
싸피에서 자율 프로젝트를 진행하며 빅데이터 파이프라인을 구축하게 되었다. 서버의 용량과 처음 다뤄보는 기술들로 처리과정이 어려웠다.
카프카에 저장된 데이터를 hadoop에 적재하는 역할을 맡았는데, 그 과정을 정리해보고자 한다.
❓ 왜 Hadoop을 사용했나요?
hadoop은 성능이 좋은 컴퓨터 한 대가 아닌, 보통 성능의 컴퓨터를 여러 개 두어 분산환경에서 데이터를 처리한다.
사용자가 wearOS 기기를 착용하고 운동을 시작하면 심박수 데이터를 모아 저강도, 중강도, 고강도 운동을 각각 몇 분씩 진행하였는지 제공하였다.

이때 1초에 1개씩 심박수 데이터를 수집하게 되는데,
- 100명의 사용자가
- 60분씩만 운동했다고 가정해도
하루에만 36만개의 데이터가 발생한다.
이렇게 많은 양의 데이터를 처리하기 위해 hadoop을 적용하였다.
🏗️ 아키텍처
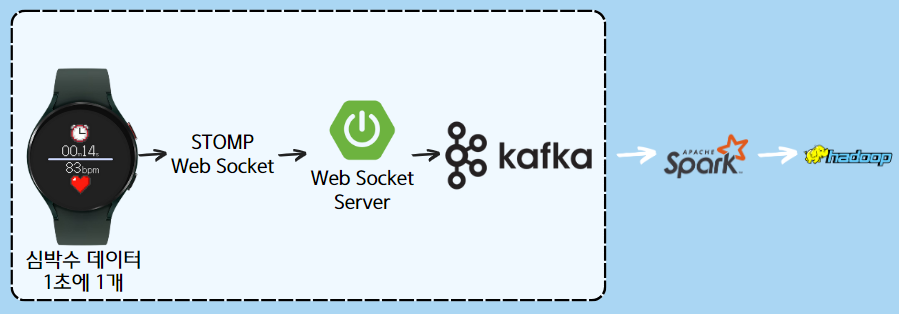
간단하게 정리하자면 아래 두 과정으로 나눌 수 있다.
1. 워치에서 소켓통신을 통해 데이터 kfaka에 저장
2. kafka에 저장된 테이터를 spark를 통해 hadoop에 적재
🛠️ 사용 기술
Kafka
카프카는
- low coupling
워치와 hadoop이 서로의 정보를 알지 못해도 데이터를 처리한다. - 장애 복구성
서버에 장애가 생겨도 워치에서 발생한 데이터는 kafka에 버퍼링되어 hadoop에 적재된다는 점이 보장
되어 적용하였다.
kafka를 docker로 띄어보자
아래 docker-compose.yml파일은 kafka를 docker container로 띄우는 코드이다.
version: '2'
services:
zookeeper:
container_name: heartbeat_zookeeper
image: wurstmeister/zookeeper
ports:
- "2181:2181"
networks:
- deploy
kafka:
container_name: heartbeat_kafka
image: wurstmeister/kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ADVERTISED_PORT: 9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://43.202.219.160:9092
KAFKA_CREATE_TOPICS: "heartbeat-raw-topic:2:1"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_HEAP_OPTS: "-Xmx4G -Xms4G"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
- deploy
networks:
deploy:
external: trueKafka는 크게 Kafka와 Zookeeper로 구분할 수 있다.
- zookeeper
메시지 큐의 데이터를 관리한다. - kafka
메시지를 TCP로 전송하기 위한 브로커를 제공한다.
Spark
kafka에 쌓여있는 데이터를 hadoop에 적재하기 위해 spark를 사용하였다. 빠른 시간 내에 구현해야했기에 레퍼런스가 많은 tool을 선택하였으며, spark의 경우 인메모리 방식의 연산으로 빠른 데이터 처리가 가능하다.
실행 명령어
- 스파크 버전 파악
spark-submit --version - 스파크 실행
spark-submit --master spark://43.202.219.160:7077 --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.0 kafka_to_hadoop.py
첫번째 시도(binary타입으로 저장)
아래와 같은 코드를 실행했을 때에는 데이터가 binary 타입으로 저장되었다.
from pyspark.sql import SparkSession
# spark session 생성
sc = SparkSession.builder \
.appName("gunapang") \
.getOrCreate()
#sc.sparkContext.setLogLevel('ERROR')
# kafka 서버와 토픽 설정
kafka_params = {
"kafka.bootstrap.servers": "http://43.202.219.160:9092",
"subscribe": "heartbeat-raw-topic",
"startingOffsets": "earliest"
}
# kafka에서 데이터를 읽어 DataFrame 생성
df = sc.readStream.format("kafka") \
.options(**kafka_params) \
.load()
# Hadoop에 쓰기 위한 경로 설정
path = "hdfs://43.202.219.160:9000/user/hadoop/heartbeat"
checkpointLocation = "/home/ubuntu/spark/checkpoint"
# DataFrame을 Hadoop에 쓰기
query = df.writeStream \
.format("parquet") \
.option("path", path) \
.option("checkpointLocation", checkpointLocation) \
.start()
query.awaitTermination()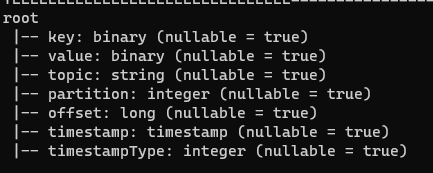
두번째 시도(의도한 데이터 타입으로 변경)
첫번째 시도와 달리 데이터 프레임을 전처리하여 저장하였다.
from pyspark.sql import SparkSession, functions as F
# spark session 생성
sc = SparkSession.builder \
.appName("gunapang") \
.enableHiveSupport() \
.getOrCreate()
#sc.sparkContext.setLogLevel('ERROR')
# kafka 서버와 토픽 설정
kafka_params = {
"kafka.bootstrap.servers": "http://43.202.219.160:9092",
"subscribe": "heartbeat-raw-topic",
"startingOffsets": "earliest"
}
# kafka에서 데이터를 읽어 DataFrame 생성
df = sc.readStream.format("kafka") \
.options(**kafka_params) \
.load()
# Kafka에서 읽은 데이터를 적절한 스키마로 변환
df = df.selectExpr("CAST(value AS STRING) as json")
df = df.select(F.from_json(df.json, "playerId STRING, heartbeat DOUBLE, createdAt ARRAY<INT>").alias("data"))
df = df.select("data.*")
df = df.withColumn("createdAt", F.to_timestamp(
F.concat(
F.expr("createdAt[0]"), F.lit("-"),
F.expr("createdAt[1]"), F.lit("-"),
F.expr("createdAt[2]"), F.lit(" "),
F.expr("createdAt[3]"), F.lit(":"),
F.expr("createdAt[4]"), F.lit(":"),
F.expr("createdAt[5]"), F.lit("."),
F.expr("createdAt[6]")
)
))
# Hadoop에 쓰기 위한 경로 설정
path = "hdfs://43.202.219.160:9000/user/hadoop/heartrate2"
checkpointLocation = "/home/ubuntu/spark/checkpoint4"
# DataFrame을 Hadoop에 쓰기
query = df.writeStream \
.format("parquet") \
.option("path", path) \
.option("checkpointLocation", checkpointLocation) \
.start()
query.awaitTermination()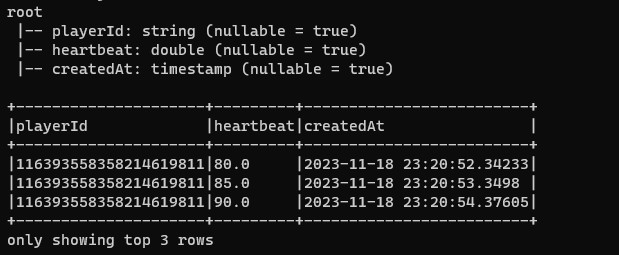
<참고 블로그>
