순위 검색
https://school.programmers.co.kr/learn/courses/30/lessons/72412

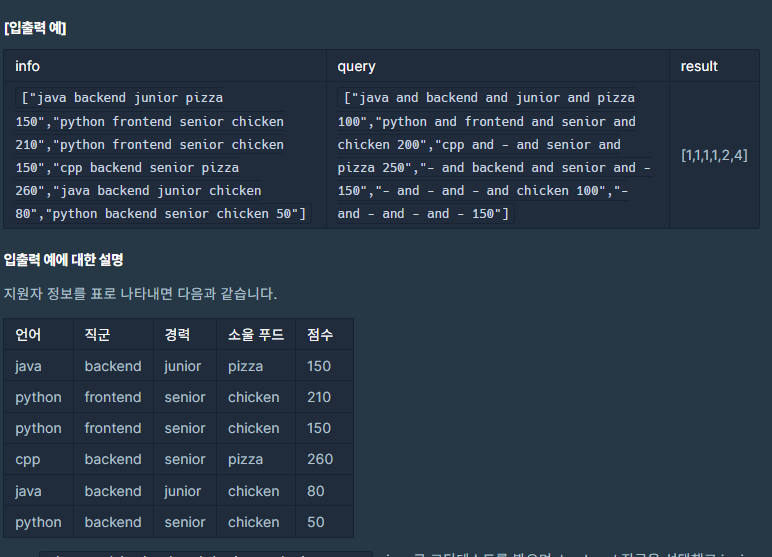
쉽게 설명하자면 SQL문에서 select문에 where절을 생각하면 된다.
하이픈인 경우에는 전체를 가져온다. 예를 들어서 첫 번째 항목(java, python, cpp)인 경우 3가지 항목을 다 검색한다는 소리이다.
중첩 딕셔너리 사용
처음 문제를 봤을 때 key, value값으로 이루어져 있는 딕셔너리를 사용해야겠다고 생각했다. 하지만 다중 중첩 딕셔너리를 어떻게 구현해야 하는지 막막하였다. 예를 들어
dp = {'java': {'backend': {'junior': {'pizza': [150], 'chicken': [80]}}} 이런식의 구조를 나타내고 싶었다. 이 해결방법은 재귀구조이다.
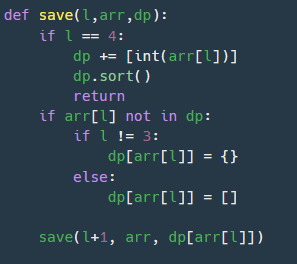
순서는 개발언어, 직군, 경력, 소울푸드, 점수 순으로 나타내어 지고 최종으로 넣어야 하는 것은 점수이다. 즉 모든 조건 별대로 점수를 묶는 것이다. 순서대로 해당 항목에 key값이 없으면 새로운 딕셔너리를 만들고 그 새롭게 만든 딕셔너리를 재귀구조에 넣어주어 중첩으로 생성되게 하였다.
그리고 l = 3일 때에는 딕셔너리가 필요없다. 왜냐하면 그 다음에는 점수가 나올 것이고 점수는 리스트안에다가 넣을 것이기 때문이다. 그래서 l=3일 때 리스트로 저장한다.
그리고 l = 4일 때 점수가 나오고 해당 리스트에 넣은 후 오름차순 정렬을 한다. 처음엔 오름차순 정렬을 안했지만 이진탐색을 위해 사용하였다.
그 결과 print(dp)하게 되면 다음과 같다.

이제 문제는 쿼리에 맞게 답을 도출하면 된다.
예를 들어 쿼리가 "java and backend and junior and pizza 100"이라 하자
그럼 dp['java']['backend']['junior']['pizza']를 찾으면 저장된 리스트가 나올 것이고 그 중 100이상만 찾으면 된다.
하지만 "- and - and - and chicken 100" 이 쿼리는 어떻게 해야할 것인가
해결책은 stack이다. 즉 1,2,3번째 항목이 하이픈이므로 1,2,3 항목은 아무 조건 없이 chicken과 100이상만 가져온다는 소리이다.
즉 stack = [['java', 'python', 'cpp'], ['backend', 'frontend'], ['junior', 'senior'], ['chicken']]을 하게 되면 1, 2, 3항목 전체를 가져오고 'chicken'만 가져올 것이다.
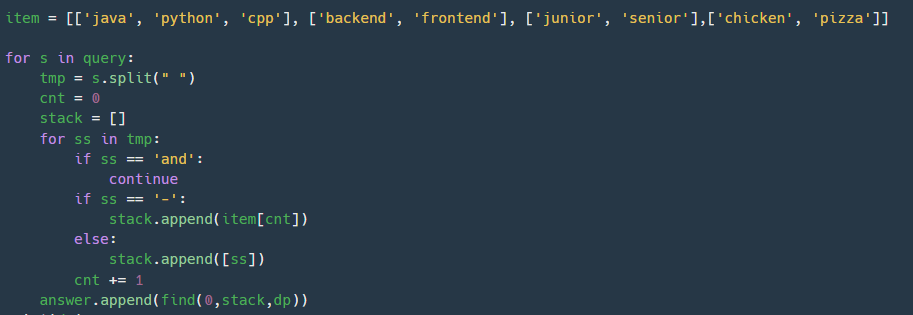
query를 ss로 세분화하고 ss가 and면 지나치고 하이픈이면 순서에 맞는 항목 전체를 stack에 넣는다. 예를 들어 첫 번째 항목이라면 ['java', 'python', 'cpp']를 stack에 넣는 것이다. 그렇지 않다면 해당 항목 ['chicken']만 넣는 것이다. 이제 query에 맞는 key값을 정리하였다. 이제 key에 맞는 value만 찾으면 되는 것이다.
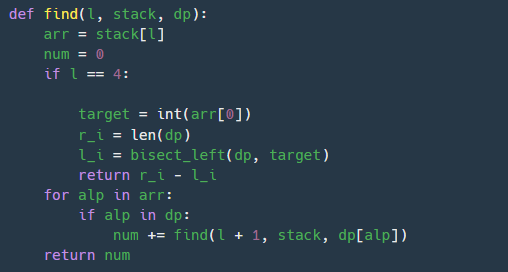
중첩 딕셔너리이기 때문에 재귀구조 형태로하여 원하는 답을 도출 할 수 있도록 하였다. 그래서 순서에 맞게 stack에 꺼내면 하이픈인 것은 전체, 아니면 해당항목만 for문을 통해 값을 가져올 것이다. 그래서 전체 값을 더하고 리턴해주면 된다.
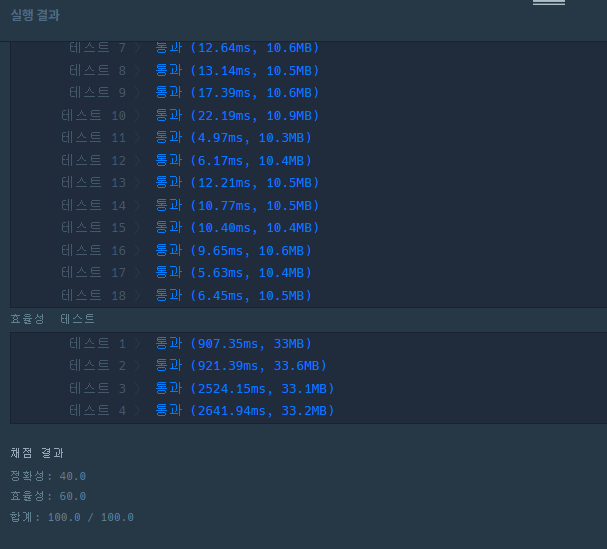
결과
bisect이란?
from bisect import bisect_left, bisect_right
예를 들어 다음과 같은 배열이 있다고 생각해보자
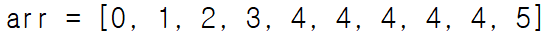
1. bisect_left
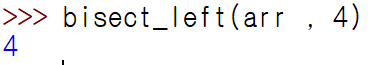
bisect_left를 하게 되면 3, 4 경계에서 해당 4값을 넣을 수 있다는 소리이므로 4를 리턴해준다.
- bisect_right
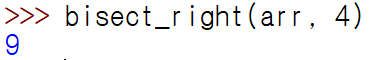
bisect_right를 하게 되면 4, 5 경계에서 해당 4값을 넣을 수 있다는 소리이므로 9를 리턴해준다.
bisect_left을 코드로 구현해보았다.

이진탐색으로 잘 알려져있던 binary_search를 약간 변경해보았다. 원래 mid값과 같으면 해당 mid값을 리턴해주었는데 이러한 경계를 구하는 것에서는 >=으로 바꾸었다. left는 앞에 값을 구해야 하므로 end값을 앞으로 땡겨온다.
bisect_right를 코드로 구현해보았다.

끝에 값을 구해야 하므로 start를 계속 뒤로 옮겨야 하기 때문에 start를 바꿔준다.
어려웠던 점
-
중첩 딕셔너리를 만드는 과정에서 이진탐색을 사용하기 위해 넣을 때마다 일일히 정렬을 하였다.
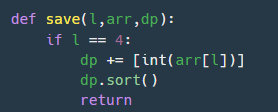
-
여기서도 bisect을 사용해보았다.
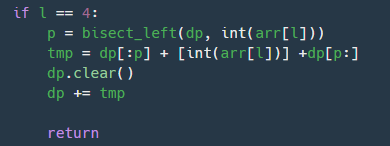
딕셔너리에 있는 리스트에 값을 추가할 때 무조건 += 를 해줘야 했다. 처음엔 dp = tmp를 계속하였는데 dp안에 tmp값이 들어가지 않고 빈 리스트만 들어갔다. 그래서 dp를 clear해주고 tmp값을 추가하는 방식으로 하였다.
하지만 위에서 정렬하는 것보다 런타임시간이 좀 길어서 정렬하는 방법으로 바꿨다.
