Kafka와 RabbitMQ는 메시지 브로커(Message Broker) 로, 시스템 간 비동기 데이터 전송을 도와주는 역할을 하지만, 아키텍처와 목적이 다르다.
Kafka의 장점 및 적합한 서비스
Kafka는 대량의 데이터를 빠르게 처리하고, 내결함성과 확장성을 보장하는 메시징 시스템이다.
- 고속 처리: 대량의 메시지를 빠르게 처리할 수 있으며, 로그처럼 저장하여 장애 발생 시 복구할 수 있다.
- 내결함성: 메시지를 디스크에 지속적으로 저장하여 데이터 유실 없이 복구 가능하다.
- 수평 확장: 여러 브로커를 추가하여 높은 트래픽을 처리할 수 있다.
Kafka가 적합한 서비스 예
- 대량 데이터 처리: 실시간 로그 분석, 스트리밍 데이터 처리
- 이벤트 기반 아키텍처:
Microservices간 이벤트 전달 - IoT 데이터 수집: 센서 데이터 및 실시간 분석
RabbitMQ의 장점 및 적합한 서비스
RabbitMQ는 낮은 지연 시간과 유연한 메시지 라우팅이 강점인 메시지 브로커다.
- 낮은 지연 시간: 빠른 메시지 전달이 가능하여 실시간 응답이 필요한 서비스에 적합
- 메시지 라우팅: 다양한 메시지 패턴(
Topic,Direct,Fanout) 지원 - 트랜잭션 지원: 메시지 손실 없이 정확한 전달이 가능
RabbitMQ가 적합한 서비스 예
- 요청-응답 패턴: 주문 처리, 트랜잭션 메시징
- 작업 큐(
Task Queue): 이메일 전송, 알림 서비스 - 실시간 메시지 전달: 채팅, 푸시 알림
트랜잭션 메시지가 많고, 메시지의 정확한 전달이 중요한 경우 RabbitMQ를
로그 기반의 대량 이벤트 처리가 필요한 경우 Kafka로 사용하는게 적절하다.
Kafka와 RabbitMQ의 비교
(1) 메시지 전달 방식
RabbitMQ는 메시지를 메모리에 저장하고 빠르게 전달하기 때문에 딜레이가 거의 없다.Kafka는 디스크에 로그를 저장하고 전달하기 때문에 조금 더 시간이 걸린다.
(2) 메시지 라우팅
RabbitMQ는"Direct Exchange" 방식 등을 사용하면 특정한Consumer에게 즉시 메시지를 전달할 수 있다.Kafka는 메시지가 여러Consumer그룹으로 복제되면서 약간의 딜레이가 발생할 수 있다.
(3) 트랜잭션
RabbitMQ는 트랜잭션 기능을 꺼두면 더욱 빠르게 메시지를 전달할 수 있다.Kafka는 메시지를 로그처럼 저장하여 데이터 보존성이 높지만, 그만큼 처리 속도는 조금 느려질 수 있다.
메시지 브로커 vs 이벤트 브로커
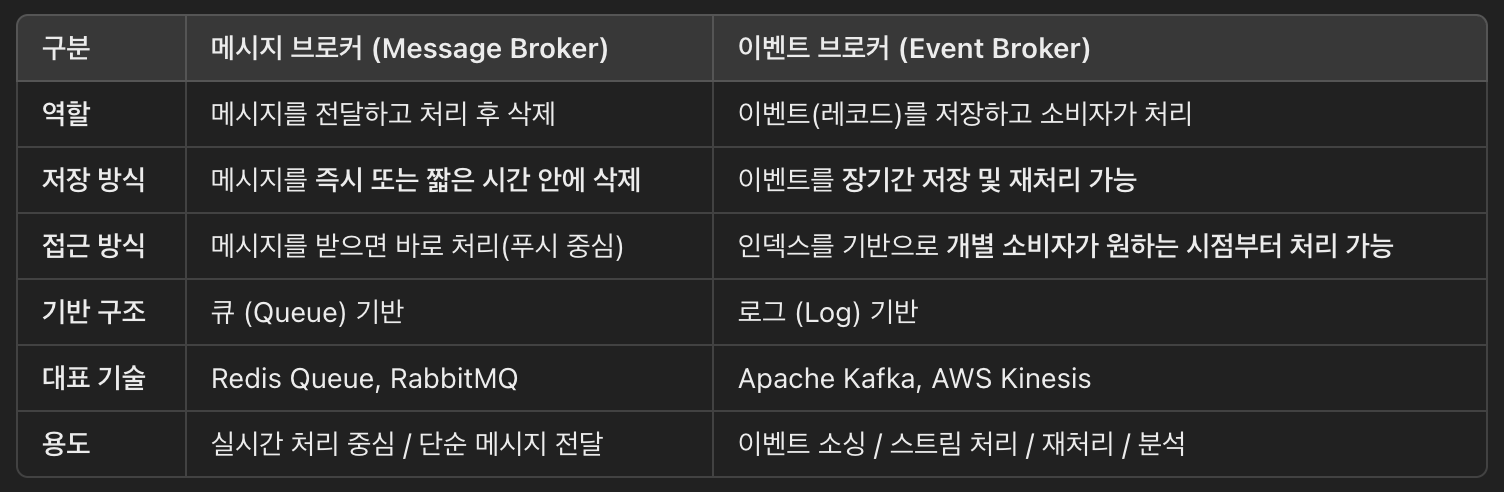
메시지 브로커란?
- 미들웨어의 일종으로, 네트워크 상의 애플리케이션들이 메시지를 주고받도록 중간에서 연결해 주는 시스템.
- 주로 프로듀서(보내는 쪽)와 컨슈머(받는 쪽) 간 실시간 통신을 담당.
- 메시지는 한 번 처리되면 삭제되는 구조이기 때문에 "실시간 전달"에 강점이 있음.
- 예: Redis Queue, RabbitMQ
이벤트 브로커란?
- 메시지 브로커와 유사하지만, 데이터베이스처럼 장기간 이벤트를 저장하고 활용할 수 있는 구조.
- 이벤트는 삭제되지 않고 저장되며, 필요할 때마다 다시 조회하거나 재처리 가능.
- 장애 복구, 데이터 분석, 리플레이 등에 유용.
- 예: Kafka, AWS Kinesis
이벤트 브로커를 사용할 때의 장점
-
단일 진실 공급원(Single Source of Truth)
→ 이벤트 데이터를 장기간 저장하면, 시스템 전체에서 신뢰할 수 있는 데이터 원천으로 활용 가능. -
재처리 / 리플레이 가능
→ 장애가 발생한 순간부터 다시 소비하거나, 이벤트를 처음부터 다시 처리할 수 있음. -
스트림 데이터 처리에 적합
→ 실시간 데이터가 끊임없이 들어오는 환경에서 대규모 이벤트 스트림을 효율적으로 처리 가능.
Kafka 클러스터 구성 방식
┌─────────────┐
│ Producer │
└────┬────────┘
│
▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Kafka Broker│◄────►│ Kafka Broker│◄────►│ Kafka Broker│ ← Kafka Cluster
└────┬────────┘ └────┬────────┘ └────┬────────┘
│ │ │
▼ ▼ ▼
Topic1 (Partition 0) Partition 1 Partition 2
▲
│
┌────┴────┐
│Consumer │ (개별 Consumer Group이 특정 Partition을 구독)
└─────────┘
- Producer: 메시지를 Topic으로 보냄
- Kafka Cluster: 여러 개의 Broker가 묶인 형태
- Partition: Topic을 나눠서 병렬 처리 가능하게 함
- Consumer Group: 각 Partition을 독립적으로 처리 (병렬 처리 핵심)
이벤트 리플레이(Event Replay) 처리 방식
Kafka에서는 메시지를 삭제하지 않고 로그 형태로 저장하므로, 특정 시점부터 다시 소비할 수 있다.
ex)
- A 서비스가 장애가 났다가 복구됨
- Kafka의 오프셋(offset)을 조정하여 처리 못 한 시점부터 다시 읽기 가능
리플레이 처리 예시 (Java / Spring Kafka)
@Autowired
private KafkaConsumerFactory<String, String> consumerFactory;
public void replayFromBeginning(String topic, String groupId) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); // 처음부터 읽기
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(topic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("리플레이 - topic: %s, value: %s%n", record.topic(), record.value());
}
}
}
이벤트 리플레이 전략
earliest: 가장 처음부터 다시 읽기latest: 가장 마지막 오프셋부터 읽기- 수동 오프셋 설정 : 특정 오프셋부터 읽기(장애 시 복구용)
