
프로세스(Process)란 무엇일까?
컴퓨터를 실행하면 디스크에서 메모리로 운영체제라는 프로그램이 로드됩니다. 운영체제는 사용자를 대신하여 하드웨어와 사용자 CPU 사이의 상호작용을 돕는데요. 사용자가 사용하는 애플리케이션은 디스크에 저장되어 있다가 실행하면 운영체제가 메모리에 가져와 프로그램의 인스턴스를 생성합니다. 이 인스턴스를 프로세스 또는 애플리케이션 컨텍스트라고 합니다.

프로세스에 대한 자세한 내용은 여기서 참고하자.
프로세스 관련 내용 정리된 블로그 <<
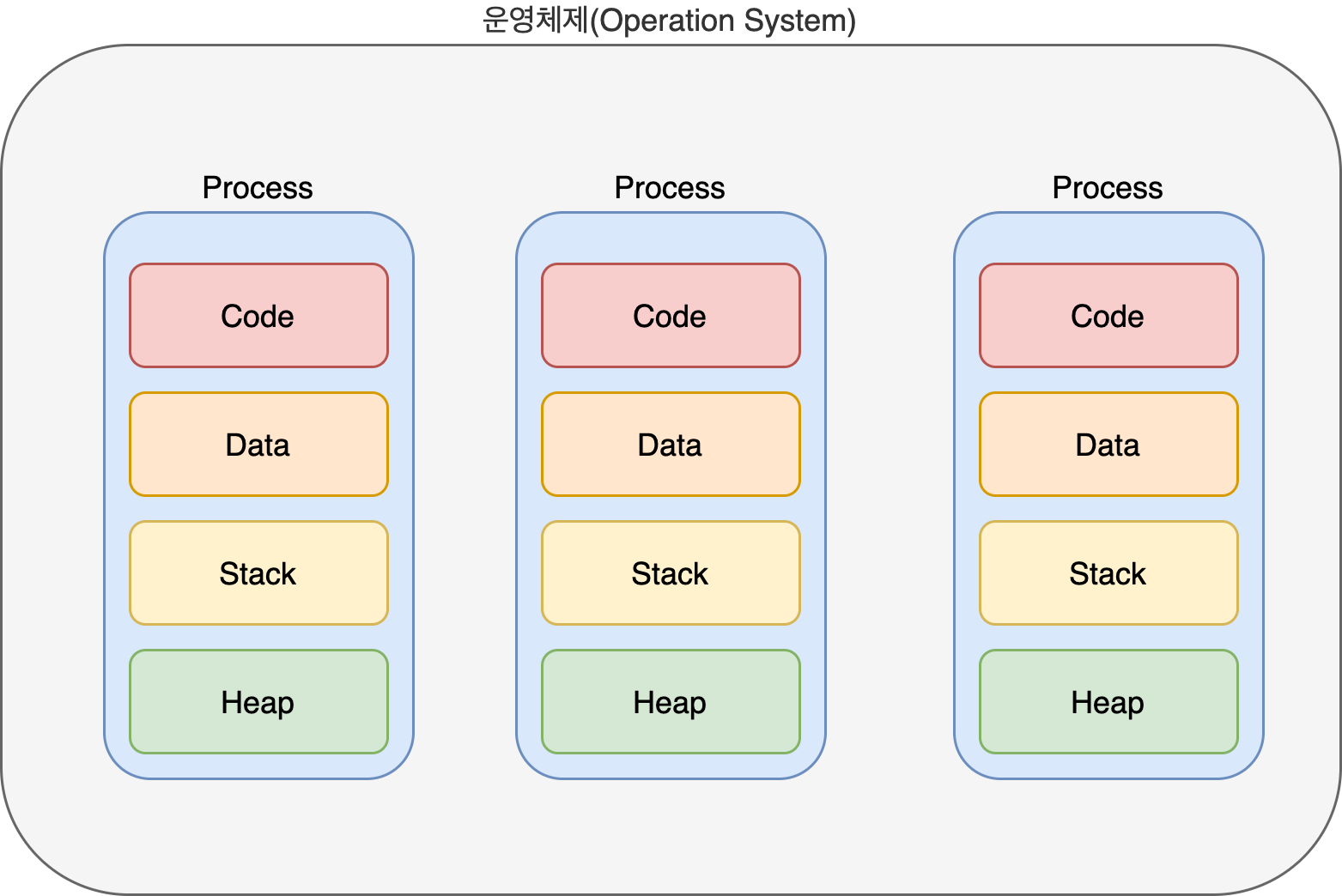
프로세스의 구성요소에 메타데이터에 대해서 보자면
프로세스안에는 PID 프로세스 아이디 : 애플리케이션이 읽고 쓰기 위해 여는 파일
코드 : CPU에서 실행되는 프로그램의 명령어
Heap 애플리케이션에 필요한 모든 데이터가 들어 있습니다.
그리고 메인스레드가 존재합니다.
각각의 프로세스는 별개입니다.
스레드(Thread)란 무엇일까?
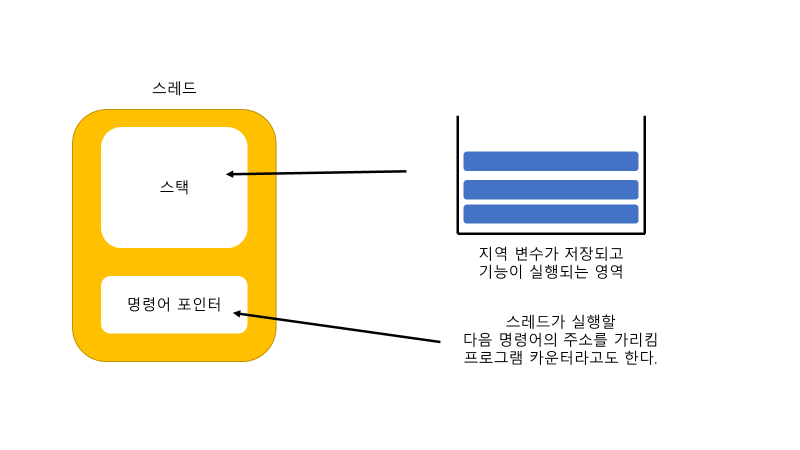
스레드는 프로세스내에서 실제 작업을 담당합니다.
스레드의 구성요소는 다음과 같습니다.
자바의정석 강의에서는 프로세스와 스레드를 공장과 일꾼으로 비유합니다.
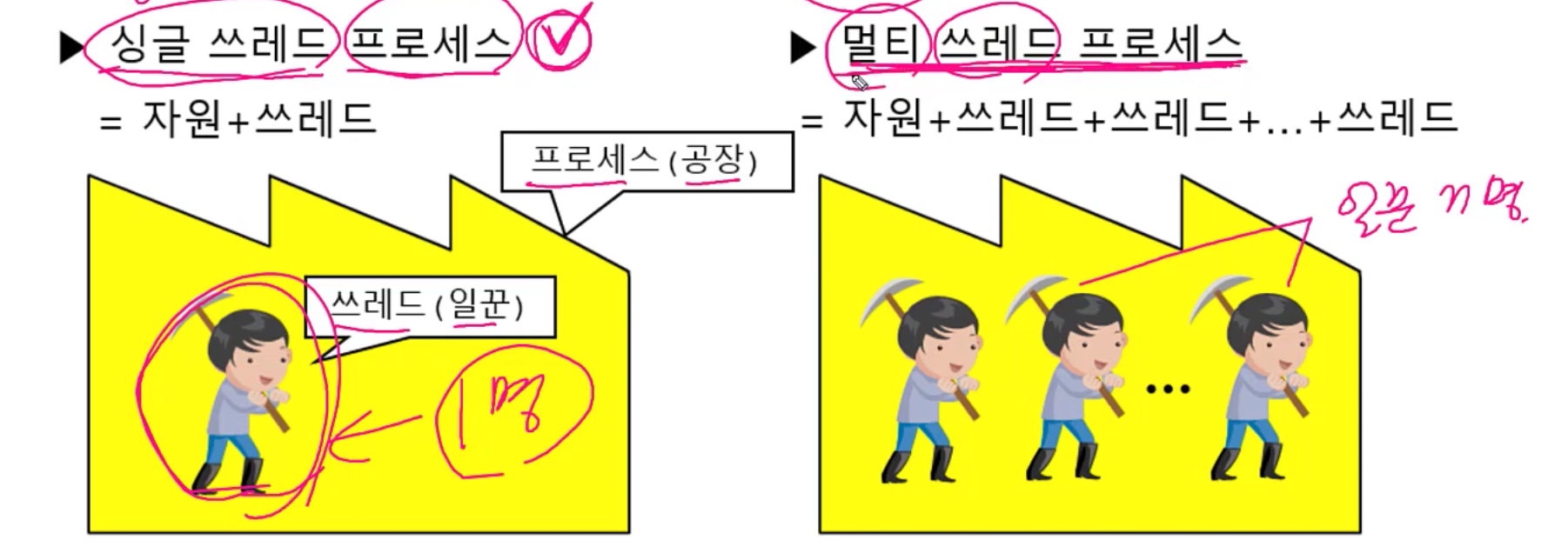
이 비유를 들고 좀 더 나아가볼까 합니다.
모든 쓰레드는 CPU를 놓고 경쟁합니다. 쓰레드가 작업하기 위해서는 CPU 실행을 두고 경쟁합니다.
CPU를 저는 이재용 회장님이라고 해보겠습니다.

삼성전자의 각각의 공장(프로세스)에 속한 직원(스레드)들은 회장님(CPU)이 옆에서 직접 감독한다.

만약 감독하는 사람(CPU)이 여러명이라면 이를 멀티코어라고 한다.
항상 스레드가 코어보다 많다.
스래싱과 컨텍스트 스위칭
그리고 CPU가 각 프로세스의 스레드의 일을 감독하고 다른 스레드를 부르기 전에는 스레드의 데이터를 모두 저장하고 다른 스레드를 호출하는데 이를 컨텍스트 스위칭(Context Switching)이라고 합니다. 너무 많은 스레드를 가동시키면 처리시간보다 이러한 컨텍스트 스위칭에 더 많은 시간을 쏟게 되고 스래싱(Thrashing) 문제가 나타납니다.
하나의 프로세스(공장)내의 스레드는 프로세스에 있는 자원(기억 장치, 프로세서, 디스크 등의 각종 하드웨어 장치나 메시지, 파일 등의 소프트웨어 요소)을 공유합니다. 그렇기 때문에 CPU 입장에서도 같은 프로세스 내의 스레드를 호출하는게 다른 프로세스 스레드를 호출하는 것보다 시간 소모가 덜합니다.
비유하자면 A공장에 있는 직원들을 감독할 때 A공장 직원들끼리 작업도구를 돌려 쓰는게 빠르지 A공장에서 감독하다가 특정 작업도구가 필요하다고 B공장 가서 B공장 직원 데리고 일하는 건 느리다는 말입니다.
멀티 스레드의 사용 이유
멀티스레드의 사용 이유는 뭘까요? 두가지 이유가 있습니다.
1. 응답성
2. 성능
응답성은 사용자에게 편의를 주는 부분입니다. 지금 우리가 사용하는 웹페이지를 보자면 여러 페이지를 띄워놓고 음악을 들으면서 글을 쓸 수 있습니다. 쇼핑몰에서는 구매자 한명을 줄 세워서 처리하지 않습니다. 수 천명의 거래를 동시에 처리할 수 있습니다. 만약 멀티스레드가 없다면 이러한 응답성의 개선을 이끌어 낼 수 없을 것입니다.
두 번째 성능은 싱글 스레드의 비해 다양한 작업을 처리할 수 있다는 점입니다. 이는 곧 비용절감으로도 이어질 수 있습니다.
스레드 생성방법
-
Thread 클래스를 상속받는다.
class 스레드 extends Thread { public void run() { // 스레드가 실행할 작업 *** } } public static void main(String[] args { 스레드 스래드1 = new 스레드(); 스레드1.start(); // 스레드 작업 시작 } -
Runnable 인터페이스를 구현한다.
class Runnable구현 implements Runnable { public void run() { // 스레드가 실행할 작업 *** } } public static void main(String[] args { 스레드 스래드2 = new 스레드(new Runnable구현()); 스레드1.start(); // 스레드 작업 시작 }
차이점은 Runnable 인터페이스를 활용할 때는 스레드를 생성할 때 파라미터로 넣어줘야 한다는 것입니다.
또한 Runnable을 이용한 스레드는 getCurrentThread()를 활용해서 스레드 함수를 사용할 수 있습니다. 왜냐하면 Runnable 인터페이스에서는 사용가능한 메소드가 1개밖에 없기 때문입니다.
start()를 이용해서 사용대기 상태에 올가게 되는데 이때 스레드의 순서는 OS가 판단하며, 두번 start() 메소드를 사용할 수는 없습니다. 작업을 또 하고 싶을 때는 새로운 스레드를 생성해서 수행해야 합니다.
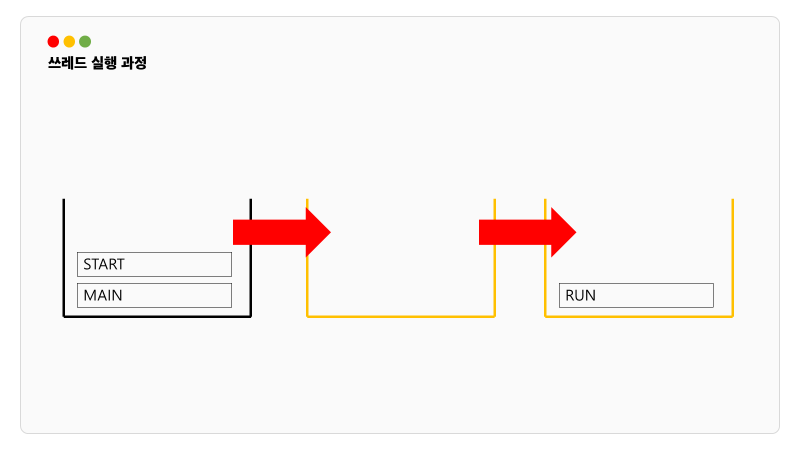
다음은 메인 쓰레드에서 특정 쓰레드를 start() 했을 때 콜스택 과정입니다. start()를 하면 해당 쓰레드의 콜스택이 만들어지고 run() 스택이 쌓이게 됩니다.
스프링부트에서 쓰레드 구현방법
@Async
자바의 Thread 상속, Runnable 인터페이스 구현과 다르게 스프링부트는 어노테이션으로 구현 가능하다.
-
메인 Application class에 @EnableAsync 를 붙인다.
-
비동기로 실행하고 싶은 메서드에 @Async를 붙인다.
class 스레드 extends Thread { public void run() { // 스레드가 실행할 작업 *** } } public static void main(String[] args { 스레드 스래드1 = new 스레드(); 스레드1.start(); // 스레드 작업 시작 }이렇게 작성하던 것을 다음과 같이 작성할 수 있다.
@SpringBootApplication @EnableAsync public class Application { public static void main(String[] args) { SpringApplication.run(YourApplication.class, args); } } @Service public class Service{ @Async public void 비동기영역() { // 스레드가 실행할 작업 } }
스레드의 우선순위
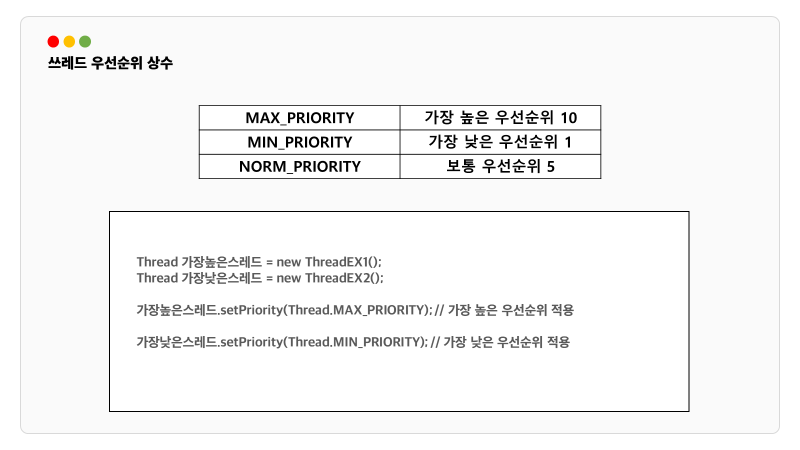
스레드는 우선순위라는 속성을 가지고 있습니다. 이 우선순위에 따라 스레드는 작업시간을 더 많이 가질 수도 더 적게 가질 수도 있게 됩니다. 우선순위는 스레드를 생성한 스레드로부터 상속 받습니다. main메서드를 수행하는 스레드는 우선순위가 5이므로 main메서드 내에서 생성하는 스레드의 우선순위도 자동으로 5가 됩니다.
우선순위 적용 방법

스레드 우선순위 상수
스레드 우선순위 주의점

쓰레드의 그룹

JVM이 시작되면 system 쓰레드 그룹이 생성됩니다. GC를 담당하는 Finalizer 쓰레드를 비롯하여 JVM 운영에 필요한 쓰레드들이 system 그룹에 포함됩니다. 이후 system 쓰레드 그룹의 하위 그룹으로 main 쓰레드 그룹이 생성되고 우리는main 쓰레드 그룹에 포함되는 쓰레드를 생성할 수 있습니다.
쓰레드 그룹은 서로 관련된 쓰레드를 그룹으로 다루기 위한 것이다.
모든 쓰레드는 반드시 하나의 쓰레드 그룹에 포함
쓰레드 그룹을 지정하지 않고 생성한 쓰레드는 main 쓰레드 그룹에 속함
그룹은 보안상의 이유로 도입된 개념이며, 자신이 속한 쓰레드 그룹이나 하위 쓰레드 그룹은 변경할 수 있지만 상위 쓰레드 그룹이나 다른 쓰레드 그룹의 쓰레드를 변경할 수는 없다.


데몬 쓰레드
일반 쓰레드의 작업을 돕는 보조적인 역할을 수행하는 쓰레드입니다.
특징 일반 스레드가 모두 종료되면 데몬 스레드는 강제적으로 종료됩니다. (일반 스레드의 경우 진행중인 작업이 있으면 프로그램이 종료되어도 계속 실행)
백그라운드에서 특별한 작업을 처리하게 하는 용도로 사용됩니다.(가비지 컬렉터, 워드프로세서의 자동저장, 화면 자동 갱신 등)
데몬 스레드 설정 방법
public class 데몬스레드 implements Runnable {
@Override
public void run() {
while(true) {
// 0.5초마다 실행
try {
Thread.sleep(500);
} catch (InterruptedException e) {
break;
}
system.out.println("데몬 스레드 실행")
데몬스레드가_할_일();
}
}
public void 데몬스레드가_할_일() {
System.out.println("데몬스레드 일하는 중");
}
// 메인 메소드에서 할 일은 Runnable을 구현하고 있는 데몬스레드를 실행
public static void main(String[] args) {
Thread 스레드 = new Thread(new 데몬스레드());
// 스레드에게 데몬 스레드 설정
스레드.setDaemon(true);
스레드.start();
// 메인 스레드를 10초 뒤에 종료시킴
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
}
System.out.println("메인 스레드 종료");
}
}데몬 스레드의 경우 모든 스레드가 종료되면 강제 종료됩니다.
메인 스레드도 하나의 스레드이기 때문에 메인 스레드가 종료되면 데몬 스레드는 작동을 멈춘다.
스레드의 실행제어
스레드의 상태
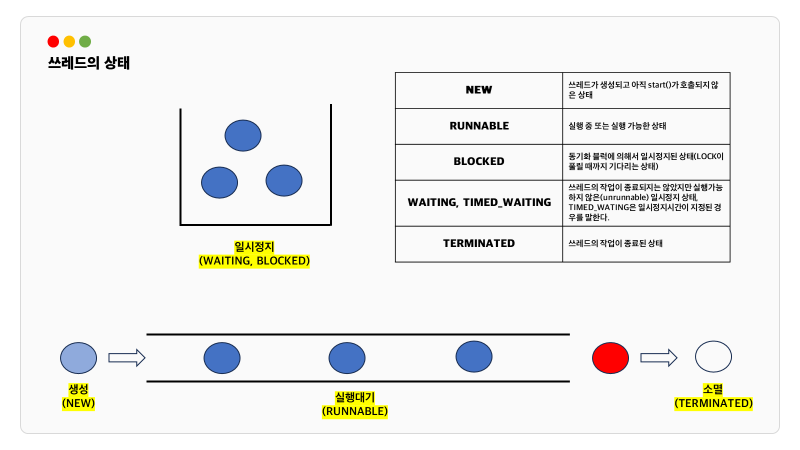
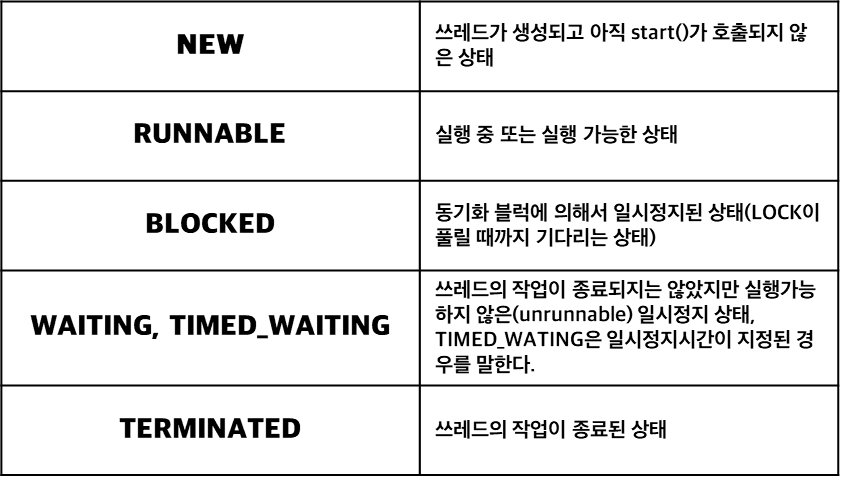
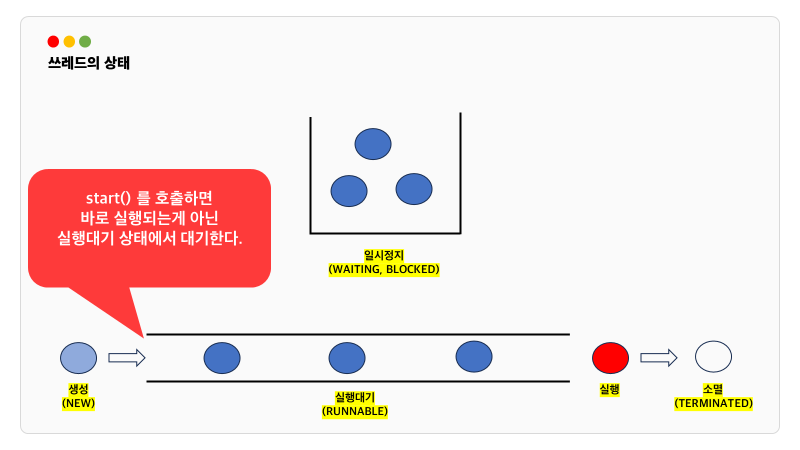
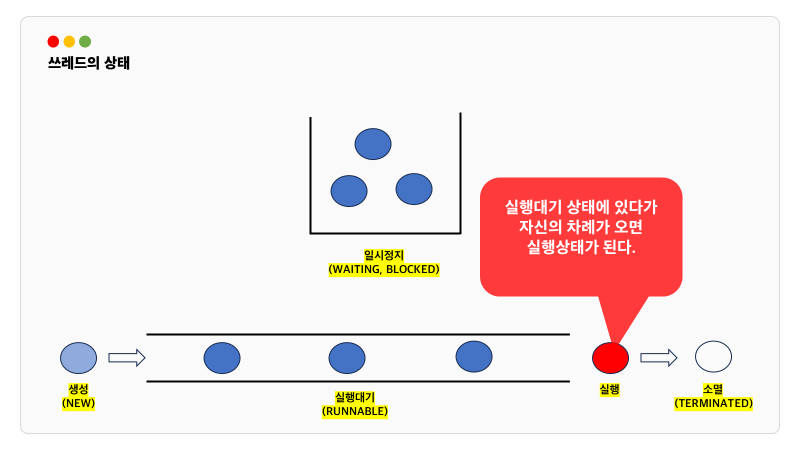
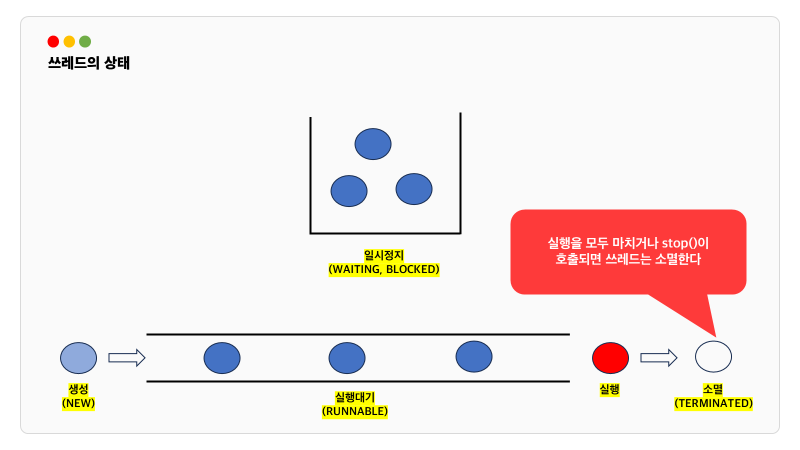
스레드의 스케쥴링과 관련된 메서드
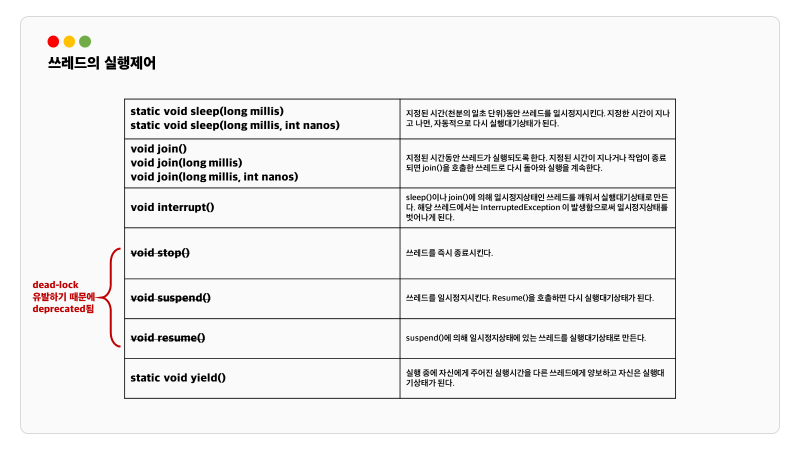
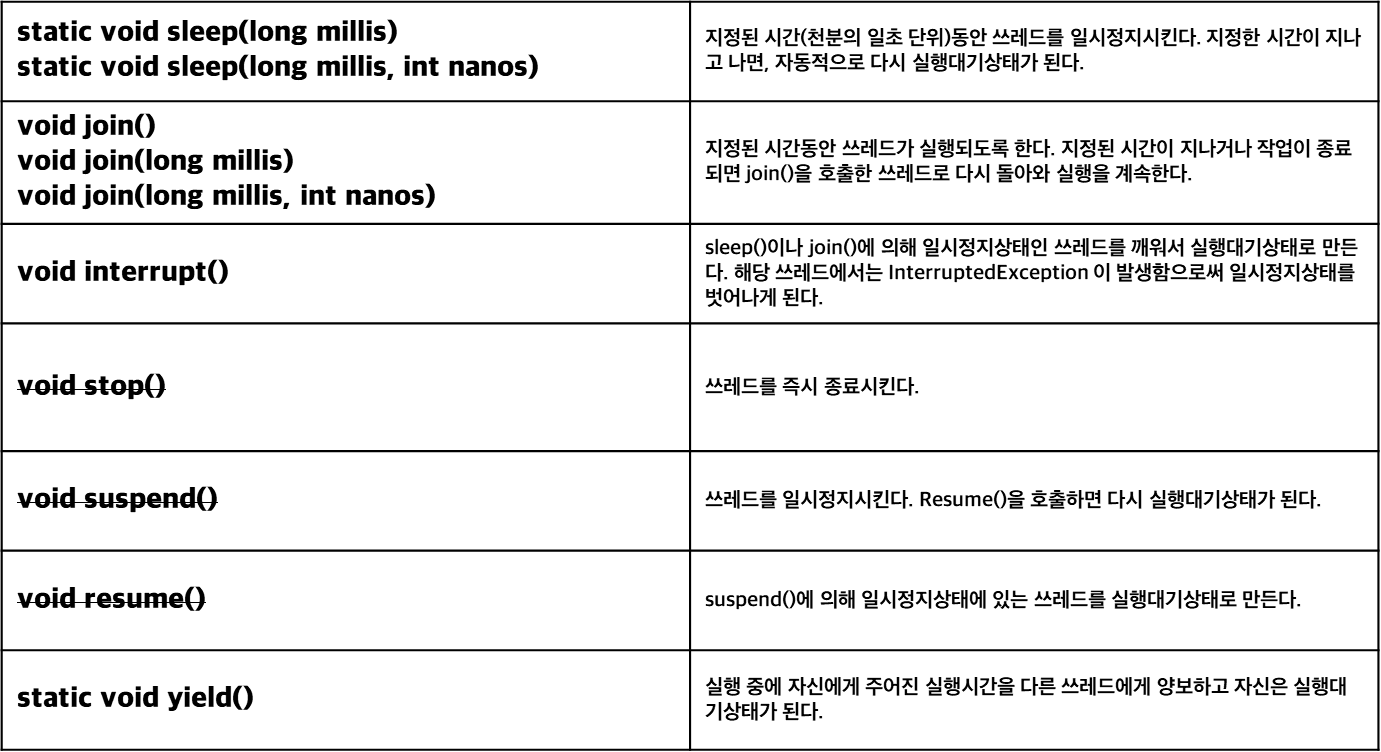


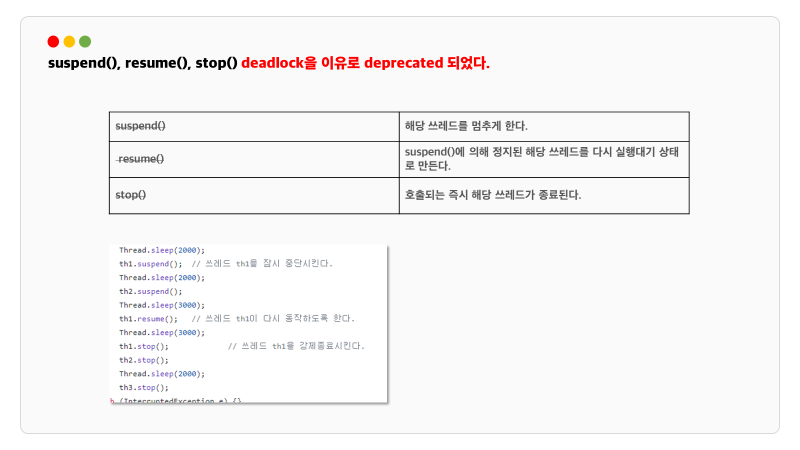
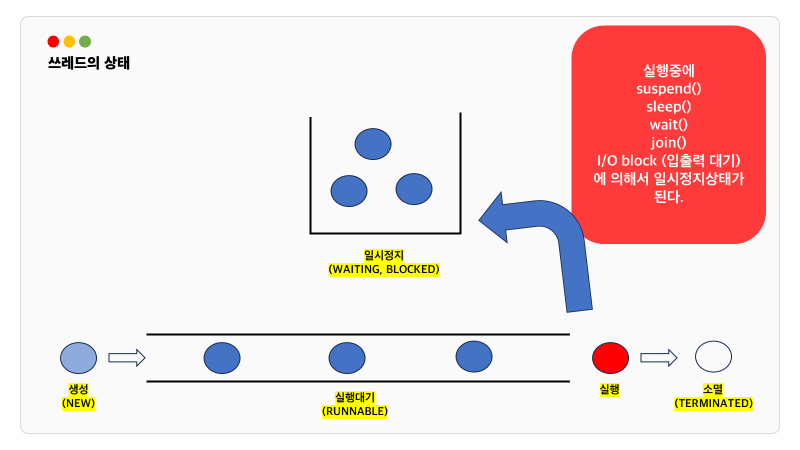
suspend(), resume(), stop()은 deadlock을 이유로 deprecated 되었습니다. supend()와 stop()은 앞서 설명한 slep() 과 다르게 특정 스레드를 집어서 멈추게 할 수 있습니다.
deprecated 된 이유는 다음과 같습니다.
suspend() 메소드는 스레드를 멈추지만 자원의 lock을 해제하지 않습니다. 해당 자원에 접근이 제한되면 deadlock이 발생할 수 있습니다.
스레드가 멈춤으로써 데이터의 일관성을 해칠 수도 있고요 어느 지점에서 멈출지 예측하기 어려워 디버깅과 유지보수를 복잡하게 만듭니다.
stop()도 즉시 종료시키다보니깐 스레드가 자원을 정리하거나 중요한 작업을 완료하는 것을 방해할 수 있습니다. 그러므로써 공유 데이터나 시스템 자원이 예측 불가능해질 수 있습니다.
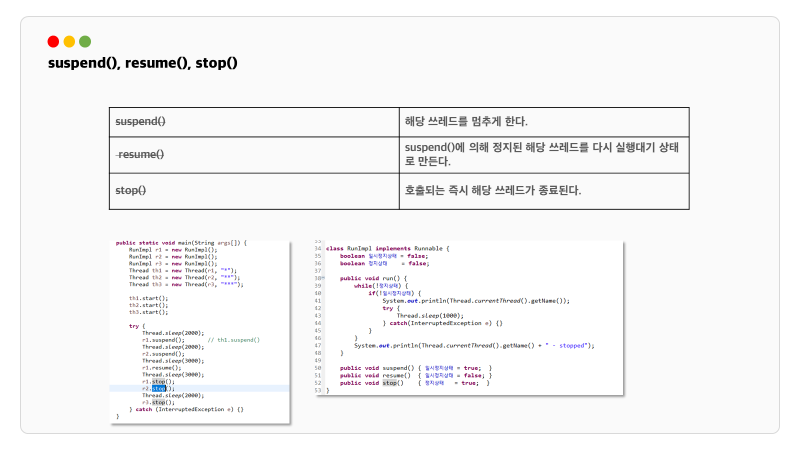
자바의 정석에서는 Runnable 인터페이스를 구체화하는 클래스에서 정지상태, 일시정지상태 속성을 만들어서 suspend(), resume(), stop() 메소드를 구현해놓은 예제가 있습니다.
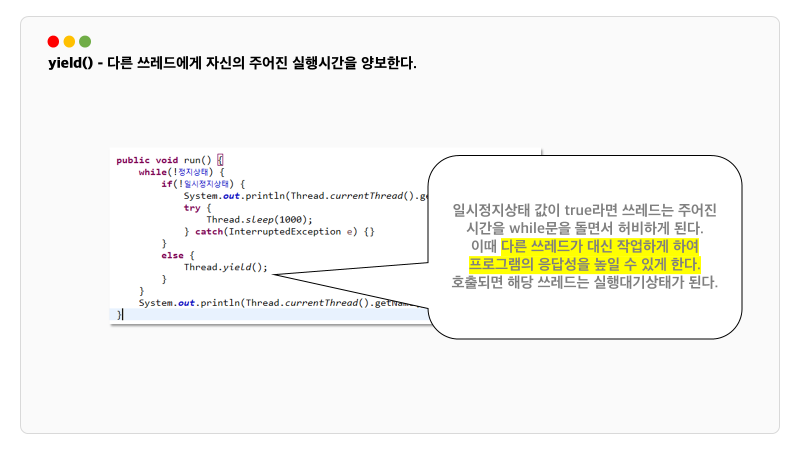
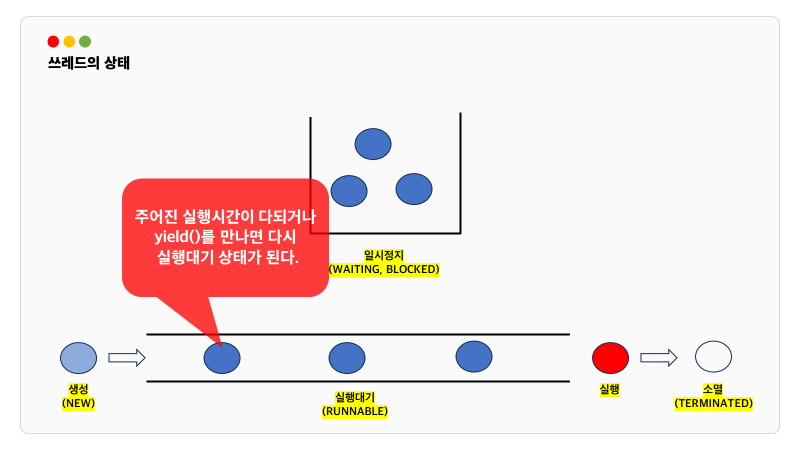
yield() 는 다른 쓰레드에게 자신의 남은 실행시간을 양보하는 메소드입니다. 그리고 해당 스레드는 실행대기상태로 돌아갑니다.

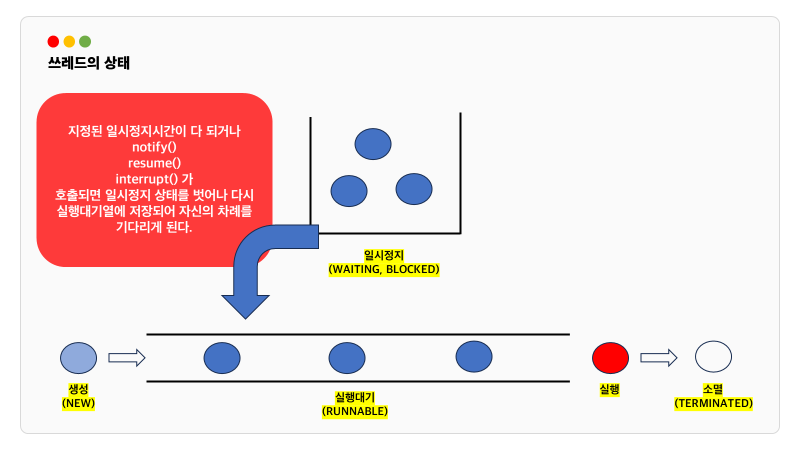
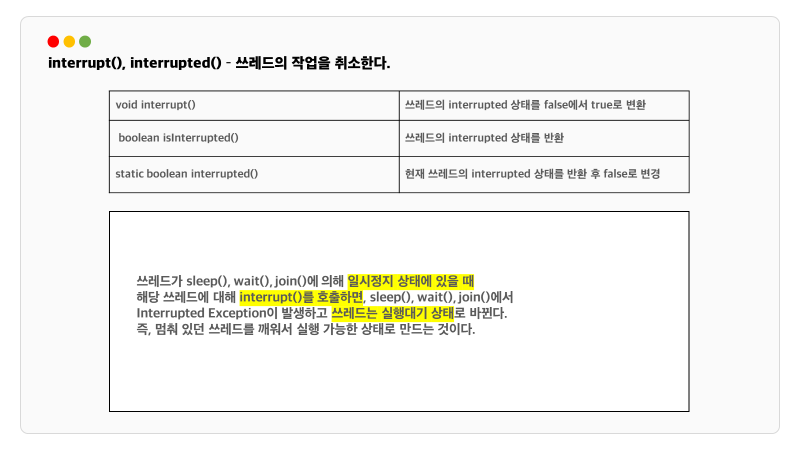
어떤 스레드가 작업중일 때 th1.join()을 호출하면 작업중이던 쓰레드는 호출한 th1 쓰레드의 작업이 끝날 때까지 기다립니다. interrupt()에 의해 대기중인 쓰레드를 대기 상태에서 벗어나게 할 수 있으므로 try-catch문으로 감싸야 합니다.
스레드 동기화(Synchronized)
멀티 쓰레드 프로세스의 경우 여러 쓰레드가 같은 프로세스 내의 자원을 공유해서 작업하기 때문에 서로에 작업에 영향을 주게 된다.
이를 막기 위해 '임계 영역'과 '락'을 활용해 방해를 받지 않고 자원을 독점적으로 사용할 수 있게 해줘야 한다.
Synchronized 설정 방법

스레드의 락을 거는 방법은 두 가지로
메소드 전체에 임계 영역을 지정하는 방법
메소드 내의 코드 일부를 블럭으로 감싸는 synchronized 블럭을 만드는 방법이 있다.

쓰레드는 이렇게 만든 임계 영역에 들어갈 때 지정된 객체의 락을 획득하고 작업을 하는 동안 다른 쓰레드에 방해를 받지 않습니다. 이후 임계 영역을 빠져나오면 락을 반납합니다.
모든 객체는 락을 하나씩 가지고 있으며 락을 가지고 있는 쓰레드만 임계 영역의 코드를 수행할 수 있습니다.
가능하면 synchronized 블럭으로 임계 영역을 최소화 하는 것이 멀티 쓰레드의 프로그램 성능 향상에 도움이 됩니다.

출금을 할려던 쓰레드가 다른 쓰레드에게 자원(내잔액)을 뺏긴 모습
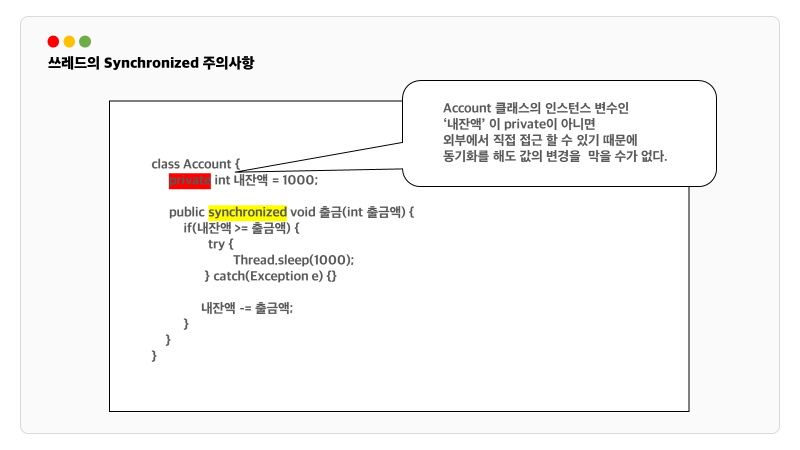
동기화에서 주의할 점은 임계영역에서 사용하는 인스턴스 변수를 private으로 접근제어를 해줘야 한다는 점이다. 외부에서 접근하면 값이 변경될 수 있기 때문이다.
Synchronized 단점 => 락을 너무 오래 갖고 있게 된다..

동기화에서는 하나의 쓰레드가 임계 영역에서 락을 가지고 대기합니다.
출금을 하는 임계 영역에서 쓰레드가 락을 들고 입금이 될 때까지 대기한다면 다른 쓰레드는 해당 객체의 락을 얻지 못할 것이고
락을 기다리느라 다른 작업들도 원활히 진행되지 않습니다.
notify(), wait()
그래서 등장한 개념이 notify와 wait입니다.
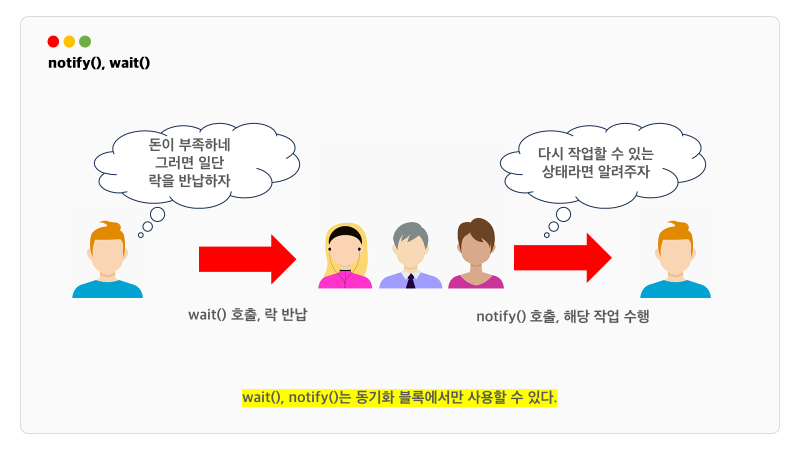
출금을 진행중이던 쓰레드는 잔액보다 출금액이 많은 상황에 직면하고 wait()을 호출하고 락을 반납합니다.
이후 해당 객체의 waiting pool에 들어갑니다.
다른 쓰레드는 해당 객체의 락을 받아 작업을 수행하게 되고 잔액이 출금액보다 많으면 notify()를 호출하여
wait 상태인 쓰레드가 다시 작업할 수 있게 됩니다.
notifyAll()

그런데 이 notify가 꼭 대기하고 있는 해당 쓰레드를 콕 집어서 깨우는 것이 아닙니다.
waiting pool에 있는 여러 쓰레드 중 임의의 하나를 깨우기 때문에 대기중인 모든 쓰레드를 깨우는 notifyAll()이 자주 쓰입니다.

(자바의 정석 참고한 예제 코드)
Lock과 Condition을 이용한 동기화

자 그러면 이제 모든 문제가 해결된 것일까요? 그렇지 않습니다.
notify()는 운이 안좋다면 필요한 쓰레드가 통지를 못 받고 계속 대기할 수 있는 단점이 존재하고 (기아 현상)
notifyAll()은 일단 대기하는 모든 쓰레드에게 통지를 하면 기아 현상은 막겠지만 불필요하게 필요한 쓰레드와 대기중인 쓰레드끼리 경쟁하게 됩니다.(경쟁 상태)
이 두 문제를 해결하기 위해 lock condition을 이용해 특정 쓰레드만 깨우고 대기하도록 해보겠습니다.
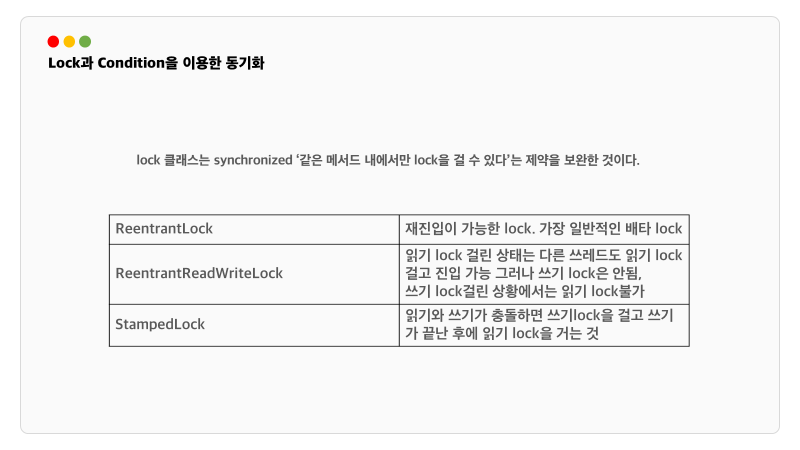
lock클래스는 synchronized 같은 메서드 내에서만 lock을 걸 수 있다는 제약을 보완한 것입니다.
다음은 ReentrantLock 클래스를 사용한 예시입니다. 참고로 Reetrant는 재진입이라는 의미입니다.
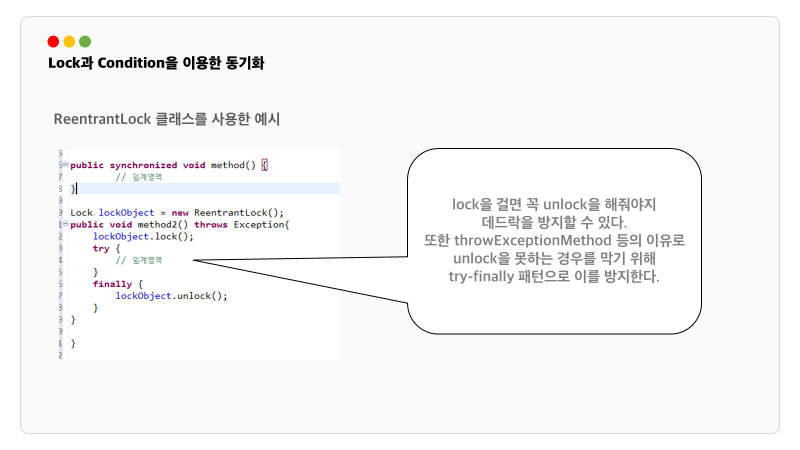
기존 synchronized는 자동으로 lock을 걸어줬다면 이제는 lock을 커스텀할 수 있습니다. ReentrantLock 클래스로 객체를 만들고 동기화 하고 싶은 시작점에 lock을 걸어줍니다. 임계영역 끝에는 꼭 unlock을 해줘야 하는데요. 만약 try-finally 패턴으로 사용하지 않으면 까먹고 unlock을 하지 않는다거나 exception으로 인해서 unlock 되기전에 예외처리 되면서 해당 자원이 계속 lock이 걸려 있을 수 있습니다. 꼭 try-finally 패턴을 활용해야 합니다.
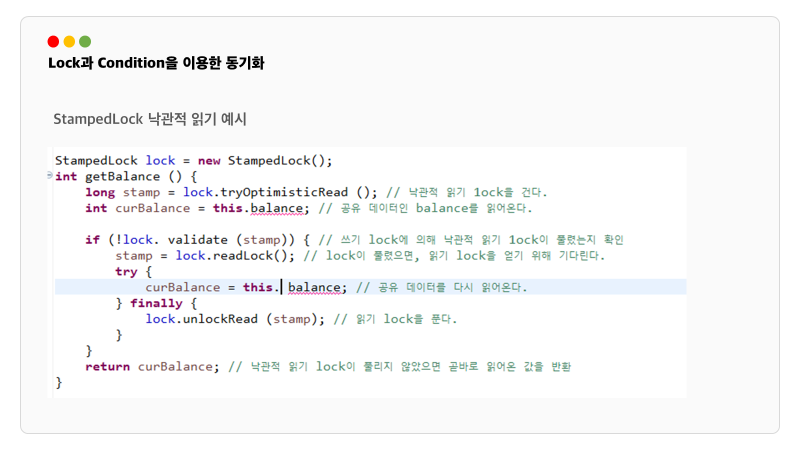
다음은 StampedLock의 낙관적 읽기 예시입니다. Stamp를 찍는다. 이 의미는 버전을 관리한다고 보시면 좀 더 쉽게 이해할 수 있습니다. StampedLock의 객체를 만들고 이를 활용해서 낙관적 읽기를 시작합니다. 이때 우리는 lock이 아닌 해당 락의 상태가 적힌 stamp를 받습니다. 그리고 공유 데이터를 읽고 validate 메소드를 활용해 stamp가 유효한지 확인합니다. 유효하지 않는 경우에는 지금 읽은 데이터가 다른 곳에서 변경될 수 있는 경우입니다. 왜냐하면 쓰기 락을 어떤 쓰레드가 쓰게 된다면 stamp가 변하면서 유효하지 않기 때문입니다. stamp가 유효하지 않으면 readLock()을 이용해서 읽기 락을 얻기 위해 기다립니다. 데이터를 읽고 unlock을 합니다.
이렇게 세세하게 lock을 걸 수 있도록 lock클래스를 사용하였습니다.
다음은 lock에 특정 condition을 부여해서 쓰레드를 분류해서 대기시켜 보겠습니다.


실제 예시를 보면 만든 lock에 대한 새로운 컨디션 객체를 만들어서 해당 컨디션 객체의 메소드를 활용해서 쓰레드를 활용하고 있습니다.
특정 condition 의 await() 메소드를 활용해서 해당 쓰레드를 대기시키고
특정 condition 에 있는 쓰레드를 signal()로 다시 깨우는 예시입니다.
volatile

코어가 메모리에서 값을 읽어올 때 값을 캐시에 저장하고 읽어서 작업하는데요.
먼저 캐시를 읽고 값이 없으면 메모리에서 읽어옵니다. 문제는 캐시에서 값을 읽어서 사용하는데 메모리에서 값이 변경되었고 이게 갱신되지 않으면 메모리에 있는 값과 다른 값을 사용할 수 있다는 점입니다.

그런 상황을 막기 위해 volatile를 변수 타입 앞에 붙여주면 해당 변수는 항상 캐시와 메모리 값이 동기화가 이뤄집니다.
또 다른 방법으로는 synchronized 블럭을 사용하는 방법이니다.
