퍼셉트론 작동 예시 구현하기
이번 실습에서는 이론 영상을 통해 학습한 퍼셉트론의 작동 예시를 직접 코드로 구현해보도록 하겠습니다.

위 세 가지 사항과 아래의 표를 고려해서 외출 여부(출력값 y)를 판단하는 Perceptron 함수를 만들어봅시다.
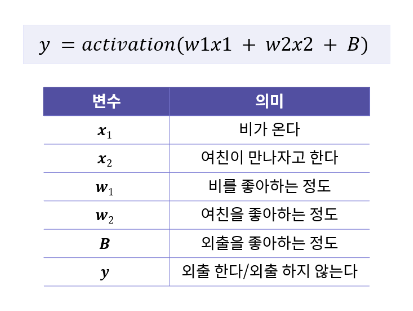

출처:엘리스실습
입력 받은 x1,x2,w1,w2값들을 이용하여 계산한 신호의 총합 output과 그에 따른 외출 여부 y를 반환하는 Perceptron 함수를 완성하세요.
활성화 함수는 ‘신호의 총합이 0 초과면 외출하고, 0 이하라면 외출하지 않는다‘는 규칙을 가집니다.
Bias 값은 외출을 좋아하는 정도를 의미하며, -1로 설정되어 있습니다.
실행 버튼을 눌러 x1,x2,w1,w2 값을 다양하게 입력해보고, Perceptron함수에서 반환한 신호의 총합과 그에 따른 외출 여부를 확인해보세요.
'''
1. 신호의 총합과 외출 여부를 반환하는
Perceptron 함수를 완성합니다.
Step01. Bias는 외출을 좋아하는 정도이며
-1로 설정되어 있습니다.
Step02. 입력 받은 값과 Bias 값을 이용하여 신호의
총합을 구합니다.
Step03. 지시한 활성화 함수를 참고하여 외출 여부
(0 or 1)를 반환합니다.
'''
def Perceptron(x_1,x_2,w_1,w_2):
bias = -1
output = x_1*w_1+x_2*w_2+bias
y = 1 if output>0 else 0
return output, y
# 값을 입력받는 함수입니다.
def input_func():
# 비 오는 여부(비가 온다 : 1 / 비가 오지 않는다 : 0)
x_1 = int(input("x_1 : 비가 오는 여부(1 or 0)을 입력하세요."))
# 여자친구가 만나자고 하는 여부(만나자고 한다 : 1 / 만나자고 하지 않는다 : 0)
x_2 = int(input("x_2 : 여친이 만나자고 하는 여부(1 or 0)을 입력하세요."))
# 비를 좋아하는 정도의 값(비를 싫어한다 -5 ~ 5 비를 좋아한다)
w_1 = int(input("w_1 : 비를 좋아하는 정도 값(-5 ~ 5)을 입력하세요."))
# 여자친구를 좋아하는 정도의 값(여자친구를 싫어한다 -5 ~ 5 비를 좋아한다)
w_2 = int(input("w_2 : 여친을 좋아하는 정도 값(-5 ~ 5)을 입력하세요."))
return x_1, x_2, w_1, w_2
'''
2. 실행 버튼을 눌러 x1, x2, w1, w2 값을 다양하게
입력해보고, Perceptron함수에서 반환한 신호의 총합과
그에 따른 외출 여부를 확인해보세요
'''
def main():
x_1, x_2, w_1, w_2 = input_func()
result, go_out = Perceptron(x_1,x_2,w_1,w_2)
print("\n신호의 총합 : %d" % result)
if go_out > 0:
print("외출 여부 : %d\n ==> 외출한다!" % go_out)
else:
print("외출 여부 : %d\n ==> 외출하지 않는다!" % go_out)
if __name__ == "__main__":
main()DIY 퍼셉트론 만들기
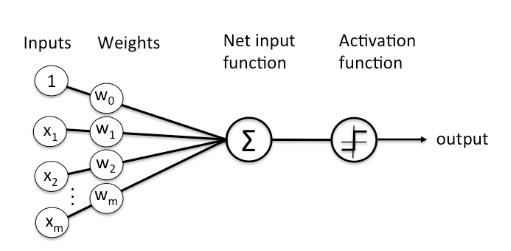
이번 실습에선 위 그림과 같은 퍼셉트론을 구현해 봅시다.

실습
가중치 값이 들어간 1차원 리스트 w와 임의의 Bias 값인 b를 설정해줍니다.
신호의 총합 output을 정의하고, output이 0 이상이면 1을, 그렇지 않으면 0을 반환하는 활성화 함수 y를 작성해 perceptron 함수를 완성합니다.
출처:엘리스'''
1. 가중치와 Bias 값을
임의로 설정해줍니다.
Step01. 0이상 1미만의 임의의 값으로 정의된
4개의 가중치 값이 들어가있는
1차원 리스트를 정의해줍니다.
Step02. Bias 값을 임의의 값으로 설정해줍니다.
'''
def main():
x = [1,2,3,4]
w = [1.2,1.1,1,-0.9]
b = -0.5
output, y = perceptron(w,x,b)
print('output: ', output)
print('y: ', y)
'''
2. 신호의 총합과 그에 따른 결과 0 또는 1을
반환하는 함수 perceptron을 완성합니다.
Step01. 입력 받은 값과 Bias 값을 이용하여
신호의 총합을 구합니다.
Step02. 신호의 총합이 0 이상이면 1을,
그렇지 않으면 0을 반환하는 활성화
함수를 작성합니다.
'''
def perceptron(w, x, b):
output = x[0]*w[0]+x[1]*w[1]+x[2]*w[2]+x[3]*w[3]+b
y = 1 if output>=0 else 0
return output, y
if __name__ == "__main__":
main()AND gate와 OR gate 구현하기
이번 실습에서는 이론 영상을 통해 학습한 퍼셉트론의 AND gate와 OR gate를 직접 구현해보도록 하겠습니다.
AND gate와 OR gate는 한 개의 퍼셉트론으로 만들어졌기 때문에 단층 퍼셉트론이라고 부릅니다.
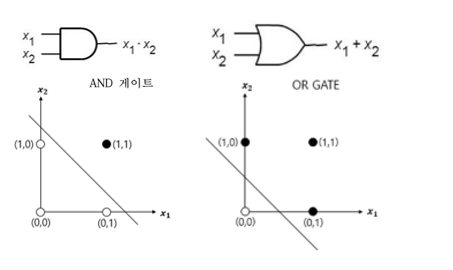
단층 퍼셉트론인 AND gate와 OR gate를 직접 구현해보며 적절한 가중치(Weight)와 Bias 값을 찾아보고, 가장 기본적인 활성화 함수인 Step Function을 구현해보도록 하겠습니다.
AND, OR gate 입출력 표
Input (x1) Input (x2) AND Output(y) OR Output(y)
0 0 0 0
0 1 0 1
1 0 0 1
1 1 1 1
실습
And_gate 함수를 완성하세요.
OR_gate 함수를 완성하세요.
활성화 함수인 Step_Function 함수를 아래 그래프를 참고하여 완성하세요.
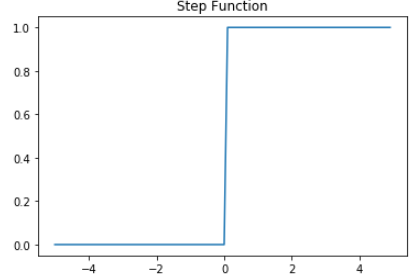
실행 버튼을 눌러 입출력 표와 결괏값을 비교해본 후 제출하세요.
Tips!
이전 실습과 달리 이번 실습은 입력값 x와 가중치 값 weight가 리스트가 아닌 Numpy array 형태로 주어져있습니다. 따라서 필요하다면 Numpy 연산 메소드를 사용해도 좋습니다.
출처:엘리스import numpy as np
'''
1. AND_gate 함수를 완성하세요.
Step01. 입력값 x1과 x2에 각각 곱해줄 가중치는
0.5, 0.5로 설정되어 있습니다.
Step02. AND_gate를 만족하는 Bias 값을
설정합니다. 여러 가지 값을 대입해보며
적절한 Bias 값을 찾아보세요.
Step03. 가중치, 입력값, Bias를 이용하여
신호의 총합을 구합니다.
Step04. Step Function 함수를 호출하여
AND_gate의 출력값을 반환합니다.
'''
def AND_gate(x1, x2):
x = np.array([x1, x2])
weight = np.array([0.5,0.5])
bias = -0.7
y = np.matmul(x,weight)+bias
return Step_Function(y)
'''
2. OR_gate 함수를 완성하세요.
Step01. 입력값 x1과 x2에 각각 곱해줄 가중치는
0.5, 0.5로 설정되어 있습니다.
Step02. OR_gate를 만족하는 Bias 값을
설정합니다. 여러 가지 값을 대입해보며
적절한 Bias 값을 찾아보세요.
Step03. 가중치, 입력값, Bias를 이용하여
신호의 총합을 구합니다.
Step04. Step Function 함수를 호출하여
OR_gate의 출력값을 반환합니다.
'''
def OR_gate(x1, x2):
x = np.array([x1, x2])
weight = np.array([0.5,0.5])
bias = -0.3
y = np.matmul(x,weight)+bias
return Step_Function(y)
'''
3. 설명을 보고 Step Function을 완성합니다.
Step01. 0 미만의 값이 들어오면 0을,
0 이상의 값이 들어오면 1을
출력하는 함수를 구현하면 됩니다.
'''
def Step_Function(y):
return 1 if y>=0 else 0
def main():
# AND Gate와 OR Gate에 넣어줄 Input
array = np.array([[0,0], [0,1], [1,0], [1,1]])
# AND Gate를 만족하는지 출력하여 확인
print('AND Gate 출력')
for x1, x2 in array:
print('Input: ',x1, x2, ', Output: ',AND_gate(x1, x2))
# OR Gate를 만족하는지 출력하여 확인
print('\nOR Gate 출력')
for x1, x2 in array:
print('Input: ',x1, x2, ', Output: ',OR_gate(x1, x2))
if __name__ == "__main__":
main()
NAND gate와 NOR gate 구현하기
앞선 실습에서는 가중치(Weight), Bias, Step Function을 이용하여 단층 퍼셉트론인 AND gate와 OR gate를 구현해보았습니다.
이번 실습에서는 가중치와 Bias 값을 조정해보며 동일한 단층 퍼셉트론 NAND gate와 NOR gate를 구현해보도록 하겠습니다.
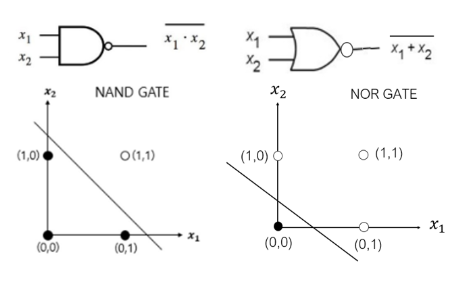
출처:엘리스NAND, NOR gate 입출력 표
Input (x1) Input (x2) NAND Output(y) NOR Output(y)
0 0 1 1
0 1 1 0
1 0 1 0
1 1 0 0
실습
앞선 실습과 위의 입출력 표를 참고하여 NAND_gate 함수를 완성하세요. 이번 실습에서는 Bias 값 뿐만 아니라 가중치도 자유롭게 적절한 값을 설정해야합니다.
앞선 실습과 위의 입출력 표를 참고하여 NOR_gate 함수를 완성하세요. 마찬가지로 Bias 값 뿐만 아니라 가중치도 자유롭게 적절한 값을 설정해야합니다.
앞선 실습을 참고하여 Step_Function 함수를 완성하세요. 앞 실습에서 구현한 함수를 그대로 사용할 수 있습니다.
실행 버튼을 눌러 입출력 표와 결괏값을 비교해본 후 제출하세요.
import numpy as np
'''
1. NAND_gate 함수를 완성하세요.
Step01. 이전 실습을 참고하여 입력값 x1과 x2를
Numpy array 형식으로 정의한 후, x1과 x2에
각각 곱해줄 가중치도 Numpy array 형식으로
적절히 설정해주세요.
Step02. NAND_gate를 만족하는 Bias 값을
적절히 설정해주세요.
Step03. 가중치, 입력값, Bias를 이용하여
가중 신호의 총합을 구합니다.
Step04. Step Function 함수를 호출하여
NAND_gate의 출력값을 반환합니다.
'''
def NAND_gate(x1, x2):
x = np.array([x1,x2])
weight = np.array([-0.2,-0.3])
bias = 0.4
y = np.matmul(x,weight)+bias
return Step_Function(y)
'''
2. NOR_gate 함수를 완성하세요.
Step01. 마찬가지로 입력값 x1과 x2를 Numpy array
형식으로 정의한 후, x1과 x2에 각각 곱해줄
가중치도 Numpy array 형식으로 적절히 설정해주세요.
Step02. NOR_gate를 만족하는 Bias 값을
적절히 설정해주세요.
Step03. 가중치, 입력값, Bias를 이용하여
가중 신호의 총합을 구합니다.
Step04. Step Function 함수를 호출하여
NOR_gate의 출력값을 반환합니다.
'''
def NOR_gate(x1, x2):
x = np.array([x1,x2])
weight = np.array([-0.5,-0.5])
bias = 0.3
y = np.matmul(x,weight)+bias
return Step_Function(y)
'''
3. 설명을 보고 Step Function을 완성합니다.
앞 실습에서 구현한 함수를 그대로
사용할 수 있습니다.
Step01. 0 미만의 값이 들어오면 0을,
0 이상의 값이 들어오면 1을
출력하는 함수를 구현하면 됩니다.
'''
def Step_Function(y):
return 1 if y>=0 else 0
def main():
# NAND와 NOR Gate에 넣어줄 Input
array = np.array([[0,0], [0,1], [1,0], [1,1]])
# NAND Gate를 만족하는지 출력하여 확인
print('NAND Gate 출력')
for x1, x2 in array:
print('Input: ',x1, x2, ' Output: ',NAND_gate(x1, x2))
# NOR Gate를 만족하는지 출력하여 확인
print('\nNOR Gate 출력')
for x1, x2 in array:
print('Input: ',x1, x2, ' Output: ',NOR_gate(x1, x2))
if __name__ == "__main__":
main()비선형적인 문제 : XOR 문제
XOR 문제는 주어진 두 x1, x2의 값이 다르면 결과가 1이 나오고 같으면 0이 나오는 문제 입니다. 이번 실습은 이진 분류가 가능한 선형 분류기 하나로 XOR 문제를 풀면 어떤 결과가 나오는지 확인하는 실습입니다.
XOR gate 입출력 표
Input (x1) Input (x2) XOR Output(y)
0 0 0
0 1 1
1 0 1
1 1 0
XOR 문제의 경우는 지금까지 만든 AND, OR, NAND, NOR gate처럼 선형 분류기 하나로 문제를 해결할 수 없습니다. 즉 이는 로지스틱 회귀(Logistic Regression)로 문제를 해결할 수 없다는 뜻과 같습니다.
로지스틱 회귀는 범주형 변수를 회귀 예측하는 알고리즘을 말합니다. XOR gate를 포함한 AND, OR, NAND, NOR gate는 0과 1의 입력쌍을 통해 0 또는 1, 즉 두 종류의 변수를 예측합니다. 따라서 지금까지 배운 gate 알고리즘은 모두 로지스틱 회귀 알고리즘입니다.
아래의 그림은 분홍색 선인 선형 분류기가 XOR 문제를 풀 수 없음을 좌표 평면 상에서 나타낸 그림입니다.
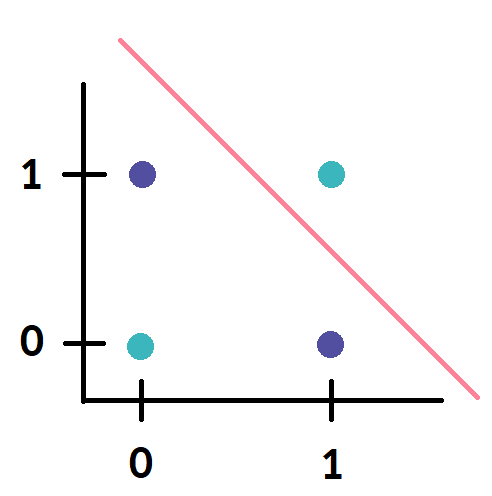
출처:엘리스실습
앞선 실습과 위의 입출력 표를 참고하여 XOR_gate 함수를 최대한 완성해보세요. 이번 실습에서도 Bias 값 뿐만 아니라 가중치 또한 자유롭게 적절한 값을 설정해야합니다. 하지만 어떤 가중치와 Bias 값을 설정하더라도 100% 완벽한 XOR_gate 함수 완성은 불가능할 것입니다.
앞선 실습을 참고하여 Step_Function 함수를 완성하세요. 앞 실습에서 구현한 함수를 그대로 사용할 수 있습니다.
실행 버튼을 눌러 입출력 표와 결괏값을 비교해보고, 분류 정확도 Accuracy가 50% 이상이 되도록 만들어보세요.
import numpy as np
'''
1. XOR_gate 함수를 최대한 완성해보세요.
Step01. 이전 실습을 참고하여 입력값 x1과 x2를
Numpy array 형식으로 정의한 후, x1과 x2에
각각 곱해줄 가중치도 Numpy array 형식으로
적절히 설정해주세요.
Step02. XOR_gate를 만족하는 Bias 값을
적절히 설정해주세요.
Step03. 가중치, 입력값, Bias를 이용하여
가중 신호의 총합을 구합니다.
Step04. Step Function 함수를 호출하여
XOR_gate 출력값을 반환합니다.
'''
def XOR_gate(x1, x2):
x = np.array([x1,x2])
weight = np.array([0.5,0.5])
bias = 0.3
y = np.matmul(x,weight)+bias
return Step_Function(y)
'''
2. 설명을 보고 Step Function을 완성합니다.
앞 실습에서 구현한 함수를 그대로
사용할 수 있습니다.
Step01. 0 미만의 값이 들어오면 0을,
0 이상의 값이 들어오면 1을
출력하는 함수를 구현하면 됩니다.
'''
def Step_Function(y):
return 1 if y>=0 else 0
def main():
# XOR Gate에 넣어줄 Input과 그에 따른 Output
Input = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
Output = np.array([[0], [1], [1], [0]])
# XOR Gate를 만족하는지 출력하여 확인
print('XOR Gate 출력')
XOR_list = []
for x1, x2 in Input:
print('Input: ',x1, x2, ' Output: ', XOR_gate(x1, x2))
XOR_list.append(XOR_gate(x1, x2))
hit = 0
for i in range(len(Output)):
if XOR_list[i] == Output[i]:
hit += 1
acc = float(hit/4)*100
print('Accuracy: %.1lf%%' % (acc))
if __name__ == "__main__":
main()
다층 퍼셉트론으로 XOR gate 구현하기
앞선 실습에서 단층, 즉 한 개의 퍼셉트론으로 가중치와 Bias를 조정하여 AND, OR, NAND, NOR Gate를 구현했습니다.
이들은 하나의 직선으로 영역을 나눈 후 출력을 조정하여 나온 결과라고 할 수 있습니다.
하지만 XOR Gate는 구현하지 못했습니다. XOR Gate를 완벽히 구현하기 위해선 어떻게 가중치와 Bias를 조정해야 할까요?
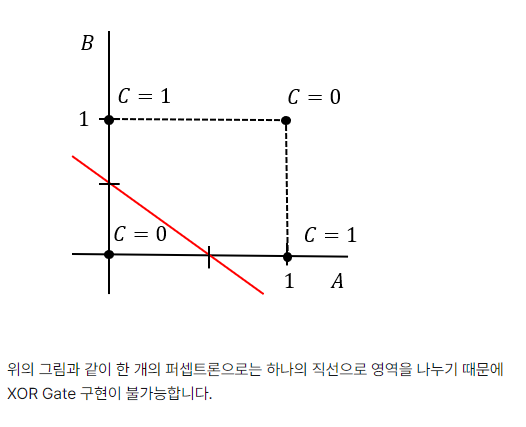
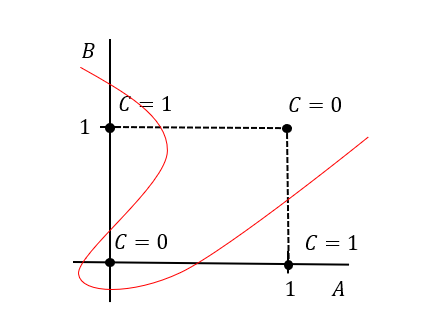
하지만, 한 개의 퍼셉트론이 아닌 여러 개, 즉 다층으로 퍼셉트론을 쌓는다면 어떨까요? 이번 실습에서는 앞서 구현한 다양한 퍼셉트론들을 활용하여 XOR Gate를 구현해보겠습니다.
XOR gate 입출력 표
Input (x1) Input (x2) XOR Output(y)
0 0 0
0 1 1
1 0 1
1 1 0
실습
AND_gate 함수를 구현하세요. 이전 실습에서 구현한 함수를 그대로 사용할 수 있습니다.
OR_gate 함수를 구현하세요. 이전 실습에서 구현한 함수를 그대로 사용할 수 있습니다.
NAND_gate 함수를 구현하세요. 이전 실습에서 구현한 함수를 그대로 사용할 수 있습니다.
Step_Function 함수를 구현하세요. 이전 실습에서 구현한 함수를 그대로 사용할 수 있습니다.
아래 그림을 참고하여 구현한 AND_gate, OR_gate, NAND_gate 함수들을 활용해 XOR_gate 함수를 구현하세요.
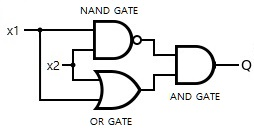
실행 버튼을 눌러 입출력 표와 결괏값을 비교해본 후 제출하세요.
출처:엘리스import numpy as np
'''
1. AND_gate 함수를 완성하세요.
'''
def AND_gate(x1,x2):
x = np.array([x1, x2])
weight = np.array([0.5,0.5])
bias = -0.7
y = np.matmul(x,weight)+bias
return Step_Function(y)
'''
2. OR_gate 함수를 완성하세요.
'''
def OR_gate(x1,x2):
x = np.array([x1, x2])
weight = np.array([0.5,0.5])
bias = -0.3
y = np.matmul(x,weight)+bias
return Step_Function(y)
'''
3. NAND_gate 함수를 완성하세요.
'''
def NAND_gate(x1,x2):
x = np.array([x1,x2])
weight = np.array([-0.2,-0.3])
bias = 0.4
y = np.matmul(x,weight)+bias
return Step_Function(y)
'''
4. Step_Function 함수를 완성하세요.
'''
def Step_Function(y):
return 1 if y>=0 else 0
'''
5. AND_gate, OR_gate, NAND_gate 함수들을
활용하여 XOR_gate 함수를 완성하세요. 앞서 만든
함수를 활용하여 반환되는 값을 정의하세요.
'''
def XOR_gate(x1, x2):
x = NAND_gate(x1,x2)
y= OR_gate(x1,x2)
return AND_gate(x,y)
def main():
# XOR gate에 넣어줄 Input
array = np.array([[0,0], [0,1], [1,0], [1,1]])
# XOR gate를 만족하는지 출력하여 확인
print('XOR Gate 출력')
for x1, x2 in array:
print('Input: ',x1, x2, ', Output: ', XOR_gate(x1, x2))
if __name__ == "__main__":
main()
다층 퍼셉트론(MLP) 모델로 2D 데이터 분류하기
data 폴더에 위치한 test.txt 데이터와 train.txt데이터를 활용하여 2-D 평면에 0과 1로 이루어진 점들의 각 좌표 정보 (x,y)(x, y)(x,y) 를 통해 모델을 학습시키겠습니다.
hidden_layer_sizes를 조정해보면서 다층 퍼셉트론 분류 모델을 학습시켜 모델의 정확도가 81% 를 넘도록 해봅시다.
이전 실습에서 단층 퍼셉트론인 AND, OR, NAND Gate를 구현하고, 이들을 쌓아서 XOR Gate를 만들어 보았습니다. 즉, XOR Gate는 단층 퍼셉트론을 여러 개 쌓아서 만든 다층 퍼셉트론 (MLP: Multi Layer Perceptron)이라고 할 수 있습니다. 다층 퍼셉트론으로 만든 모델은 인공 신경망이라고도 합니다.
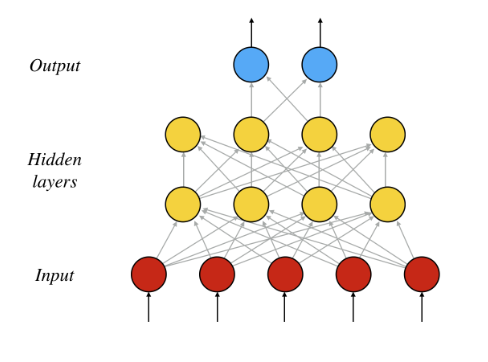
이번 실습에서는 사이킷런에서 제공하는 다층 퍼셉트론 모델인 MLPClassifier를 이용해서 2D 데이터를 분류해보겠습니다.
다층 퍼셉트론 모델을 사용하기 위한 사이킷런 함수/라이브러리
from sklearn.neural_network import MLPClassifier: 사이킷런에 구현되어 있는 다층 퍼셉트론 모델을 불러옵니다.
MLPClassifier(hidden_layer_sizes): MLPClassifier를 정의합니다.
hidden_layer_sizes: 간단하게 hidden layer의 크기를 조절할 수 있는 인자입니다.
MLPClassifier는 역전파(backpropagation)라는 기법을 사용하여 모델을 학습합니다. 역전파는 2장에서 자세하게 배울 수 있으니 여기선 용어만 알아둡시다.
밑의 소스 코드는 첫 번째 히든층에 4개, 두 번째 히든층에 4개의 퍼셉트론을 가지게 설정한 것이고, 위 그림과 같은 모델을 나타냅니다.
clf = MLPClassifier(hidden_layer_sizes=(4, 4))
clf.fit(X, Y)
Copy
실습
MLPClassifier를 정의하고 hidden_layer_sizes를 조정해 히든층의 레이어의 개수와 퍼셉트론의 개수를 바꿔본 후, 학습을 시킵니다.
정확도를 출력하는 report_clf_stats함수를 완성합니다. hit는 맞춘 데이터의 개수, miss는 못 맞춘 데이터의 개수입니다. 정확도 점수 score는 (맞춘 데이터의 개수 / 전체 데이터 개수) x 100으로 정의하겠습니다. score를 코드로 작성해보세요.
앞서 완성한 함수를 실행시키는 main 함수를 완성합니다. 코드 주석의 Step들을 참고하세요.
일반적으로, 레이어 내의 퍼셉트론의 개수가 많아질수록 성능이 올라가는 것을 확인할 수 있습니다. 레이어의 개수와 퍼셉트론의 개수를 극단적으로 늘려보기도 하고, 줄여보면서 정확도를 81% 이상으로 늘려보세요.
출력 예시
아래 이미지는 학습 결과에 대한 출력 예시입니다. 그래프에서 나타나는 배경색은 모델이 예측한 결과, O/X 가 나타내는 색은 실제값 (ground truth) 입니다. 모델이 맞게 예측한 경우 O, 틀리게 예측한 경우 X 로 표시됩니다.
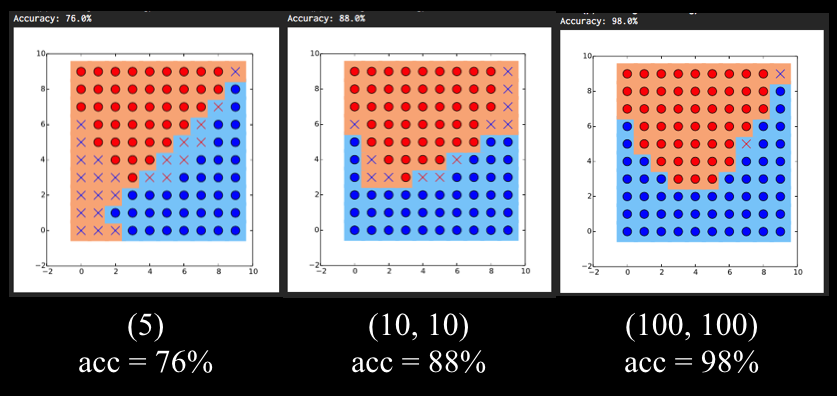
출처:엘리스import numpy as np
from visual import *
from sklearn.neural_network import MLPClassifier
from elice_utils import EliceUtils
elice_utils = EliceUtils()
import warnings
warnings.filterwarnings(action='ignore')
np.random.seed(100)
# 데이터를 읽어오는 함수입니다.
def read_data(filename):
X = []
Y = []
with open(filename) as fp:
N, M = fp.readline().split()
N = int(N)
M = int(M)
for i in range(N):
line = fp.readline().split()
for j in range(M):
X.append([i, j])
Y.append(int(line[j]))
X = np.array(X)
Y = np.array(Y)
return (X, Y)
'''
1. MLPClassifier를 정의하고 hidden_layer_sizes를
조정해 hidden layer의 크기 및 레이어의 개수를
바꿔본 후, 학습을 시킵니다.
'''
def train_MLP_classifier(X, Y):
clf = MLPClassifier(hidden_layer_sizes=(100, 100))
clf.fit(X,Y)
return clf
'''
2. 테스트 데이터에 대한 정확도를 출력하는
함수를 완성합니다. 설명을 보고 score의 코드를
작성해보세요.
'''
def report_clf_stats(clf, X, Y):
hit = 0
miss = 0
for x, y in zip(X, Y):
if clf.predict([x])[0] == y:
hit += 1
else:
miss += 1
score = hit/(hit+miss)*100
print("Accuracy: %.1lf%% (%d hit / %d miss)" % (score, hit, miss))
'''
3. main 함수를 완성합니다.
Step01. 학습용 데이터인 X_train, Y_train과
테스트용 데이터인 X_test, Y_test를 각각
read_data에서 반환한 값으로 정의합니다.
우리가 사용할 train.txt 데이터셋과
test.txt 데이터셋은 data 폴더에 위치합니다.
Step02. 앞에서 학습시킨 다층 퍼셉트론 분류
모델을 'clf'로 정의합니다. 'clf'의 변수로는
X_train과 Y_train으로 설정합니다.
Step03. 앞에서 완성한 정확도 출력 함수를
'score'로 정의합니다. 'score'의 변수로는
X_test와 Y_test로 설정합니다.
'''
def main():
X_train, Y_train = read_data('data/test.txt')
X_test, Y_test = read_data('data/train.txt')
clf = train_MLP_classifier(X_train,Y_train)
score = report_clf_stats(clf, X_test,Y_test)
visualize(clf, X_test, Y_test)
if __name__ == "__main__":
main()
