
출처 | https://www.youtube.com/watch?v=UVY0mfa4VP0&list=PLqTUMsvO70nk8WfCyU-IPmc85390CaSqM&index=1
https://cafe.naver.com/thisisMySQL
https://velog.io/@ong_hh/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%EA%B5%AC%EC%B6%95
INSERT

USE sqldb;
CREATE TABLE testtbl1 (id, int, userName, char(3), age int);
INSERT INTO testtbl1 VALUES(1,'홍길동',25);
여기서 ID와 이름만 입력하고 나이를 입력하고 싶지 않다면 테이블 이름 뒤에 입력할 열의 목록을 나열해야 한다.
INSERT INTO testtbl1(id, userName) VALUES(2,'설현');AUTO_INCREMENT
-
자동으로 증가한다.
-
테이블 속성이 AUTO_INCREMENT로 지정 되어 있다면 INSERT에서는 해당 열이 없다고 생각하고 입력하면 된다.
-
AUTO_INCREMENT로 지정할 때는 꼭
PRIMARY KEY또는UNIQUE로 지정해야 한다. 데이터 형은 숫자 형식만 사용할 수 있다.
USE sqldb
CREATE TABLE testtbl2
(id, int(AUTO_INCREMENT) PRIMARY KEY, userName, char(3), age int);
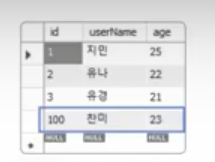
INSERT INTO testtbl2 VALUES (NULL,'지민',25);
INSERT INTO testtbl2 VALUES (NULL,'지환',23);
INSERT INTO testtbl2 VALUES (NULL,'유경',27);
SELECT * FROM testtbl2;
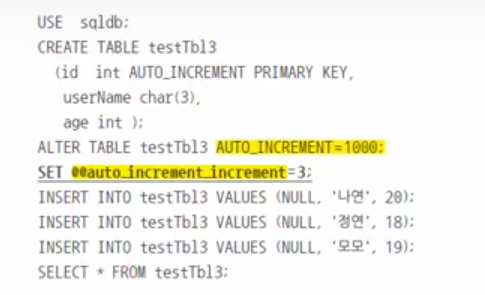
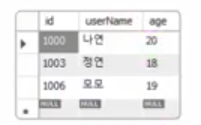
ALTER TABLE testtbl2 AUTO_INCREMENT = 100;
INSERT INTO testtbl2 VALUES (NULL, '찬이수',23);
SELECT* FROM testtbl2;
1000부터 시작하고 3씩 증가하는 구조
대량의 샘플 데이터 생성
INSERT INTO 테이블이름 (열이름1,2,3...)
SELECT문 ;SELECT문의 결과 열의 개수는 INSERT할 때의 테이블의 열 개수와 일치해야한다.
USE sqldb;
CREATE TABLE testtbl4(id int, Fname varchar(50), Lname varchar(50));
INSERT INTO testtbl4
SELECT emp_no, first_name, last_name
FROM employees.employees;
UPDATE
- 데이터의 수정
[형식]
UPDATE 테이블이름
SET 열1=값1,값2,값3
WHERE 조건;
[예제]
UPDATE testtbl4
SET Lname = '없음'
WHERE Fname = 'kyoichd';DELETE FROM
- DELETE는 행 단위로 삭제한다. 형식은 이와 같다
[형식]
DELETE FROM 테이블이름 WHERE 조건;
[예제]
USE sqldb;
DELETE FROM testtbl4 WHERE Fname = 'Ansu';
[예제2]-- 5명만 삭제
USE sqldb;
DELETE FROM testtbl4 WHERE Fname = 'Ansu' LIMIT 5;
실습1
USE sqldb;
CREATE TABLE bigTbl1 (SELECT * FROM employees.employees);
CREATE TABLE bigTbl2 (SELECT * FROM employees.employees);
CREATE TABLE bigTbl3 (SELECT * FROM employees.employees);
DELETE FROM bigTbl1; -- 테이블이 30만건이 지워지고 / 하나씩 지운다 -> 그래서 시간이 오래걸린다.
DROP TABLE bigTbl2; -- 테이블이 통채로 날라간다. / 테이블 구조가 날라간다.
TRUNCATE TABLE bigtbl3; -- 테이블의 구조는 남아 있고 DELETE는 남아있다.
INSERT 실습2
USE sqldb;
CREATE TABLE memberTBL (SELECT userID, name, addr FROM userTbl LIMIT 3);
ALTER TABLE memberTBL
ADD CONSTRAINT pk_memberTBL PRIMARY KEY(userID); -- PK를 지정함
SELECT * FROM memberTBL;
INSERT INTO memberTBL VALUE('bbk','바비코','미국');
INSERT INTO memberTBL VALUE('SJH','서장훈','서울');
INSERT INTO memberTBL VALUE('HJY','현주엽','경기');
INSERT IGNORE INTO memeberTBL VALUE('bbk','바비코','미국');
INSERT IGNORE INTO memeberTBL VALUE('SJH','서장훈','서울');
INSERT IGNORE INTO memeberTBL VALUE('HJY','현주엽','경기');
SELECT* FROM memberTBL;
INSERT INTO memberTBL VALUES('bbk','바비코','미국') -- 키가 중복되면 업데이트해라[밑]
ON DUPLICATE KEY UPDATE name = '비비코', addr = '미국';
INSERT INTO memberTBL VALUES('DJM','둥짜몽','일본')
ON DUPLICATE KEY UPDATE name = '둥짜몽', addr = '일본';
- DUPLICATE KEY 중복되는 키면~으로 해석
WITH 절과 CTE
-
CTE는 뷰, 파생 테이블, 임시 테이블 등으로 사용되던 것을 대신할 수 있으며, 더 간결한 식으로 보여지는 장점이 있다.
-
CTE는 재귀적 / 비재귀적 2가지가 있다.
비재귀적 CTE
[형식]
WITH CTE_테이블이름(열 이름)
AS
(
<쿼리문>
)
SELECT 열 이름 FROM CTE_테이블이름;
[예제]
USE sqlDB;
SELECT userid AS '사용자' , SUM(price*amount) AS '총구매액'
FROM buyTBL
GROUP BY userid;
+ CTE를 이용하여 구문을 단순화 한다.
WITH abc(userid, total)
AS
(SELECT userid, SUM(price*amount) FROM buytbl GROUP BY userid)
SELECT* FROM abc ORDER BY total DESC;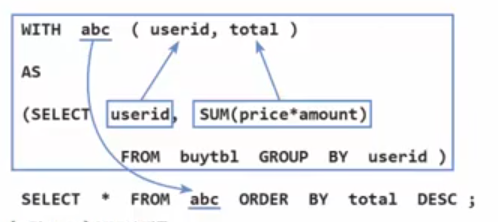

아는만큼보인다.