
1.머신러닝이란 무엇일까?
머신러닝
- 가장 먼저 시작함
- 알고리즘(컴퓨터의 학습), 인공지능(기술 개발)의 한 분야
- 소프트웨어 프로그램
인공지능의 정의(1959, 아서 사무엘) : 명시적인 프로그래밍이 없이도 컴퓨터가 스스로 학습할 수 있도록 하는 학문
인공지능이 정의된 이후 다양한 프로그래밍 언어가 탄생했고 사람들이 규칙을 지정하면서 많은 것들을 자동화해 왔다. 사람이 일일이 프로그래밍하는 대신, 프로그램이 데이터를 통해 규칙을 스스로 학습하는 아이디어에서 머신러닝이라는 분야가 출발했다.
쇼핑몰 카테고리를 예시로 들 수 있다.
수많은 상품들을 규칙을 통해 구분할 수 있지만, 구분이 모호한 새로운 상품이 들어오게 되면 구분하기 어려워진다. 사람이 직접 규칙을 새로 만들려면 시간이 오래 걸리고 어렵지만, 머신러닝은 그동안 상품을 구분해왔던 데이터를 기반으로 새로운 카테고리를 만들고 구분할 수 있다.
2.머신러닝의 종류
머신러닝은 컴퓨터가 학습을 하는 방법에 따라 지도학습과 비지도 학습, 두가지 종류로 나눌 수 있다.
1.지도학습(SUpervised learning) : 이미 정답이 있는 Label이 있는 데이터를 이용해 학습 시키는 것
*라벨링 : 어떠한 대상의 특징에 따라 정답을 표기하는 것
*Label : 어떠한 대상에 표기된 데이터
*트레이닝(데이터)셋, 훈련데이터 : label이 된 데이터들의 모음
 트레이닝 셋으로 학습시키면 라벨명으로 data 분류를 해주는 모델을 만들 수 있다. 만들어진 분류 모델을 테스트할 때 사용하는 새로운 데이터, 즉 라벨링이 되지 않은 데이터를 테스트 데이터라고 한다. 모델에 들어가는 데이터라고 보면 될 것 같다!
트레이닝 셋으로 학습시키면 라벨명으로 data 분류를 해주는 모델을 만들 수 있다. 만들어진 분류 모델을 테스트할 때 사용하는 새로운 데이터, 즉 라벨링이 되지 않은 데이터를 테스트 데이터라고 한다. 모델에 들어가는 데이터라고 보면 될 것 같다!
지도학습은 트레이닝 셋의 형태에 따라서 분류와 회귀 분석으로 나뉜다.
1) 분류
- 트레이닝 셋은 정답과 답이 맵핑되어 있음
- ex) 과일 사진을 보고 과일을 구분하는 모델
=> 문제와 정답이 정확히 인간이 정해놓은 대로 딱 맞아 떨어지는 경우
2) 회귀 분석

- 수학적으로 나타낼 수 있으면 그래프로 표현할 수 있음

- ex) 온도와 아이스아메리카노 판매량의 상관 관계
- 특정한 온도일 때 판매량을 정확한 수치로 예측할 수 있다.
- 사람들은 위의 그래프를 보고 기온과 판매량이 비례한다는 것을 알 수 있다.
- 원인과 결과 관계에 관련이 깊다.
=> 문제와 답이 정확히 존재한다기보다 문제와 답의 관계가 인과성을 지닌 연속적인 수치로 나타나는 데이터 셋을 사용하여 학습하는 것
2.비지도 학습: 라벨(정답)이 없는 데이터를 군집화 하여 새로운 데이터에 대한 결과를 예측하도록 공부시키는 방법
ㄴ트레이닝 셋은 문제와 정답이 매핑되어 있지 않다.
ㄴ입력 데이터들의 유사한 속성값을 갖는 데이터들의 군집을 구할 수 있다.
유사도 함수: 유사한 속성값을 찾기 위해 유사도를 측정
ㄴ라벨링 되어 있지 않은 데이터로부터 유사한 속성(패턴, 형태)를 찾는다.
ㄴ지도학습보다 난이도가 있다.
비지도 학습의 성질을 이용해 지도학습에서 적절한 특징을 찾기 위한 전처리 방법으로 비지도 학습을 이용하기도 한다.
*전처리 : 데이터 분석 목적과 방법에 맞는 형태로 처리하기 위하여 불필요한 정보를 분리 제거하고 가공하기 위한 예비적인 조작
ex) 많은 과일 사진이 있지만 과일의 이름은 컴퓨터에게 알려주지 않는다. 컴퓨터 혼자서 비슷한 사진들을 모아 과일을 분류하는 모델인 것이다.
우리 생활 대입 예시
=>학교에서 교과서를 가지고 배우는 것 : 지도학습
=>일상에서 여러 경험을 하면서 생겨나는 지식 : 비지도학습
3.딥러닝이란 무엇일까?
딥러닝: 학습 목적에 적합한 속성, 특징을 자동으로 추출하고 이를 이용하여 우수한 성능의 학습을 수행함
우선 인간의 뉴런은 무언가 입력을 받아서 어떤 신호를 만들고 전달한다. 위에서 봤던 머신러닝은 이렇게 간단 신경망을 이루는 1개의 뉴런과 원리가 비슷하다.
이 뉴런들이 엄청나게 많이 복잡하게 얽혀서 하나의 망을 이루는 것을 심층 신경망이라고 한다. 그리고 이것을 딥러닝과 비슷한 맥락으로 볼 수 있는 것이다.
4.딥러닝의 기본 구성요소
퍼셉트론 : 딥러닝을 구성하는 기본 요소로써 인공 신경망 최초의 알고리즘
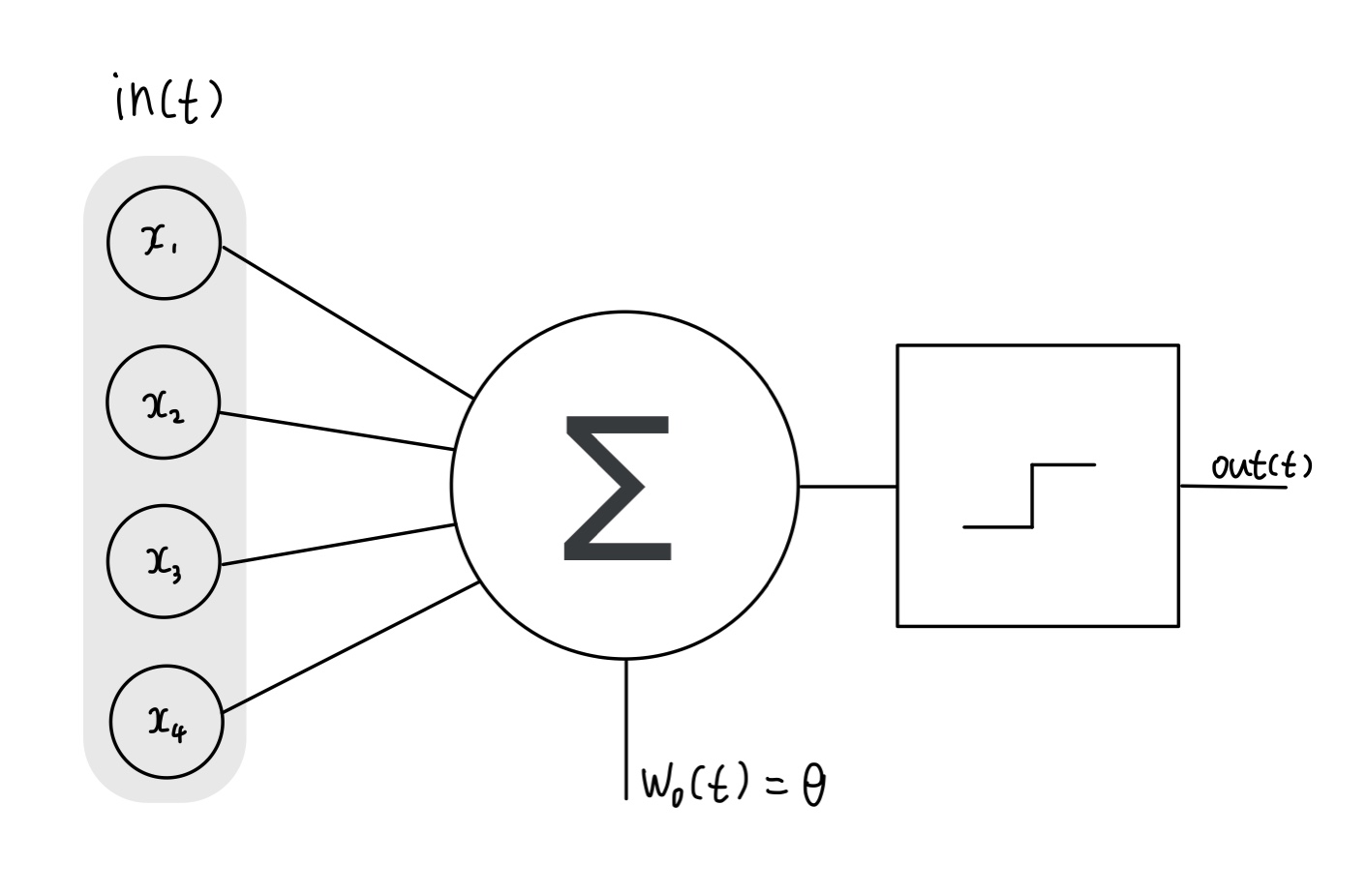 ↑뉴런으로 이루어진 신경망 구조를 수학적으로 본뜬 구조
↑뉴런으로 이루어진 신경망 구조를 수학적으로 본뜬 구조
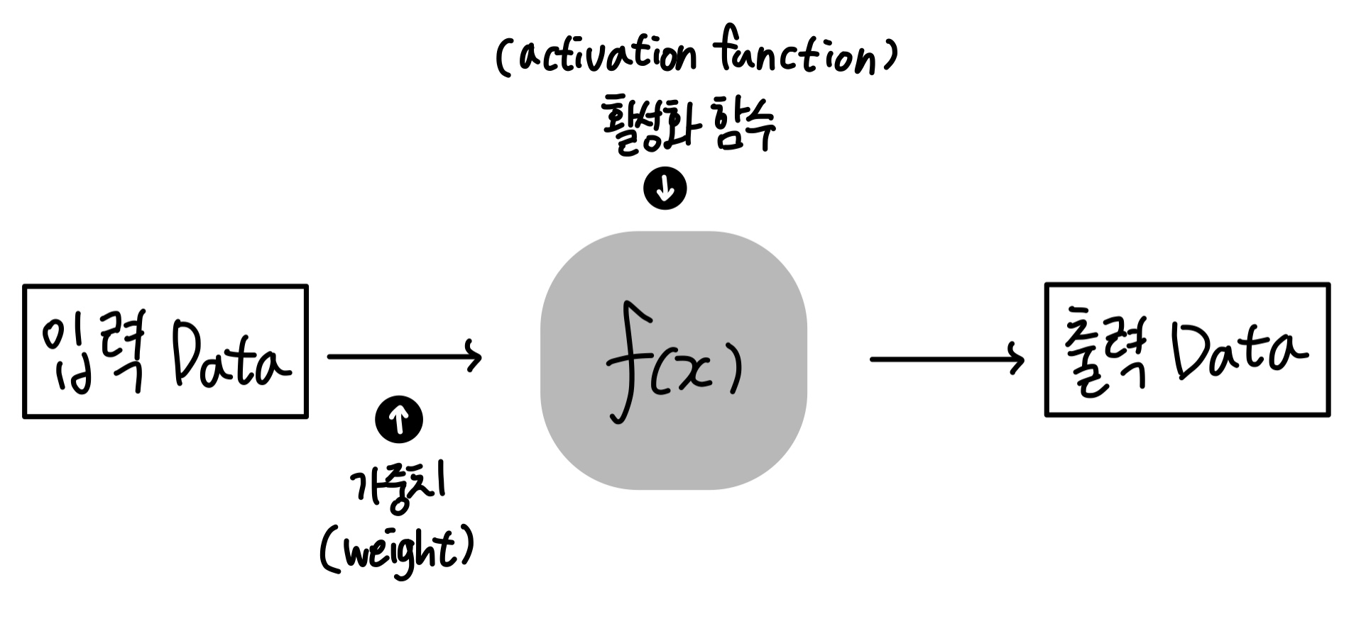 입력 데이터에 어떠한 가중치가 실리는지, 활성화 함수를 통해서 전달할지말지 판단하여 출력을 내보낼 수 있다.
입력 데이터에 어떠한 가중치가 실리는지, 활성화 함수를 통해서 전달할지말지 판단하여 출력을 내보낼 수 있다.
 입력층: 입력 뉴런으로 이루어진 입력 데이터를 받는 층
입력층: 입력 뉴런으로 이루어진 입력 데이터를 받는 층
은닉층: 은닉 뉴런으로 이루어진 입력과 출력 사이에 존재해서 어떠한 계산을 하는 층
출력층: 출력 뉴런으로 이루어져 최종 출력을 내보내는 층
은닉층이 2개 이상일 때부터 심층 신경망이고 이때부터 딥러닝이라고 한다.
또 이 층등의 노드(뉴런)간의 연결강도를 나타내는 가중치가 존재한다.
이 가중치는 이전층의 어떤 노드의 결과값을 얼마나 신뢰할 것이냐는 의미로 볼 수 있다. 신뢰도라고 보면 될 것 같다!
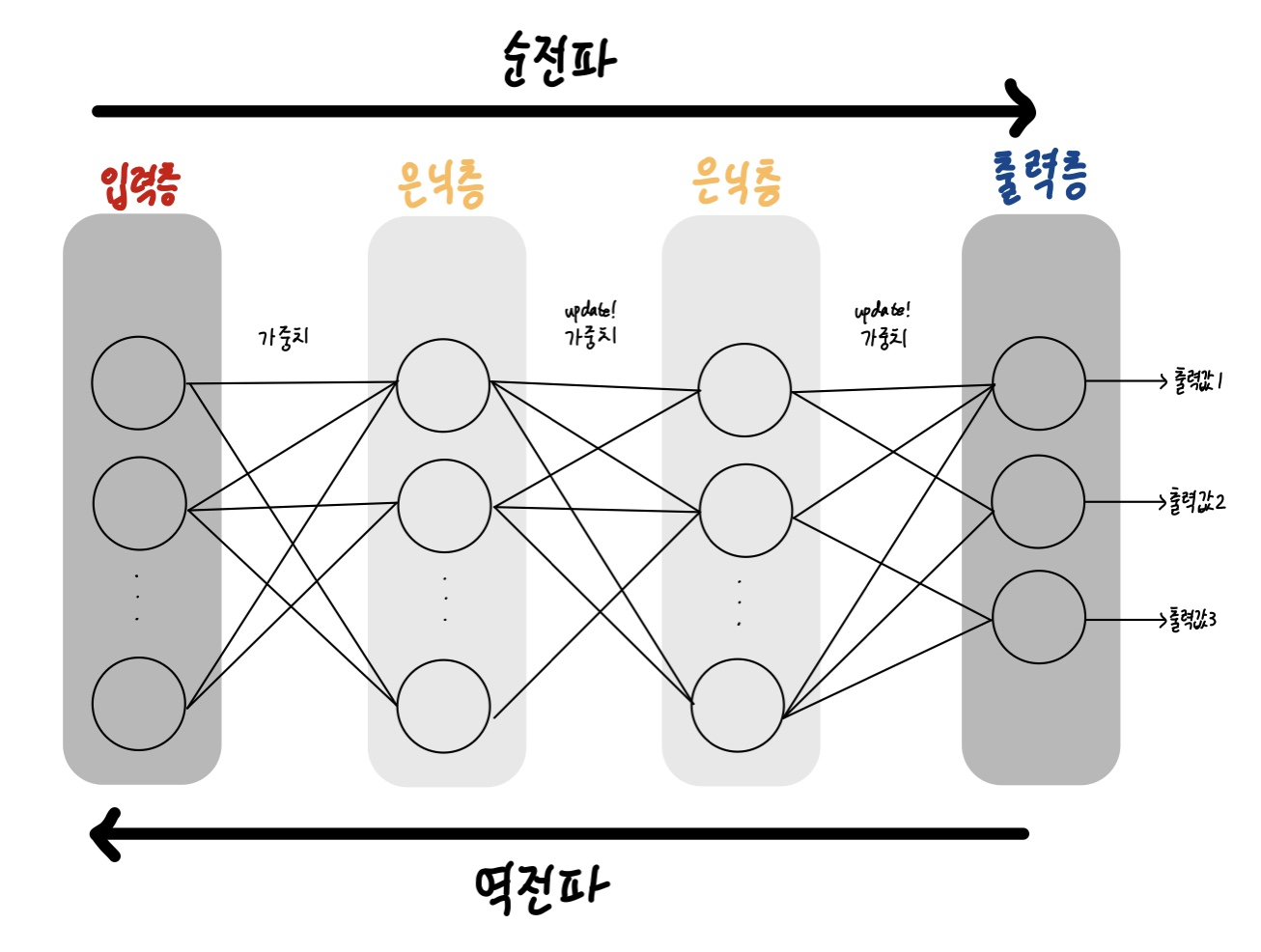
1.순전파 : 출력 값과 실제 값의 차이를 '손실'에러로 계산(출력값 - 실제값 = 손실)
ㄴ입력층 -> 은닉층 -> 출력층
ㄴ처음 손실값은 0보다 많이 큰 경우가 대부분(처음부터 출력값이 잘 난오기 어려우기 때문에) => 손실을 최소화하는 학습 필요 => 역전파
2.역전파 : 역방향으로 계산하여 손실을 최소화 할 수 있도록 가중치를 업데이트
=> 순전파, 역전파가 반복적으로 이루어지면서 적합한 가중치를 스스로 찾아내고 결국 우수한 성능을 가진 인공신경망이 완성된다.
5.딥러닝의 학습요소
딥러닝을 학습시킬 때 적절한 학습시간, 좋은 성능 등의 최적화를 위해서 배치, 에포크, 반복이라는 개념이 필요하다.
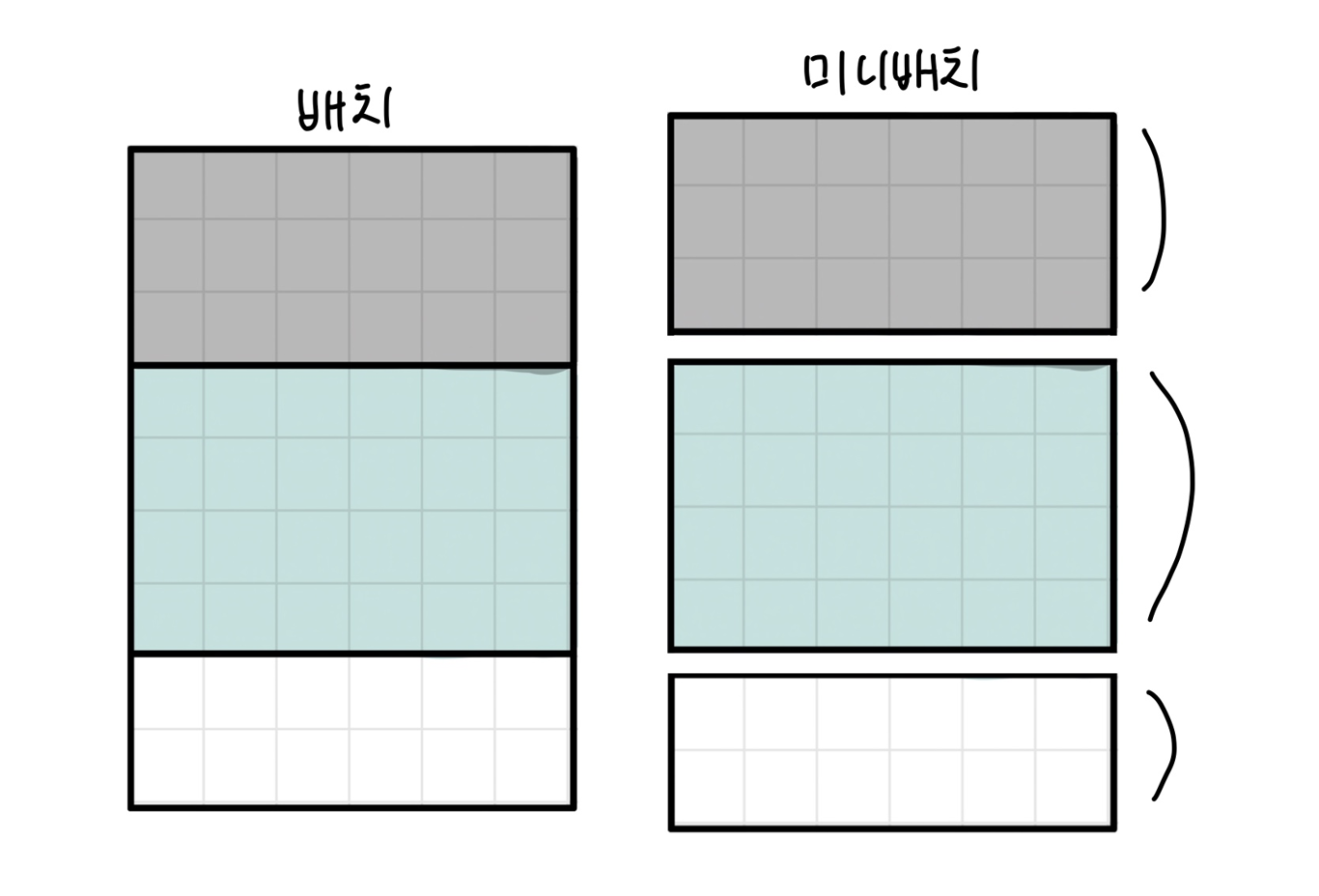
1.배치 : 트레이닝 셋을 batch size로 작게 나누는 것
- 집단, 묶다, 일괄, 배치
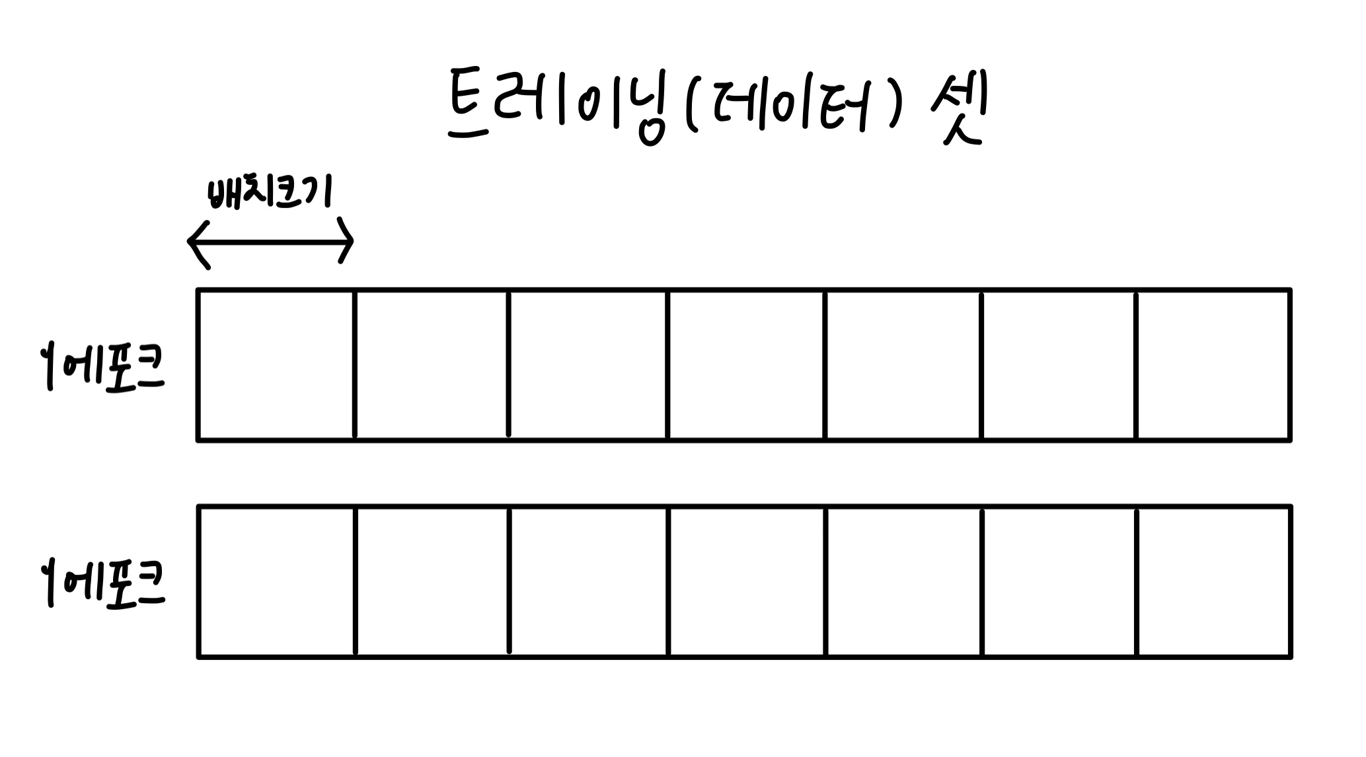
- 배치사이즈 : 전체 트레이닝(데이터) 셋을 여러 작은 그룹으로 나누었을 때 하나의 소그룹에 속하는 데이터 수
- 배치폼 : 그림처럼 나누어진 형태
- 나누는 이유 : 비효율적인 리소스 사용 방지
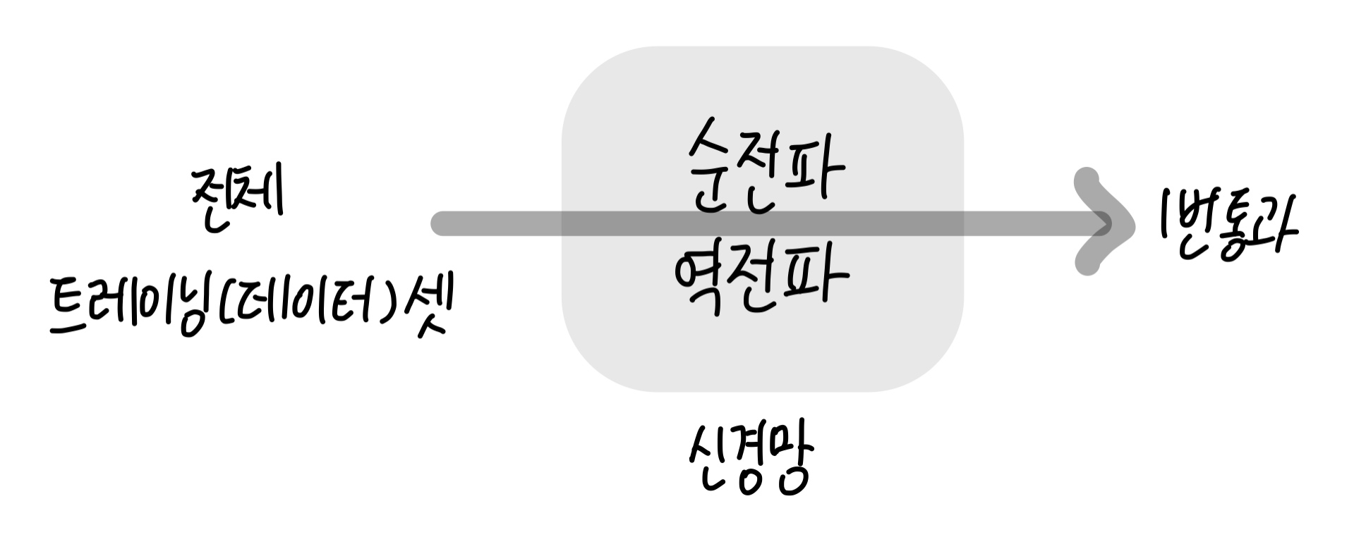
2.에포크 : 전체 트레이닝 셋이 신경망을 통과한 횟수
- 시대
- 1-epoch : 전체 트레이닝 셋이 하나의 신경망에 적용되어 순전파와 역전파를 통해 신경망을 한 번 통과했다는 것을 의미
 3.반복 : 1-epoch를 마치는데 필요한 미니 배치 개수
3.반복 : 1-epoch를 마치는데 필요한 미니 배치 개수
미니 배치가 신경망을 통과할 때마다 가중치가 업데이트됨
*미니 배치 : 거대한 양의 데이터 일부를 무작위로 추려서 단위 별로 쪼갠 배치
ex) 1000개의 데이터 셋을 배치 사이즈 200으로 설정하고 2-epoch를 진행한다면 iteration은 5, 총 가중치의 업데이트는 2 * 5 총 10번이 이루어짐
이러한 특징을 가진 세 가지 요소는 적절히 잡아주는 것이 중요!
문제1) 배치 사이즈 너무 큼=>한 번에 처리하는 양↑=>학습속도↓, 메모리 부족
문제2) 배치 사이즈 너무 작음=>가중치 업데이트 빈도수↑=>불안정한 훈련
