프로젝트를 진행하면서 건강에 대한 정보를 저장 할 테이블을 생성하게 됐는데, 당연하듯이 테이블을 생성했다가 동료분께서 이렇게 만들면 "왜" 안돼요? 라는 질문을 하셨을때 시원하게 정규화라는 단어를 꺼내지 못한 내가 미워 이렇게 정리합니다.
요구조건: 건강검진을 진행 시 여러 항목의 건강점수와 총점수를 저장 해야하고 하루에 여러번 건강검진을 진행 할 수 있다.
Class Diagram
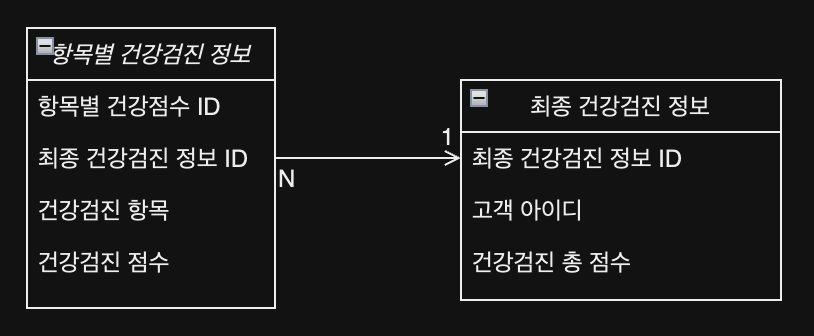
처음 만들었던 테이블 구조를 간단하게 표현한다면 다음과 같습니다.
이렇게 만들면 될 거 같아요!라고 말씀드렸는데 동료분께서 테이블 하나에 항목별 점수 컬럼들을 추가해서 저장하면 안돼요? 라는 질문을 하셨다. 질문 후에 아래와 같은 대화가 추가로 오갔다.
-
건강검진 항목이 추가되거나 제거됐을때 테이블 컬럼을 수정해야해요. >> 수정하면 되지 않을까요?
-
테이블이 늘어나고 조회할 항목들이 늘어나서 조회 시간이 늘어나는거 아니에요? >> 맞는 말인거 같다.
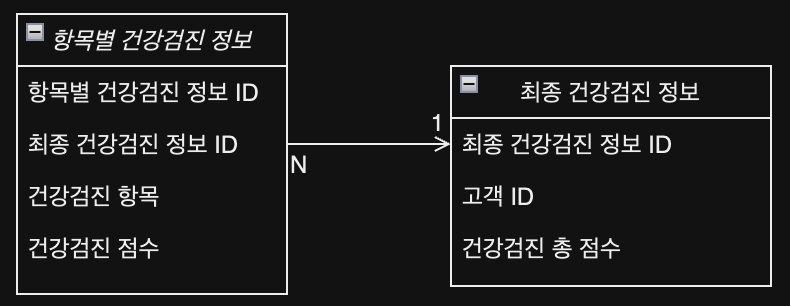
흠 그렇다면 다음과 같은 테이블 구조가 나온다.

이렇게 나온 테이블을 정규화를 시켜보자.
정규화 (Normalization)
정규화의 목적
- 데이터 중복을 최소화
- 데이터의 무결성 유지
- 이상 현상(Anomalies) 방지 (삽입 이상, 삭제 이상, 수정 이상)
정규화 단계
테이블 = 집, 컬럼 = 성격이 다른 사람들, 기본 키 = 집주인, 나머지 = 손님, 데이터 = 사람들 주머니 - 제1정규형
모든 속성이 원자 값을 가져야 합니다. 즉, 각 열은 하나의 값을 가져야 하며, 중복되는 값이 없어야 합니다.
손님들 주머니에 여러 가지 넣지 말라는 거 같다.
- 여기선 고칠게 없어보인다.
- 제2정규형
제1정규형을 만족하면서, 기본 키의 모든 부분집합에 대해 부분적 종속(Partial Dependency)을 제거해야 합니다. 즉, 기본키의 일부에 종속된 비기본키 속성이 없어야 합니다.
집주인과 손님들이 서로 얽히지 말라는 거 같다.
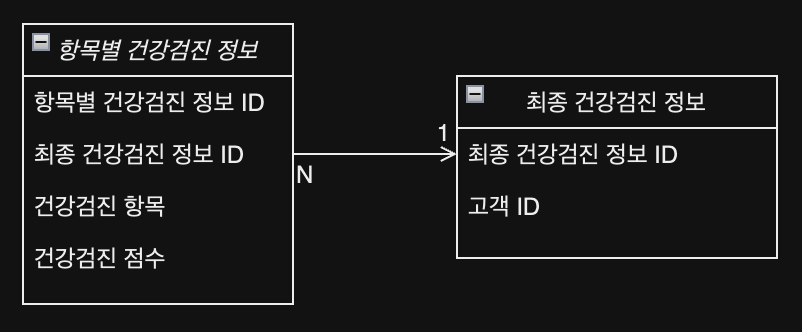
- 심박수 점수, 스트레스 점수는 기본키에 종속되지만 총 점수는 아니기 때문에 제거한다.
근데 기본 키에 종속 된다고 테이블에 일관성 있는 데이터라고 볼 수 있을까?
다음과 같은 예를 들어보자.
| 건강검진정보 ID | 고객ID | 심박수점수 | 스트레스점수 | 총점수 |
|---|---|---|---|---|
| 1 | 고객1 | 15 | 4 | 19 |
| 2 | 고객2 | 9 | 16 | 25 |
| 3 | 고객1 | 20 | null | 20 |
실제 서비스 상에서는 그럴 일 없겠지만 심박수 점수만 추가될 일이 있다고 가정한다면 이 테이블에서 스트레스 점수는 일관성 있는 데이터 일까?
제 2정규형에 의해 다음과 같이 테이블 구조가 변경된다.
- 제3정규형
제2정규형을 만족하면서, 이행적 종속(Transitive Dependency)을 제거해야 합니다. 즉, 비기본키가 다른 비기본키에 종속되면 안 됩니다.
손님들끼리 얽히지 말라는거 같다.
- 여기도 고칠게 없어보인다.
- BCNF (Boyce-Codd Normal Form)
제3정규형을 강화한 형태로, 모든 결정자(Determinant)가 후보키(Candidate Key)여야 합니다.
집주인이 될 수 있는 사람만 손님을 정할 수 있다는 뜻인거 같다.
- 여기도 고칠게 없어보인다.
4, 5 정규형은 적용할 일이 생기면 다시 추가 해보는게 좋을거 같다.
성능
좋다. 정규화를 통해 유연하고 확장 가능한 테이블로 변경 되었다. 근데 한가지 빼먹은게 있다.
테이블이 늘어나고 조회할 항목들이 늘어나서 조회 시간이 늘어나는거 아니에요?
이 중요한 사안을 해결해야 한다.
사실 이 성능이라는 것은 개발 편의 및 아키텍처 등 모든 걸 뒤엎을 만큼의 중요할 때가 있는 반면 아닐 때도 있는 거 같다. 모든 아키텍처는 대용량 트래픽을 맞아보기 전까지 모른다는 말도 들어본 거 같다. 그렇기 때문에 내가 현재 개발하고 있는 비즈니스가 어떻게 사용되고, 얼마나 사용되는지 등을 알아봐야 하는 거 같다.
건강검진 정보는 하루, 일주일, 한 달간의 데이터를 조회하고, 유저가 언제든지 조회할 수 있는 데이터다.
가장 많은 데이터가 조회될 한 달 데이터를 기준으로 하루에 10번 건강검진을 받았을 때 310번의 건강검진 데이터를 조회한다고 가정하고 시간을 비교해 봤다.
0.1초 미만의 근소한 차이가 있었고, 생성 시간에 인덱싱을 추가하니 더 차이가 줄어들었다.
건강검진을 하는 시간(약 30초)이 있어 초 단위로 데이터가 생성되지 않고, 주식처럼 실시간으로 보여줘야 하는 데이터가 아니기 때문에 이 정도의 trade off는 이득이라고 생각한다.
결론
나는 최종 테이블에 총 점수를 넣었었다. 비즈니스적으로 이득인 부분이 있어서 소신 있게 넣었는데 정규화에는 맞지 않는 데이터이다. 결국 정규화는 DB 측에서 해야 할 역할과 책임을 잘 풀어나갈 수 있는 가이드라고 생각한다. 테이블 생성 시 어떤 선택을 할 때 이 가이드를 알고 그 선택을 했는지, 모르고 했는지는 큰 차이라고 생각한다. 쉴 때 기본기를 더 잘 다져놔야겠다.
