
Dev-Event-Slack-Bot
용감한 친구들의 "개발자 컨퍼런스 및 해커톤 일정(https://github.com/brave-people/Dev-Event)" 을 알려주는 repo 기반으로, 주 1회씩 해당 내용을 정리해서 전송하는 slack bot을 만들어 보자! 깃허브에서 확인하기!
논리적 기획 및 설계
-
작은 규모의 볼륨으로 웹서버와 같이, API 서버(flask)도 덧붙여서, cron과 함께 다 같이 dockerizing 하여 배포하려고 했지만, 욕심만 늘어나서 진짜 딱 하나의 최초 목적에만 우선적으로 집중해서 배포하기로 했다. (logging 확인을 위한 API, send hook log check, 통계적 기능, process checker, admin의 기능도 사실 어느정도 염두 해 두긴 했었으나, 배보다 배꼽이 크다.)
-
과유 불급, 일단 무조건 목적에 맞는 기능 하나라도 제대로 완성해서 배포하자!
-
Dev-Event 라는 repo에서는 "개발자 컨퍼런스 및 해커톤 일정을 아낌없이 알려준다" 라는 슬로건으로 아주 유익한 정보를 전달 해 준다. 벌써 꽤 볼륨과 star, watch의 규모가 커졌다.
-
해당 repo에서 파생되어 Dev-Event-Subscribe 에서는 github "watch" 기능을 활용하여 issue를 (PR와 같이) 올려 watch 한 사람들의 github 계정 메일로 이메일을 보내는 역할을 하고 있다.
-
그리고 사실 이 slack-bot은 (2)의 Subscribe repo에서 파생되었다. (2)의 레포 issue가 올라오는 시간은 매 주 일요일 약 19:30 ~ 20:30 사이이다. 이 시간대 사이를 노려 크롤링 하고, 신규 컨텐츠를 파싱하여 slack-bot에게 전달해 해당 slack-bot을 멤버로 추가한 모든 채널에 만들어진 message를 보내게 하는 것이 기본 기획 흐름이다.
코딩
핵심 로직과 물리적 설계
크롤링과 slack bot이 message를 보내기까지
-
위 기획 및 설계에서 (3)을 조금 더 상세 한 전체 흐름은 아래와 같다.
- Dev-Event-Subscribe 의 “issues” 를 크롤링 한다.
- 크롤링 한 정보를 csv 파일로 저장한다.
- 최초시 csv 를 만든다 (csv가 존재하지 않으면 최초로 인식)
- 최초가 아닐 경우, 이미 있는 csv 파일 (과거의 것) 과 새롭게 크롤링한 정보와 대조한다.
- 정확하게 issue의 url 를 체크한다.
- 바뀐 것이 있으면 변화(새롭게 올라온 것으로)로 여기고, 훅을 보낼 데이터를 만들고, 이벤트 정보를 모두 send_message (hooking) 합니다
- 그리고 바뀐 것으로 csv를 다시 저장한다.
-
그리고 결국, csv 대신 mongodb atlas(free) 를 선택했다.
디렉토리
├── core
│ ├── __init__.py
│ ├── config.py
│ ├── db
│ │ └── mongodb.py
│ ├── exception_handler.py
│ └── slack.py
├── crawler
│ ├── __init__.py
│ └── crawler.py- 필요한 핵심덩어리들은 아래와 같다.
core>dbdb connection 과 query - Repository 역할 / DTO는 굳이 필요가 없음core>slack.pyslack API 활용해서 slack bot들에게 send message 명령을 핵심으로 다른 여타 slack과 관련된 로직 필요cralwer데이터를 가져올 crawler , 핵심 로직 flow (main)이 여기에 있어야 한다.core>crawler로 넣고, root 경로엔 main.py 만 두려고 했다.- 헤로쿠 배포과정에서 스케쥴러 실행 커멘드의 경로 인식의 문제로 위와 같이 변경되었다.
- 헤로쿠 배포를 살펴보면서 다시 살펴보자.
- 사실 추후에 slack app 배포를 위한 OAuth server + https 설정을 위한 nginx + certbot이 추가 된다. 그리고
git action으로 옮긴다.
-
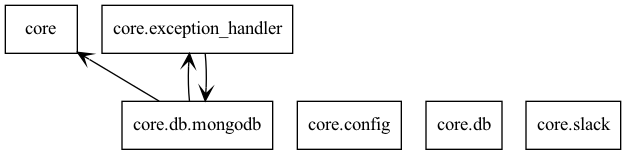
core는 위와 같이 이뤄져 있다. 사실 여기에 crawler도 있었고, 최대한 각 class간의 디펜던시는 없게, 단일 작업을 빠르게 하는 것이 목표라 싱글톤으로 진행했다. 코드 자체의 완성도는 좀 더 올려야할 것 같다.
-
핵심적인 class는 "Repository", "Slack", "Crawler" 세 덩어리이다.
main -> Crawler -> [ Slack, Repository, Logging ]와 같은 형태로 object를 가져와서 실행한다.


- 더 자세한 코드는 repo에서 위 구조기반으로 살펴보면 더 쉽게 확인 가능하다.
배포
heroku + heroku Advanced Scheduler
heroku
-
Heroku는 대표적인 PaaS(Platform-as-a-service) 이다. 헤로쿠에 대한 얘기를 하면 너무 길어지기 때문에 배포를 위한 헤로쿠 사용으로 바로 살펴보자.
-
핵심은 헤로쿠는 시대를 앞서간다는 평가도 받는, "클라우드 컴퓨팅 앱 배포", "개발자는 인프라에 신경쓸 필요가 없다", "오토스케일링", "간편한 확장과 책임지는 보안", "CLI 기반으로 git 만큼 간단한 버전관리 및 배포", "많은 써드파티와 add-on" 그리고 무료인 PaaS 이다.
-
하지만 2022.11 기준으로 무료를 결국 폐지하기로 한다. 그동안 헤로쿠 고생많이했다. 칼럼ㅣ한때 잘 나갔는데... ‘헤로쿠’가 시들해지는 이유 글이 재미있다. 우선 사용하려면 회원가입을 해야한다!!
-
회원가입 후
create a new app으로 app을 하나 만들고 region을 세팅하자.
heroku cli
-
헤로쿠는 cli로 쉽게 컨트롤이 가능하다. https://devcenter.heroku.com/articles/heroku-cli#install-the-heroku-cli 에서 살펴보자.
-
(mac기준) 먼저 brew 패키지 매니저로 install을 하자
brew tap heroku/brew && brew install heroku -
설치 확인을 위해
heroku --version커멘드로 헤로쿠 버전이 잘 나오는지 확인하자. -
이제
heroku login으로 cli 기반 heroku 로그인을 진행하자.
git + heroku cli
-
이미 git으로 버전관리 중인 디렉토리로 가서 (버전관리 중이 아니어도
git init부터 해서 진행하면 된다) heroku에게 이 git remote를 기반으로 heroku에 배포하겠다는걸 알리자 -
heroku git:remote -a <app-name>그러면 remote branch가 하나 더 생기는 것과 동일하다. add, commit 하고git push heroku <branchName>으로 push 하면 사실 배포가 된다. 그 이전에 아래 설정을 해 주자. -
python 기반 application을 위한 build pack 세팅해주기
heroku buildpacks:set heroku/python- 자세한 설명은 헤로쿠 offical docs
-
requirements.txt으로 사용하고 있는(디펜던시) python lib 명시하기pip freeze > requirements.txt
-
runtime.txt으로 run time의 python version 명시해주기- python version 체크 후
echo 'python-3.9.10' > runtime.txt
- python version 체크 후
-
배치 성격의 스케쥴러를 러닝할 것이기에, 혹시나 하는 heroku app server time zone 세팅하기.
heroku config:add TZ="Asia/Seoul"
-
위 설정을 하고
git push heroku main으로 배포하면 기본 준비 완료! -
이런 설정값은 어떤 형태의 앱을 배포하냐 에 따라 굉장히 다르다. django, flask 등에 Web-Application 관련 값들은 official docs를 확인하는게 가장 좋다.
heroku add-on : Advanced Scheduler
- 헤로쿠 앱 페이지에 Installed add-ons -> Configure Add-ons 으로 add-on을 추가하자.
Advanced Schduler를 사용할 것이다.
- 하지만 add-on 등록하려면 free 라도 우선 payment 를 등록해야 가능하다. 기본 가격 테이블은 아래와 같다.
| PLAN | Hobby | Primeum 0 | Primeum 1 | Primeum 2 |
|---|---|---|---|---|
| Task개수 | 3 | 15 | 30 | 60 |
| 매달 실행 횟수 | 1,000 | 50,000 | 100,000 | 200,000 |
| 실행 내역 보관 | 3 | 7 | 14 | 30 |
| 가격 | 무료 - Free | $15/월 | $30/월 | $60/월 |
- 1개 Task를 달에 30번 밖에 실행을 안할 예정이기에 Free 로 사용이 가능하다.
Create Trigger로 작업을 하나 만들자!
- 생각보다 설정을 해줘야 할 부분은 많지 않다. 작업 이름과 해당 작업을 위한 커멘드, 그리고 타임존 세팅을 해주자.
- 그리고 시크릿파일은 따로 쓰지말고, 앱 설정에 -> 환경 변수 세팅 (Reveal Config Vars)를 통해 직접 세팅하고, 코드에서는
os.environ.get('환경변수키이름', default)와 같이 접근하면 된다.
- 이런 설정값을 다 하고, 배포를 다시하자.
git push heroku main(branch name)
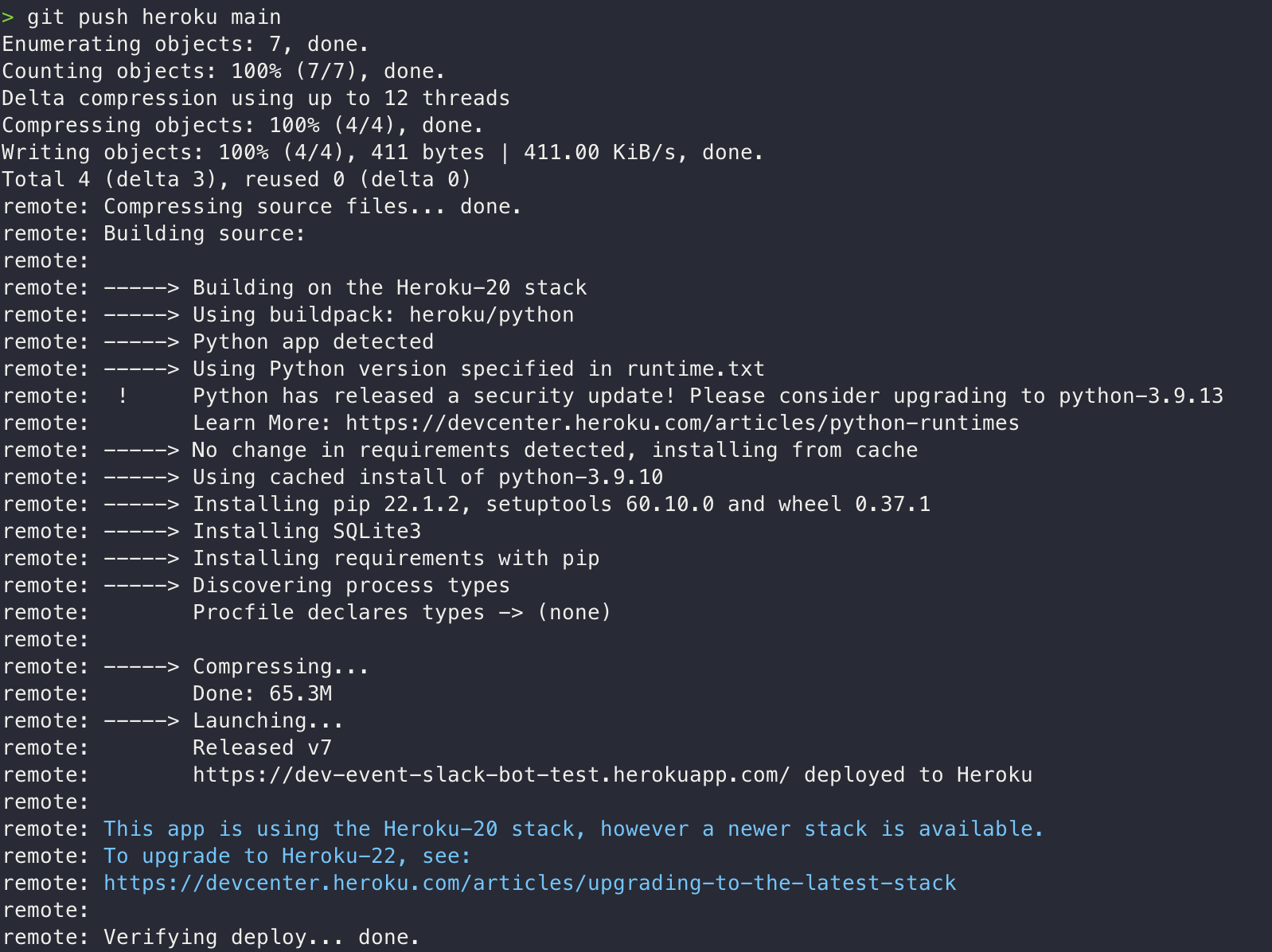
이슈
- 여기서 왜 csv 파일을 사용하지 않고, mongodb atlas를 사용하게 되었고 cralwer를 core에서 분리하고 main만 최상으로 빼내게 되었는가를 살펴보자.. 일단 나는 Advanced Scheduler 에 Task Command를
python main.py라고 했었다.
2022-08-19T09:21:34.322279+00:00 heroku[scheduler.5886]: Starting process with command `python main.py`
2022-08-19T09:21:34.918584+00:00 heroku[scheduler.5886]: State changed from starting to up
2022-08-19T09:21:35.892652+00:00 app[scheduler.5886]: Traceback (most recent call last):
2022-08-19T09:21:35.892670+00:00 app[scheduler.5886]: File "/app/main.py", line 57, in <module>
2022-08-19T09:21:35.892756+00:00 app[scheduler.5886]: exception_handler(exc)
2022-08-19T09:21:35.892765+00:00 app[scheduler.5886]: File "/app/core/exception_handler.py", line 14, in exception_handler
2022-08-19T09:21:35.892826+00:00 app[scheduler.5886]: raise exc
2022-08-19T09:21:35.892828+00:00 app[scheduler.5886]: File "/app/main.py", line 48, in <module>
2022-08-19T09:21:35.892885+00:00 app[scheduler.5886]: msg_txt_list: list[dict] = crawler_run()
2022-08-19T09:21:35.892887+00:00 app[scheduler.5886]: File "/app/crawler/crawler.py", line 160, in crawler_run
2022-08-19T09:21:35.892978+00:00 app[scheduler.5886]: return crawl.data_compare()
2022-08-19T09:21:35.892986+00:00 app[scheduler.5886]: File "/app/crawler/crawler.py", line 127, in data_compare
2022-08-19T09:21:35.893055+00:00 app[scheduler.5886]: standard_data_list = self.get_standard_data()
2022-08-19T09:21:35.893057+00:00 app[scheduler.5886]: File "/app/crawler/crawler.py", line 46, in get_standard_data
2022-08-19T09:21:35.893115+00:00 app[scheduler.5886]: return self.set_standard_data(self.data_parsing())
2022-08-19T09:21:35.893117+00:00 app[scheduler.5886]: File "/app/crawler/crawler.py", line 53, in set_standard_data
2022-08-19T09:21:35.893176+00:00 app[scheduler.5886]: with open(self.FILE_PATH, 'w', encoding='utf-8') as file:
2022-08-19T09:21:35.893196+00:00 app[scheduler.5886]: FileNotFoundError: [Errno 2] No such file or directory: 'None/data/standard_url.csv'- 일단 csv파일을 배포에 사용하지 않고 file I/O로 해당 파일을 가져오지 못한다.
- 그리고
sys.path가 어떻게 되어있는지 제대로 파악하기 힘들다. 즉 내가 원하는 대로sys.path를 세팅할 수 없다. - 직접 세팅하는 file logging 은 의미가 없다. 헤로쿠가 찍어주는 로깅을 활용해야 한다.
- 위 3가지 특성은 PaaS와 헤로쿠 코어에 대한 이해도가 낮아서 저런 배포형태를 가져갔었다. 우리가 굳이 비교를 하자면, k8s 에서 POD가 뜨면서 컴퓨팅을 하는 클라우드 환경을 생각해보자.
마무리
-
일단 스케쥴 세팅을 했으면 헤로쿠가 돌려줄 때 까지 기다릴 수 없다. 전체적 완성도는 떨어지지만 우선 바로 돌려서 확인해 보자!
-
참고로 slack app 만들기는 다음 장에서 다시 자세하게 살펴보자.

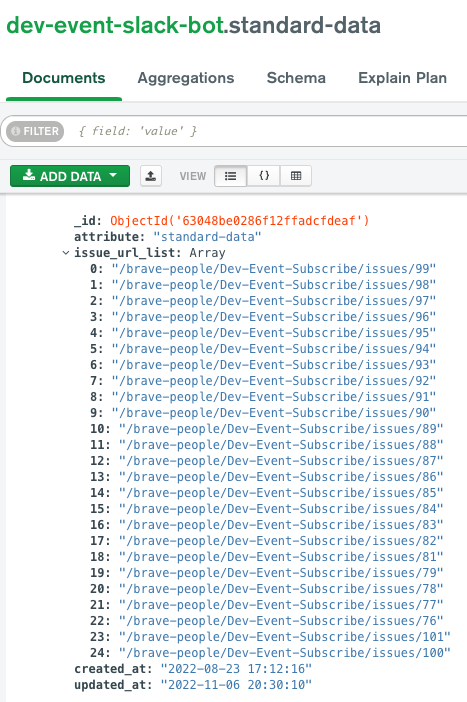
타겟 크롤링 이후 -> 파싱 -> 위 데이터과 비교 -> hooking이 핵심이라 standard data가 잘 되는지도 체크할 필요가 있다. 아주 잘 된다.
출처
