HPC(High Performance Computing)란?
세상에는 엄청난 양의 데이터가 있으며, 높은 컴퓨팅 성능은 기업이 데이터를 이해하는 데 도움이 될 수 있습니다. 한 분야의 대세에서 쇠퇴하기까지의 라이플사이클 흐름을 거친 기술의 경우, 더 많은 산업이 인공 지능, 기계 학습 및 기타 새로운 기술을 통해 분석한 중요한 통찰력을 활용할 수 있기 때문에 고성능 컴퓨팅(HPC)은 과학적 연구에서 발견되는 것 이상의 사용 사례로 확장될 수 있습니다.
그렇다면 이것이 조직에 어떤 의미가 있을까요?
비즈니스 성장을 지원하기 위한 방안으로, 추세를 추적하거나 하루에 수천 건의 금융 거래를 계산하기 위해 대량의 소비자 데이터를 분석해야 하는 필요성을 점점 더 느끼고 있다면 HPC를 고려해야 할까요?
이 글을 통해 HPC의 몇 가지 기본 사항을 다룰려고 합니다. 이를 통해 HPC를 도입해야 한다고 느끼게 된다면, 현재 진행 중인 작업에 대해 더 잘 이해할 수 있게 될 것입니다.
HPC가 무엇인가요?
HPC는 수백 또는 수천 대의 컴퓨팅 서버의 컴퓨팅 성능을 집계하는 것으로, 고성능 컴퓨팅은 일반 컴퓨터보다 훨씬 빠른 속도로 데이터 집약적인 계산을 수행할 수 있는 기능입니다. 이는 페타플롭(일반적인 컴퓨터의 전력보다 수백만 배 더 빠름) 또는 엑사플롭 단위로 측정할 수 있는 계산 능력에 대해 이야기하는 것입니다. 이러한 종류의 엑사스케일 컴퓨팅은 게놈 시퀀싱에서 폭풍 진행경로 예상에 이르기까지 수많은 산업 및 전문 분야에서 작업을 발전시키는 데 필요합니다.
HPC를 알아야 하는 이유는 무엇일까요?
HPC 기능은 역사적으로 학술적인 연구를 발전시키는 데 사용되었지만, 인공 지능 및 기타 데이터 집약적인 분야의 사용 사례가 증가함에 따라 다른 산업에서도 HPC 솔루션의 하나인 HPC와 유사한 인프라 및 슈퍼컴퓨터 활용에 대한 이점을 발견하기 시작했습니다.
HPC와 슈퍼컴퓨팅이라는 용어를 같은 의미로 사용하는 경우가 있지만, 일반적으로 HPC는 우리가 이미 다룬 강력한 처리 능력을 의미하고, 슈퍼컴퓨터는 매우 빠른 네트워크를 통해 상호 연결된 많은 컴퓨터와 프로세서에 데이터를 공급하는 관련 저장소로 구성된 단일 시스템입니다.
필요한 초기 비용, 전문화된 인프라 및 유지 관리 비용을 감안할 때 많은 조직에서 슈퍼컴퓨터를 감히 도입할 수 없는 영역이라고 생각할 수 있습니다. 특히 이러한 유형의 컴퓨팅이 국가 연구소용으로 도입되었다는 점을 고려해보면 충분히 납득할 수 있습니다.
그러나 오픈 소스 접근 방식이 도입되면서 HPC 솔루션에 더 쉽게 접근할 수 있게 되었습니다. 예를 들어, 1990년대까지 산업 표준 구성 요소로 구축된 대규모 병렬 컴퓨터 클러스터가 독점 적인 하드웨어와 함께 등장하기 시작했습니다. 이것은 HPC에서 Linux 및 오픈 소스 소프트웨어를 급격히 채택하기 시작하면서 모든 고성능 컴퓨팅 사이트에서 유비쿼터스(언제 어디서나 접속 가능한 환경)가 실현되던 때입니다. 그리고 최근에는 2000년대 후반부터 기존 HPC 워크로드 중 일부가 클라우드 리소스로 이동하기 시작했습니다. 업계는 모놀리식 온프레미스 슈퍼컴퓨터 대신 특정 하드웨어에서 분리된 워크로드와 함께 개방형 표준을 기반으로 하는 유연한 인프라로 발전했습니다.
그리고 산업에 관계없이 점점 더 많은 기업들이 대규모 컴퓨팅 문제에 직면하면서 HPC는 빅데이터와 융합하는 시점에 있습니다. 이는 데이터 홍수의 시대에서 시간 및 비용의 범위 내에서 데이터를 처리해야 하는 필요성에서 비롯됩니다. 컴퓨팅 성능이 향상되면 더 큰 데이터셋을 더 빠르게 수집하고 동일한 시간에 더 많은 순열(permutations)을 실행할 수 있기때문에 궁극적으로 문제를 더 효율적으로 해결할 수 있습니다.
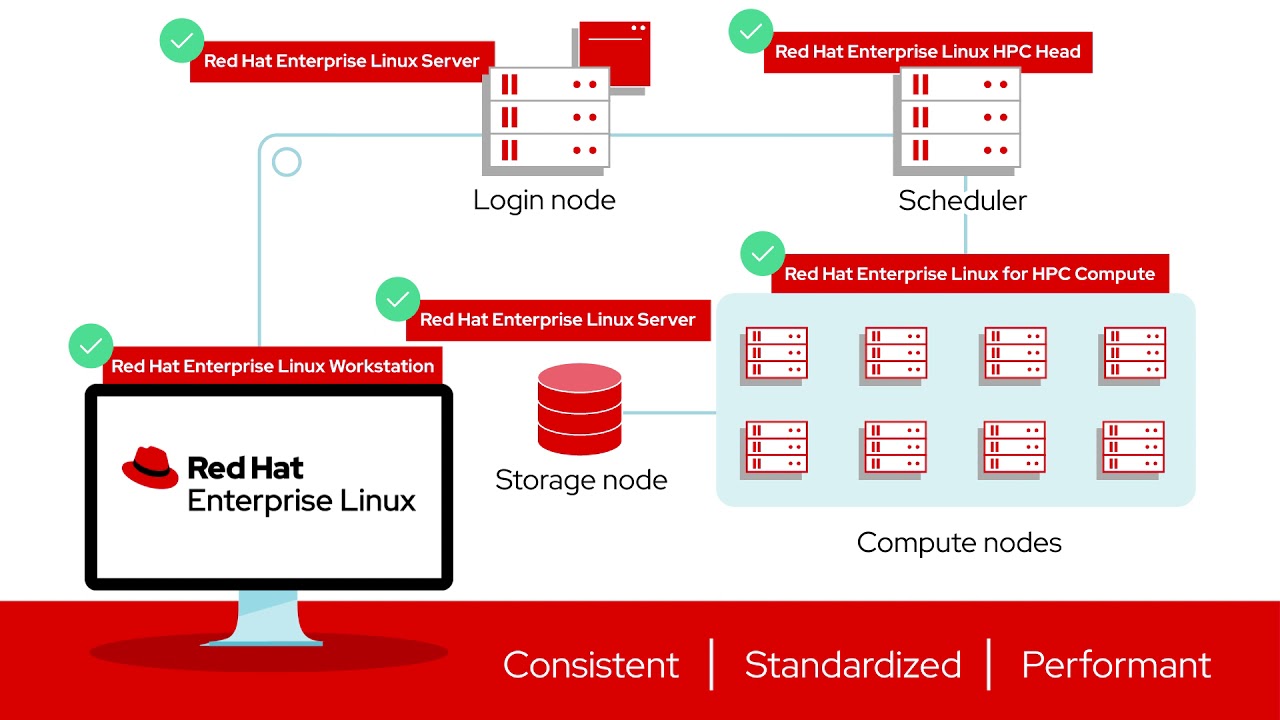
HPC 시스템을 구성하는 요소는 무엇일까요?
HPC 시스템은 실제로 컴퓨터의 그룹 또는 클러스터입니다. HPC 시스템의 주요 요소는 네트워크, 스토리지 및 컴퓨팅입니다. 시스템의 컴퓨팅 부분은 네트워크를 통해 제공된 데이터를 가져와 결과를 생성합니다.
HPC 클러스터는 함께 네트워크로 연결된 수백 또는 수천 개의 컴퓨팅 서버 또는 노드로 구성됩니다. 노드는 서로 병렬로 작동하여 큰 작업의 작은 부분을 동시에 실행하므로 하나의 문제를 해결하는 데 걸리는 시간이 줄어듭니다. 병렬 처리라는 용어는 여기에서 유래했습니다. HPC의 주요 이점은 이런 병렬처리에 있지만, 사전 정의된 순서 또는 여러 연속 단계에서 하드웨어 및 소프트웨어 리소스를 사용하는 워크플로우 역시 점점 증가하고 있습니다.
모든 노드는 조화롭게 작동하기 위해 서로 통신할 수 있어야 하며 컴퓨터는 네트워크를 통해 통신합니다. 네트워킹을 통해 클러스터는 데이터 저장소와 통신할 수 있으며 HPC는 이러한 구성 요소 간의 고속 데이터 전송을 지원할 수 있어야 합니다.
마지막으로, HPC 애플리케이션의 성능에 중요한 스토리지 구성 요소는 데이터가 처리되는 속도만큼 빠르게 컴퓨팅 서버에 데이터를 공급하고 수집할 수 있어야 합니다.
오픈소스와 Linux는 세계 최고의 슈퍼컴퓨터를 지원합니다
HPC 클러스터는 소프트웨어 없이는 실행되지 않습니다. 오픈 소스 소프트웨어는 진입 장벽을 낮추고 과학 커뮤니티의 협업을 더 쉽게 만듭니다.
HPC 클러스터를 실행하기 위한 가장 인기 있는 선택 중 하나는 Linux이며 RHEL(Red Hat Enterprise Linux)은 세계 최고의 슈퍼컴퓨터들이 선택하는 운영 체제입니다. 세계에서 가장 강력한 컴퓨터 시스템 500개 목록이 연 2회(6월과 11월) 공개됩니다. 거의 30년 동안 TOP500 순위는 기술 산업 및 그 이상에서 데이터와 소프트웨어의 교환을 장려하면서 HPC 시장에 활력을 불어넣었습니다.
Container 및 HPC의 다음 단계
컨테이너는 애플리케이션 코드, 종속성 및 사용자 데이터를 패키징하는 기능을 제공하여 글로벌 커뮤니티 전반에서 통찰력과 데이터 공유를 단순화하고 분산된 사이트와 클라우드 간에 애플리케이션을 더 쉽게 마이그레이션할 수 있도록 합니다.
이런 기능적인 특성으로 인해, 컨테이너는 HPC와 많은 연관성이 있습니다. Podman은 HPC 시장에서 많은 가능성을 보여주는 컨테이너 엔진 중 하나이며, 컨테이너 채택이 계속 증가함에 따라 Kubernetes 기반 Red Hat OpenShift와 같은 HPC를 지원하는 컨테이너 오케스트레이션 플랫폼에 대한 필요성에 초점이 맞춰질 것입니다.
오픈 소스 소프트웨어, 기성 하드웨어 및 커뮤니티 기반의 표준은 HPC의 지속 가능성에 매우 중요합니다. HPC 세계의 혁신은 커뮤니티 주도로 이루어졌으며, 최근 클라우드 기술을 채택하는 업계의 움직임은 HPC 기능을 커뮤니티 외부의 조직에 적용하는 데 도움이 될 수 있습니다. 기술 산업, 학계 및 기타 공공 기관 간의 협력은 궁극적으로 HPC 및 클라우드에 대한 확장된 기능을 주도할 것입니다.
그럼 결론은..?
디지털 컴퓨터의 세계 이전에 "컴퓨터"라는 용어는 수학적 계산을 수행하는 사람들을 지칭하는 데 사용되었습니다. 인간은 많은 일을 할 수 있지만 컴퓨터는 우리의 손이 닿지 않는 범위에서 정보를 처리하는 것을 가능하게 합니다. 그리고 노트북이나 데스크탑 컴퓨터의 계산 능력은 오늘날 가장 복잡하고 중요한 과학적 문제를 해결하는 데 사용할 수 있는 고성능 컴퓨팅 시스템에 비해서는 부족한 수준입니다.
오픈 소스 접근 방식을 사용하면 HPC 인프라 및 애플리케이션이 과학을 훨씬 뛰어넘어 엔터프라이즈 데이터 센터로 유입되고 클라우드로 이동할 수 있습니다. Red Hat은 HPC에 대해 많은 지원을 하고 있으며, 이후로도 계속해서 발전해 나갈 것입니다. Red Hat에서 무엇을 하고 있는지 이 곳에서 확인해 볼 수 있으며, 이를 통해 HPC 환경을 이해하고 선택하는데 많은 도움이 될 것입니다.
참고한 문서들
- https://www.redhat.com/ko/topics/high-performance-computing/what-is-high-performance-computing
- https://insidehpc.com/white-paper/insidehpc-guide-hpc-moves-cloud/
- https://www.redhat.com/ko/resources/business-transformation-high-performance-computing-whitepaper
- https://www.redhat.com/ko/blog/open-source-and-collaboration-propel-rhel-top-top500
