[ 글의 목적: promtail을 실운영 서비스에 적용하면서 생길 수 있는 사소한 이슈와 해결에 대한 정리 ]
Logrotate & Promtail
리눅스 로그 에서 소개한 logrotate 와 Django의 PLK stack 에서 소개한 promtail 의 충돌에 대한 애기이다. 두 프로그램을 사용한적이 없다면, "해당 링크 클릭"으로 가볍게 먼저 읽어볼 수 있다.
1. 이슈 전체 시나리오
promtail의 수집 대상의 logging file을logrotate가 daily로 압축 처리하는 바람에promtail이 기억하는positions.yaml을 갈아엎어야 하는 상황이다.
1) 서버 구성
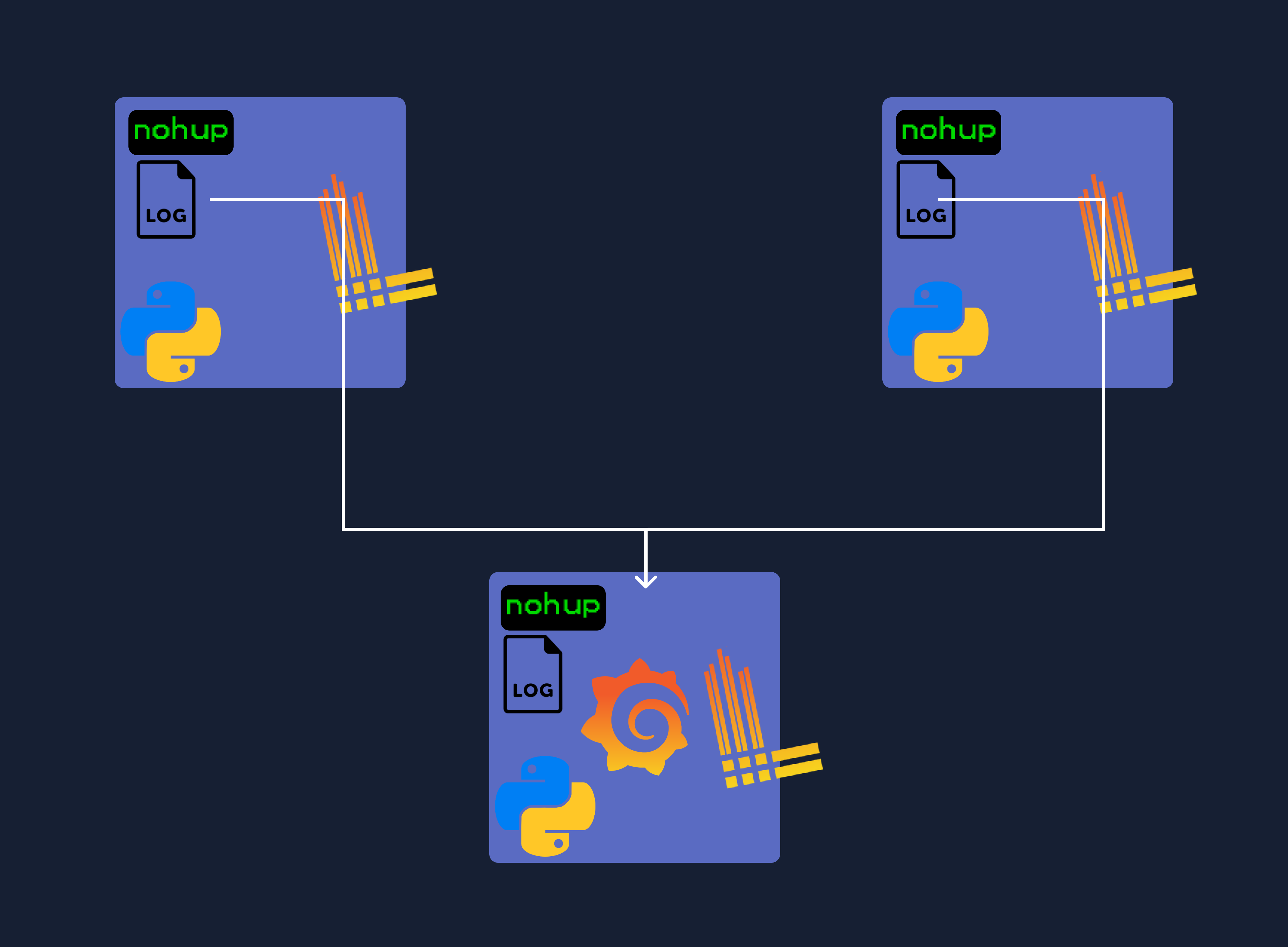
host 컴퓨터 자체가 꽤 짱짱한 (러프한 사양으로는 CPU 16코어 이상 & 50G 램 이상의) 3대의 서버에서 python 기반의 분산 데이터스크레이핑 프로그램이 무한히 돌고 있다. python 기반 서비스는 [ 단일 프로세스 실행 + 멀티프로그래밍 & 코루틴 ] 의 형태로 이뤄져 있고, 실행 스크립트를 기반으로 돌아간다.
완전하게 private한 서비스라 admin에서 "로그 확인을 위해 각 서버에 TCP로 붙어서 file을 read 하도록" 만들어져 있었다. 로그 모니터링이 사실 거의 필요없었던 터라, 수집이 잘 안될때 사후 처리용으로 쌓는 로그정도였다. 아래와 같이 로그파일이 디렉토리에 쌓인다.

(분산 서버 디렉토리를 보기 좋게 합쳐서, 모자이크 & 가시화 한 이미지입니다)
2) Promtail 구성
최근에 전체 로그 포괄 모니터링의 니즈로 인해, 2번째 서버에 PLG stack을 구성하고, ops-docker-compose 를 구성해 각 서버에 세팅을 했다.
version: "3.5"
services:
prometheus:
image: prom/prometheus
hostname: "${HOST_NAME}-prometheus"
container_name: prometheus
volumes:
- ../prometheus:/etc/prometheus
- ../prometheus/data:/prometheus
command:
- "--config.file=/etc/prometheus/prometheus.yaml"
- "--storage.tsdb.path=/prometheus"
- "--web.enable-lifecycle"
ports:
- "9090:9090"
networks:
- crawler-ops-network
node-exporter:
image: prom/node-exporter
hostname: "${HOST_NAME}-node-exporter"
container_name: node-exporter
ports:
- "9100:9100"
networks:
- crawler-ops-network
promtail:
image: grafana/promtail
hostname: promtail
container_name: promtail
volumes:
- ../promtail:/etc/promtail
- ../domain:/var/crawler
- /var/log:/var/log
command:
- "-config.file=/etc/promtail/promtail.yaml"
networks:
- crawler-ops-network
networks:
crawler-ops-network:
driver: bridge(운영 정보를 담은 설정은 제외했지만, 이 상태 그대로 러닝가능하다.) 위와 같은 compose file로 구성되어 있었고, 2번째 서버에만 Grafana + Loki 까지 얹어서 2번째 서버에 모두 수집되도록 세팅했다.
promtail config
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /etc/promtail/positions.yaml
clients:
- url: ...
scrape_configs:
...
- job_name: python_apps
static_configs:
- targets:
- localhost
labels:
job: python-logs
__path__: /.../crawler/*/nohup.log운영과 관련된 부분은 조금 모자이크를 했다. 여튼 __path__ 에 와일드카드를 기반으로 nohub.log 로 나오는 모든 log file을 promtail로 가져오려고 했고, 그에 따라 positions.yaml 파일은 아래와 같이 형성된다. (예시)
positions:
/.../crawler/a/nohup.log: "330403"
/.../crawler/b/nohup.log: "110820"
/.../crawler/c/nohup.log: "42633"
/.../crawler/d/nohup.log: "9542"
# ...생략...
/var/log/system.log: "55792"
# ...생략...3) Logrotate 구성
/.../crawler/.../**/*.log {
create 0644 nobody root
daily
size 1000M
dateext
dateformat %Y-%m-%d-%s
rotate 3
copytruncate
delaycompress
compress
notifempty
missingok
}위 설정은 쉽게, [ 매일 매일 특정 경로에 생성되는 모든 *.log 파일 대상으로, 1000MB 이상인 파일을 특정 이름으로 압축하고, 3개를 넘어가면 삭제하는 ] 세팅이다.
여기서 문제가 발생한다.
logrotate: "어후 하루에 너 로그만 1G가가 넘게 쌓이냐 압축맞아라"- as-is
/.../crawler/a/nohup.log 1600MB - to-be
/.../crawler/a/nohup.log2023-11-28.gz 100MB&/.../crawler/a/nohup.log 0MB
- as-is
promtail: "뭐야? 왜 내가 110820 까지 읽던 로그파일 내용 어디갔어..?" 0줄부터 시작하네,,?positions.yaml내용의 라인넘버가 올때까지 기다려야 겠네
loki: "왜 로그를 안주니..?"grafana: 아래 사진으로 대체
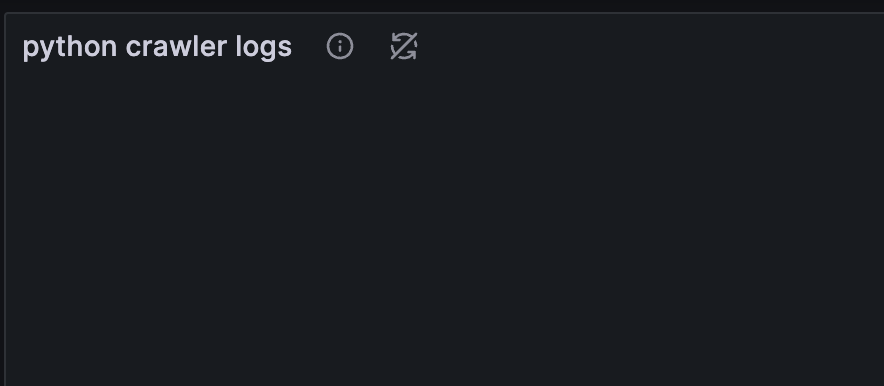
데이터스크레이핑 프로세스 상태 체크를 하는 프로세스가 따로 있는데 logs 가 비어있는 것을 보고 순간 찐으로 당황했다. 내가 지금 실시간으로 관리하는 서버가 아니라 과거부터 구축해서 간간이 매니징만 하는 서버이다 보니, 멈추면 분명 칼같이 SOS 전화가 올텐데 이렇게 고요하다고? 서비스는 잘 구동중인데.. 새로 도입한 promtail 설정이 문제였던 것이다.
4) Promtail은 기본적으로 파일의 inode를 추적하여 로그를 읽는다.
Inode 란 리눅스나 유닉스 파일시스템에서 소유권, 데이터의 물리적 주소, 링크, 파일 타입, 크기, CMA(create, modify, access) 시간 등 파일의 모든 정보를 갖고 있는 구조체 를 가리킨다.
일반적으로 한 개의 inode는 한 개의 파일(리눅스와 유닉스에서는 파일과 디렉토리 등을 모두 파일로 본다)과 같고(하드 링크로 파일을 생성하면 inode가 중복되는데 이때 동일한 inode는 inode 카운터에 포함되지 않고 단일 inode로 본다), 가용한 inode의 개수는 디스크의 용량에 따라 결정된다. 일반적으로 한 inode당 4096byte를 가지고 있지만 이는 조정할 수 있다.
리눅스에서 파일이나 디렉토리를 삭제하는 것은 물리적으로 데이터를 지우는 것이 아니라 이 inode와 물리적 데이터 간의 연결고리(주소)를 끊어줌으로써 삭제된 것처럼 보이게 하는 것이다. 그래서 파일 복구시 이 inode와 물리적 데이터 간의 주소만 다시 연결시켜 주면 데이터를 복구할 수 있다.
2. 해결
1) 방법에 대한 고민
-
logrotate 설정을 조정하여 nohup.log가 로테이트될 때 "특정 스크립트를 실행하도록 하기", 예를 들어, postrotate 스크립트를 사용하여 Promtail을 재시작하거나 SIGHUP 신호를 보내어 새 파일을 읽도록 등
-
Logrotate의 Copytruncate 관련 설정값 세팅: logrotate의 copytruncate 옵션을 사용하면 로그 파일을 복사한 후 원본 파일을 줄이는 방식으로 로테이션을 수행하기. 이 방법을 사용하면 파일의 inode가 변경되지 않으므로 Promtail이 계속해서 같은 파일을 추적할 수 있다.
-
추가적인 라벨링: nohup.log 파일의 로테이션이 발생할 때, 새로 생성된 파일에 대해 다른 라벨을 부여하여 Promtail이 새 파일을 별개의 스트림으로 인식하도록 하기.
-
압축된 로그 처리: Promtail 설정에
pipeline_stages를 추가해 압축된 로그 파일을 읽고 처리할 수 있는 파이프라인을 구성하기. 이를 통해 압축된 로그 파일을 Promtail이 직접 처리하도록 할 수 있다.
등의 여러가지 해결에 대해 리스트업 했다. 일단 각 host서버에 쿠버네티스로 세팅되어 pod 마냥 뜨는게 아니다. [ 클라우드서버에 코어 시스템은 온프램으로 구축되어 있고, 여타 서비스들이 도커라이징된 형태로 구성 ] 되어 있다. IaC 와 같은 것도 없다 그래서 "로그 생성 자체에 대한 방법 변경" 은 시스템의 많은 부분을 바꿔야 할 수 있어서 제외했다.
-
"2번" 의 경우 언젠간 그래도 해당 로그 파일을 비워야하고, (보통 생명주기를 7일, 1주일로 보았다) 그때 같은 문제가 발생할 것이다. 그리고 2번 관련 이슈는 아래에 다시 언급한다.
-
"3번" 의 경우 그냥 매번 새로운 라벨링이라 원하는 형태가 아니었다,,
-
"4번" 의 경우 굉장히 솔깃했지만 실시간 로그 수집이 아니라 과거 로그 수집기가 되어버린다.. 사실 이래도 상관없는데 이러면 PLG stack을 왜 도입했지,, 사실 스스로가 운영 실시간 디버깅을 더 쉽게 하려는 목적도 있었었다..
여기서 잠깐
logrotate 의 copytruncate 작동 방법 (logrotate, copytruncate의 함정 글 참조) 을 생각해보면 "원본 파일은 그대로 둔다" 이 핵심이기 때문에 promtail 에겐 바뀌지 않은 inode 자체가 문제가 된 것이다.. inode가 바뀌었다면 promtail이 새파일이라고 인식하게 된다.
2) 실제 시도한 방법
언급한 "1번" 방법으로 접근했다. copytruncate 설정을 바꿀수는 없었다. 분산 데이터 스크레이핑 코어 시스템은 일단 While True 이고 이런 과정에 logfile을 특정 시그널 없이 바로 처리하면 바로 로그 손실이 되며, file read에 대한 어떤 기능이 있다면 바로 I/O issue가 발생할 수 있다.
그래서 shell script를 그냥 만들어서 logrotate 가 로테이팅 이후 해당 script를 실행하게 하는 방향으로 결정했다.
1차 bash script 작성하기
#!/bin/bash
# positions.yaml 파일의 경로를 정의
POSITIONS_FILE="/path/to/promtail/positions.yaml"
# positions.yaml 파일을 임시 파일로 복사
cp $POSITIONS_FILE "${POSITIONS_FILE}.tmp"
# 각 nohup.log 파일에 대해 positions.yaml.tmp 파일을 업데이트
# 각 포지션 값을 그냥 0으로 설정
for log_path in $(grep -o '/...생략.../crawler/.*/nohup.log' $POSITIONS_FILE); do
sed -i "s|${log_path}.*|${log_path}: 0|" "${POSITIONS_FILE}.tmp"
done
# 임시 파일을 원본 파일로 대체
mv "${POSITIONS_FILE}.tmp" $POSITIONS_FILE
# Promtail 서비스 재시작
# ... docker compose 실행 ...-
아차 모든 로그가 무조건 압축되는 것이 아니다
logrotate설정을size 1000M로 잡았기 때문에 1G가 안넘는 친구들은 압축 대상에서 제외되며 해당 Log 마저 저렇게 강제로 바꾸면 안된다..점점 아찔한데 이게 맞나 싶어졌다 -
그러면 "압축이 된 nohub.log를" 알고, 그 "압축된 nohub.log 경로 file 값만 초기화" 해야 한다.
2차 bash script 작성하기
logrotate에 의해 로그가 압축이 된다면,dateformat설정값에 의해 "해당 날짜값이 이름" 에 들어간다.- 그러니 logrotate 가 running되는 그 날짜 값에 맞는 형태의 압축 파일이 만들어진 path 만 배열에 저장한다.
- 그리고 그 배열에 저장된 값만 position 값을 0으로 세팅하고, 그 외의 값은 그대로 가져간다.
- 그리고 다시 시작한다.
여기서 의문
copytruncate 는 "일단 복사를 하는 행위" 가 먼저 발생하기 때문에, "gz" 가 만들어지기까지 시간이 걸릴 수 있다.. 그러면 postrotate (logrotate가 실행된 이후 액션) 은 "복사와 압축 등의 행위가 모두 끝난 뒤에 하는 것인가?" 에 대한 의문이 있었다.
즉 복사 또는 압축 등이 시작하고 postrotate 로 세팅된 shell 을 실행하면 아직 gz 가 만들어지기 전이기 때문에 위 로직이 의미가 없어진다. 이 의문은 linux command man official page 에서 확인 할 수 있다. 결론은 모든 logrotate의 작업(복사, 압축, 삭제 등)이 완료된 후에 발생 한다는 것이다. 이렇게 완성된 script는 아래와 같다.
#!/bin/bash
# positions.yaml 파일의 경로를 정의
POSITIONS_FILE="/.../positions.yaml"
# 오늘 날짜 - logrotate의 dateformat 설정과 일치하도록 변수 세팅
TODAY=$(date +%Y-%m-%d)
# 로그 디렉토리를 정의
LOG_DIR="/.../crawler"
# 오늘 생성된 로그 파일 압축판의 경로를 저장할 배열을 초기화
declare -a UPDATED_LOG_PATHS
# 오늘 생성된 압축 대상 파일을 찾고, 해당 로그 파일의 경로를 배열에 저장
find $LOG_DIR -type f -name "*$TODAY*" -exec dirname {} \; | while read dir_path; do
log_path="$dir_path/nohup.log"
if [[ -f $log_path ]]; then
UPDATED_LOG_PATHS+=("$log_path")
fi
done
# echo "${UPDATED_LOG_PATHS[@]}" # 디버깅 전용
# positions.yaml 파일을 임시 파일로 복사
cp $POSITIONS_FILE "${POSITIONS_FILE}.tmp"
# 배열에 저장된 로그 파일의 위치를 positions.yaml.tmp에서 0으로 세팅
for log_path in "${UPDATED_LOG_PATHS[@]}"; do
sed -i "s|${log_path}.*|${log_path}: \"0\"|" "${POSITIONS_FILE}.tmp"
done
# 임시 파일을 원본 파일로 대체
mv "${POSITIONS_FILE}.tmp" $POSITIONS_FILE
# 재시작 ... 생략 ...그리고 재시작은 원본 파일로 대체 하기 전에 stop 하고 대체 한 뒤에 다시 시작해야 한다.
여기서 굉장히 빡셋던 부분은 logrotate 이 "positions.yaml" 파일과 "재시작" 관련 실행 권한이 있느냐? 이다. 특히 쉘스크립트 디버깅을 하는 과정에서 러프하게 권한을 생각하고 있다가 운영에 엄격하게 적용하다보니,, 항상 유저와 권한 핸들링이 개빡세다
그리고 docker compose로 promtail 관련된 ops들이 러닝하다보니 볼륨(내부 경로)가 실제 절대 경로와 다르다,, 후,, 해당 부분도 굉장히... 이 방법이 굉장히 섹시하지 못하다.
3) 다시 처음으로
위 방법이 권한과 서버 개별 설정도 필요해서 굉장히 섹시하지 못한 방법임을 깨달았다. 서비스 코드를 건들지 않고 logrotate 와 promtail 만 건들꺼면
logrotate 의 copytruncate 설정값을 create 로 해서 file이 새로운 inode 번호를 가지게 한 뒤 docker compose (promtail restart) 를 다시 시작하도록 하는게 더 쉽고 복잡하지 않은 방법이라는 생각이 들었다.
[ 1) 방법에 대한 고민 - 3번 추가적인 라벨링 으로 처리하기 ]
위에서 언급한 "추가적인 라벨링" 으로 접근하려고 한다. 즉, 서비스 로깅 자체를 rotate로 가져가는게 좋을 것 같다. python logging 는 TimedRotatingFileHandler 를 통해 "로그 파일이 특정 크기에 도달했을 때 새 파일을 생성" 하는 방향으로 세팅할 수 있다.
처음부터 왜 그렇게 세팅하지 못했나?
- 로그파일 적재가 중요하지 않은 서비스 였다. 이미 핵심 이슈나 예상되는 이슈는 모두 처리가 되어 있기 때문에 대응 개발이 필요한 경우는 따로 alert 가 되어 있다.
- python 프로세스가 개별 실행 + 멀프 으로 돌아가기 때문에 로그파일을 다 따로 떨군다. 처음 구현시 흩어진 로깅은 오히려 디버깅 & 개발에 방해가 되었다.
- 그래서 로그파일이 디스크먹는걸 막기 위해서만을 위한 목적으로
logrotate가 세팅이 되었다. - admin에서는 [와일드 카드 & 패턴 /
nohub.log] file을 대상으로 그냥 tail 결과값과 동일하게 읽어서 보여준다.
TimedRotatingFileHandler 세팅하기
TimedRotatingFileHandler 를 세팅하면 (1) 서비스 logging 로직 (2) admin log file read login (3) logrotate 쓸모없음 (4) promtail config 4가지를 바꿔야 한다.

아니 선생님.. ops 도입은 나를 위해서 했는데 왜 일이 더 많아진거요?
어쩌면 promtail 도입이 역행이 아니었는가 싶기도 하지만, 이를 계기로 서비스의 전체적인 완성도가 한층 올라갔고, 추가 확장에 훨씬 용이해졌다.
import logging
from logging.handlers import TimedRotatingFileHandler
...생략...
# logging set config
time_rotating_file_handler = TimedRotatingFileHandler(
"nohup.log", encoding="utf-8", when="midnight", interval=1, backupCount=7
)
formatter = ...
time_rotating_file_handler.setFormatter(formatter)
logging.basicConfig(level=logging.INFO, handlers=[time_rotating_file_handler])
...생략...python official docs / 위와 같이 세팅하면 가장 최신의 로그파일은 nohup.log 이라는 이름으로 작성되어 지고, 자정에 application.log.2023-01-01 와 같은 이름으로 만들어진다. 그리고 nohup.log 라는 로그 파일이 새로 만들어지는 것과 같기 때문에 (file의 inode값 변경) promtail 에서는 다른 파일로 간주하고 positions.yaml 업데이트 하고 읽는다.
이렇게 세팅하면 사실 promtail 설정과 admin log API 변경은 할 필요가 없어진다. 서비스 로깅 업데이트만 하고 logrotate 설정만 삭제하면 된다.
단점은 "서비스와 독립적으로 OS 데몬 레벨에서 관리되던 것" 들이 "python applicaiton level에서 관리되도록" 바뀐다. 즉, 저 로그 파일로테이팅은 python code가 러닝이 안되면 절대 로테이팅이 안된다.
여기서는 쉽게 말했지만, 사실 운영에 해당 세팅을 하기위한 사전 작업들이 꽤 많이 필요하다..

벨로그 데시보드 배포 전부터 봤었어요! 이번글도 좋네요 감사합니다 화이팅 :)