
출처| https://www.youtube.com/watch?v=85Zg0HUv_Eo&list=PLVsNizTWUw7Hox7NMhenT-bulldCp9HP9&index=38
https://daegwonkim.tistory.com/177
인덱스의 내부작동1
클러스터형 인덱스와 보조 인덱스는 모두 내부적으로 균형 트리로 만들어진다. 균형 트리(Balanced Tree)는 '자료 구조'에 나오는 범용적으로 사용되는 데이터의 구조로써 데이터를 검색하는 데 효율적으로 이루어져있다.
균형 트리는 나무를 거꾸로 표현한 자료 구조로, 트리에서 제일 상단의 뿌리를 루트, 줄기를 중간, 끝에 달린 잎을 리프라고 부른다.
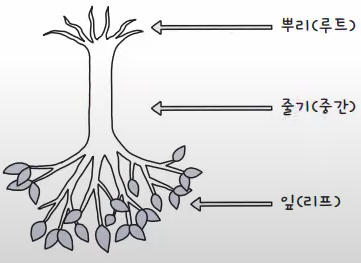
균형 트리 구조에서 데이터가 저장되는 공간을 노드(Node)라고 한다.
루트 노드(Root Node)는 노드의 가장 상위 노드를 말한다. 모든 출발은 루트 노드에서 시작된다.
리프 노드(Leaf Node)는 제일 마지막에 존재하는 노드를 말한다.
루트 노드와 리프 노드 사이에 있는 노드를 중간 노드(Internal Node)라고 한다.
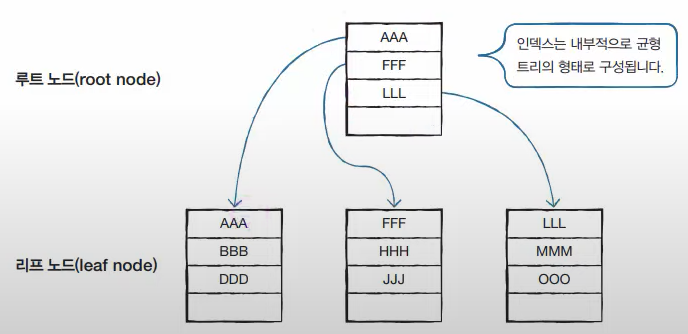
노드라는 용어는 개념적인 설명에서 주로 나오는 용어이며, MySQL에서는 페이지(Page)라고 부른다.
인덱스는 균형 트리로 이루어져 있기 때문에 SELECT의 속도를 향상시킬 수 있다.
다만 인덱스를 구성하면 데이터 변경 작업(INSERT, UPDATE DELETE) 시 성능이 나빠진다. 특히 INSERT 작업이 일어날 때 더 느리게 입력될 수 있다.
이유는 페이지 분할이라는 작업이 발생하기 때문인데, 페이지 분할이란 새로운 페이지를 준비해서 데이터를 나누는 작업을 말한다.
페이지 분할이 일어나면 MySQL이 느려지고, 너무 자주 일어나게되면 성능에 큰 영향을 미친다.
INSERT 문으로 인한 페이지 분할
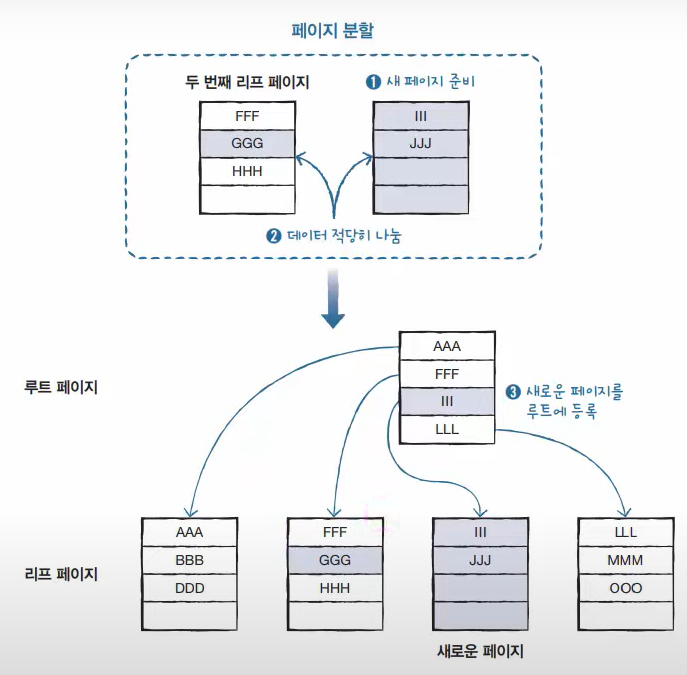
페이지 분할로 인한 중간 노드의 생성
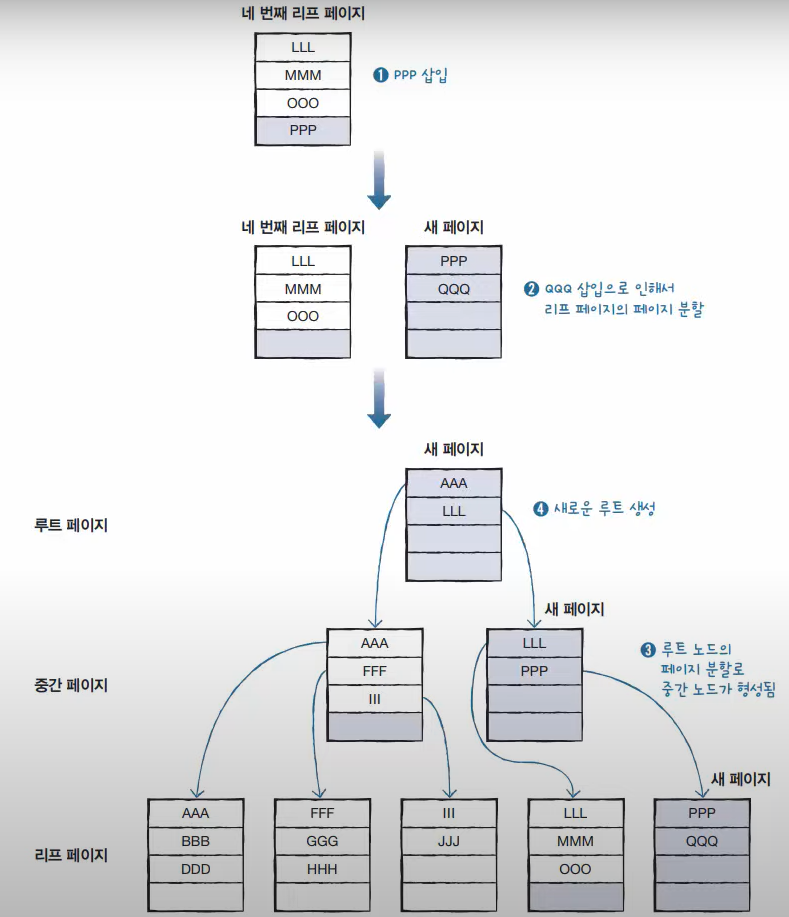
클러스터형 인덱스와 보조 인덱스의 구조
CREATE DATABASE IF NOT EXISTS testdb;
USE testdb;
DROP TABLE IF EXISTS clustertbl;
CREATE TABLE clustertbl -- Cluster Table 약자
( userID CHAR(8) ,
name VARCHAR(10)
);
INSERT INTO clustertbl VALUES('LSG', '이승기');
INSERT INTO clustertbl VALUES('KBS', '김범수');
INSERT INTO clustertbl VALUES('KKH', '김경호');
INSERT INTO clustertbl VALUES('JYP', '조용필');
INSERT INTO clustertbl VALUES('SSK', '성시경');
INSERT INTO clustertbl VALUES('LJB', '임재범');
INSERT INTO clustertbl VALUES('YJS', '윤종신');
INSERT INTO clustertbl VALUES('EJW', '은지원');
INSERT INTO clustertbl VALUES('JKW', '조관우');
INSERT INTO clustertbl VALUES('BBK', '바비킴');
SELECT * FROM clustertbl;
인덱스를 지정함. PRIMARY KEY로 지정하면 클러스터형 인덱스로 지정된다.
ALTER TABLE clustertbl
ADD CONSTRAINT PK_clustertbl_userID
PRIMARY KEY (userID);다시 조회하면,
SELECT * FROM clustertbl;
UserID 열로 정렬된다.
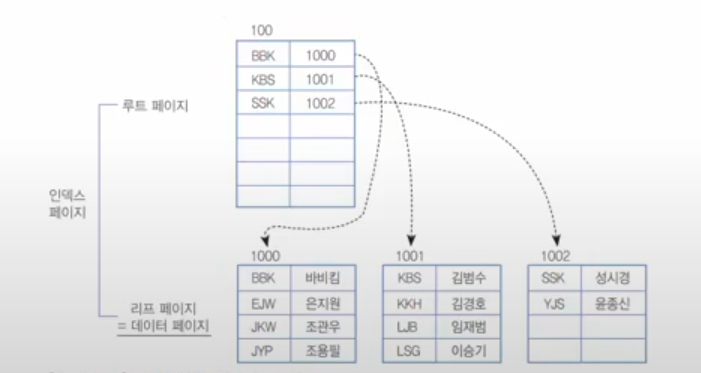
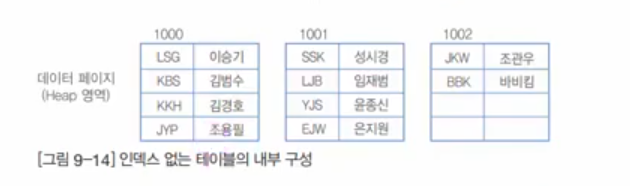
이렇게 정렬이 된다. 루트 페이지의 기준은 각 PK의 첫 번째 열, BBK-1000/KBS-1001/SSK-1002 영어 사전처럼 정렬이 된다.
이번엔 보조 인덱스를 만들어 보자.
CREATE DATABASE IF NOT EXISTS testdb;
USE testdb;
DROP TABLE IF EXISTS secondarytbl;
CREATE TABLE secondarytbl -- Secondary Table 약자
( userID CHAR(8),
name VARCHAR(10)
);
INSERT INTO secondarytbl VALUES('LSG', '이승기');
INSERT INTO secondarytbl VALUES('KBS', '김범수');
INSERT INTO secondarytbl VALUES('KKH', '김경호');
INSERT INTO secondarytbl VALUES('JYP', '조용필');
INSERT INTO secondarytbl VALUES('SSK', '성시경');
INSERT INTO secondarytbl VALUES('LJB', '임재범');
INSERT INTO secondarytbl VALUES('YJS', '윤종신');
INSERT INTO secondarytbl VALUES('EJW', '은지원');
INSERT INTO secondarytbl VALUES('JKW', '조관우');
INSERT INTO secondarytbl VALUES('BBK', '바비킴');

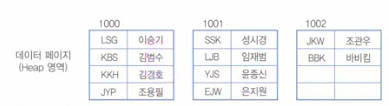
이 모습으로 저장되어 있다. 이번엔 UNIQUE 키로 보조 인덱스를 생성했다.
ALTER TABLE secondarytbl
ADD CONSTRAINT UK_secondarytbl_userID
UNIQUE (userID);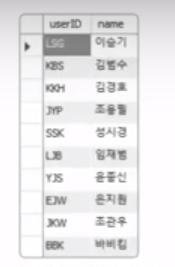
데이터 구조가 정렬되진 않고, 내부적으로는 이와 같이 구성 될 것이다.
보조인덱스
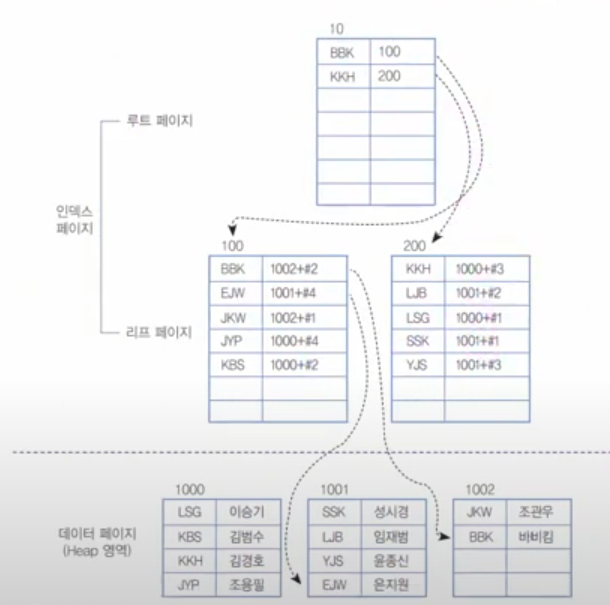
- 전체적인 틀은 유지된다. + 찾아보기만 만든다. 앞에 있는 [LSG,KBS,KKH,JYP] Etc... 뽑아서 사용한다.
클러스터 인덱스
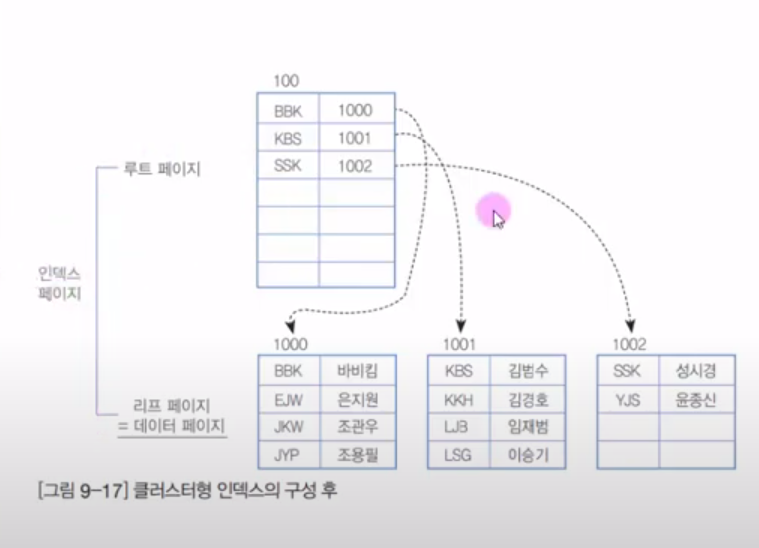
- 영어 사전처럼 구성된다.
