팀 프로젝트를 진행하면서 노션에 정리한 내용을 요약하여 작성했습니다.
PEAS로 봤을 때, Utility-based Agent
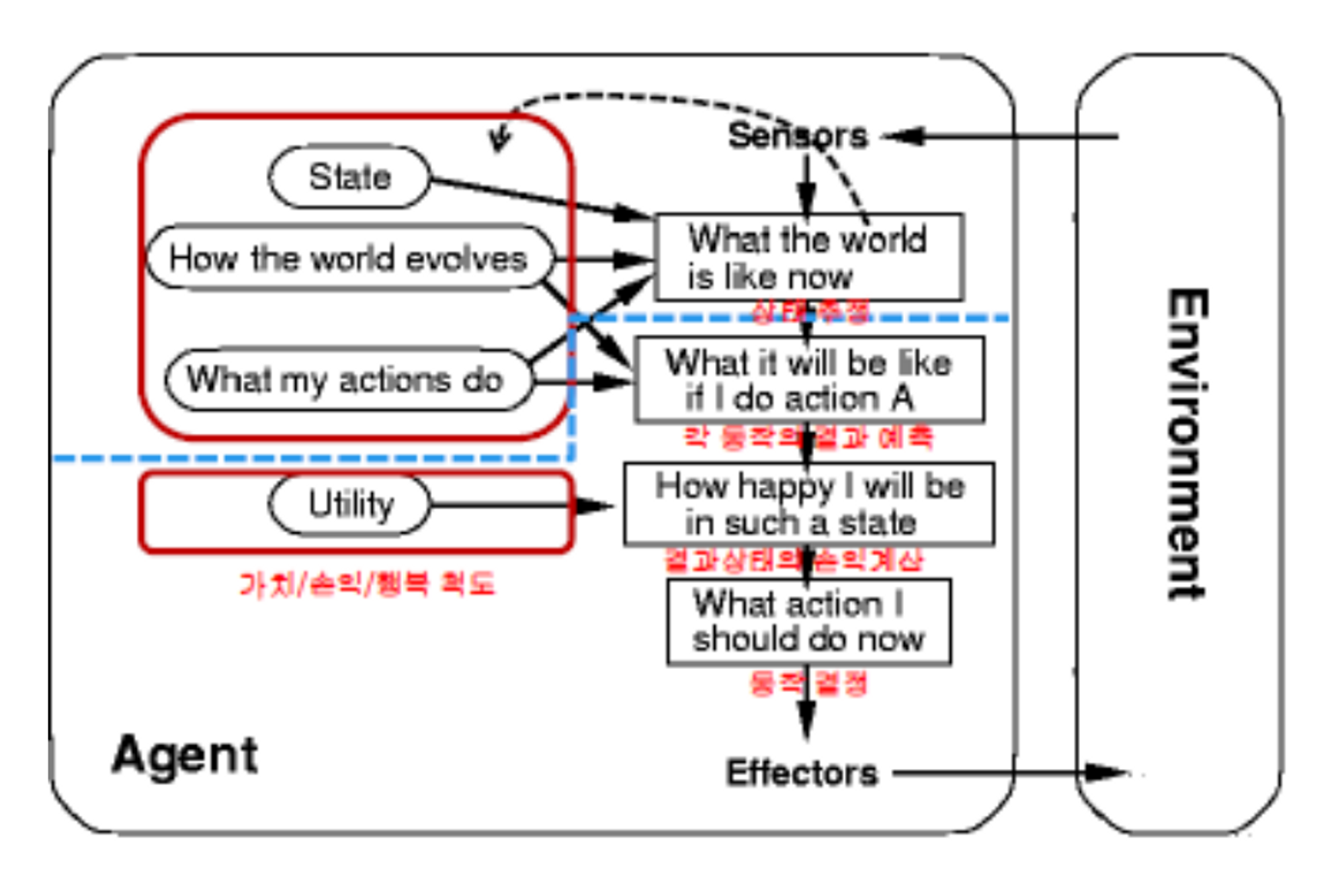
Q1) State
[이론]
현재 인식할때의 시간을 T라고 한다면, (T-1)때, 에이전트가 추정/추측한 상태를 state라고 한다.
[구현]
Utility-based Agent의 기준에 따라 에이전트의 상태를 정의하고 있다. 상태 클래스인 AgentState는 에이전트의 위치, 방향, 보유한 아이템 등을 나타내며, 이를 통해 에이전트의 현재 상태를 표현한다.
에이전트의 현재 인식하는 상태는 AgentState 클래스를 통해 나타낼 수 있다. 에이전트는 이 클래스를 사용하여 현재 인식한 상태를 추정하거나 추측한다.
시간에 대한 개념은 x 구현이 안 되어 있음
Q2) How the world evolves(world Model)
[이론]
환경에 어떻게 바뀌어가고 있느냐에 대한 지식
[구현]
WumpusEnvironment 클래스는 게임 환경을 초기화하고, 웜푸스, 함정, 금화 등을 추가하며, 에이전트의 액션을 실행하고 환경을 업데이트하는 역할을 수행한다. Wumpus World 환경에서 환경의 변화를 구현하고 있으며, 에이전트와의 상호작용을 처리하는 기능을 제공한다.
Q3) What my actions do(Action Model)
[이론]
1) 현재 상태에서 수행 가능한 행동들에 대한 결과를 예측한다. + 어떤 행동을 최종적으로 결정할 것인가에 대해서 평가한다.
2) Utility 값을 통해서 1)에서 예측한 결과들에 대한 가치/손익/행동을 계산한다.
3)2에서 계산한 가치/손익/행동 중 가장 value가 좋은 행동을 결정한다.
[구현]
def execute_action(self, agent, action): 함수로 분석함(5가지 전부 구현)
- 상태추정
상태 추정 self.list_things_at() 함수를 사용하여 에이전트의 주변 상태를 추정한다. 예를 들어, self.list_things_at(self[agent], Wumpus)는 에이전트의 위치 주변에 Wumpus가 있는지 확인하는 역할을한다.
- 각 동작의 결과 예측
각 동작의 결과를 예측하고 해당 결과에 따라 처리를 수행한다. 예를 들어, action == 'Climb'인 경우 에이전트가 시작 지점에서 금을 가지고 있는지 여부를 확인하여 게임의 승패를 판단한다.
- 결과 상태의 손익계산
각 동작의 결과 상태에 대한 손익을 계산 금을 가지고 시작 지점으로 돌아와서 게임을 이겼을 경우 agent.performance += 1000을 통해 에이전트의 점수를 증가한다. 에이전트가 함정이나 몬스터에게 사망했을 경우에는 에이전트의 점수를 감소시킨다.
- 동작 결정
Climb 액션인 경우 에이전트가 시작 지점에 도착하고 금을 가지고 있다면 승리로 처리하며, 그렇지 않은 경우 패배로 처리한다. 회전이나 이동 동작에 따라 에이전트의 위치와 방향을 변경한다.
- 유틸리티 - 가치/손익/행복 척도
agent.performance 변수를 사용하여 에이전트의 성과를 측정한다. 성과는 액션 수행에 따라 증가 또는 감소하며, 이를 통해 게임의 결과를 평가한다. 금을 획득하면 에이전트의 성과가 증가하고, 몬스터에게 사망하면 성과가 감소한다.
A* 알고리즘은 어떻게 구현했는가?
시작 노드부터 현재 노드까지의 비용을 g(n), 현재 노드에서 목표 노드까지의 예상 비용을 h(n)이라 할 때, 이 두 값을 더한 f(n) = g(n) + h(n)이 가장 최소가 되는 노드를 다음 탐색 노드로 선정
f(n) = g(n) + h(n)[휴리스틱함수)
A* 알고리즘 코드
def make_plan(self, dest, world, exact=False):
paths = []
goals = dest
curr_state = self.kb.get_state() #현재상태
for goal in goals:
cost = np.inf #무한대를 표현
path = [] #최소 경로 저장
frontier = queue.PriorityQueue()
explored = {}
frontier.put(curr_state) #현재 상태를 큐에 넣는다.
explored[curr_state] = []
while not frontier.empty() and frontier.queue[0].cost < cost:
state = frontier.get()
if self.is_goal(state, goal, exact):
actions = self.get_valid_actions(state)
for action in actions:
frontier_path = explored[state] + [action]
frontier_cost = len(frontier_path)
result = self.take_action(state, action)
if self.is_allowed(result, world, exact) and (result not in explored.keys() or frontier_cost < len(explored[result])):
path_cost = self.get_distance(result, goal) + frontier_cost
result.cost = path_cost
frontier.put(result)
explored[result] = frontier_path
if self.is_goal(result, goal, exact) and frontier_cost < cost:
path = frontier_path
cost = frontier_cost
paths.append((path, cost))
if paths:
return min(paths, key = lambda t: t[1])[0]
return NoneCost 비용 계산은 어떻게 하는가?
cost A* 검색이 시작되기 전에 각 상태에 대해 무한대(np.inf)로 초기화 한다.
A* 검색이 진행됨에 따라 누적된 경로 비용을 기반으로 각 상태의 비용이 업데이트한다.
경로 비용(g(n))은 현재 상태에 도달하는 데 걸린 경로의 길이(코드의 frontier_cost)
현재 상태에서 목표(코드의 self.get_distance(result, goal)).
코드
def get_distance(self, loc, dest):
return abs(loc.x_pos - dest.x_pos) + abs(loc.y_pos - dest.y_pos)
def make_plan(self, dest, world, exact=False):
'''
path_cost = self.get_distance(result, goal)#h(n) + frontier_cost #g(n)
#경로 비용을 계산한다. A* 검색 중에 비용이 업데이트되는 방식
코드
while not frontier.empty() and frontier.queue[0].cost < cost:
state = frontier.get()
if self.is_goal(state, goal, exact):
actions = self.get_valid_actions(state)
for action in actions:
frontier_path = explored[state] + [action]
frontier_cost = len(frontier_path)
result = self.take_action(state, action)
if self.is_allowed(result, world, exact) and (result not in explored.keys() or frontier_cost < len(explored[result])):
path_cost = self.get_distance(result, goal) + frontier_cost
result.cost = path_cost
frontier.put(result)
explored[result] = frontier_path
if self.is_goal(result, goal, exact) and frontier_cost < cost:
path = frontier_path
cost = frontier_cost
path_cost = self.get_distance(result, goal) + frontier_cost를 사용하여 새 상태에 대한 경로 비용을 계산한다.
result 상태의 cost 속성을 계산된 path_cost 값(result.cost = path_cost)으로 업데이트하도록 설계함
if self.is_allowed(result, world, exact) and (result not in explored.keys() or frontier_cost < len(explored[result])):
path_cost = self.get_distance(result, goal) + frontier_cost
result.cost = path_cost
frontier.put(result)
explored[result] = frontier_path비용을 비교하여 최적의 경로를 결정
if self.is_goal(result, goal, exact) and frontier_cost < cost:
path = frontier_path
cost = frontier_cost- 목표 상태에 도달하면(
self.is_goal(result, goal, exact)is true) 현재 경로의 경로 비용(frontier_cost)과 지금까지 얻은 최소 비용(cost)을 비교하도록 설계함 - 현재 경로 비용이 더 낮으면 그에 따라
path및cost변수를 업데이트 하도록 설계
path = frontier_path 및 cost = frontier_cost.
A* 알고리즘을 언제까지 실행해? [종료조건은?]
frontier 대기열이 비어 있거나 frontier 대기열의 현재 상태 비용이 현재 최소 비용(cost)을 초과할 때까지 A* 검색 알고리즘을 실행하도록 설계
while not frontier.empty() and frontier.queue[0].cost < cost:오류 발생 부분
1. Safe_locs가 아니라 다시 태어나면 위험을 감지한 상황에 대한 리스트가 초기화된다.
Agentstate 클래스에 set_location_start 메서드를 생성하여 KB 클래스를 경유하는 방법으로 agent가 행동하는 시점에 die_flag를 체크하여 초기화 하도록 하였음
