Elasticsearch - 루씬 기본 개념과 ES 시스템 및 데이터 구조(Node, Index, Shard) 이해하기

새로운 Elasticsearch 데이터 구조 이해하기
해당 글은 김종민님의 Datastream - 새로운 Elasticsearch 데이터 구조 이해하기
동영상을 기준으로 추가적인 자료를 참고해서 elastic의 전체적인 구조에 대한 정리글입니다. 완전 es가 처음이신 분 보다 한 번은 사용해보신 분을 대상으로 하고 있습니다! 해당 내용 정리전에 가볍게 "아파치 루씬"에 대해 살펴보고 들어가겠습니다.
[ 🔥 스크롤 압박 주의해 주세요! 매우 깁니다! 🔥 ]
1. 아파치 루씬
- 왜 갑자기 "Apache Lucene" 인가? ES의 전신이 바로 아파치 루씬이기 때문이다. 루씬은 자바(Java) 언어로 개발된 오픈소스 정보 검색 라이브러리이다. 1999년 더그 커팅에 의해 개발되었다. 루씬 개발 프로젝트는 아파치재단이 관리하는 최상위 프로젝트이다.
1) 검색엔진
-
검색엔진의 가장 기본이 무엇일까? 1990년대 초 등장한 월드와이드웹(www), 인터넷의 출현은 많은 정보의 홍수를 이끌어 냈다. 하지만 방대한 정보를 찾기 위해 "직접 찾았어야" 했다. 사실 이 검색엔진은 "스크래핑, 크롤링" 기술과 연관이 깊다.
-
구글과 같은 기업이 "하이퍼 링크가 문서간 '인용' 개념으로 서로 얼마나 연결되어 있는 것을 counting해서 ranking해 search한 result 문서를 보여주는" 개념으로 "포탈" 이라는 모습으로 등장했다. 이게 검색엔진의 가장 기본적인 모습이다.
-
그리고 이러한 서로 연결된 모든 문서를 방문하는 것이 "크롤러 봇" 이었고 이를 통해 검색엔진을 고도화하고 완성했다.
2) 루씬은 검색엔진
-
루씬은 고성능 정보 검색 IR(Information retrieval) 라이브러리다. IR은 문서를 검색하거나, 문서와 연관된 메타 정보를 검색하는 과정을 말한다.
-
위에서 언급했듯, 검색엔진은 링크와 텍스트 기반 인식 기본이다. 크롤러가 방문한 웹 페이지에서 새로운 링크를 발견하면 웹 서버에 데이터 정보를 요청하고 이때 웹 서버는 검색엔진에게 웹 페이지 정보를 보내는데 이것이 바로 "메타태그가 포함된 사이트 정보"다.
-
크롤러는 그렇게 추가된 수집한 URL에서 단어와 문구를 분리하여 저장한다. 저장과정에서 각 단어와 문구(쿼리)에서 가중치(weight)와 연관도(relevance)를 부여하고 최종 결과 값을 인덱스(색인)한다.
-
검색자가 검색창에 검색어를 입력하면 그 때 필요한 것을 끄집어 내는 것이 아니라 검색엔진이 미리 구축해 두었던 인덱스(색인)을 검색하는 것이다. 이 과정이 없으면 검색 결과를 얻기까지 엄청난 시간이 소요된다.
3) 루씬의 간략 시스템 구성도
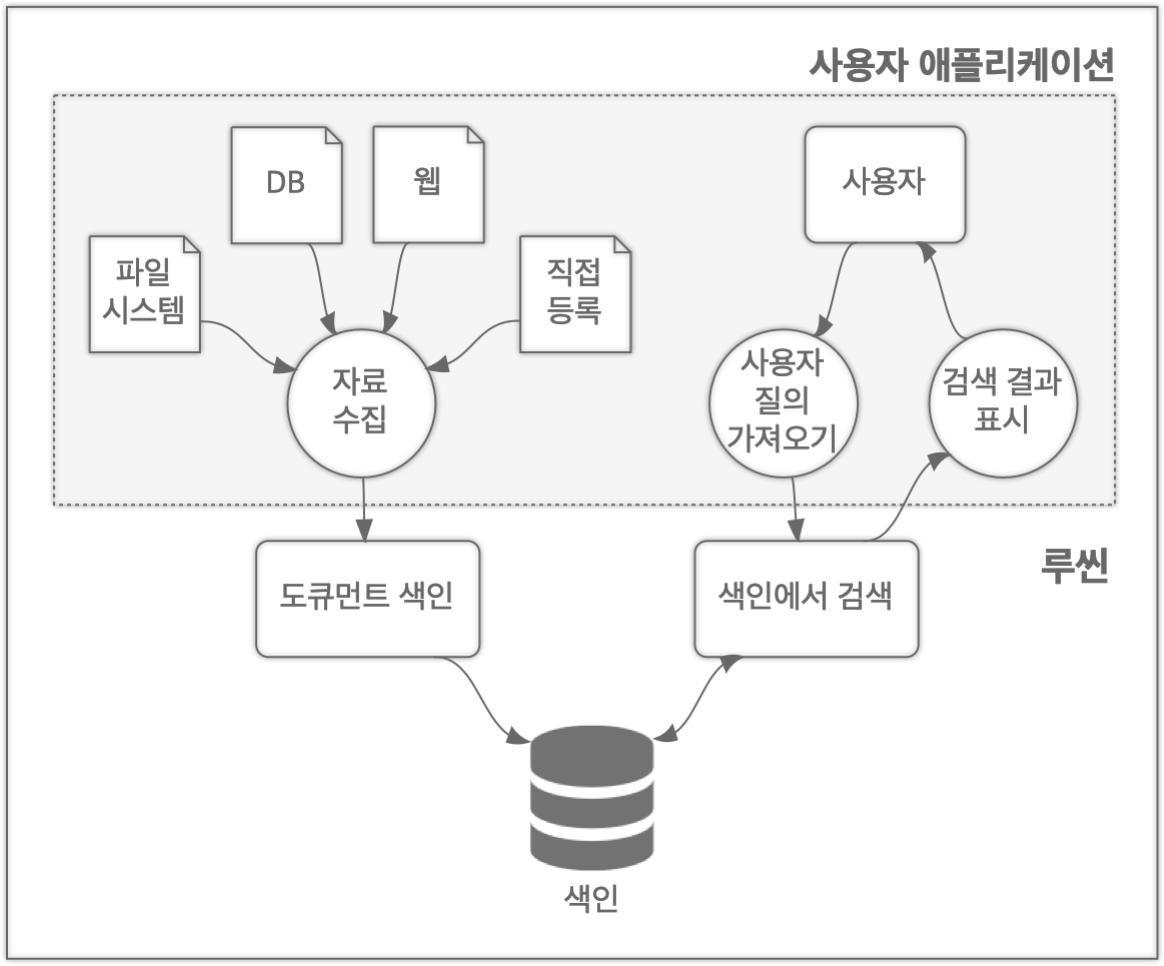
-
"자료수집"을 "크롤링"이라 생각하고, 그렇게 모여지고 이미 색인된 데이터를 end-user(사용자)는 query한다.
-
이 "자료수집"의 본질은 ES로 가면서 데이터(JSON Document)를 인덱싱해서 여러 데이터 노드에 분산 저장해서 빠르게 검색하고 분석하는 Document Database 면모로 갖춰지게 되었다.
2. ES 시스템 및 데이터 구조

- RBD와 핵심 차이는 위와 같다. RDB는 특정 value를 찾기위해 특정 table의 모든 record를 보면서 체크하지만, ES에서는 특정 텍스트값 기반으로 이미 어떤 docment에 포함되어 있는지 색인이 되어 있어서, 찾는 속도에서 차이가 날 수 밖에 없다.

-
이해하기 쉬운 RDBMS의 물리&논리 단위를 ES와 비요해서 정리한 표다. 참고로 꼭 주의할 점은 ES도 버전에 따라 이런 단위가 달라지고 있다!! 위 표는 ES 7.X.X 버전 이전이다. 시초에 가깝다.
-
ES 7.X 이후 버전은 Type이 사라지고, Index가 Table과 유사한 개념으로 바뀌었다. 이 글은 ES 7.X 이후 버전 중심으로 작성되었다!
-
그리고 ES의 편리한 점은 "자체 restAPI" 를 지원한다는 점이다. insert, query할 때 또는 다양한 configue에 http request를 기본적으로 rest-full하게 활용할 수 있다.
1) 기본적인 시스템 단위
-
Cluster: 독립된 elasticsearch 시스템 환경, 1개 이상의 노드로 구성. 1개의 elasticsearch만 구동해도 1개의 cluster로 구성을 하게 된다. 그 이상의 노드로 구성된 elasticsearch cluster는 내부적으로 데이터를 교환하지 않는다.
-
Node: 실행중인 elasticsearch 시스템 프로세스 단위다.
-
Document: 저장된 "단일" 데이터 단위, 흔히 RDB에서 record와 비교되는 단위이다.
-
Index: document의 "논리적집합"을 의미한다. RDB에서의 table과(es7이후) 비교되는 단위이다. 기본적으로 index는 1개 이상의 shard로 구성되어 있다.
-
Shard: index(색인)과 search(검색) 진행하는 작업 단위(thread)를 말한다.
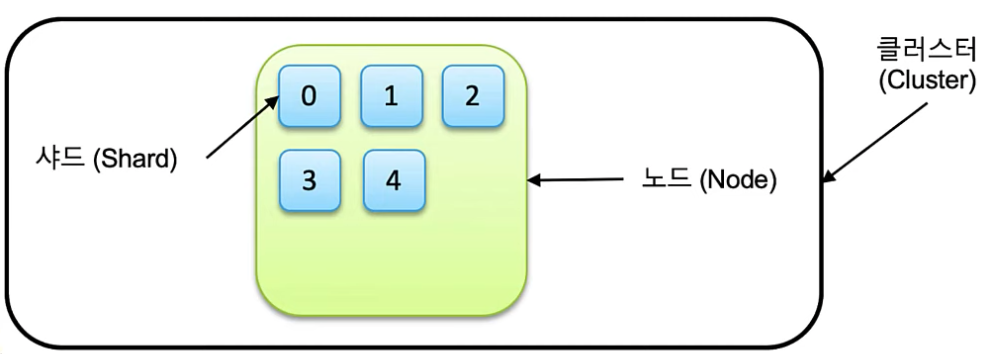
2) Shard
- 샤드는 기본적으로 primary shard와 replica 으로 구성된다.
- 각 샤드들은 클러스터 내의 노드들에 분산되어 저장된다.
- 같은 프라이머리 샤드와 복제본은 같은 데이터셋을 담고 있으며 반드시 다른 노드에 저장 된다.
- 데이터 노드가 1개인 경우 복제본은 생성되지 않는다. 아래 그림 말고 위 그림이 노드가 1개인 경우라 복제본이 없다.
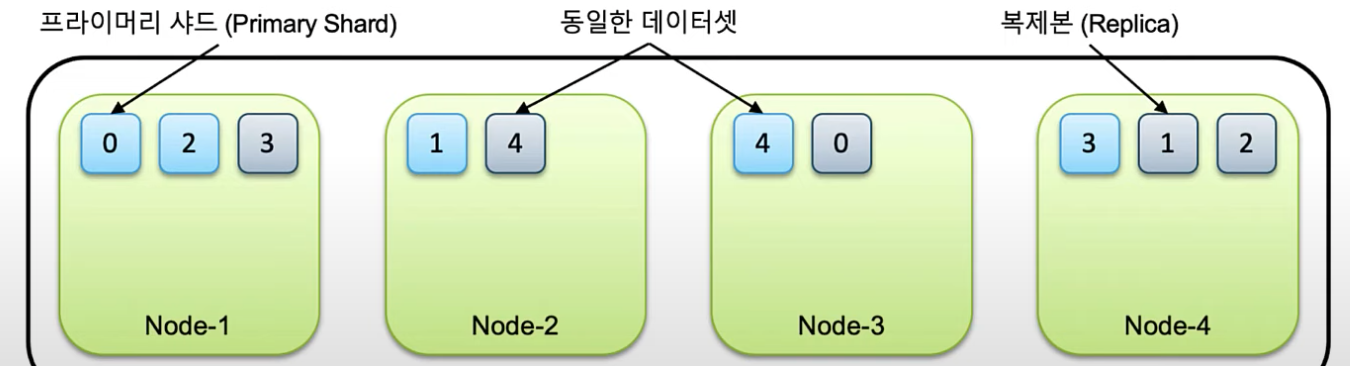
- 이런 구조기반으로 기본적인 "데이터 무결성"을 유지한다. 노드가 유실되면 남아있는 샤드의 데이터를 다른 노드로 복사한다.
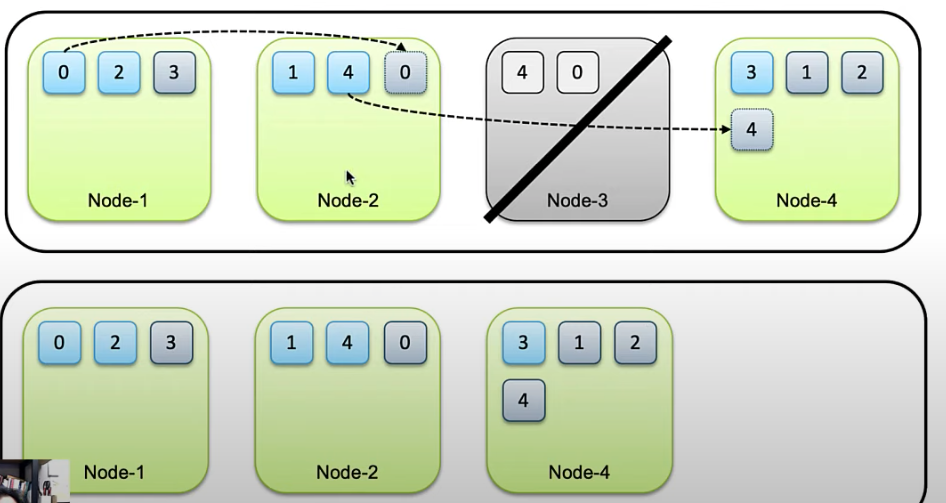
- 각 index별로 primary shard와 replica set 수 설정을 할 수 있다. 당연하지만 replica set이 0인 경우는 무결성을 유지하기 힘들다.
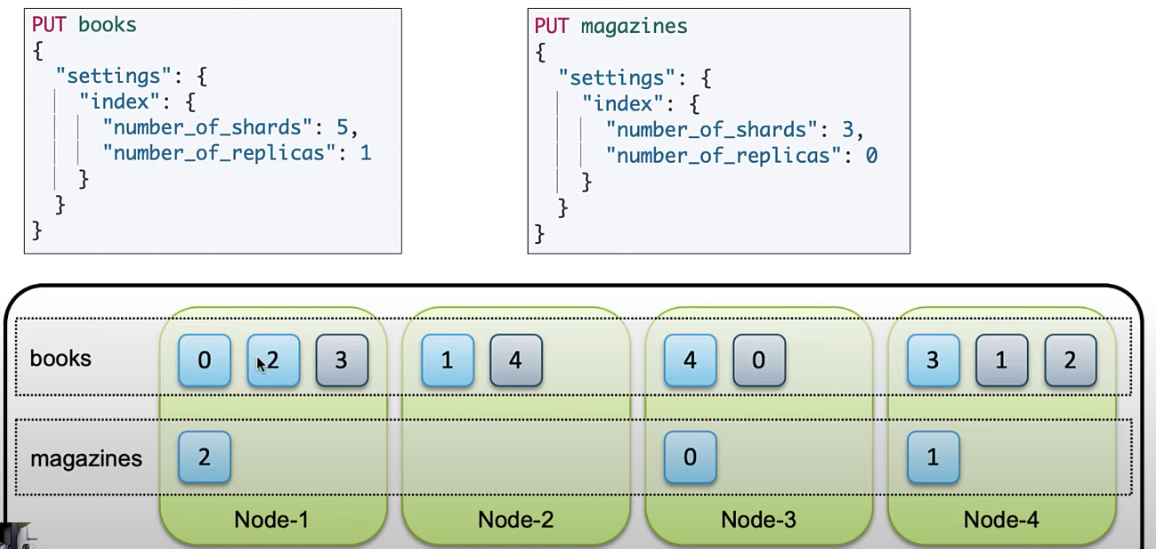
- primary shard는 기본적으로 "처음 인덱스 생성 시점" 에서 설정한 이후에는 변경이 불가능 하다. 하지만 replica set의 개수는 언제든지 변경할 수 있다. 위 그림에서 세팅한
books의 replica set 변경은 아래와 같이PUT books/_settings요청으로 가능하다.
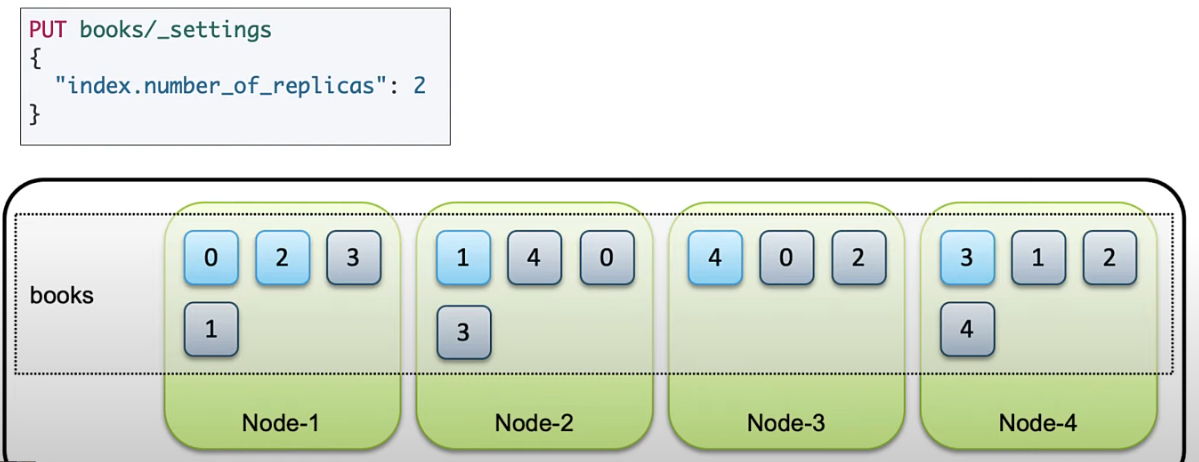
3) ES 데이터 활용하기
3-1) ES 데이터 insert와 shard
-
ES에 데이터가 입력이 될때, 데이터를 색인할때 index에 해당하는 모든 shard에 Round Robin 방식으로 입력된다.
-
사용자는 어떤 docment가 어떤 shard에 적재되는지 알 수 없다 -> 알 필요가 없다. 메인을 통해서만 search & insert 를 하면된다.
-
myindex라는 index가 존재하고 5개 shard구분이 되어 있다고 가정한다면, 데이터를 넣을 때 마다 doc id 를 지정했는데 그 id를 hash한 result에 해당하는 shard의 number로 RR 방식으로 적재된다.
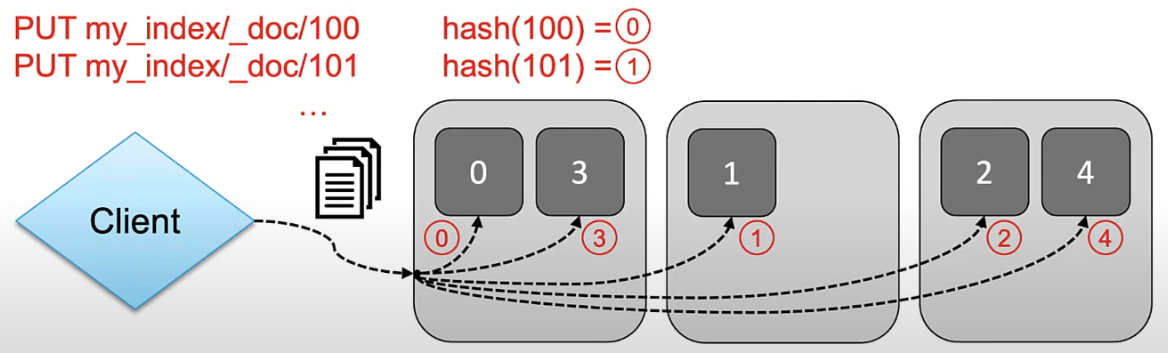
-
doc-id를 특정하지 않고 랜덤하게 넣으면 대체적으로 균등하게 적재되게 되어 있다.
-
검색을 할 때도 요청을 받은 노드가 해당되는 모든 샤드에 검색 명령을 전달한다. 최초로 검색 전달을 받은 노드를 "coordinate node"라고 부른다.
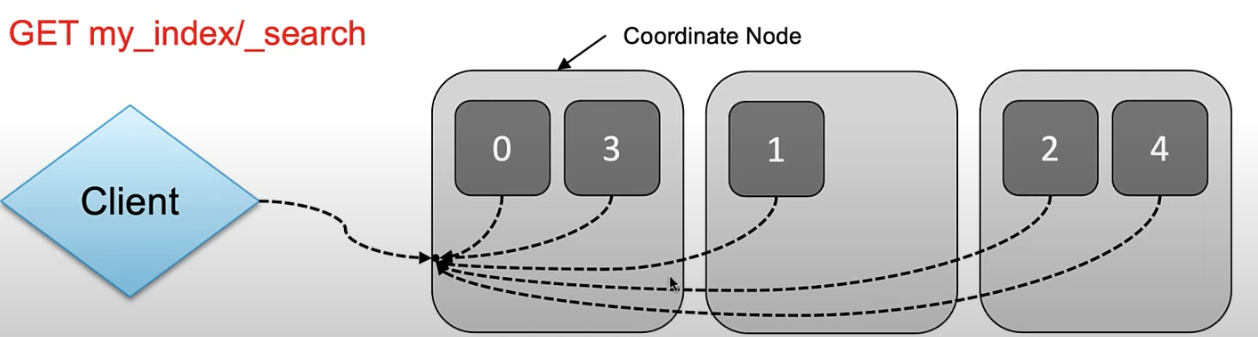
-
각 샤드별로 분산 실행되고 결과는 다시 요청받은 노드, coordinate node로 전달되어 취합된 후 client로 response를 준다. 위에서 언급했듯, 이 코디네이터 노드랑 통신하면 되기 때문에 사용할때 어떤 shard에 저장되는지, 어떤 shard와 통신할지 고민할 필요가 없는 것이다.
-
shard는
settings: { index.number_of_shards }로, index별 개수 설정이 가능한 것을 확인했다. 이 개수 세팅이 실제 운영에서는 중요하다. -
인덱스용량에 따라 적절한 수의 샤드로 구성해야 한다. 인덱스를 선언하지 않고 바로 document를 insert해도
schemless라는 세팅으로 자동 index를 세팅하며 샤드 개수에도 default 설정을 따른다. -
따로 개수를 설정하지 않으면, 6.X 버전 까지는 default primary shard 5개. 7.X 버전 이후로는 default primary shard 1개로 설정된다.
3-2) 멀티테넌시 - multitenancy
-
ES에서는 서로 다른 인덱스를 "묶어서 한꺼번에 검색" 가능하다. 쉼표로 나열하거나 와일드 카드 사용가능하다. ex)
GET book,magazines/_searchorGET filebeat-*/_search -
그렇기 때문에 로그 데이터 같은 경우 날짜 (일, 월 등) 단위로 데이터를 쌓는 것이 여러 모로 용이하다. 필요한 검색 범위만 최소화 할 수 있다. ex)
GET logs-2022-06*/_search날짜로별로 인덱스 삭제가 가능하니 disk overhead 역시 최소화 할 수 있다.
3-3) ES초기의 Oversharding 문제
-
초기 ES는 무결성과 분산성을 위해 index를 적절한 수 shard로 나누는 것을 권장했다. 하지만 활용법이 확대되면서, shard보다 index로 나눈 multitenancy 활용이 많아졌다.
-
샤드당 권장 사이즈는 system spec에 따라 다르지만, 보통 10-50GB가 수용이 가능하다. 너무 많이 나눠도 별로니 적절하게 나누는게 좋다.
-
Filebeat 등에서는 용량과 상관 없이 날짜별로 index를 생성하니, 6종류 인덱스를 180일간 보관하는 경우는
6(index) * 5(shard) * 180(days) = 5,400개의 샤드가 유지된다. (6.X 이하 버전에는 default shard가 5개) -
샤드를 충분히 나누지 않아 활용 못하는 경우보다 shard 수가 "너무 많아서 발생하는 문제가 많아 졌다." 그래서 7.X 이후에는 default shard를 1개로 변경했다.
3-4) Alias API
-
이름과 같이 index 별칭과 같은 느낌이다. 하나의 alias에 복수개의 index를 연결 가능하다. 여러개의 index가 연결된 경우 조회만 가능하다.
-
여러개의 경우 GET만 가능하지만 alias와 index가 1:1인 경우 insert, delete도 가능하다. 그래서 alias를 2개 세팅해두면 편하게 되는 것이다. 1개는 나머지 인덱스 조회 전용으로, 1개는 가장 최근의 index로 1:1
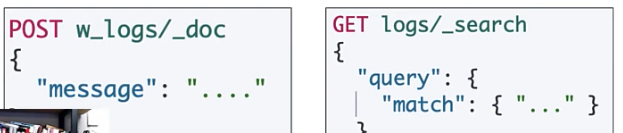
- 이렇게
w_logs는 "쓰기전용"으로 만든다. 조회를 할때는logs로 하면된다. 조회 전용으로 이logs관련된 index 다 alias로 묶어 버리면 된다.

-
왼쪽 사진은 위에서 언급한것과 같이
index "logs-*", logs-... index를 모두 하나의 logs와 같이 alias로 묶는다. -
오른쪽 사진은
w_logs를 write전용으로 할 alias index를 바꿔버리는 것이다.
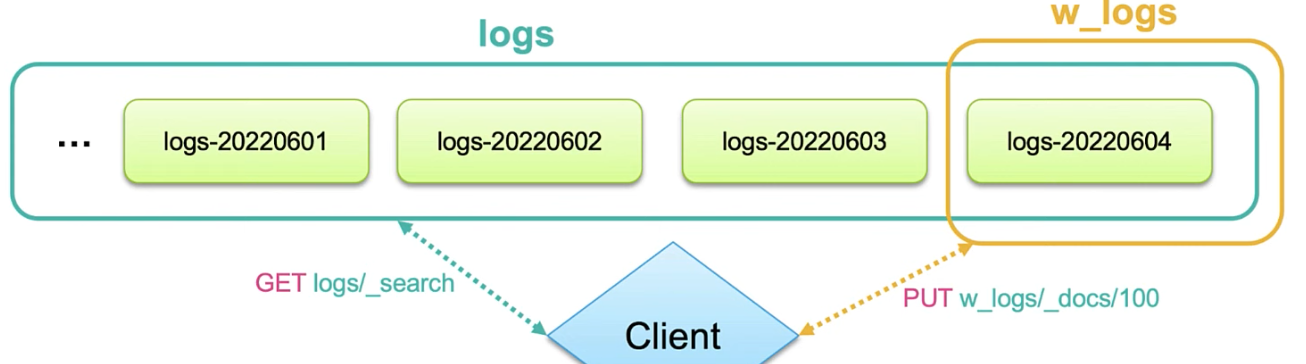
-
이 흐름을 그림으로 보면 위와 같다. 다양한
logs-...index를 지속적 단일 검색logs/_search로 가능하며 write할때는 alias만 바꿔주면서 1:1 상태로 유지하면 된다. 이러면 code level을 바꾸는게 아니라 alias만 바꾸면 된다. (client설정도 변경이 필요가 없다.)
3-5) Rollover API
-
날짜 기준으로 index를 나누면 샤드 용량에 최적화해서 사용하지 못한다. 어느날은 log가 한 샤드가 못버틸 수도, 어느날은 한참 모자를 수도 있다. 이런 경우 "샤드 용량에 최적화" 해서 쓸 수 있게 하는
rollover를 활용할 수 있다. -
rollover는 기본적으로 날짜가 아닌 용량을 기준으로 인덱스를 새로 나누어 생성 가능하게 해준다. index가 아닌 alias 또는 datastream을 대상으로 실행 한다.

-
POST my-logs/_rollover경우,my-logsalias에 해당하는 인덱스들이 7일이상 경과 또는 도큐먼트 1000개 이상 또는 사이즈가 10GB 이상이라면my-log-000000을 back-up index처럼 세팅하며,my-log-000001을 새로 만들어 준다. 이런 행위를 자동으로 해주는 것이 rollover API 이다. -
rollover 조건에 만족되었다고 자동으로 인덱스가 만들어지는 것이 아니라,
POST <인덱스>/_rollover를 입력해야 새로운 rollover index가 생성된다. 그래서 해당 명령어를 백단에서 주기적으로 실행할 필요가 있다.

- 주기적으로 실행해야 하기 때문에 ILM(index lifecycle management)로 제어하는 것이 바람직하다. (추천되어 진다.) 키바나에 Data -> ILM 메뉴 -> Rollover 세팅할 수 있는 곳이 있다.
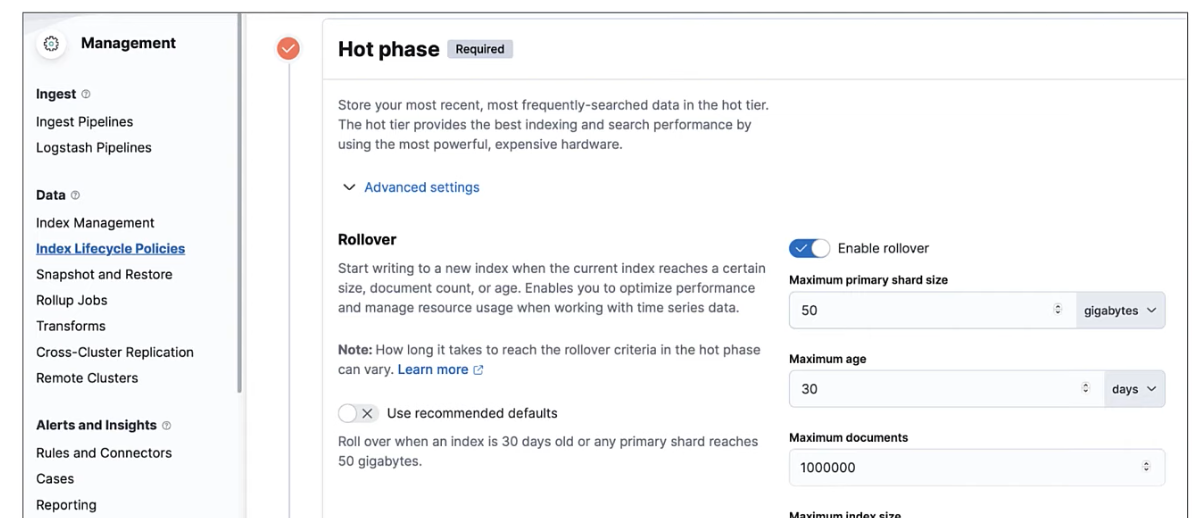
4) 데이터 스트림 (Datastream)
-
색인은 입력 alias, 검색은 조회 alias, 계속하다보니 더 복잡해진다. 오히려 원래 인덱스 처럼 그냥 한군데로 다 하면 안되는 것일까?
is_write_index이런 설정도 귀찮다! 해서 등장하게 된 것이다. -
데이터가 계속 추가(append)되는 시계열(로그, 메트릭) 데이터에서 사용한다. 일반 인덱스를 사용하듯 데이터스트림을 대상으로 데이터 색인, 검색 가능하다. 데이터스트림 뒤에 하나 이상의 히든 인덱스를 자동으로 구성하고 알아서 확장 한다. (자동으로 rollover)
-
반드시 기준이 되는 date, date_nanos 타입의 @timestamp 필드가 필요하다. 우리가 사용할 때 alias처럼 접근하면 된다.
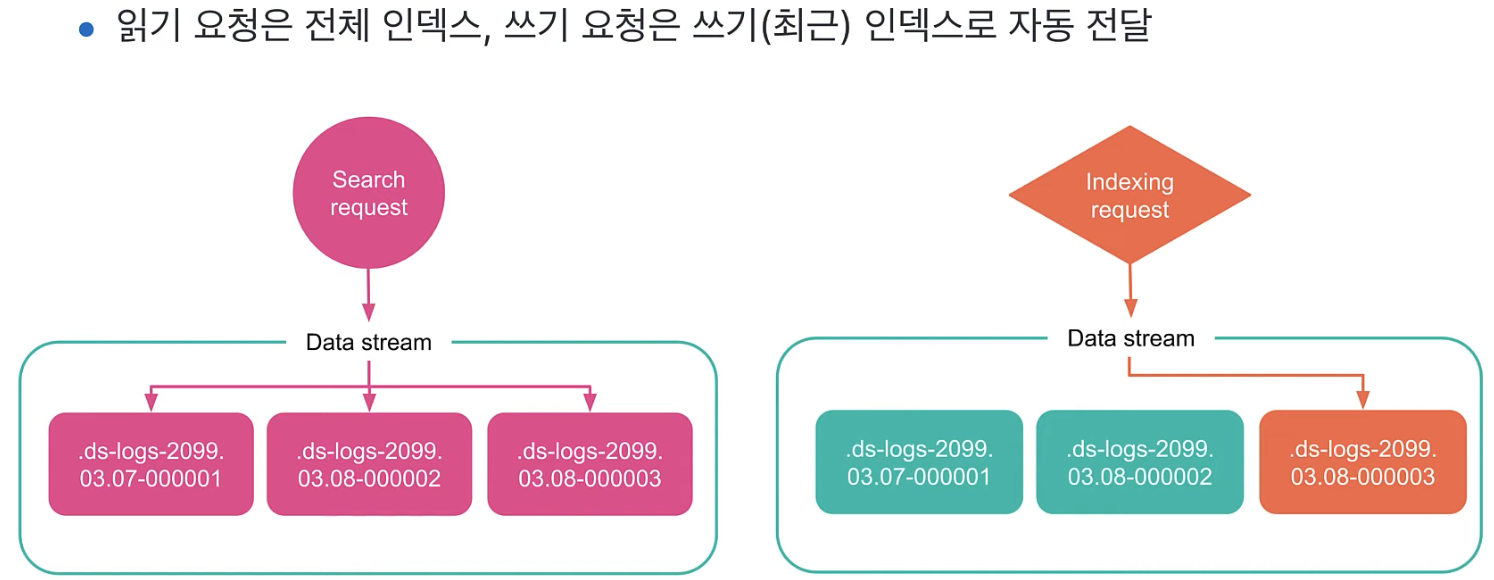
-
이 index로 search 또는 insert를 알아서 하면, 알아서 데이터 스트림이 alias를 사용하듯이 처리한다. 그래서 rollover 대상으로 직접 지정 가능하며, 숨겨진 인덱스들은 "정해진 네임규칙"에 의해 자동 생성된다.
-
.ds-<데이터셋>-<yyyy.MM.dd>-<generation>형태를 따른다.데이터셋은 임이의 데이터스트림 구분자이며,generation은 6자리의 십진수 "시퀸스, 순번값" 이다. -
데이터 추가, 조회만 가능하며 삭제, 변경은 불가능하다. 이 부분이 alias와의 가장 큰 차이점이다. 하지만 숨겨진 인덱스에 직접
Update by Query, Delete by Query API를 사용하면 삭제 또는 업데이트가 가능하다.
4-1) D.S 설정 순서
- ILP 설정을 하고, index template을 설정해야 한다. index template 설정 수순은 아래 사진과 같다.

- 그리고 마지막으로 Datastream 생성 및 연결을 위해
POST <데이터셋>-.../_doc명령으로 도큐먼트 입력한다. index template 설정으로 인해 이렇게 index 만들 듯이 도큐먼트 저장을하면 자동으로 Datastream으로 저장이 된다.
5) Elastic Integrations & Elastic Fleet
-
자주 사용되는 데이터셋을 쉽게 수집하기 위해 제공되는 256개 이상의 템플릿이 있다. 키바나에서 integrations를 살펴보면 되며, 기본적으로 다 Datastream으로 저장이 된다.
-
Elastic Fleet은 elastic agent 들을 한곳에서 관리하는 도구다. 수집하는 호스트 별로 elastic agent 설치 및 저장, 수집하는 데이터 종류 별로 agent policy를 설정한다. 설치된 elastic agent 에 agent policy 연결하여 적용한다. 즉 호스트별로 일단 agent 설치 후에 fleet으로 전체 관리를 하는 것이다.

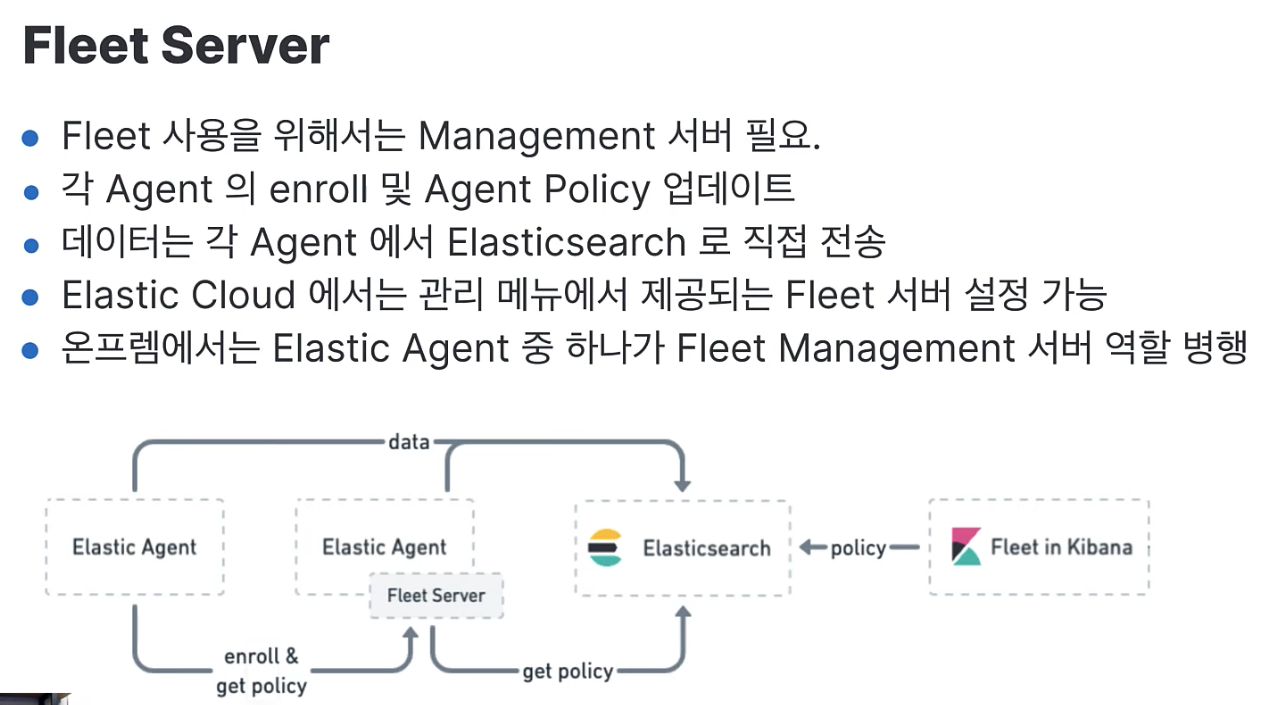
- fleet server가 middleware 처럼 agent를 전체 총괄하게 된다. kibana의 UI를 통해 컨트롤하면 fleet server가 중계를 해주는 것이다.
마무리
-
해당 글은 앞서 언급한 대로 Datastream - 새로운 Elasticsearch 데이터 구조 이해하기 동영상 내용 정리가 주된 내용이다. 해당 영상에서 실제 데모를 직접 시연하니, es 사용에 관심있다면 꼭 한 번 살펴보는 것을 추천한다.
-
생각보다 ES가 개발자 편의를 위해 아주 다양하게 툴을 만들어 내고 있는 것을 깨달을 수 있었다. 동영상을 보고 "내가 한 것은 elastic만 사용해서 search만 깨작거린게 다구나" 라는 것,, 이제 kibana와 elastic은 몰아일체의 수준까지 온 것 같다.
-
개인적으로 PLG도 사용했지만, log 찾는 수준이 엔터프라이즈에 맞지 않았다. 단순 모니터링 목적에 오히려 더 많이 부합했고, 진짜 데이터 시각화와 인사이트를 위해 활용하는 것은 개인적으로 elastic이 무겁지만 훨씬 더 사용할만 했다.
(볼륨을 생각해 보면 당연한 것이 아닐까 하긴 한다 ㅎ) -
이제 elastic의 기초와 베이스를 가지고 ELK stack을 기반으로 우선 M.Q (or Event Que) 없이 CDC 또는 다양한 log 수집기 같은 환경을 만들어 보자.
출처
