왜 필요할까?
Luis 라는 자연어 처리 api를 접목하려는 중, 이것 저것 살펴 보다가, 아래와 같이 limitation 부분이 눈에 띄었다.
Luis 의 경우 사용순서가,
- intent, entity 등을 추가한다.
- 추가한 값들을 기반으로 train 하여 나만의 모델을 만든다.
- 해당 모델의 endpoint를 사용하여 자연어를 질의하고 결과값을 받는다.
테스트 목적이나, PoC 진행시에는 크게 문제가 되지 않는 방식이지만, 신경써야 하는 부분이 있다.
만든 모델을 활용하여 prediction을 endpoint를 통해서 받을 때, 아래와 같은 제약사항이 발생한다.

초당 50번 이상의 쿼리가 있다면?
만약 서비스가 대박이 났을때, 우리는 높은 확률로 자연어 처리가 느리다는 이유로 매니저에게 불려가게 된다. 거의 100% 확률로 불려가서 깨진다.
Cognitive Services와 같은 PaaS형 서비스들과 같이, 내가 만든 VM 기반 서비스들이 아닌경우, limitation이라는 부분이 존재한다.
우리는 관리 포인트를 없애기 위해 PaaS를 선택했는데, limitaion이 발목을 잡을 줄이야?
어떻게 해결할까?
단순하게 생각하자면, 뒤에 어떻게든 여러개의 Luis prediction 리소스들을 생성해서, 부하분산하면 된다라고 생각하면 되지만, 조금 들여다 보면 손댈것들이 많다. 말은 쉽지...
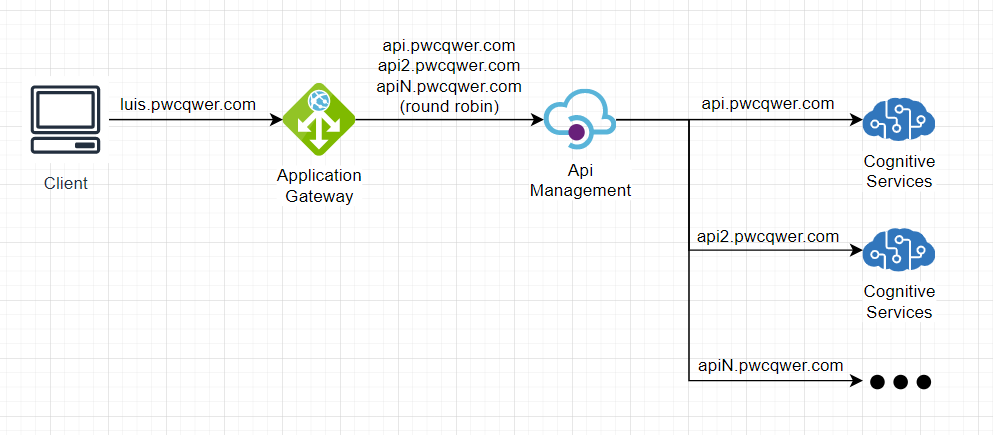
위의 구성도를 쉽게 설명해 보자면,
- client는 모두 동일한 url로 질의
- Application Gateway에서 host name override를 활용한 부하분산
- Api Management에서, 들어오는 header의 host 값에 따른, 각각의 prediction resource로 질의
라는 순서로 진행시키려 한다.
어떻게 진행할지 한번 세세히 알아보자!
위의 방법은, Cognitive Services 뿐만 아니라, restful을 지원하는 다른 서비스들에서도 충분히 활용 가능하다!!

n년차 눕눕