
출처 | https://velog.io/@kimdukbae/%EC%9D%B4%EB%B6%84-%ED%83%90%EC%83%89-%EC%9D%B4%EC%A7%84-%ED%83%90%EC%83%89-Binary-Search
https://yoongrammer.tistory.com/75
이진탐색(이분탐색)
이진 탐색(이분 탐색) 알고리즘은 정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 방법이다.
이진 탐색은 배열 내부의 데이터가 정렬되어 있어야만 사용할 수 있는 알고리즘이다.
변수 3개(start, end, mid)를 사용하여 탐색한다. 찾으려는 데이터와 중간점 위치에 있는 데이터를 반복적으로 비교해서 원하는 데이터를 찾는 것이 이진 탐색의 과정이다.
이진 탐색 / 이분 탐색 알고리즘 코드 (Python)
재귀 함수로 구현한 이진 탐색(이분 탐색)
# 재귀 함수로 구현한 이진 탐색
def binary_search(array, target, start, end):
if start > end:
return None
mid = (start + end) // 2
# 원하는 값 찾은 경우 인덱스 반환
if array[mid] == target:
return mid
# 원하는 값이 중간점의 값보다 작은 경우 왼쪽 부분(절반의 왼쪽 부분) 확인
elif array[mid] > target:
return binary_search(array, target, start, mid - 1)
# 원하는 값이 중간점의 값보다 큰 경우 오른쪽 부분(절반의 오른쪽 부분) 확인
else:
return binary_search(array, target, mid + 1, end)
n, target = list(map(int, input().split()))
array = list(map(int, input().split()))
result = binary_search(array, target, 0, n - 1)
if result is None:
print('원소가 존재 X')
else:
print(result + 1)
>>> 4
# sample input
# 10 7
# 1 3 5 7 9 11 13 15 17 19반복문으로 구현한 이진 탐색(이분 탐색)
# 반복문으로 구현한 이진 탐색
def binary_search(array, target, start, end):
while start <= end:
mid = (start + end) // 2
# 원하는 값 찾은 경우 인덱스 반환
if array[mid] == target:
return mid
# 원하는 값이 중간점의 값보다 작은 경우 왼쪽 부분(절반의 왼쪽 부분) 확인
elif array[mid] > target:
end = mid - 1
# 원하는 값이 중간점의 값보다 큰 경우 오른쪽 부분(절반의 오른쪽 부분) 확인
else:
start = mid + 1
return None
n, target = list(map(int, input().split()))
array = list(map(int, input().split()))
result = binary_search(array, target, 0, n - 1)
if result is None:
print('원소가 존재 X')
else:
print(result + 1)
>>> 4
# sample input
# 10 7
# 1 3 5 7 9 11 13 15 17 19-
시간 복잡도는 O(logN)이다. (여기서 log는 log₂이다.)
단계마다 탐색 범위를 반으로(÷2) 나누는 것과 동일하므로 위 시간 복잡도를 가지게 된다.
예를 들어 처음 데이터의 개수가 32개라면, 이론적으로 1단계를 거치면 약 16개의 데이터가 남고, 2단계에서 약 8개, 3단계에서 약 4개의 데이터만 남게 된다.
즉, 이진 탐색(이분 탐색)은 탐색 범위를 절반씩 줄이고, O(logN)의 시간 복잡도를 보장한다 -
두 개의 코드를 보면 조건이 start > end 일 경우 /// start <= end일 경우 2가지로 나누어 작성된다. 해당 부분을 자세히 말하면,
- 재귀 함수로 구현된 경우 : 재귀 호출을 멈추는 기준으로 사용된다.
- 반복문으로 구현된 경우 : 반복문을 계속 실행하기 위한 조건으로 사용된다.
Python 이진 탐색 라이브러리
Python에서는 bisect라는 이진 탐색 라이브러리(모듈)을 지원한다! 예제를 통해 알아보도록 하자.
-
bisect_left(a, x) --> 정렬된 순서를 유지하면서 리스트 a에 데이터 x를 삽입할 가장 왼쪽 인덱스를 찾는 메소드
-
bisect_right(a, x) --> 정렬된 순서를 유지하도록 리스트 a에 데이터 x를 삽입할 가장 오른쪽 인덱스를 찾는 메소드
from bisect import bisect_left, bisect_right
a = [1, 2, 4, 4, 8]
x = 4
print(bisect_left(a, x))
>>> 2
# 리스트 a에 4를 삽입할 가장 왼쪽 인덱스는 2이다.
print(bisect_right(a, x))
>>> 4
# 리스트 a에 4를 삽입할 가장 오른쪽 인덱스는 4이다.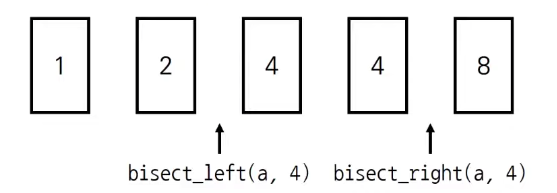
from bisect import bisect_left, bisect_right
# '정렬된 리스트'에서 `값이 특정 범위에 속하는 원소의 개수`를 구할 때 좋다.
def count_by_range(b, left_value, right_value):
right_index = bisect_right(b, right_value)
left_index = bisect_left(b, left_value)
print('right : ', right_index, 'left :', left_index)
return right_index - left_index
a = [1, 2, 3, 3, 3, 3, 4, 4, 8, 9]
print(count_by_range(a, 4, 4))
>>> right : 8 left : 6
>>> 2
# 리스트 a에 4는 총 2개 존재한다.
print(count_by_range(a, -1, 3))
>>> right : 6 left : 0
>>> 6
# 리스트 a에 -1~3사이의 값은 총 6개 존재한다.- 이렇게 Python의 bisect라이브러리(모듈)은 '정렬된 리스트'에서 '값이 특정 범위에 속하는 원소의 개수'를 구할 때 사용하면 효율적이다.
이진탐색 예제
이진 탐색을 사용하여 key = 32값을 찾는 과정을 보도록 하겠다.
- 먼저 배열의 가운데를 결정한다.
mid = low + (high - low) / 2
= 0 + (9-0)/2
= 4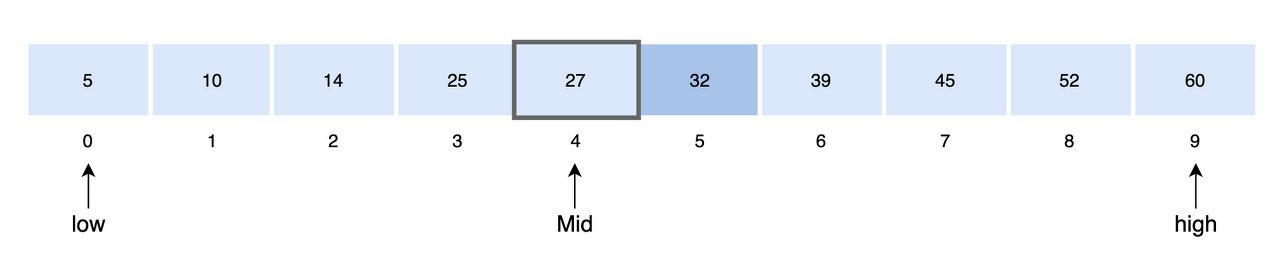
- 중앙 값과 검색 값을 비교한다.
A [4] < key 이므로 배열의 오른쪽 구간을 검색 범위로 정한다.
low = mid + 1
= 4 + 1
= 5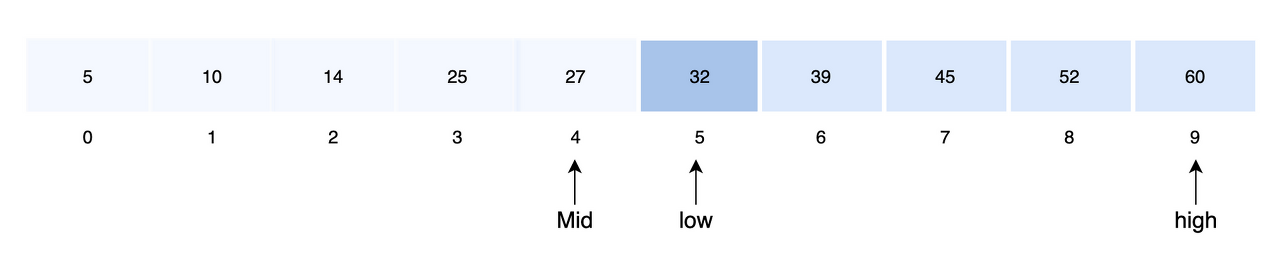
- 중앙 값을 결정합니다
mid = 5+ (9-5)/2
= 7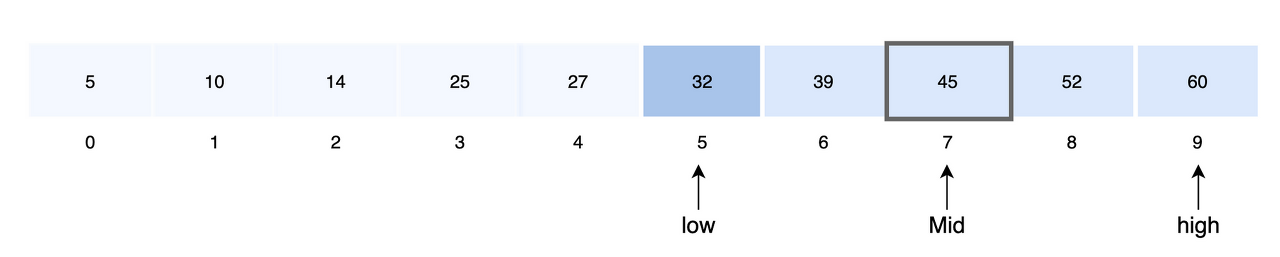
- 중앙 값과 검색 값을 비교합니다.
A [7] > key 이므로 배열의 왼쪽 구간을 탐색 범위로 정합니다.
high = mid -1
= 7 - 1
= 6

- 중앙 값을 결정합니다.
mid = 5 + (6-5)/2
= 5
- 중앙 값과 검색 값을 비교합니다.
A [5] = key 이므로 탐색을 종료합니다.
