
[ "한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다." ]
주니어 백엔드 개발자가 반드시 알아야 할 실무 지식
최범균: 나이를 먹어서도 백발에 개발을 하고 싶은 코딩을 좋아하는 개발자다. 좋은 책을 쓰는 것을 꿈꾸고 있고, 꾸준히 블로그와 브런치에 글을 쓰고 있다. ‘스프링4 프로그래밍 입문’, ‘JSP 2.3 웹 프로그래밍’, ‘개발자가 반드시 정복해야 할 객체 지향과 디자인 패턴’ 등의 책을 집필했다. https://javacan.tistory.com/ 블로그와 https://www.youtube.com/@madvirus 유투브 열심히 지금까지도 지식공유를 해주신다!
리뷰
책 소개에 나오는 사례가 완벽하게 학부생때 경험한 시나리오였다. 커넥션풀, DBMS 에 대한 낮은 이해도, 사실 "연결"이 왜 메모리를 먹는지도 잘 몰았던 시절, 연결에 왜 timeout 을 줘야하는지도 몰랐던 그 때가 바로 떠올랐다.
개인적으로 무엇보다 개발은 실수를 하며 심연을 해맬때 결국 가장 큰 성과를 얻었다. 근데 지금도 심연에 있는 기분이 들때가 많다.. 결국 오답노트가 공부에 가장 큰 도움이 되었다. 이 책은 그 좋은 오답노트 수첩을 훔쳐보는 기분이다. 시니어 분들에게는 향수와 가이드할 목차를, 주니어 분들에게는 겪어 보지 못한 실수도 같이 해보며 따라갈 수 있는 실마리를 줄 것 같다.
인스턴트가 넘쳐나는 LLM 시대에 (어쩌면 벌써) Classic 을 읽는 기분이다.
- 성능의 근본 개념과 접근법을 다룬 2장,
- 실질적이고 깊이 있는 DB 이야기로 가득 찬 3장,
- 프레임워크를 떠나 API 서버와 인프라 전반을 다루는 4장 (외부 API 연동, 동시 요청 제한, 서킷 브레이커, HTTP 커넥션 풀, 연동 서비스 이중화 등),
- 이어서 코드 수준에서 동기/비동기, 스레드 처리, 메시징, 트랜잭션 아웃박스, CDC까지 짚어주는 5장,
- 레이스 컨디션, 락과 세마포어, DB 동시성 처리 등을 다룬 6장,
- IO 병목과 네트워크 관점에서의 자원 효율화 방식을 설명한 7장,
- 실무에서 반드시 필요한 보안 기초(시큐어 코딩 포함)를 정리한 8장,
- 리눅스 기반의 OS 및 서버에 대한 기본 지식(계정 권한, 디스크 용량, 크론 등)을 다룬 9장,
- 네트워크 기본 개념을 복습하는 10장,
- 그리고 마지막으로 자주 사용되는 서버 구조 및 설계 패턴(MVC, 계층형 아키텍처, DDD, 마이크로서비스, CQRS 등)을 다룬 11장까지.각 장은 위와 같은 구성으로, 2장을 시작으로 실무에서 꼭 짚고 넘어가야 할 체크포인트들을 순차적으로 다루며, 각 주제에 필요한 핵심 사전 지식을 자연스럽게 덧붙이는 방식으로 전개된다. 요즘 주니어 개발자를 위한 가이드는 확실히 잘 나오는 듯하다... 그런데 왜 중니어, 시니어를 위한 책은 없는 걸까 ㅠㅠ
물론 이 책이 모든 부분을 CS/OS 레벨이나 네트워크의 HW나 DB의 스토리지 레벨까지 깊게 파고들지는 않지만, 그 대신 얕고 넓게, 무엇보다 “실제로 겪은 실무 사례”와 함께 폭넓게 정리되어 있다는 점이 강점이다. 사실 이런 책은 실마리만 잘 잡아주면 된다. 이후의 depth는 각자의 몫이니까.
더욱이 조금 더 주관적인 의견을 덧붙이자면, DBMS(특히 인덱싱과 쿼리 최적화), 네트워크, 리눅스 기반 OS 활용만 제대로 마스터해도 대부분의 서비스 이슈는 어떻게든 해결 가능하다고 믿는다. 하나 덧붙이자면 서비스로직 처리할때 비동기, 동시성, lock 개념 정도..?
마무리하자면, 이 책은 마치 옆자리 팀장님이 “나는 그럴 땐 이렇게 했었어~” 하며 빠르게 구두로 알려주는 느낌이다. 그리고 그 말 한마디에 문득 실마리가 풀리던, 그 익숙한 순간처럼 읽힌다.
근데 아주 솔직히 내가 진짜 0-1년차 였다면 이 책이 한 숨에 읽히진 않았을 것 같다. 그리고 마냥 웃으면서 볼 수도 없었을 것 같고 ㅎㅎ
목차별 리뷰
2장 느려진 서비스, 어디부터 봐야 할까
1) 처리량과 응답 시간
API 호출이라는 단순한 흐름(application → server → DB)을 바탕으로 성능을 바라보는 시각은 명쾌하다. 응답 시간이라는 것은 단순히 서버 코드만의 문제가 아니며, TTFB(Time to First Byte), TTLB(Time to Last Byte) 처럼 전체 체인을 기준으로 측정되어야 한다. 특히 파일 다운로드의 경우, 두 시간 차이가 클 수 있다. 아래 글 한번 읽어보길 추천

구글이 "100ms의 지연이 검색 횟수를 0.2% 감소, 400ms 지연은 0.4% 감소시킨다"는 발표를 한 적 있다. (응답 시간)퍼포먼스는 사용자 경험(UX)의 핵심이다.
실제 서비스에서의 서버 처리 시간은 단순히 비즈니스 로직을 수행하는 시간이 아니라, DB 커넥션, 외부 API 연동, 응답 데이터 생성까지를 포함한다. 결국 이 모든 항목의 병목을 파악하려면 구간별 실행 시간을 측정하고 분리 분석하는 능력이 필요하다.
특히 TPS(Transaction Per Second)를 기준으로 병목을 판단하는 관점은 실무에서 유용하다. 단순히 요청 수를 보는 것이 아니라, "얼마나 처리 완료됐는가?" 를 보는 기준은 진짜 서비스를 운영하는 입장에서 중요하다.
시간당 시스템 처리하는 작업량, TPS(transaction per second) or RPS(request per second) - 여기서는 주로 TPS ("처리 완료" 가 중요)
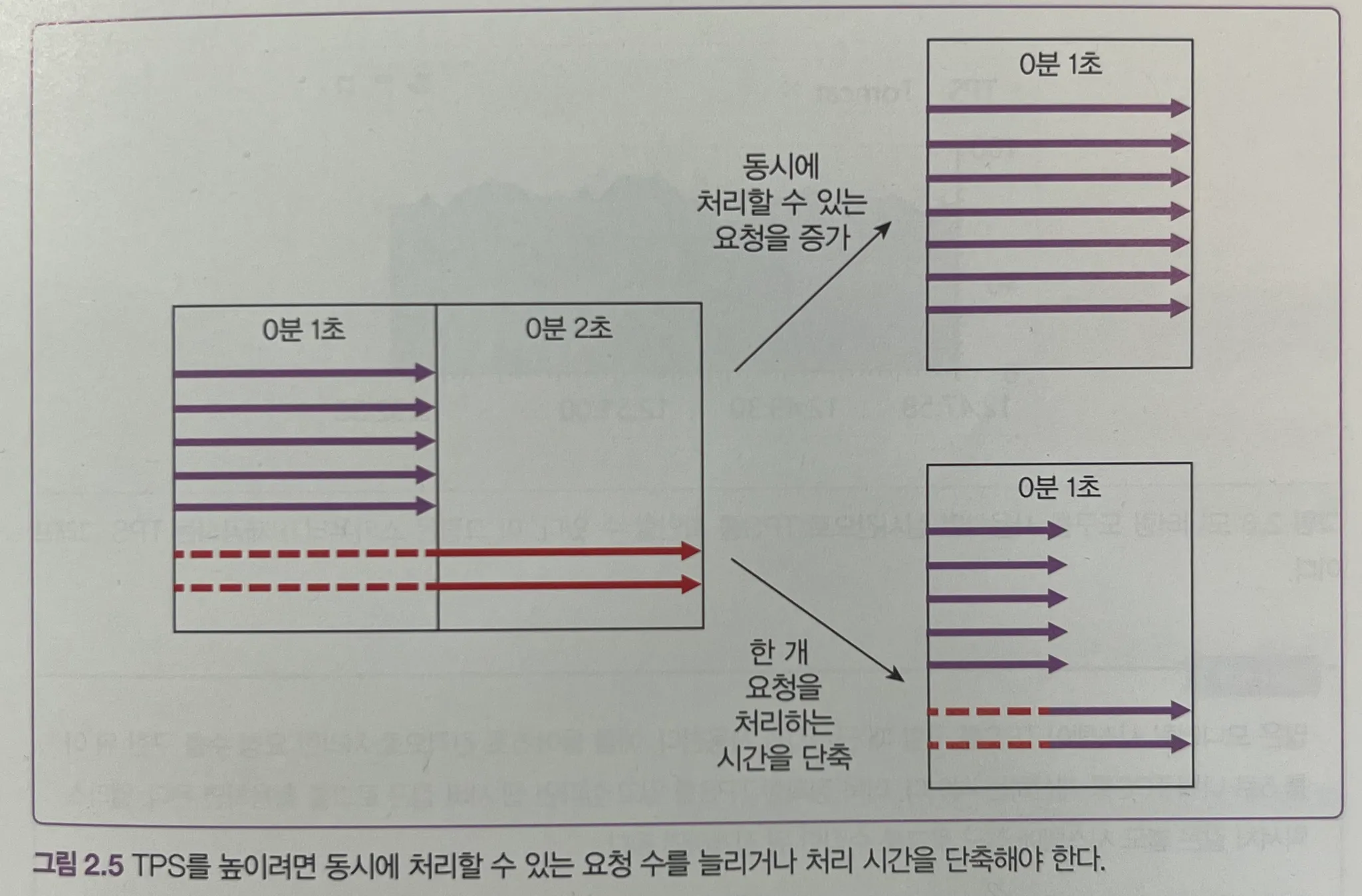
동시에 처리할 수 있는 요청을 증가 시키던지, 한 개 요청을 처리하는 시간을 단축 시키던지의 방향으로 TPS를 높여야 하고, 사실 측정을 위해서는 모니터링이 중요하다.
2) 서버 성능 개선 기초
서버의 성능 저하 증상은 다음과 같이 나타난다.
- 전체 응답 시간이 10초 이상으로 증가
- 연결 시간 초과
- 서버 재시작 후 일시 회복되나 반복 발생
이 경우 단순히 서버를 재시작하는 것으로는 근본적인 해결이 안 된다. 정확한 병목 지점을 찾아내야 하고, 이를 위해선 구간별 실행 시간을 측정 할 수 있어야 한다.
- 수직 확장(Scale-up): CPU, RAM 등을 늘려 한 서버의 스펙을 강화
- 수평 확장(Scale-out): 서버 대수를 늘리고, 로드밸런서를 통해 분산 처리
긴급한 상황에서는 수직 확장이 효과적일 수 있지만, 지속 가능한 확장은 수평 확장이며, 특히 다수의 요청을 안정적으로 처리하기 위해 필수적이다.
3) DB 커넥션 풀
DBMS도 결국 서버다. 요청이 들어올 때마다 DB에 새로 접속하면 비효율적이다. 그래서 DB 커넥션 풀을 이용해 일정 수의 커넥션을 유지하고 재활용한다. 커넥션 풀을 구성할 때 고려해야 할 주요 요소는 다음과 같다.
- 최대/최소 커넥션 수
- 커넥션 유지 시간 (타임아웃)
- 커넥션 대기 시간
(관련해서 Django 5.1의 커넥션 풀 적용기를 참고하면 실무 적용 힌트를 얻을 수 있다.)
예시로, 커넥션 풀 크기: 5, 쿼리 처리 시간: 0.1초 → 초당 최대 50쿼리 처리 가능하다.
대기 시간이 3초를 초과한다면, 요청을 거절하거나 "잠시 후 다시 시도" 메시지를 보내는 것이 더 나은 사용자 경험일 수 있다.
4) 캐시 전략
DB 조회 자체를 줄이기 위해 캐시를 도입하는 것도 병목 개선의 중요한 방법이다. 책에서 캐시의 크게 두 유형을 소개한다. 있다
- 로컬 캐시 (프로세스 내부 메모리 기반, 빠르지만 스케일링 어려움)
- 리모트 캐시 (redis 등 외부 서버, 느리지만 공유 가능)
각각 장단점이 정반대이므로 상황에 맞게 선택해야 한다. 예를 들어 트래픽이 순간적으로 튀는 경우에는, 사전에 데이터를 캐시에 미리 올려두는 "워밍(warming)" 전략이 유효하다.
단, 캐시 무효화(invalidation) 가 매우 중요하다. 원본 데이터가 변경되었을 때 캐시도 함께 갱신되거나 삭제되지 않으면 오히려 더 큰 문제가 된다.
대용량 API 응답 시에는 GC(Garbage Collection) 및 메모리 사용량도 주의해야 한다. Java에서는 스트림 방식, Go나 Rust로 전환하는 등 GC 부담을 줄이기 위한 다양한 접근이 있다. (디스코드 사례)
5) 응답 데이터 압축
응답 시간의 상당 부분은 데이터 전송 시간이 차지한다. 네트워크 속도는 제어하기 어렵지만, 전송할 데이터의 크기는 줄일 수 있다.
- HTML, CSS, JS, JSON과 같은 정적 텍스트는 gzip 압축 을 통해 최대 70%까지 줄일 수 있다.
- HTTP의
Accept-Encoding헤더를 통해 브라우저와 서버 간 압축 여부 협상이 가능하다.
이는 사용자 응답 속도 개선뿐 아니라 클라우드 전송 비용 절감에도 매우 효과적이다. 정적 파일은 가능하면 CDN을 활용해 가까운 곳에서 받아오게 하고, 브라우저 캐시를 최대한 활용해야 한다. 이 또한 응답 시간과 비용 모두를 줄이는 데 도움이 된다.
6) 대기 처리
일부 서비스는 특정 시간에 엄청난 트래픽이 몰린다. (ex. 콘서트 티켓 예매, 이벤트 시작 직후 등) 이때 단순한 스케일링(up or out)으로는 대응이 어렵고, 오히려 단순 비용만 증가할 수 있다. 따라서 "현재 수용 가능한 요청만 받고 나머지는 대기시키는" 방식이 실용적이다.
이런 방식은 마치 은행의 창구 번호표 시스템과 같다. 대표적인 방식은 유량 제어(rate limiting) 가 있고, 이는 보통 미들웨어나 클라이언트 사이드에서 구현한다.
3장 성능을 좌우하는 DB 설계와 쿼리
이 장은 신입이라면! 쿼리 실행 계획을 직접 비교해보며 따라가 보는 것을 추천한다! 예시도 실무에 맞게 잘 준비되어 있어 Follow-up 하며 익히기에 적절하다. PS) 개인적으로 너무 귀에 딱지가 앉은 내용들이라 많이 함축했다.
데이터 양이 조금만 많아져도 Full Table Scan 은 쿼리 성능에 큰 영향을 미친다. 이는 DB가 조건 없이 테이블의 모든 데이터를 순차적으로 읽는 방식인데, 단일 인덱스 또는 복합 인덱스를 적극적으로 활용해 피해야 한다.
- 단일 인덱스: 하나의 컬럼만을 기준으로 한 인덱스
- 복합 인덱스: 두 개 이상의 컬럼을 묶어 조건절에 활용
- 선택도가 높은 컬럼: 중복 값이 적은 컬럼일수록 인덱스 효과가 크다.
- 커버링 인덱스 (Covering Index): 실행하는 쿼리에 필요한 모든 컬럼을 포함한 인덱스.
- 예:
SELECT name, age FROM users WHERE email='abc@xyz.com'의 경우(email, name, age)로 인덱스를 구성하면 쿼리 수행 시 테이블을 접근하지 않아도 된다.
- 예:
다만, 인덱스는 추가/변경/삭제 연산 시마다 쓰기 성능에 오버헤드가 발생한다. 항상 트레이드오프를 고려해야 한다.
자주 호출되는 Aggregation 쿼리(합계, 카운트 등)는 실시간 계산보다 사전 집계해서 저장하는 방식이 효과적이다.
- 예: 사용자의 총 좋아요 수, 누적 조회수 등을 별도 필드에 미리 저장
- 단, 집계 값이 변경되는 트리거가 있는 경우, 동기화 로직이 필요하다.
서비스가 장기 운영되면 데이터 양이 계속 누적된다. 이 중 자주 조회되지 않는 오래된 데이터는 별도 테이블로 분리하거나, 이관/보관 처리하는 것이 효율적이다.
1) DB 인프라 확장 - Primary / Replica 구조
- 읽기와 쓰기 분리:
Primary는 쓰기 전용,Replica는 읽기 전용으로 나눠 부하를 분산 - 단, 아래와 같은 주의점이 존재한다:
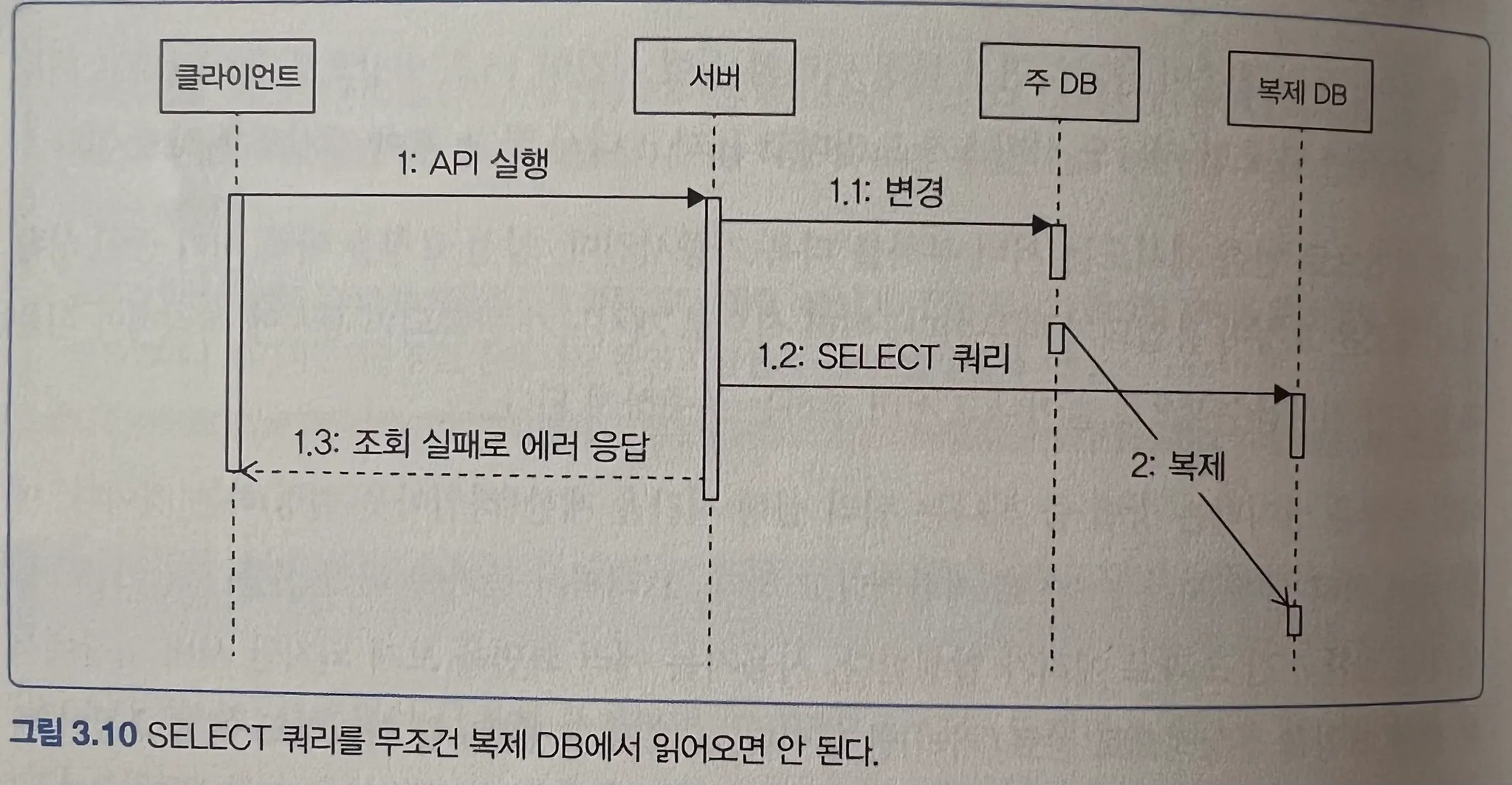
- Replica는 Primary의 변경 사항을 비동기적으로 복제하기 때문에, 지연이 발생한다.
- 따라서 인증/인가, 사용자 세션 등 실시간성이 중요한 SELECT는 반드시 Primary에서 수행해야 한다.
쿼리 타임아웃 & 배치 작업 시 청킹(Chunking)
- 장시간 실행되는 쿼리는 타임아웃을 유발할 수 있으므로, 대용량 데이터 처리 시에는 청크 단위로 나눠서 처리한다.
- 특히 배치 작업에서는 병렬 처리 또는 페이지 단위로 나눠서 로직을 구성하는 것이 필수적이다.
DBMS는 동시에 허용할 수 있는 최대 연결 수가 정해져 있다.
- 연결 수 초과는 전체 서비스에 장애를 유발할 수 있으므로, 커넥션 풀 또는 연결 수 제한 설정을 잘 조정해야 한다.
여러 데이터 수정이 정합성에 민감한 작업이라면 반드시 하나의 트랜잭션으로 묶어야 한다.
BEGIN → 작업들 → COMMITorROLLBACK- 트랜잭션을 적절히 활용하면 장애 복구 시에도 데이터 무결성을 보장할 수 있다.
2) 서비스 중인 DB 테이블 수정 시 특히 주의할 점
MySQL 은 테이블 구조를 변경할 때, 실제로는 새로운 테이블을 생성한 뒤, 기존 데이터를 복사하고, 이후 기존 테이블을 새 테이블로 교체하는 방식으로 작동한다.
- 이 과정에서
UPDATE,INSERT,DELETE등의 DML이 일시적으로 허용되지 않을 수 있다. - 운영 서비스에서 테이블 변경이 병목이나 서비스 중단으로 이어질 위험이 크다.
PostgreSQL 은 다행히 대부분의 구조 변경(ADD COLUMN, ALTER TYPE, RENAME 등)이 내부 메타데이터 변경으로 처리되어, Non-blocking(비차단) 방식으로 작동하는 경우가 많다. (PS. 이 책의 DBMS 기준은 대부분 MySQL 을 말한다.)
- 그러나 컬럼 타입 변경 등 일부 연산은 여전히 테이블 전체를 리라이트(재작성)할 수 있으므로 사전 확인 필요.
- 운영 중인 DB 테이블에 변경을 가할 경우, DBMS마다 동작 방식과 영향 범위가 다르므로 반드시 사전 검증이 필요하다. 무중단 배포를 위해서는 마이그레이션 절차의 자동화와 사전 롤백 시나리오도 함께 준비하는 것이 바람직하다.
4장 외부 연동이 문제일 때 살펴봐야 할 것들
외부 시스템이 우리보다 성능이 떨어지거나 트래픽을 감당하지 못할 경우가 많다. 이때 우리는 '서버'가 아니라 '클라이언트'가 되는 셈이다. 이 입장에서 체크 할 것을 알려주는 장이다.
1) 외부 API 호출시 타임아웃 설정은 필수
타임아웃이 설정되어 있지 않으면, 외부 API가 응답을 주지 않아도 무한정 기다리게 된다. 그 결과
- 전체 시스템 처리량이 급격히 하락하고
- 커넥션 풀 고갈 → 요청 처리 지연
- 최악의 경우 서비스 다운으로 이어진다
따라서 반드시 타임아웃을 명확히 설정해야 하며, 실무에서는 기본적으로 짧게(수 초 내외) 잡고, 예외적인 경우만 늘려야 한다.
2) 재시도(Retry) 전략
재시도는 단순히 '다시 해보자'가 아니라 조건과 설계가 중요한 전략이다.
책에서는 재시도 가능한 조건은 다음 세 가지를 제시한다.
- 단순 조회(읽기) 기능일 때
- 연결 타임아웃이 발생했을 때
- 멱등성(idempotent)을 보장하는 변경 기능일 때
읽기 타임아웃(read timeout)은 실제로 API 요청이 두 번 발생하게 되므로, 외부 비용(예: 과금)이 발생할 수 있으면 신중하게 판단해야 한다.
재시도는 ‘몇 번’, ‘얼마 간격으로’가 핵심이다. 무한 재시도는 곧 Retry Storm이라는 안티패턴으로 이어지며, 외부 시스템을 더 위험하게 만들 수 있다.
외부 API 호출에 제한이 있거나 트래픽 보호가 필요할 경우
- 초과 요청에 대해 503(Service Unavailable)을 즉시 응답
- 벌크헤드(Bulkhead) 패턴을 적용하여, 문제가 생긴 외부 API와 나머지 시스템이 영향을 분리하여 받도록 설계
3) 서킷 브레이커(Circuit Breaker)
전기 누전차단기처럼, 외부 시스템이 일정 횟수 이상 실패하면 즉시 실패(Fail Fast)로 전환해 전체 시스템을 보호하는 방식이다.
- 초기 상태: 닫힘(Closed) → 정상 호출
- 일정 실패율 이상: 열림(Open) → 호출 금지
- 일정 시간 후: 반열림(Half-Open) → 일부 호출로 상태 확인
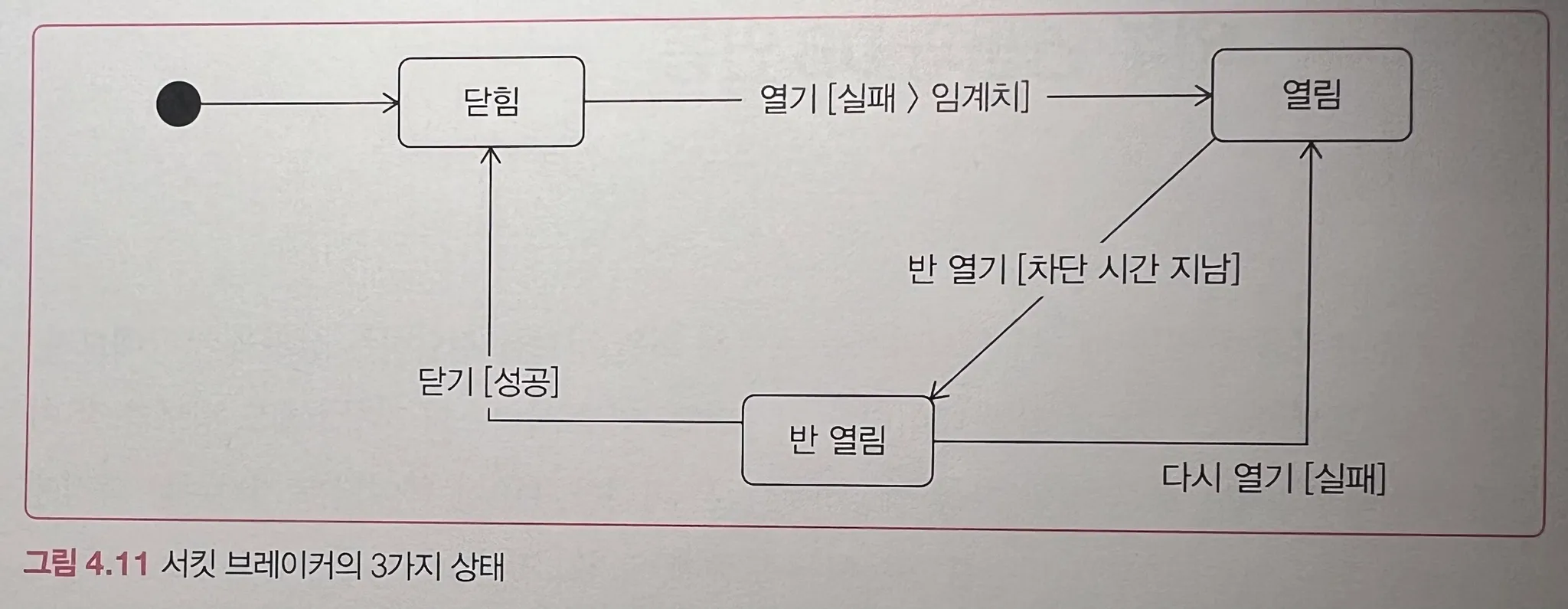
4) 외부 API 응답 지연과 DBMS 커넥션 고갈
외부 API의 응답이 늦어질 경우, 그 응답을 기다리는 동안 DB 커넥션을 점유하게 되면
1. DBMS 커넥션 풀이 고갈되고
2. 후속 요청들은 대기 → 응답 시간 증가
3. 결국 타임아웃 및 서비스 에러로 이어짐
커넥션은 최대한 빨리 반납하는 게 핵심이다. 외부 연동과 DB 작업은 명확히 분리하고, 가능하면 응답 대기 전에 커넥션부터 반납해야 한다.
5) HTTP 커넥션 풀과 웹서버 고려
웹서버 레벨에서의 커넥션 풀 관리도 중요하다. 예를 들어, keep-alive 설정이 적절치 않으면 서버 리소스를 불필요하게 점유하게 된다. 클라이언트와의 커넥션도 ‘적절한 수명과 갯수 제한’이 필수다.
5장 비동기 연동, 언제 어떻게 써야 할까
개인적으로 5장부터 7장은 처음 개발을 배우던 나에게 항상 "벽" 처럼 느껴졌던 부분이다. 동기와 비동기, "왜 비동기 처리를 하지?" 부터 비동기 처리하면서 고민해야 할 동시성 이슈, 또한 동시 실행에 대한 제어와 제한 이 모든게 따라온다.
참고로 대부분의 예시는 java 이다. python 에서도 사실 코루틴, 경량 스레드 (또는 직접 thread를 만드는) 측면에서 아주 동일하게 접근 가능하며, 더욱이 node 는 Asynchronous (이벤트 루프) 자체에 집중하고 따라가면 될 것 같다.
5장은 아래 사진 한 장이 시작이자 끝이다 ㅎ
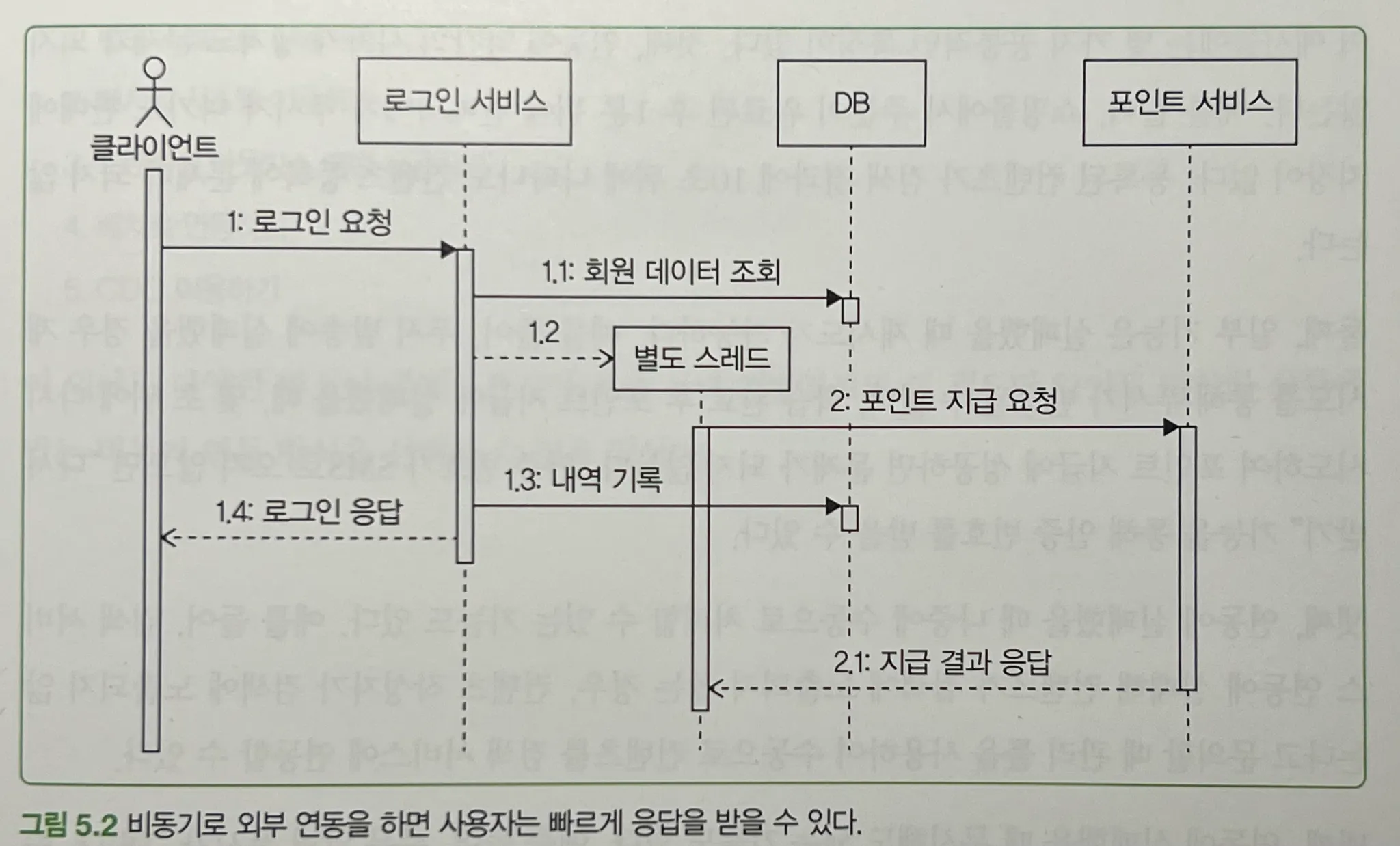
- 쇼핑몰에서 주문이 들어오면 판매자에게 푸시 보내기
- 학습을 완료하면 학생에게 포인트 지급하기
- 컨텐츠 등록할 때 검색 서비스에도 등록하기
- 인증 번호를 요청하면 SMS로 인증 메시지 발송하기
등 위 케이스에서 API 가 "동기" 로 응답 또는 외부 서비스 (API) 응답까지 기다릴 필요가 있을까? 이 부분 부터 시작이다. 대게 아래와 같은 특징을 가진다.
- 연동의 시차가 생겨도 문제가 크지 않다.
- 실패했을 때 재시도가 가능하다.
- 나중에 수동으로 처리해도 크리티컬하지 않다.
- 실패해도 무시해도 된다. (단순 알림)
이러한 전제를 바탕으로, 이 책은 여러 실전적 비동기 처리 방식들을 소개한다.
1) 별도 스레드로 실행하기
대표적인 예시로는 Spring Framework의 @Async 어노테이션을 통해 특정 메서드를 비동기 실행하는 방법이 있다. 다만 주의할 점은 다음과 같다:
try-catch구문 사이에 비동기 코드가 껴 있으면 에러 전파가 안된다- 즉, 트랜잭션 롤백이 되지 않음 → 호출부가 아닌 정의부에서 에러처리 필요
- 그리고 중요한 사실: 스레드는 메모리를 많이 사용한다
이러한 점을 간과하면 비동기 처리가 오히려 시스템 리소스를 잡아먹는 병목이 될 수 있다.
2) 메시징
아주 주관적으로 나의 경우 "메시징 시스템, 이벤트 기반 아키텍쳐" 를 배우고 이해하는 순간 진짜 새로운 세계가 열렸던 기분이 들었었다. (메시징 관련 시리즈 보러가기)
Producer: 메시지를 발행
Consumer: 메시지를 구독하고 처리
- Producer는 유실에 대비해야 하며, 타임아웃과 실패에 대한 에러 처리 로직을 마련해야 한다.
- 예를 들어, 재시도할 수도 있지만, 중복 처리를 피하기 위한 고유 식별자 부여가 필수적이다.
- 재시도 → 중복 → 소비자 쪽에서 idempotent하게 처리
- 로그를 남긴다면 후처리 가능한 형태의 데이터로 남겨야 한다
메시지는 일반적으로 아래 2가지로 개념적 분리를 한다
- 이벤트(Event): "무엇이 발생했다"를 알리는 것 (ex: 주문됨, 배송완료됨)
- 커맨드(Command): "무엇을 해달라"는 요청 (ex: 포인트 지급)
3) 글로벌 트랜잭션이 필요한 이유
단일 서비스에서 여러 리소스를 조작할 때, 또는 분산 환경에서 여러 DB나 시스템을 하나의 트랜잭션처럼 다뤄야 할 때 등장하는 개념이 바로 글로벌 트랜잭션이다.
- 사용자가 상품을 주문하면,
- 주문 DB에 저장하고
- 동시에 푸시 알림을 메시지 큐에 넣어야 함
- 그런데 푸시 메시지를 먼저 보냈는데 주문이 실패했다면?
- 알림은 갔지만 실제 주문은 존재하지 않는 비정상 상태가 된다. → 이를 방지하려면 글로벌 트랜잭션(2PC 또는 Outbox 패턴) 같은 처리가 필요하다.
위 상황을 아래와 같이 접근할 수 있다.
- 주문 처리 트랜잭션이 끝난 후, 메시지를 메시지 큐에 전파
- 메시지 큐에 넣는 로직은 트랜잭션 외부에서 처리
- Outbox 테이블에 먼저 메시지를 적재한 후, 커밋 후에 큐로 전달
4) 궁극적 일관성
분산 시스템의 핵심 개념 중 하나다.
- 데이터 복제가 실시간은 아니지만, 결국 언젠가는 일치하는 상태에 도달한다
- 이 과정에서 일시적 불일치가 발생할 수 있음 → 비동기 메시징도 이와 유사
5) CDC(Change Data Capture)
- DB의 변경사항을 감지하여, 외부 시스템과 연동하는 비동기 처리 기술
- 예시: Postgres → Kafka → ELK Stack으로 전파
- 실제로 아래 두 글에서 Logstash 기반의 CDC 와 Debezium 기반 CDC, 아래 2가지 글을 작성한 적이 있는데 해당 책 내용과 참조하면 많은(?) 도움이 되지 않을까 한다 ㅎㅎ
- Elasticsearch - ELK stack & Postgresql & Logstash, query based CDC 만들기 by docker compose
- 카프카 클러스터와 파이썬 (2) - Debezium & Postgresql & Django, log based CDC 만들기 (source & sink connector)
6장 동시성, 데이터가 꼬이기 전에 잡아야 한다
서버가 동시에 들어오는 수많은 요청을 어떻게 처리할 것인가는 백엔드 실무에서 매우 중요한 주제다. 특히 하나의 공유 자원에 여러 요청이 동시에 접근하게 되면, "동시성(concurrency)" 문제가 발생하고, 이는 쉽게 데이터 꼬임 또는 경쟁 상태(race condition) 로 이어질 수 있다.
대표적인 예로는 투표 시스템이 있다. 특정 API에 요청이 몰릴 경우, 실제로는 투표 수가 100번 증가했어야 하는데, 중간에 요청이 섞이며 50번만 반영되는 식의 문제다. 이런 문제를 피하기 위한 동시성 제어는 시스템 전반에서 이루어져야 한다.
1) 프로세스 수준에서의 동시 접근 제어
서버는 일반적으로 다음 두 가지 방식 중 하나로 동시 요청을 처리한다:
- 스레드 기반 처리: 각 요청마다 독립된 스레드를 생성하거나 할당하여 처리
- 비동기 IO 기반 처리: 이벤트 루프 기반으로, IO 작업이 완료될 때 콜백으로 응답을 처리
공유 자원에 대한 접근은 반드시 임계 영역(critical section)을 정의하고, 해당 영역에 접근하는 코드에 대해서는 락(lock)을 걸어야 한다. 이 흐름은 다음과 같다:
잠금 획득 → 임계 영역 접근 → 잠금 해제
Java에서는 synchronized, ReentrantLock 등이 활용되고, 이를 일반화하면 mutex(mutual exclusion)라 한다.
또한 세마포어(semaphore)를 활용하면, 특정 자원에 동시 접근 가능한 스레드 수를 제한할 수 있다. 예를 들어, Velog Dashboard V2의 비동기 배치 시스템 에서는 세마포어 형태로 최대 요청 수를 제한하고 있다.
또 하나의 좋은 전략은 아예 공유 자원을 사용하지 않는 것, 즉 불변(immutable) 객체를 사용하는 방식이다. 불변 객체는 상태 변경 자체가 없으므로 동시 접근 제어가 필요 없다.
2) DB와 관련된 동시성 제어
동시성 문제는 DB에서도 동일하게 나타난다. 이에 대한 대표적인 접근법은 아래 두 가지로 나뉜다:
-
비관적 잠금(Pessimistic Locking)
- "실패할 가능성이 높다"는 가정 하에, 미리 다른 접근을 막는 방식
→ 데이터에 베타적 잠금(exclusive lock)을 걸어, 한 번에 하나의 클라이언트만 접근 가능
- "실패할 가능성이 높다"는 가정 하에, 미리 다른 접근을 막는 방식
-
낙관적 잠금(Optimistic Locking)
- "성공할 가능성이 높다"는 가정 하에, 변경 전후 값을 비교해 충돌 여부를 판단
→ 실제 락 없이version필드나updated_at비교로 처리
- "성공할 가능성이 높다"는 가정 하에, 변경 전후 값을 비교해 충돌 여부를 판단
특히 트랜잭션 범위 내에서 외부 시스템(예: PG사, 결제 API)과 연동해야 하는 경우에는, 비선점 낙관적 방식보다는 선점 비관적 방식이 더 안전하다. 예컨대 결제 취소까지 함께 고려되어야 한다면, 먼저 확실하게 잠금을 걸어야 한다.
또한 증분 쿼리 방식(예: UPDATE SET count = count + 1)은 DBMS가 원자적으로 처리해주는지를 반드시 확인해야 한다. 일부 DB는 이조차도 race condition을 일으킬 수 있다.
3) 잠금 사용 시 주의 사항
잠금을 사용할 때 반드시 고려해야 할 중요한 이슈는 다음과 같다!
-
잠금은 반드시 해제되어야 한다.
잠금을 놓치면, 해당 자원은 영구적으로 접근 불가해지며 시스템이 멈춘다. -
대기 시간 설정을 명확히 해야 한다.
무한 대기 대신timeout을 명시해줘야 대기하는 스레드가 적절히 포기할 수 있다. -
교착 상태(deadlock)를 피하자.
예: 스레드 A는 잠금 X를 가지고 Y를 기다리고, 스레드 B는 Y를 가지고 X를 기다리는 상황
→ 이를 피하기 위해 잠금 순서를 일관되게 정하거나, 타임아웃 및 실패 처리 로직을 함께 두는 것이 중요하다.
4) 동시성 회피 전략: 단일 스레드 처리
사실상 가장 간단하고 강력한 전략은 바로 단일 스레드 처리(single-threaded processing) 이다.
예를 들어, Redis 기반 큐, Kafka consumer group, Node.js의 이벤트 루프 모델 등은 모두 기본적으로 단일 스레드 방식으로 설계되어 동시성 문제 자체를 회피하는 전략이다.
7장 IO 병목, 어떻게 해결하지에서는
- 네트워크 IO 에 대한 이해와 자원 효율화, 특히 가상 스레드 얘기,
- 논블로킹 IO 로 성능 올리는 방법과 언제 무엇을 트레이드 오프하냐에 대한 얘기를 다룬다.
8장 실무에서 꼭 필요한 보안 지식에서는
- 인증과 인가부터 토근 보안, RBAC(Role Based Access Control) 구조, 데이터 암호화,
- Hash-based Message Authentication Code (무결성 인증 보장), 방화벽, 감사 로그, 비정상 접근 처리를 다룬다.
9장 최소한 알고 있어야 할 서버 지식에서는
- 대부분 OS 와 shell 기반 인프라 관리에 대한 얘기이며, 진짜 이 정도 기본은 해야한다고 매우 동감하는 장이었다.
- OS 계정과 권한, 프로세스 체크, 디스크 관리, File Descriptor, 서버 timezone, cron(tab),
- alias, 네트워크 정보 체크 (ifconfig, netstat 등) 를 다룬다.
10장 모르면 답답해지는 네트워크 기초, 11장 자주 쓰는 서버 구조와 설계 패턴를 넘어 부록까지 너무 알차다. 진짜 딱 신입오면 너무 주고싶은 책이다.
사실 이제 사무실에 이 책을 두고 새로 오시는 분에게 꼭 찔러주고 싶다. 이걸로 온보딩 과제를 만들어 볼까도 싶다 ㅎ
