python - memory optimization (2) : GC, reference counter and GIL
Python Deep Dive & Design Pattern

Python 메모리 관리 기법
"interpreting" 의 전체 과정과 cpython이 C로 python 메모리 할당과 관리를 어떻게 하는지 큰 그림을 살펴봤다. 할당을 했으면 해제는 어떻게 할까? python이 메모리를 해제하는 방법과 그 때문에 발생하는 GIL에 대해 알아보자.
-
파이썬을 사용하면 메모리의 할당과 해제를 프로그래머가 직접할 필요가 없다. 오히려 올바르지 않게 직접하면 역효과가 난다.
-
"객체가 더 이상 사용되지 않으면", 알아서 해당 객체를 메모리에서 해제해야 한다. 그럼 어떤 객체가 "더 이상 사용되지 않는" 객체일까? 이를 위해 파이썬은 레퍼런스 카운팅과 가비지 컬렉션의 두가지 방법을 모두 사용한다.
-
사실 레퍼런스 카운팅 자체도 GC에 포함시키기도 하지만, 우선 따로 두고 살펴보기로 한다.
1. 레퍼런스 카운팅 (reference counting)
-
객체 자체에서 스스로가 참조되는 횟수를 기록하고 더 이상 참조되지 않아서 참조 횟수가 0이 된다면 객체를 할당 해제 한다.
-
할당 해제 할때
__del__(self)함수가 호출 되며Destructors라고도 부른다.
1) 작동 방법
-
모든 객체는 참조 당할 때 레퍼런스 카운터를 증가시키고 참조가 없어질 때 카운터를 감소시킨다. 이 카운터가 0이 되면 객체가 메모리에서 해제한다. 어떤 객체의 레퍼런스 카운트를 보고 싶다면 sys.getrefcount()로 확인할 수 있다.
-
파이썬 내부에서는
Py_INCREF매크로를 사용하여 참조 횟수를 증가시키고Py_DECREF매크로를 사용하여 참조 횟수를 감소시킨다. 만약 참조 횟수가 0이 된다면Py_DECREF매크로는_Py_Dealloc함수를 사용하여 메모리에서 객체를 해제한다. 공식 문서 에서 더 살펴볼 수 있다. -
ps) "매크로" 란, C언어에서
#define선행처리 지시문에 인수로 함수의 정의를 전달함으로써, 함수처럼 동작하는 매크로를 만들 수 있다.
2) 한계, 순환 참조
- 레퍼런스 카운팅은 메커니즘도 간단하고 사용되지 않을때 바로바로 회수가 가능한 장점이 있다. 하지만 "자기 자신을 참조하는 순환 참조" 형태를 해결할 수 없다.
li = list()
li.append(li)
...
del lili는 리스트 object 이다. 그리고 자기 자신을 append하여li에 대한 참조 회수를 +1 한다. 이런 경우엔li를 destory해도 카운팅 값이 1로 남아 메모리에서 해제되지 않게 된다.
a = Human()
b = Human()
a.friend = b # 이 순간 b 의 래퍼런스 카운팅 2
b.friend = a # 이 순간 a 의 래퍼런스 카운팅 2
del a
del b-
특정 class의 instance로 만든 경우도 동일하다. 역시 del 이후 a, b는 각 1 값으로 남아 해제되지 않게 된다.
-
그래서 우리는 최대한 순환 참조의 형태를 피해서 코드를 짜는게 좋다. 하지만 웹어플리케이션과 같이 무중단으로, 장기러닝되는 프로세스의 경우 순환 참조의 형태가 있을 수 있다. 그래서 등장한 것이 G.C 이다.
2. 가비지 컬렉션 (Garbage Collection)
-
공식 홈페이지 c-api GC 에 대한 글을 살펴보자. 그리고 우린 gc 모듈을 통해 제어할 수 있다.
-
gc 모듈은 사실 오로지 "순환 참조 해결"을 위해 존재한다. 그래서 official docs에서도
Cyclic Garbage Collection라고 부른다. 그리고 gc 모듈 문서에서는 수거기는 파이썬에서 이미 사용된 참조 횟수 추적을 보충하므로, 프로그램이 참조 순환을 만들지 않는다고 확신한다면 수거기를 비활성화 할 수 있습니다. gc.disable()을 호출하여 자동 수거를 비활성화 할 수 있습니다. 라고 언급하고 있다.
1) 작동 방법
-
가비지 컬렉터는 내부적으로
generation(세대)과threshold(임계값)로 가비지 컬렉션 주기와 객체를 관리한다. (threshold는 허용 가능한 한계치라는 의미에 더 가깝다) -
세대는
0 - 2세대로 구분 되며, 최근에 생성된 객체들이 0세대에 포함된다. 한 객체는 하나의 세대에만 속할 수 있다. 그리고 0세대일수록 더 자주 GC를 하도록 설계되어 있다. 이는 아래와 같은 이론에 근거한다.
- 링크 : https://www.memorymanagement.org/glossary/g.html#term-generational-hypothesis
Infant mortality or the generational hypothesis is the observation that,
in most cases, young objects are much more likely to die than old objects.
Strictly, the hypothesis is that the probability of death as a function of age
falls faster than exponential decay (inverse hyper-exponential),
but this strict condition is not always required for techniques
such as generational garbage collection to be useful.- gc모듈에서
get_threshold()메서드를 사용하면 3개의 원소가 있는 튜플을 얻을 수 있다. 이는 각(threshold 0, threshold 1, threshold 2)를 의미한다.
>>> import gc
>>> gc.get_threshold()
(700, 10, 10)-
n세대에 객체를 할당한 횟수가
threshold n을 초과하면 가비지 컬렉션이 수행된다는 것을 의미한다. -
0세대의 경우
(메모리에 객체가 할당된 횟수) - (해제된 횟수)가threshold 0 => 700을 초과하면 실행된다. 이후 세대부터는 0세대 가비지 컬렉션이 일어난 후, "0세대 객체를 1세대로 이동시킨 후 카운터를 1 증가" 시킨다. 이 값이threshold 1 => 10을 초과하면 그때 1세대 가비지 컬렉션이 일어난다. 2세대도 동일하다. -
1세대로 갈때 0세대 count는 0으로 비우고 1세대 카운팅을 ++ 한다. 역시 2세대로 갈때 0세대, 1세대 count는 0으로 비우고, 2세대 카운팅을 ++ 한다.
-
아주 간단하게 보면 0세대 가비지 컬렉션이 객체 생성 700번만에 일어나고 -> 1세대는 7000번만에 -> 2세대는 7만번만에 일어난다는 의미이다.
2) 가장 중요한건 "순환 참조 감지"를 하는 것이다.
-
위에서 살펴본바와 같이 GC존재 목적은 "순환 참조 감지" 이다. 순환 참조는 컨테이너 객체에 의해서만 발생할 수 있음을 알아야 한다. 컨테이너 객체는 다른 객체에 대한 참조를 보유할 수 있다. 그러므로 정수, 문자열은 무시한 채 관심사를 컨테이너 객체에만 집중할 수 있다.
-
ps) container object는 "데이터의 종류에 무관하게 저장할수 있는 자료형을 저장한 모델"을 의미한다. 예를 들면 문자열(str), 튜플(tuple), 리스트(list), 딕셔너리(dictionary), 집합(set) 등은 "타입에 무관하게 저장이 가능한 컨테이너 객체"들이고 정수, 실수, 복소수 등은 "타입이 고정되어 있는 단일 종류"(Literal)한 자료형이다. 즉 컨테이너 타입을 상속한 객체로서 여러 데이터 객체에 대한 메모리 참조 정보를 담고 있는 객체 이다.
-
https://github.com/python/cpython/blob/main/Include/internal/pycore_gc.h
/* GC information is stored BEFORE the object structure. */
typedef struct {
// Pointer to next object in the list.
// 0 means the object is not tracked
uintptr_t _gc_next;
// Pointer to previous object in the list.
// Lowest two bits are used for flags documented later.
uintptr_t _gc_prev;
} PyGC_Head;
#define NUM_GENERATIONS 3
struct gc_generation {
PyGC_Head head;
int threshold; /* collection threshold */
int count; /* count of allocations or collections of younger
generations */
};
/* Running stats per generation */
struct gc_generation_stats {
/* total number of collections */
Py_ssize_t collections;
/* total number of collected objects */
Py_ssize_t collected;
/* total number of uncollectable objects (put into gc.garbage) */
Py_ssize_t uncollectable;
};
struct _gc_runtime_state {
/* List of objects that still need to be cleaned up, singly linked
* via their gc headers' gc_prev pointers. */
PyObject *trash_delete_later;
/* Current call-stack depth of tp_dealloc calls. */
int trash_delete_nesting;
/* Is automatic collection enabled? */
int enabled;
int debug;
/* linked lists of container objects */
struct gc_generation generations[NUM_GENERATIONS];
PyGC_Head *generation0;
/* a permanent generation which won't be collected */
struct gc_generation permanent_generation;
struct gc_generation_stats generation_stats[NUM_GENERATIONS];
/* true if we are currently running the collector */
int collecting;
/* list of uncollectable objects */
PyObject *garbage;
/* a list of callbacks to be invoked when collection is performed */
PyObject *callbacks;
/* This is the number of objects that survived the last full
collection. It approximates the number of long lived objects
tracked by the GC.
(by "full collection", we mean a collection of the oldest
generation). */
Py_ssize_t long_lived_total;
/* This is the number of objects that survived all "non-full"
collections, and are awaiting to undergo a full collection for
the first time. */
Py_ssize_t long_lived_pending;
};
-
위에서 살펴본 작동 방식 대로, 세대별 임계값이 넘어 gc가 시작되면, struct
PyGC_Head에 선언된 더블 링크드 리스트 (_gc_next,_gc_prev) 로 모든 컨테이너 객체에 접근한다. -
각 객체에 접근하여 "참조하는 다른 컨테이너 객체의 참조 횟수 감소",
gc_refs값을 감소 시킨다. 아직 외부에서 정상적으로 참조되고 있는 컨테이너 객체는 0이 안된다. -
gc_refs가 0이 되면 unreachable (임시 설정,GC_TENTATIVELY_UNREACHABLE) flag를 설정한다. -
하지만 0이라고 해서 무조건 참조가 안되는 것은 아니다, 외부에서 직접 참조되고 있지 않아도,
gc_refs가 0이상인 것들인 객체에 의해 참조되고 있다면 0이어도 도달 가능하기 때문에 gc는 다시 이러한 객체를 찾아 reachable flag를 설정한다. -
위 과정이 끝나면 unreachable flag를 가진 객체는 진짜 도달 불가능이 확정이 되고, 메모리에서 진짜 해제가 된다.
3. GIL (Global Interpreter Lock)

GIL issue는 위와 같은 메모리 할당 해제, 레퍼런스 카운팅과 GC 때문에 존재한다. GIL은 2022 PyCon Korea 내용을 많이 발췌했다. [ 아래 등장하는 사진은 모두 PyCon 유튜브 내용입니다 :) ]
1) GIL은 왜 존재하는가
- 파이썬 인터프리터가 한 스레드만 하나의 바이트코드를 실행 시킬 수 있도록 해주는 Lock 이다. 즉, 하나의 스레드에 모든 자원을 허락하고 그 후에는 Lock을 걸어 다른 스레드는 실행할 수 없게 막아버리는 것이다.
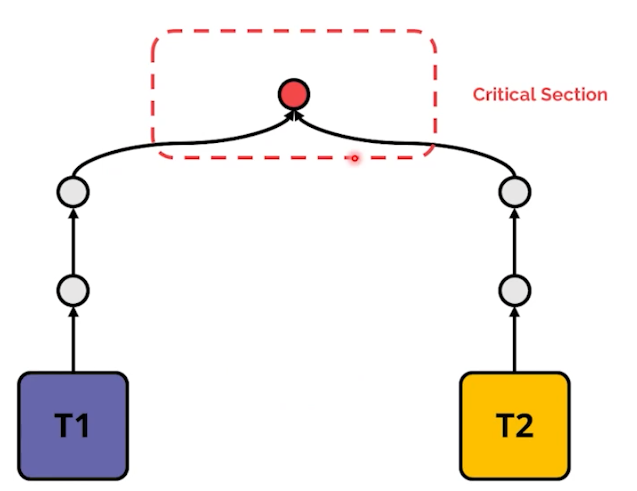
-
위 그림은 2개의 thread가 빨간점이라는 공통된 자원에 접근 했을 때 그림이다. 빨간점 부분에 thread safe한 조취가 이뤄지지 않으면, dead lock 등의 상황이 발생할 수 있다.
-
왜 위와 같은 상황이 python에서 발생하는가?
-
위에서 reference counting를 생각해보자. python은 "사용하지 않는 객체를 찾기위해 참조 횟수를 카운팅" 한다. 그리고 그 값은 실제 "변수" 값으로 저장된다. 레퍼런스 카운팅 값 자체가 메모리에 존재한다는 의미다. 그리고 multi thread 환경에서 그 변수는 위 그림과 같이 빨간점의 영역 이다.

- 2개의 thread가 "변수에 1을 증가시키고 저장하는" 같은 작업을 한다고 하자. 그리고 그 변수의 reference counting 값은 critical section (빨간점) 영역에 존재한다.
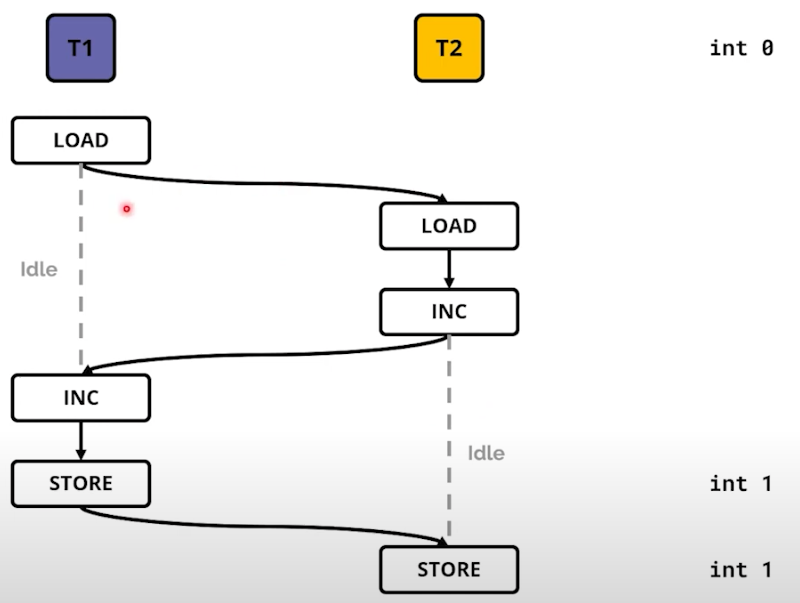
-
실제 수행 (위와 다를 수 있겠지만)을 위에서 아래 방향으로 시간이 흐르는 형태로 작업을 한다고 가정하자. T1에서 변수를 가져오는 작업 이후 context switching 이 일어나 T2의 LOAD와 INC 작업을 했다. 그 이후 다시 T1으로 context switching 나 +1과 저장까지 완료 후, 1이라는 값이 저장되었다.
-
마지막으로 T2로 context switching 이 되어 1이라는 값에 +1을 한다. T1의 +1에 의해 2가 되어야 하지만, 최종적으로 1이 저장된다. 이 상황이 흔히 볼 수 있는 race-condition이다. 어떻게 핸들링 할 수 있을까? 대표적으로 Mutex 가 존재한다.
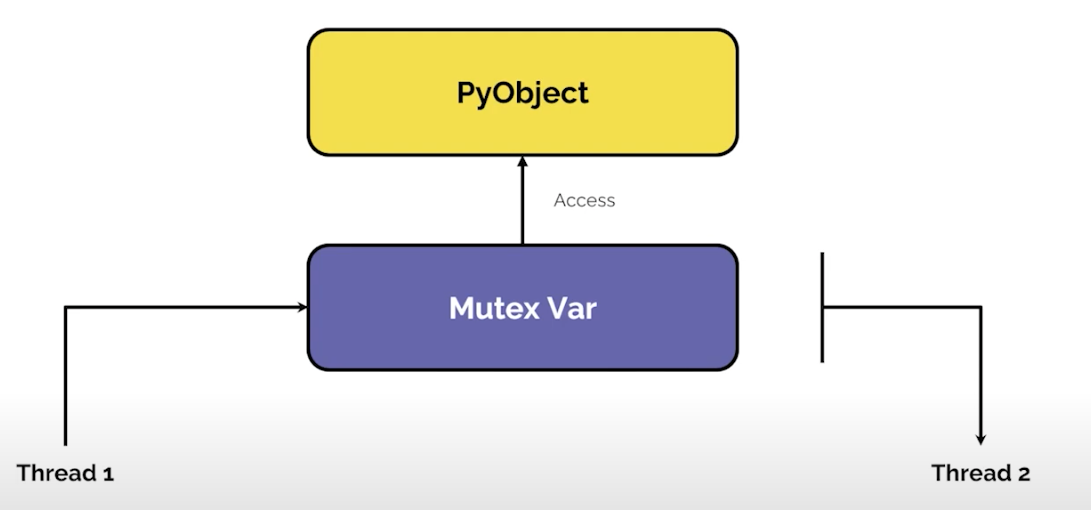
- Mutex는 공유자원에 접근할 때 하나의 Thread만 접근이 가능하게 처리하는 것을 의미한다. 그리고 해당 Thread가 공유영역 작업이 끝내야만 다른 Thread가 접근 가능하게 처리한다.
2) GIL 이 일어나는 cpython 코드
- 실제로 Cpython의 take_gil 함수 구현 부분을 보자 - 깃허브에서 보기
/* Take the GIL.
The function saves errno at entry and restores its value at exit.
tstate must be non-NULL. */
static void
take_gil(PyThreadState *tstate)
{
// ... //
/* Check that _PyEval_InitThreads() was called to create the lock */
assert(gil_created(gil));
MUTEX_LOCK(gil->mutex);
// ... //
while (_Py_atomic_load_relaxed(&gil->locked)) {
unsigned long saved_switchnum = gil->switch_number;
unsigned long interval = (gil->interval >= 1 ? gil->interval : 1);
int timed_out = 0;
COND_TIMED_WAIT(gil->cond, gil->mutex, interval, timed_out);
/* If we timed out and no switch occurred in the meantime, it is time
to ask the GIL-holding thread to drop it. */
if (timed_out &&
_Py_atomic_load_relaxed(&gil->locked) &&
gil->switch_number == saved_switchnum)
{
if (tstate_must_exit(tstate)) {
MUTEX_UNLOCK(gil->mutex);
// gh-96387: If the loop requested a drop request in a previous
// iteration, reset the request. Otherwise, drop_gil() can
// block forever waiting for the thread which exited. Drop
// requests made by other threads are also reset: these threads
// may have to request again a drop request (iterate one more
// time).
if (drop_requested) {
RESET_GIL_DROP_REQUEST(interp);
}
PyThread_exit_thread();
}
assert(is_tstate_valid(tstate));
SET_GIL_DROP_REQUEST(interp);
drop_requested = 1;
}
}
// ... //
MUTEX_UNLOCK(gil->mutex);
errno = err;
}
-
실제로
MUTEX_LOCK(gil->mutex);을 호출하는 것을 볼 수 있다. -
while (_Py_atomic_load_relaxed(&gil->locked))에서 해당 LOCK이 해제될때까지 기다리는 것도 볼 쉬 있다. -
그리고 while이 끝나고
MUTEX_UNLOCK(gil->mutex);을 하는것을 볼 수있다.
3) 성능
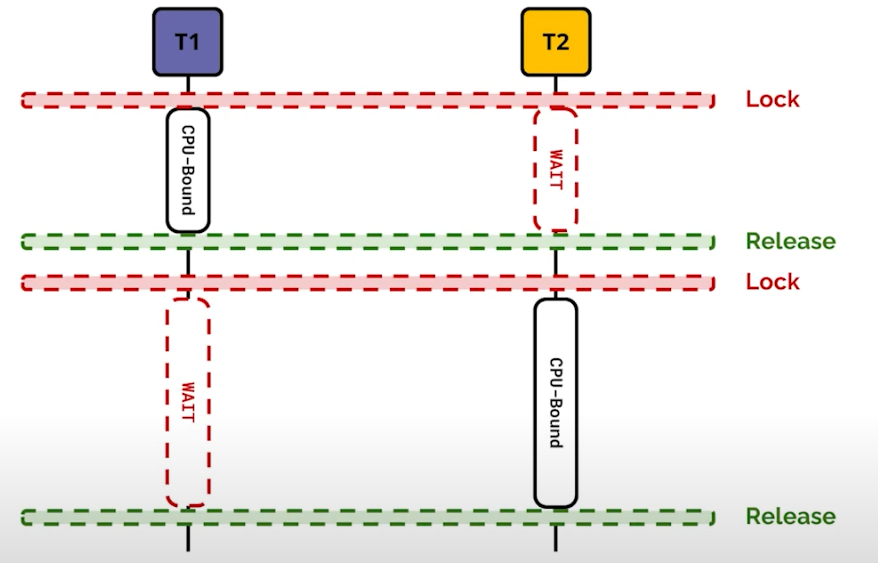
- Mutex에 의해 하나의 Thread만 접근하고 다른 Thread는 WAIT 상태이니 성능 오버헤드가 발생한다. 하지만 이런 오버헤드가 항상 발생하는 것은 아니다.
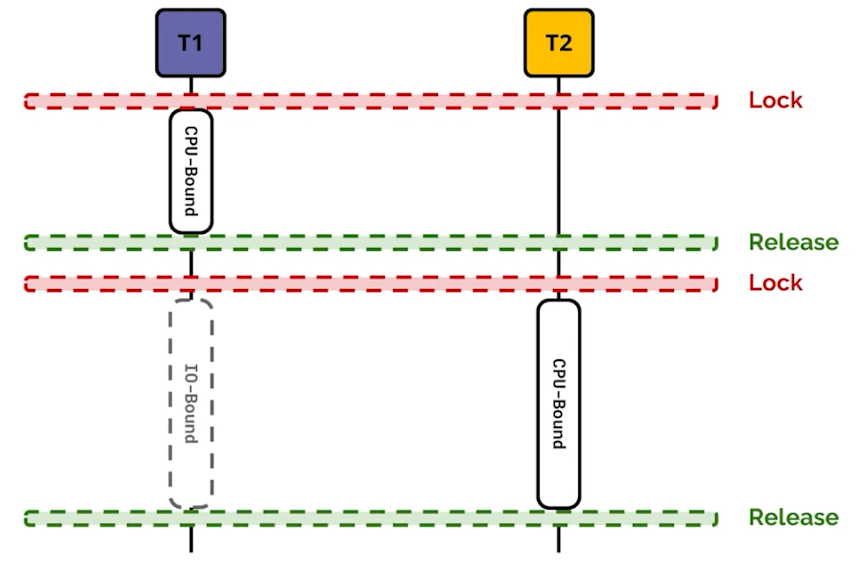
- Network file download 또는 print 와 같은 I/O Bound task 의 경우 GIL을 사용하지 않고, 다른 thread가 CPU-BOUND 작업을 할 수 있게 하고, I/O Bound는 실행이 된다.
(1) CPU bound, IO bound
-
일반적으로 연산이 많이 필요한 로직은 CPU bound, 로컬 파일 시스템 혹은 네트워크 통신이 많은 로직은 I/O bound, 더 정확하게는 OS의
Burst용어를 알아야 한다. -
버스트는 "어떤 특정된 기준(criterion)에 따라 한 단위로서 취급되는 연속된 신호(signal) 또는 데이터의 모임. 어떤 현상이 짧은 시간에 집중적으로 일어나는 현상. 또는 주기억 장치의 내용을 캐시 기억 장치에 블록 단위로 한꺼번에 전송하는 것." 을 의미한다.
-
CPU burst는 프로세스 내에서 CPU 명령작업이 연속된 작업을 의미하며 IO burst는 로컬 혹은 네트워크등의 I/O wait 작업이 연속되는것을 의미한다.
(2) 그럼 어떻게 GIL의 한계를 극복하는가?
-
MultiThread 대신 MultiProcess를 활용한다. 하지만 MultiProcess는 기본적으로 독립적인 메모리 공간, [code(text), data, heap, stack 영역] 을 가지기 때문에 무겁다. 이런 점 때문에 오히려 더 늘어질 수 도 있다.
-
C-Bindings를 활용한다. cpython은 c로 되어있기 때문에 C언어 코드를 활용할 수 있다. 하지만 완벽하게 GIL을 벗어날 수 없다. 아래 사진을 살펴보자.
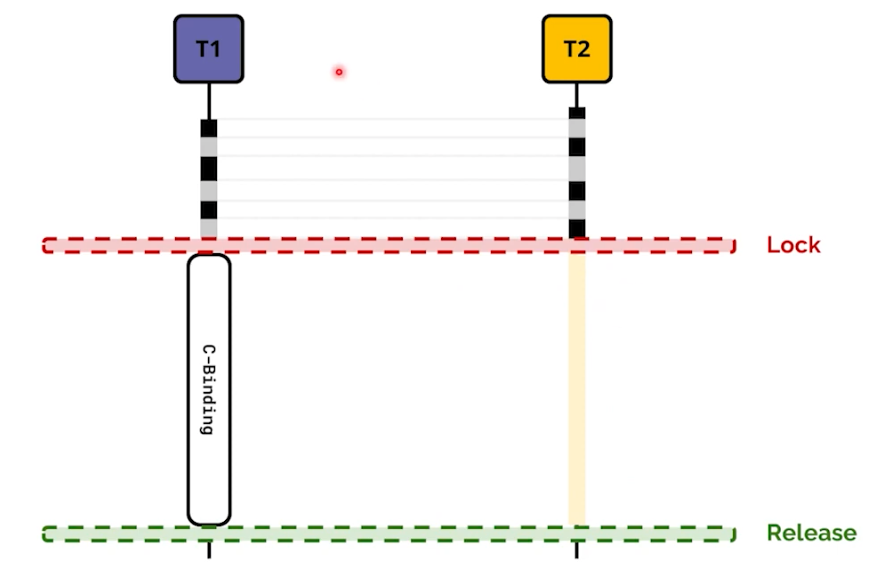
-
그리고 직접 GIL을 해제하는 로직이 필요하다. 코드의 복잡성과 난이도가 올라가고, 엄청나게 극복할 수는 없다.
-
마지막으로, 해당 세션에서 GIL에 대한 미래를 소개한다.
atomic_fetch_add와 같은 상세한 정보는 꼭 PyCon에서 직접 확인하는 것을 추천한다.
출처
- 많은 분들의 많은 글을 참조했습니다. 부족한 부분 많이 지적해 주세요.
- https://2022.pycon.kr/program/talks
- 파이콘 GIL 새션 : https://www.youtube.com/watch?v=hj8BnSAalEs
- https://www.beautifulcode.co/blog/81-global-interpreter-lock-gil-in-python
- https://luavis.me/python/dismissing-python-garbage-collection-at-instagram
- https://seonghyeon.dev/python-memory-management
- https://blog.winterjung.dev/2018/02/18/python-gc
- https://www.memorymanagement.org/glossary/g.html
- https://docs.python.org/ko/3/library/gc.html#gc.disable

도움이 많이 되었습니다, 감사합니다!