
web scraping with python (o'reilly)
기술서적을 인문학책 처럼 가볍게 리뷰를 하려고 한다,, 사실 이 책에서 분산 크롤러 서버 아키텍쳐에 대한 인사이트를 얻고 싶었지만, 책은 이제 막 크롤러 개발을 시작한 사람들을 독자로 타겟팅 했다. 하지만 "무엇이 가장 중요하고 어떻게 접근을 해야할지" 기본만큼은 확실하게 짚어준다. 스크레이핑 & 크롤링 분야의 전체적인 이야기와 토픽을 하나씩 정리하며 독자에게 어디를 깊게 각자 공부해야할지 알려주는 이정표 같은 느낌의 책이다. [ 스크레이핑과 크롤링은 다르다! ] 가 와닿지 않는다면 이 책을 과감하게 추천한다! 🤗
라이언 미첼: 웹 크롤링, 보안, 데이터 과학에 관심이 많은 개발라고 한다. 현재 글로벌 펀드사 헤지서브(HedgeServ)에서 시니어 개발자로 근무하고 있다. 프랭클린 W. 올린 공과대학교를 졸업했고 하버드 대학교에서 소프트웨어 엔지니어링 석사 과정을 밟았다. 어바인(Abine)에서 웹 크롤러와 봇을 만들었고, 링크드라이브(LinkeDrive)에서는 API 및 데이터 분석 도구를 만들었다. 금융업 및 유통업 분야에서 웹 크롤링 프로젝트 컨설팅을 하고 있고, 교육과 강연 활동도 활발하게 펼치고 있다. 본서 외 저서로 『Instant Web Scraping with Java』(Packt, 2013)가 있다.
리뷰
위에서 언급한 대로, 이 책은 크롤링을 처음 입문하는, 특히 웹쪽이 아닌 사람에게 아주 흥미롭게 읽히고 좋을 것 같다.
[1장] 에서는 브라우저가 네트워크 패킷을 어떻게 serving 해서 rendering 하는지 아주 간략한 정보 부터, HTML 구조 분석(BeautifulSoup), 타겟 데이터를 스크레이핑 하는 "전략", scrapy library, 문서 및 데이터 저장 정도를 다룬다. 정말 "초심자, 기본기"에 초점이 맞춰져 있다. 이 책에 deep dive를 기대한 사람이라면 1장에서 조금 실망했을 것이다.
[2장] 에서는 mess한 HTML & data file 분석(인코딩, csv, pdf file, docs), mess한 data 정리(n-gram, 자연어 처리 - 데이터축약, 마르코프 모델, NLTK), request library로 더 복잡한 요청하기(login, form tag submit, 쿠키처리), 자바스크립트 간단 소개와 크롤링, 셀레니움, API를 통한 스크레이핑, HTTP method, unofficial API 찾기 (browser network tab), 이미지 처리와 텍스트 인식(OCR) - 테서렉트 등, 캡챠(CAPTCHA) 읽기와 테서랙트 훈련, 윤리와 사람인 것 처럼 하기(헤더, 쿠키, csrf token, hidden value, 간단한 crawling code unittest, 병렬 웹 크롤링, 마지막으로 한 번 더 크롤링의 윤리를 정리해준다.
책 전체가 "크롤링 그 자체와 기술"에 초점이 맞춰져 있다. 그래서 크롤링 실전 기술에 흥미가 있는 사람에게 좋다고 느껴진다. 개인적으로 크롤링의 꽃은 "분산 크롤링과 조금 큰 규모의 크롤링 project 구조를 어떻게 잡을 것"이냐 라고 생각한다. 하지만 이 책에서는 해당 부분에서는 깊게 다루지 않아서 아쉬웠다.
"크롤러를 만들어 검색 엔진의 역할처럼 이리 저리 다니며 인덱싱을 해보겠다!" 도 좋지만, 요즘엔 단순 스크레이퍼를 더 활용한다(타겟 데이터와 필요한 원천 데이터를 정해놓고 코드를 짜는 경우가 많다).
퍼포먼스가 중요했던 크롤러를 개발하면서 참 많이 배웠었다. 당장, 생각한 타겟 데이터를 단순하게 실행 및 수집하는 스크레이퍼 짜는 것은 누구나 쉽게 시작할 수 있다, 심지어 python을 몰라도 docs만 잘 읽는다면 말이다. 하지만 다양한 사이트 대상으로 타겟 데이터를 선정하고, 인덱싱 하고, 코드의 유지 보수와 퍼포먼스까지 같이 고려한 "크롤러"를 만들기는 참 어려운 것 같다.
해당 경우 중요하게 여겨지는 것은 "전체 설계"와 다양한 에러에 대응하는 "전략" 인 것 같다. 얼마나 빠르게, 얼마동안의 cycle, error handling 전략, unstable한 crawling 특성상 429 or 5xx error는 쉽게 마주할 수 있다. 그리고 웹이라는 진영 특성상, 브라우저를 통해 접근가능한 영역은, 무조건, 어떻게든 crawling & scraping 이 가능하다는 것 이다. 설령 그것이 activeX, Chapcha, auth-token 등으로 잘 감싸져 있어도 결국 시간과의 싸움이 된다.
전체 목차를 기준으로 책 내용을 정리했다. 기본기 말고 응용 및 핵심만 아래에 나열해본다.
목차별 리뷰
Part 1. 스크레이퍼 제작
첫 번째 웹 스크레이퍼
-
초반에 웹어플리케이션과 브라우저가 network flow중 개입하는 예시를 들어주는 것은 본질적이여서 좋다. (비트스트림(전압) -> 헤더 바디 바이트 덩어리 -> 패킷 -> MAC...IP... -> 도착지 역순). 그리고 바로
urllib모듈의urlopen실습으로 간다. -
그리고 html.read() 한 바이트 데이터를 "html.parser" 파서를 통해 bs4로 object화 시킨다. (
bs4,BeautifulSoup). 이후 바로 "lxml" 파서까지 소개한다. 참고로 lxml은 불완전한 html(닫힌 tag가 없거나, body가 없거나 등) 도 직접 붙여가며 만든다. -
HTTPError등 스크레이퍼를 만들때 가장 "기본" 이라고 생각되는, try - except 에서 에러 핸들링을 보여준다. 개인적으로 스크레이퍼에서 exception handling을 어디까지 얼마나 잘 하냐는 디테일에서 그 짬(?)이 느껴진다고 생각된다.
고급 HTML 분석
-
bs4의
find,find_all로 넘어간다. 개인적으로 official docs 정말 보기 싫게 생긴 라이브러리 중 하나다. 그래도 정리 자체는 굉장히 잘 되어 있으니 차라리 official docs 보는 것을 추천한다. -
find_all(tag, attributes, recursive, text, limit, keywords)/find(tag, attributes, recursive, text, keywords)두 개의 인자를 확실하게 짚어준다.attributes는 dict object를 받아 DOM 자체의 속성값을 필터링한다. 그 외는 docs보는게 낫다. 그리고 "체이닝"이 가능하다는 것이 좋다. 참고로 책에서는 bs 구버전 method 표현형식인 카멜 케이스로 표기되어 있지만 지금은 모두 스네이크로 통합이 되었다. -
BeautifulSoup의 대표적인 class (object)들을 소개한다.
Tag(일반적인 HTML tag),NavigableString(태그 안에 들어가 있는 텍스트),Comment(태그 안에 있는 주석 like<!-- -->). 이렇게만 알아도 bs4는 다 사용가능하다. (책 쓰여지는 시점 기준 원래 4개가 다 라고 한다!) -
그리고 다양한 method를 소개한다. 부모 자식 및 자손 (
next_siblings(),previous_siblings(),parent,children) 등이 있다. 그리고 "regex"를 value 로 활용해 tag를 찾는 방법도 소개한다. 일단 나는 "속도 및 퍼포먼스"가 중요하다면 regex를 최후의 수단으로 생각하고 다른 방법을 계속 찾는게 낫다고 생각한다. -
Taginstance들은attrs라는 접근자를 통해 html tag (target dom)이 가지는 특정 속성값을 가져올 수 있다.imgTag: Tag인 경우imgTag.attrs["src"]가 가능하다는 것이다. -
그리고 가장 소개하고 싶었던 부분은 바로 lambda function 을 사용하는 부분이다. find_all은 매개 변수에 인자로써 function을 넘길 수 있으며 해당 함수는 반드시 "객체를 매개변수로 받아야" 하고 "불리언" 값만 리턴할 수 있다.
# 속성이 정확하게 2개인 태그를 모두 찾기
bs.find_all(lambda tag: len(tag.attrs) == 2)
# bs가 제공하는 method를 활용할 수 있다.
bs.find_all(lambda tag: tag.get_text() == "something")
# 위는 아래와 같다.
bs.find_all("", text="something")
# 좀 더 복잡하게 아래와 같이 사용 가능하다.
# "container" 클래스를 가진 div 요소들을 선택
find_all(lambda tag: tag.name == "div" and "container" in tag.get("class", []))크롤링 시작하기
-
실습으로 wiki백과 웹 페이지를 활용하는데 케빈 베이컨의 여섯 다리(Six Degrees of Kevin Bacon)에 비유한다. 두 다리를 이으면 무조건 다 닿을 수 있다는 것이다.
-
여기서는 "웹 크롤링" 의 관점을 얘기한다. web data를 수집하는 crawling bot이 있고 해당 bot이 어떻게 html을 읽어가며 link를 타고 들어가고 서로 이어주는지, 얼마나 깊이 타고 들어가야 하는지, site map을 통해서 바로 규모가 큰 웹페이지를 파악하는 방법에 대해 말한다. 사이트맵이 잘 소개되어 있는 웹페이지라면 디렉토리 구조처럼 바로 파악이 가능하고 하나하나 파고들어가는 crawling bot에 비해 훨씬 효율적이다.
-
그리고 인터넷 웹크롤링을 소개하며 "구글"을 말한다. 그리고 실제 간단한 예시 코드를 보여준다. 쉽게, 시작 페이지에서 이동가능한 모든 외부 link를 가져오고, 모든 외부 link를 따라가거나 (또는 랜덤), 외부 link가 없으면 이제 내부 link로 간다. 그에 발전한 아래와 같은 순서도를 소개한다.
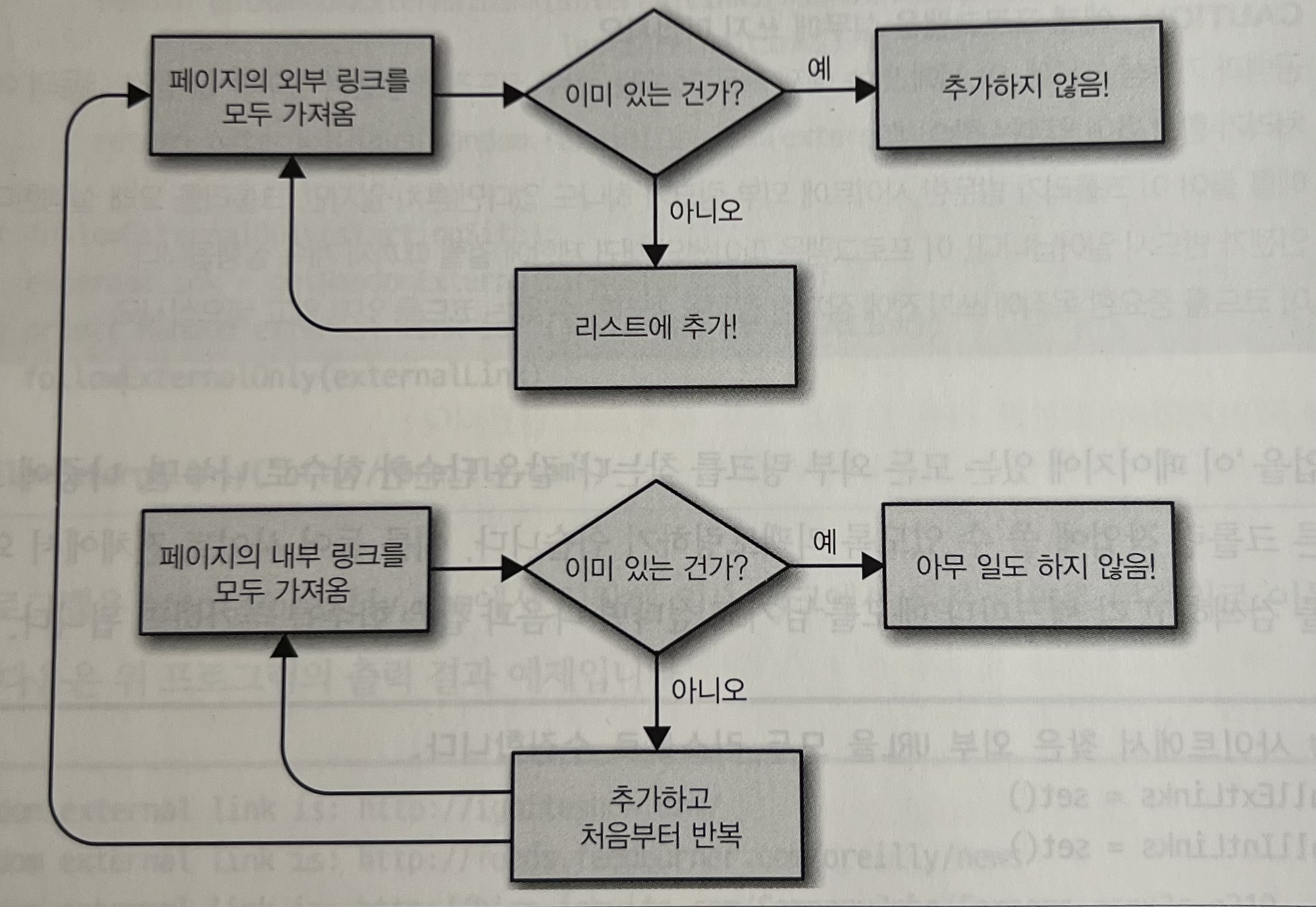
웹 크롤링 모델과 크롤러 구성
-
여기서는 크롤링 측면 뿐 아니라 코드 레벨에서 기본적인 내용이라 크게 짚고 넘어갈만한 내용이 없었다.
-
웹 크롤링을 사전에 설계하기 위한 다양한 얘기와 시사점을 던진다. target data 선정하고, 전략에 대해 말한다. 그리고 "모델" 과 같이 "목표 데이터" 가 명확하면 할수록 좋다는 점을 많이 시사한다. 해당 부분에 몇번이고 너무 공감한다. 그에 따라, 다양한 웹사이트들에 따라 유동적이게 작동하는 방법에 대한 고민이 있다.
-
일단 class를 통해 OOP 관점으로 crawling을 구성하는 기본적인 형태에 대해 말한다. target data model을 위한 class를 만들고 Crawler class로 url들을 crawling하는 형태다. 그리고 "검색을 통한 사이트 크롤링" 방법도 얘기한다. 그리고 "패턴 찾기" 라는 본질적인 의문을 던져준다.
-
이 다음이 "스크레이피, scrapy module" 활용법이고, 그 다음이 "데이터저장" 이다. 과감하게 둘다 skip하겠다. 스크레이피는 목적이 딱 그쪽에(웹 크롤링) 국한되어 있는 프레임워크이며 기능도 방대해 official docs를 보는 것을 훨씬 추천한다. 그리고 PyMysql library까지 소개하는데 너무 기본적인 내용이라 굳이 정리하지 않겠다.
Part 2. 고급 스크레이핑
part1에 비해 다양한 분야와 상황에 대한 예시가 있어서 이 책의 골자라고 느껴진다. n그램과 자연어 처리, 병렬 처리 등에 대한 언급도 있어서 흥미롭게 읽을 수 있다. 역시 특정 분야 자체에 deep dive하는 목적이 아닌 책이라, 전반적인 소개가 다인것은 조금 아쉽다.
다양한 파일 형태의 문서 읽기, 텍스트 인코딩
-
실제로 crawling하다보면, 특히 한글, 가져온 text가 깨진 경험이 있을 것이다. 사실 lxml은 그 부분까지 자동으로 처리해주지만, 그럼에도 Doc Type에 명시한 인코딩과 실제 인코딩 값이 다른 경우도 허다하다. 이때 아스키코드(ASCII) 인코딩 chartset과 UTF-8에 대한 개념이 조금 필요하다. 그 부분에 대해서 살짝 언급한다.
-
그리고 csv 다루는 방법, pdf 파일을 파싱하는 방법(이 경우 다양한 오픈소스 라이브러리가 존재한다, 대표적으로 PyPDF2, pdfminer.six 등이 있다.), word와 docs도 다룬다. 이 경우 인터넷의 docs file을 request & read 한 뒤
iomoudle의BytesIO과zipfilemodule의ZipFile을 사용해 "xml"로 메모리에 올리고(변수할당) 그 xml을 bs4로 파싱하는 형태를 추천한다. -
이 경우
<w:t></w:t>태그를 기준으로 텍스트를 나누는 것을 볼 수 있고, regex 와 w tag의 attribute를 활용하면 html tag 다루듯이 parsing할 수 있다.
지저분한 데이터 정리하기
- 웹에는 정형화된 데이터 뿐 아니라 비정형 데이터도 많다. 그런 "지저분한 데이터를" 정리하는 관점에 대해서 다룬다. 먼저 NLP에서 언급되는 "N-gram"을 말한다. 수집한 text데이터에서 완성도 높은 n-gram을 위해 문자열을 어떻게 handling해야하는지 보여준다.
\n과 같은 이스케이프 문자 처리 및 유니코드 문자 제거, regex밑 구두점에 대한 처리, "유효한 ngram"을 만드려고 한다. 그리고 "오프리파인"을 소개하는데, 데이터베이스 타겟 전용 전문화된 excel이라고 생각하면 된다. 해당 S/W는 데이터 후처리 및 정제에 유명하니 관심있으면 꼭 찾아보는 것을 추천한다.
자연어 읽고 쓰기
-
구글에서 "귀여운 고양이"라는 natural language를 검색했을때 일어나는 전반적인 얘기를 언급한다. 일단 스프레이핑하는 data 자체를 데이터 요약을 위해 ngram을 활용을 하고, 핵심 단어 추출을 한다. 그 과정에 of, the, in 등의 주제와 상관없는 단어를 정제하며 텍스트 요약에 대한 강조를 한다.
-
그리고 마르코프 모델(Markov Model) 을 언급한다. 마르코프 모델은 어떤 특정 사건이 다른 특정 사건에 뒤이어 일정 확률로 일어나는 대규모 무작위 분포를 분석할 때 자주 쓰인다. ‘특정 상태의 확률은 오직 과거의 상태에 의존한다’ 라는 핵심을 가지고 날씨 예보를 예시로 많이 든다. 예시는 아래와 같다.
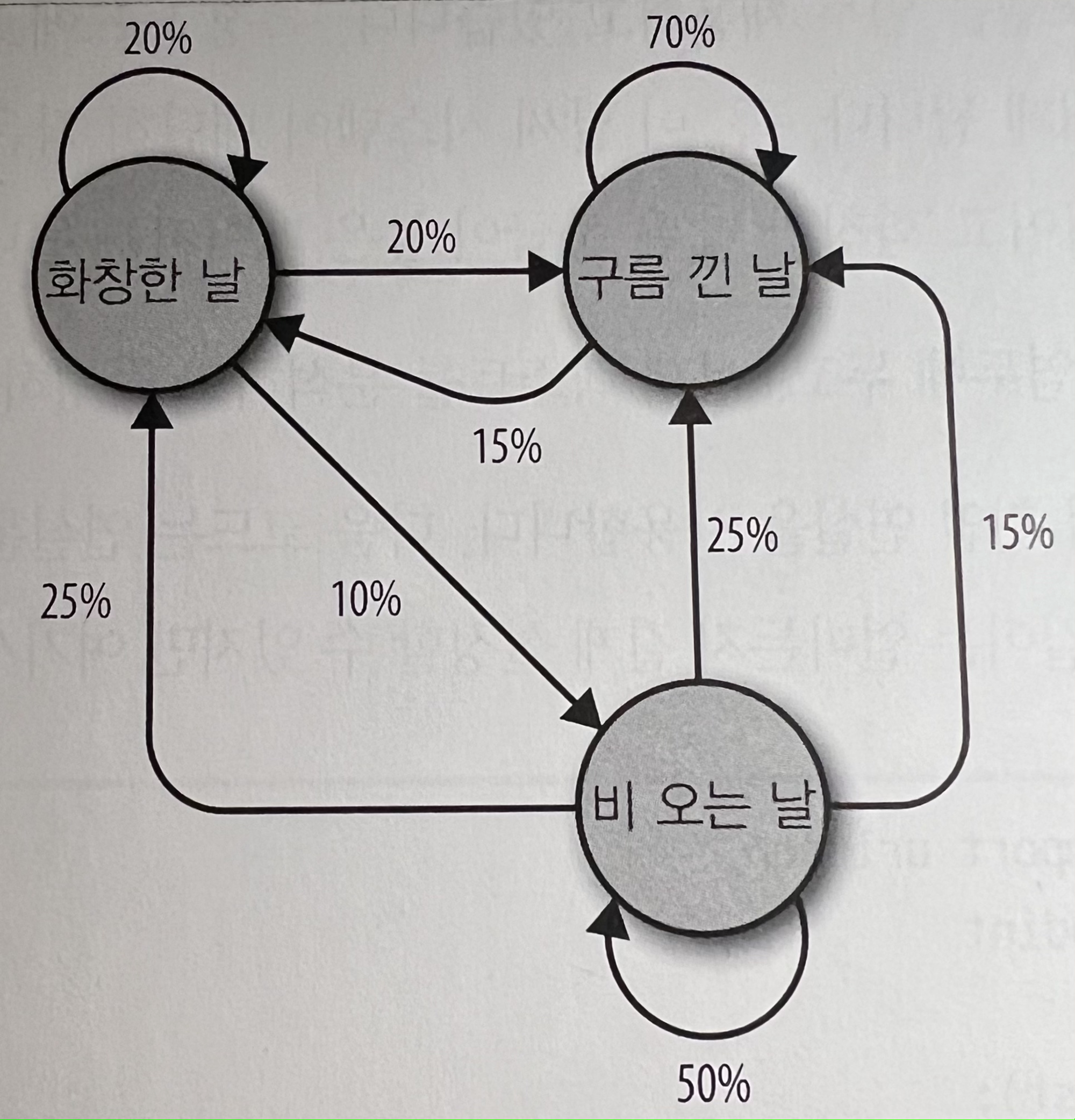
-
실제 구글의 페이지 평가 알고리즘도 웹사이트를 노드로 나타내고 들어오는/나가는 링크를 노드 사이의 연결로 나타내는 마르코프 모델을 일부 채용하고 있다고 한다. 특정 노드에 도달할 확률은 그 사이트의 상대적 인기를 나타내게 된다. 이 날씨 시스템이 대단히 작은 인터넷이라면, "비오는 날"은 등급이 낮은 페이지, "화창한 날"은 등급이 높은 페이지가 된다. 더 깊이 들어가면 너무 NLP에 대한 얘기가 되어서, 다른 참고 링크들로 대체하겠다.
-
그리고 "방향성 그래프"에 대한 얘기와 "너비 우선 탐색(BFS)"을 얘기한다. 즉 스크레이핑 자체를 방향성 그래프의 BFS 관점에서 하며 "페이지 평가" 관점에서 "마르코프"를 생각할 수 있다는 점이다. NLTK 라는 자연어 툴킷도 소개한다. 자연어 처리에 관심이 많다면 꼭 여기 링크도 확인해 보길 바란다.
폼과 로그인 뚫기
-
여기서 책은 http request method, request library, form-data (multipart form)으로 binary file (이미지 등) 포함하기, cookie에 대한 얘기를 아주 간략하게 소개한다. 사실 기술적으로 유의미한 인사이트는 얻기 힘들다. 여기에 덧붙이고 싶은 내용이 많다.
-
일단 HTTP에 base64기반의 basic access authentication 도 code base로 통과하는 코드를 꼭 한 번 작성해보길 바란다. 의외로 과거의 가장 기본의 auth에서 막히는 경우도 꽤 보았다. 그리고 csrf token 역시 잊지말아야 할 부분이다.
-
그리고 API에 해당하는 부분은 backend API를 많이 만들어본 사람일라면 어떻게 통과를 할지 감이 바로 올 것 이다. HTTP request에 대해 좀 이해하고, method를 get만 사용하던 것에 벗어나 post로 login하고 session을 만들어서 해당 session으로 target data를 수집하는 것, 이게 이제 "(타겟 데이터)크롤링" 이라고 할 수 있지 않을까. 나도 아직 내공이 너무나도 부족하지만, 이런 디테일한 접근과 관점에서 관록이 제일 드러나는 것 같다.
이후 내용
-
이후엔 javascript와 셀레니움을 간략하게 다룬다. ajax와 jquery 언급부터 API 활용하기 위해 chrome과 같은 browser에서 network tab 예시로 보여준다. 그리고 OCR과 numpy 소개하며 이미지 file 자체를 text로 바꾸는 전략에 대해 소개한다. 그리고 "캡챠 읽기와 테서렉트 훈련"을 소개하며 해당 부분 역시 depth가 있지 않아 흥미있는 소개 정도에 그친다.
-
그리고 스크레이핑 윤리에 대해 얘기한다. 법적인 논재와 판례가 살짝나오며 "robot.txt" 등과 같은 rule을 따루는 것에 대해 말한다. 그리고 "사람 처럼 보이는 전략"에 대해 소개한다. 해당 부분은 header값 user-agent, cookie, request 텀 조절 (사람 처럼), form 보안을 위한 hidden값 parsing (csrf token 등), unit testing 까지 다룬다. 진짜 전반적인 생태계에 궁금함이 있는 사람이 읽으면 많은 도움이 되겠다는 생각이 든다.
병렬 웹 크롤링과 마무리
-
python3 이후의
_thread로 main process에서 멀티 쓰레딩을 하는 방법에 대해 소개하고 race condition handling을 위한 queue 자료 구조를 언급한다. 그리고 python의multiprocessingmodule과 같이 "멀프 + 멀쓰" 스크레이핑을 보여준다. -
그리고 클라우드 컴퓨팅을 예시로, 원격 서버에서 python code 기반 다중 스크레이핑을 말한다. 그러면서 Proxy와 python의
PySocks를 소개한다. 그리고 토어(토르 브라우저)와 셀레니움을 같이 사용하는 간단한 예시도 언급한다. 끝으로는 윤리에 대한 언급으로 책이 마무리가 된다. -
초반에 언급했지만 전반적으로 조금 아쉬웠다. 크롤링 세계의 얕은 전체적인 그림을 기대하고 산 책이 아니었고 병렬 처리를 위한 디자인 패턴이나, 단순 멀프 멀쓰보다 network I/O를 동시성(Concurrency)과 병렬성(Parallelism) 관점에서 좀 더 잘 다루는 방법을 기대했다. 코루틴과 greenlet에 대한 얘기를 살짝 기대했었다.. 근데 생각보다 너무 껍질맛만 보는 내용이 주로 이뤄서 아쉽다. 그래도 이제 막 크롤링과 웹 스크레이핑에 관심이 가지는 분들에게는 입문 도서로 너무 추천한다.
