오늘 포스팅에서는 트리에 대해 공부하기 전에 이해를 돕고자 링크드 리스트에 대해서 먼저 알아보려고 한다.
Linked List ❓
연결 리스트(Linked List)란 배열과 다르게 노드(node)를 사용해 엘리먼트와 엘리먼트 간의 연결(link)을 이용해 리스트를 구현한 것을 말한다.
즉, 연결 리스트는 데이터와 다음 노드의 주를 담고 있는 노드들이 한 줄로 연결되어 있는 방식의 자료구조이다.
연결 리스트는 데이터를 노드의 형태로 저장하고, 노드에는 데이터와 다음 노드를 가르키는 포인터를 담은 구조로 되어있다.
연결되는 방향에 따라서 단일 연결 리스트(Singly linked list), 이중 연결 리스트(Doubly linked list), 환형 연결 리스트(Circular linked list)가 있다.
💡 왜 사용하는가?
그렇다면 파이썬에는 배열이 존재함에도 불구하고 연결 리스트를 사용하는 이유는 무엇일까?
결론을 먼저 말하자면 시간 복잡도 측면에서 연결리스트가 더 효율적이다!
파이썬 내장 함수의 시간 복잡도에서 배열의 삽입과 삭제의 시간 복잡도가 O(n)이 걸리는 것은 배열이 물리적인 데이터의 저장 위치가 연속적이어야 하므로 데이터를 옮기는 연산 작업이 필요하기 때문이다.
하지만 연결 리스트는 데이터를 삽입, 삭제할 경우, 노드의 Next 부분에 저장한 다음, 노드의 포인터만 변경해주면 되므로 더 효율적으로 데이터를 삽입, 삭제할 수 있다.
연결 리스트와 배열의 차이점
- 배열 : 인덱싱이 된 칸에 원소들을 넣어 관리한다.
- 연결 리스트 : 각 원소들을 포인터로 연결지어 관리한다.
관련 용어
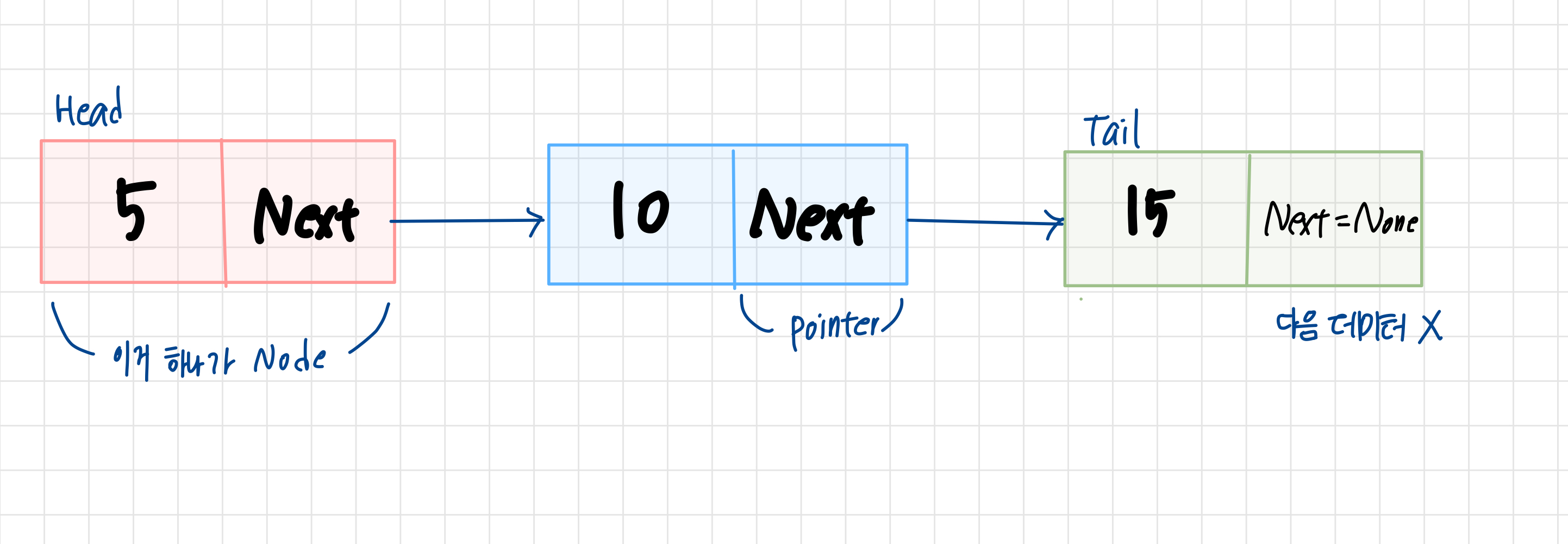
- 노드(node) : 데이터가 저장되는 단위. [데이터값, 포인터]로 구성
- 포인터(pointer) : 다음 데이터의 주소를 담고 있는 공간. 노드에서 다음 또는 이전 노드와의 연결 정보를 가지고 있는 공간.
- 헤드 (head) : 연결 리스트의 가장 시작점인 데이터
- 테일 (tail) : 연결 리스트의 가장 마지막 데이터
Next=None(또는Null) : 다음 데이터가 없을 경우 포인터의 주소값은 None(or Null)
연결 리스트의 기본 구조는 위의 그림과 같다.
💡 연결 리스트의 장단점
👍 장점
- 연결 리스트의 길이를 동적으로 조절할 수 있다.
- 데이터의 삽입, 삭제가 효율적이다.
- 배열은 미리 데이터 공간을 할당해야 하지만 연결 리스트는 미리 할당할 필요가 없다.
👎 단점
- 임의의 노드에 바로 접근할 수 없다. 특정 위치에 있는 원소에 접근하려면 연결 리스트의 처음부터 순차적으로 원소를 훑으며 해당 위치까지 원소를 찾아가야 한다.
- 다음 노드를 연결하기 위해서는 별도의 위치를 저장하기 위한 추가 공간이 필요하다. 따라서 저장공간 효율이 높지는 않다. 배열의 경우 인덱스를 통해 데이터에 접근해 O(1)의 시간 복잡도를 가지지만 연결 리스트의 경우 O(n)을 갖는다. 즉, 연결된 노드의 정보를 찾기 위해 주소를 확인하고 다음 데이터를 탐색하는 시간이 있기 때문에 접근 속도가 느리다.
- 중간에 위치한 데이터 삭제 시, 앞뒤 데이터의 연결을 다시 구현해야 하는 부가적인 작업이 필요하다.
## 💡 기본 연결 리스트 구현
싱글 연결 리스트를 기준으로 간단한 연결 리스트를 구현하면 아래와 같다.
# 노드 클래스 정의
class Node:
def __init__(self, data): # data입력 시 next 초기값은 none
self.data = data
self.next = None
# 링크드 리스트 구현
class SingleLinkedList:
# 초기화
def __init__(self, data):
self.head = Node(data) #head 지정
# 처음부터 순차적으로 탐색해서 마지막에 노드 추가
def append(self, data):
# 첫 번째 노드가 비어있다면
if self.head == '':
self.head = Node(data)
else:
current_node = self.head # head에 주목
while current_node.next is not None: # 현재 노드의 다음 노드가 none이 아니라면 마지막 노드가 아니므로
current_node = current_node.next # 다음 노드로 현재 노드로 포인터를 이동
current_node.next = Node(data) # while문을 빠져나온다면 다음 노드가 없으므로 노드 생성
# 모든 노드 값 출력
def print_all(self):
current_node = self.head
while current_node is not None: # 현재 노드가 마지막 노드가 아니라면
print(current_node.data) # 현재 노드의 데이터를 출력하고
current_node = current_node.next # 현재 노드에서 다음 노드로 포인터 이동
# 노드의 인덱스 알아내기
def get_index(self, index):
count = 0 # 인덱스 값 0으로 초기화
node = self.head
while count < index:
count += 1 # index 값까지 count를 1씩 증가시키며
node = node.next # 노드도 하나씩 이동시키면 찾기
return node
# 삭제할 데이터의 노드 삭제
def delete(self, data):
# 첫 번째 노드가 없을 경우
if self.head == '':
print('Not Found')
return
# 첫 번째 노드에 데이터가 존재할 경우
if self.head.data == data:
temp = self.head # 삭제해야하는 노드를 temp로
self.head = self.head.next # 현재의 노드는 다음 노드로 이동
del temp # temp 삭제
else:
node = self.head
# 일치하는 데이터가 나올때까지, 마지막까지 탐색
while node.next is not None:
if node.next.data == data: # 데이터를 찾으면
temp = node.next
node.next = node.next.next
del temp
return
else: # 데이터를 찾지 못하면
node = node.next # 다음 노드로 이동
# 노드 검색
def search_node(self, data):
node = self.head
while node is not None:
if node.data == data: # 데이터와 일치하는 노드를 찾으면
return node # 노드 반환
else:
node = node.next # 아니면 다음 노드로 이동
# node 생성
# data = 1, data만 입력 했으므로 next는 none
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
# node1을 node2와 연결
node1.next = node2
# 가장 맨 앞 node를 지정하기 위해 head로 지정
head = node1
👩🏻💻👊🏻⭐️