x와 Generator가 생성한 가짜 데이터 G(z)를 각각 입력받아 D(x) 와 D(G(z))인 보라색을 계산하여 진짜와 가짜를 식별한다
-
Preview CGAN
-
특징
- 내가 원하는 종류의 이미지 생성
- GAN이 가진 생성 과정의 불편함 해소
-
목적함수
- 조건부 확률 관점이 추가됨
- 특정 조건 정보인 y를 G와 D에 입력
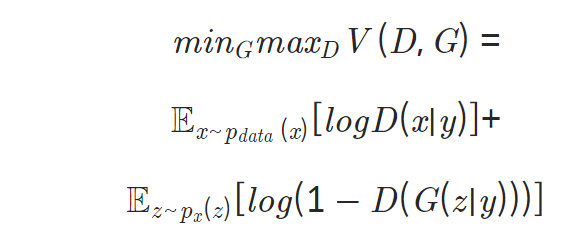
-
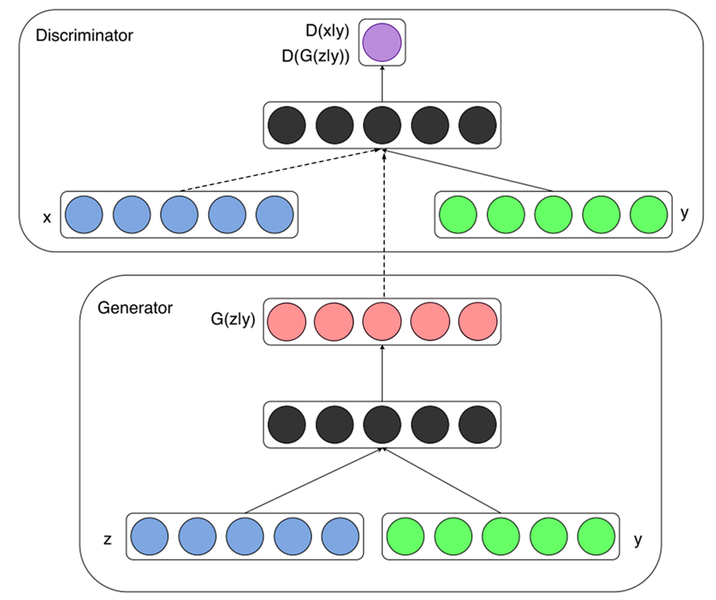
Feed forward
-
Generator
- 노이즈 z(파란색)와 추가 정보 y(녹색)을 함게 입력받은 후에 Generator 내부에서 결합이 되어 representation(검정색)으로 변환이 되어 가짜 데이터 G(z | y)를 생성하고 y는 레이블 정보이고 one-hot벡터를 입력으로 넣는다.
-
Discriminator
- 실제 데이터 x와 Generator가 생성한 가짜 데이터 G(z | y)를 각각 입력 받아 y정보가 각각 함께 입력이 되어서 진짜와 가짜를 판별한다.
- 실제 데이터 x와 y는 한 쌍을 이루어야하고, y는 동일 레이블이다.
-
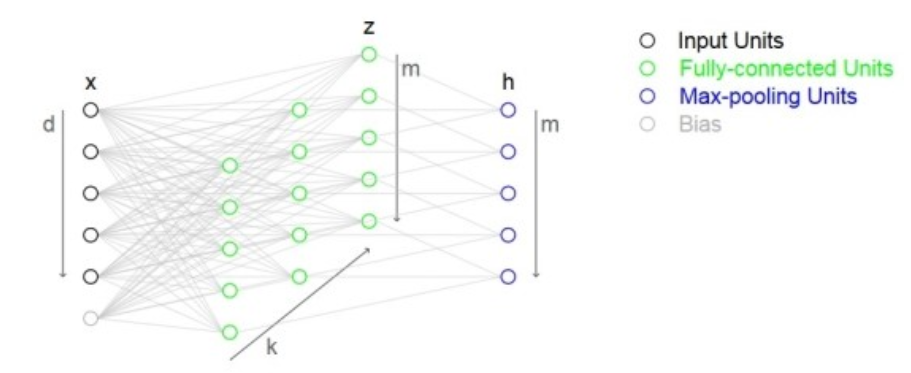
Maxout
- 정의: 두 레이어 사이 연결할 시, Activation Function이 생략된 여러 개의 FC레이어 통과 시켜서 input의 Weighted sum을 계산해서 linear function의 가장 큰 값만 취하기
- 수식
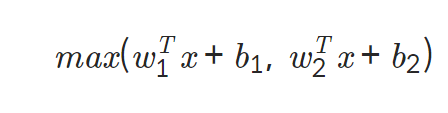
Pix2Pix
-
한 이미지의 픽셀에더 다른 이미지의 픽셀 형태로 변환한다는 의미
-
이미지를 입력으로 하여 원하는 다른 형태의 이미지로 변환 시키는 GAN모델
-
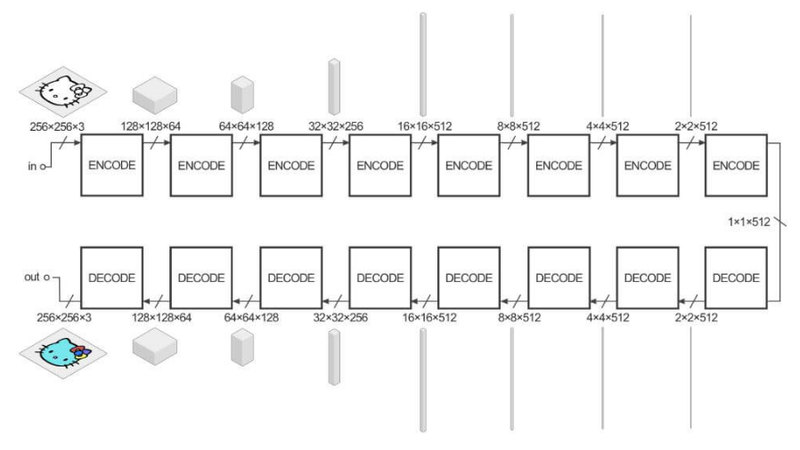
Image to Image Translation형식
Generator
-
입력이미지를 변화된 이미지로 출력하는데 이용된다.
-
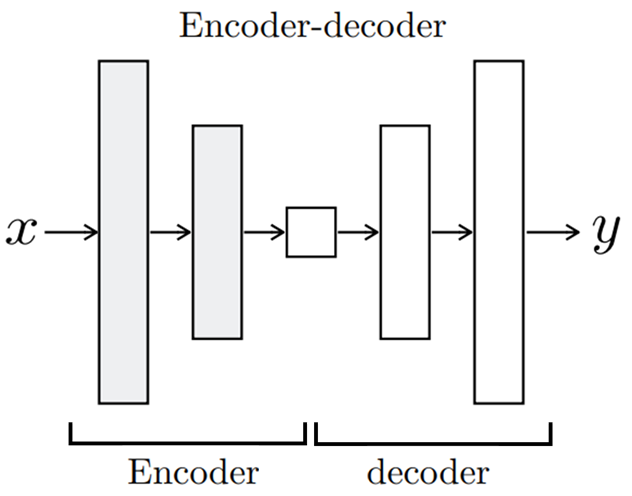
입력이미지와 변환된 이미지의 크기는 동일해야하므로 Encodr-Decoder구조를 가진다.
Encoder- Decoder
-
Convolution Layer에서 진행이 된다.
-
Encoder: 입력 이미지(x)를 받아 단계적으로 이미지를 down-sampling하여 중요 representation을 학습한다. 최종 출력은 bottleneck라고 불리고 입력 이미지(x)의 가장 중요한 특징을 담고 있다.
-
Decoder: 이미지를 up-sampling하여 입력 이미지와 동일한 크기의 변환된 이미지(y)를 생성한다.
U-Net
- 기존 Encoder-Decoder의 방식을 보완하기 위해 만든 구조
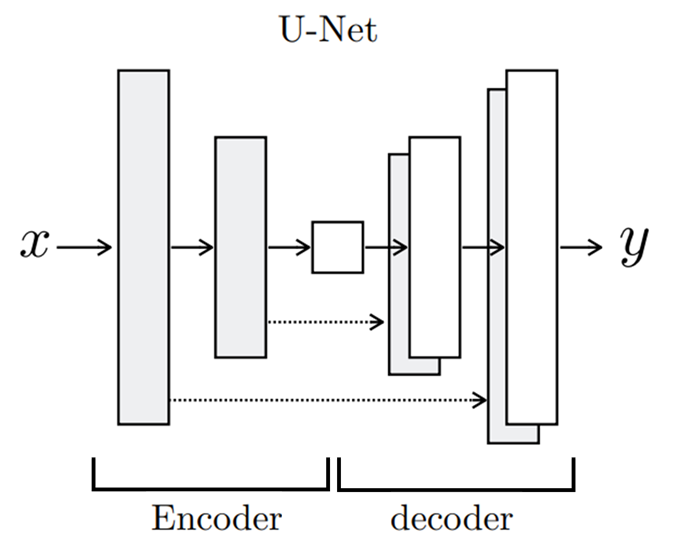
-
각 레이어마다 Encoder 과 Decoder가 연결되어있다
- Decoder가 변환 이미지 생성을 더 잘하도록 추가 정보 제공하여 선명한 이미지 얻는다
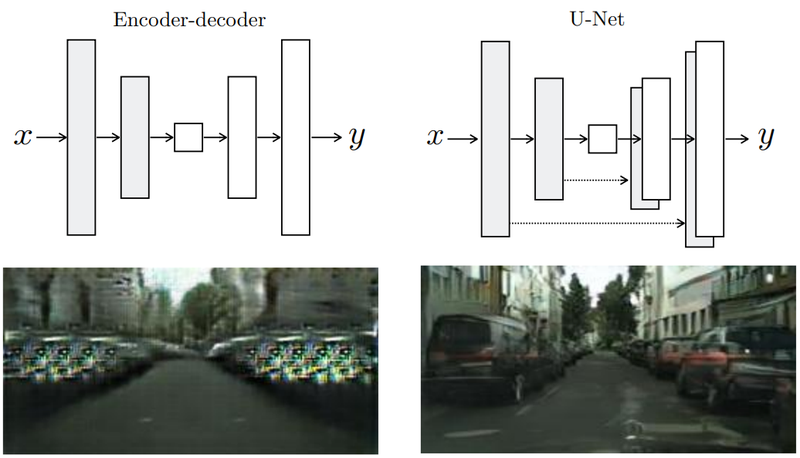
Loss Function
- L1 + CGAN을 활용하면 가장 큰 선명도를 얻을 수 있다.

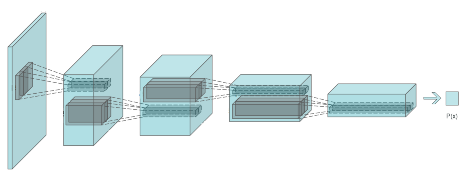
Discriminator
- DCGAN의 Discriminator은 생성된 가짜 이미지 혹은 진짜 이미지를 하나씩 입력 받아서 convolution 레이어를 점점 줄여나가면서 최정적으로 하나의 이미지에 대한 하나의 확률 값을 갖는다.
- Pix2Pix의 Discriminator는 하나의 이미지가 입력으로 들어오면, convolution레이어를 거쳐서 확률값을 나타내는 최종 결과를 생성하게 되는데 그 결과가 하나가 아닌 여러 개의 값을 갖는다.
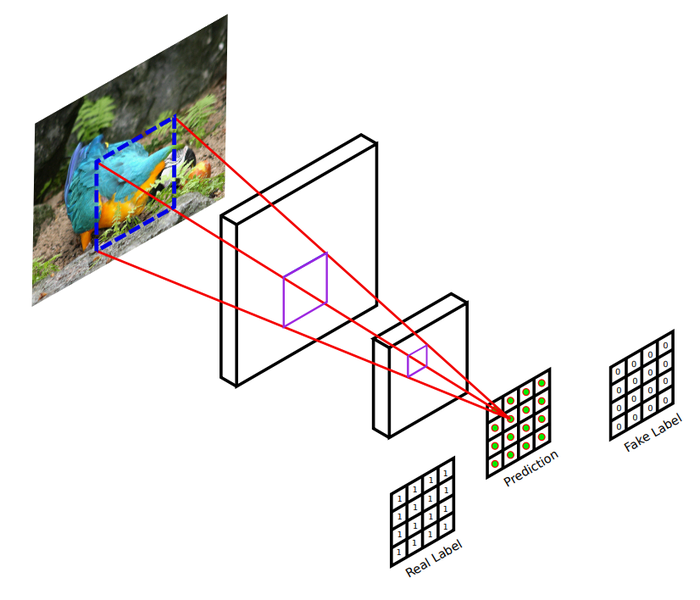
-
입력이미지의 파란색 점선: 여러 개의 출력 중 하나의 출력을 계산하기 위해 receptive field영역을 나타내고, 전체가 아닌 일부 영역만 T/F를 판별하는 확률값 도출하는 것으로 이 방식을 여러 번하여 서로 다른 확률값을 계산할 수 있고 이 값의 평균을 최종 출력값으로 생성합니다.
-
PatchGAN: 이미지의 일부 영역을 이용하는 것
- 거리가 먼 픽셀은 연관성이 없다는 것을 의미하므로 특성 크기를 가진 일부 영역을 자세하게 T/F 판별을 통해서 더 진짜 같은 이미지 생성한다.

-
sigmoid사용: 최종 출력에서 진짜 및 가짜 이미지 판별
-
C64
Encoder
-
C64 하이퍼파라미터의 레이어: 64개의 4X4필터에 stride=2인 Convolution->0.2 slope의 LeakyReLU
-
CD512 하이퍼파라미터의 레이어: 512개의 4X4필터에 stride=2적용한 Convolution ->BatchNorm -> 50%-> Dropout -> ReLU