메모리 관리
1. 메인 메모리 개요
메모리는 RAM을 의미한다. SRAM은 캐시 메모리에 사용되고 DRAM이 메인 메모리에 사용된다.
운영체제가 등장하고 운영체제의 역할이 프로세스 관리도 중요했지만 메모리 관리가 매우 크게 차지했다. 메모리가 매우 비싼 자원으로 속했기 때문이다.
현재 메모리 용량이 매우 크게 증가했지만 여전히 메모리를 관리하는 역할은 매우 중요하다.
메모리 용량이 증가했지만 프로그램의 크기 또한 계속해서 증가하고 있기 때문에 메모리의 용량은 언제나 부족한 상태이다.
프로그램이 처음 시작할 때는 기계어나 어셈블리언어로만 작성을 하는 형태가 많이 있었다. 하지만 시대를 넘어오면서 수많은 다른 언어를 사용하기 시작했다. 프로그램의 크기가 점차 커지기 시작하는 것이다. 요즘에는 숫자 처리, 문자 처리뿐만 아니라 멀티미디어 처리, 빅데이터 처리 등을 위해 프로그램이 사용되므로 프로그램의 크기가 매우 커지고 있기 때문에 메모리의 큰 공간을 차지하게 된다. 이에 중요한 문제가 어떻게 하면 메모리를 효과적으로 사용할 수 있는가에 대한 질문이다. 그래서 메모리 사용의 낭비를 없애는 방법을 많이 찾게 되었다. 이러한 형태 중 하나가 가상 메모리라는 도구가 있다.
메모리는 주소와 데이터로 구성되어 있다. CPU가 원하는 데이터의 주소를 메모리에 보내주게 되면 메모리는 CPU에게 해당하는 데이터를 보내준다. 또한 CPU에서 계산된 결과를 메모리의 특정 주소에 저장하고 명령을 보내면 메모리에서 해당 주소에 데이터를 저장한다.
프로그램을 개발할 때는 여러 가지의 파일 형태를 가진다. 소스 파일은 고수준언어 또는 어셈블리언어로 개발된 파일을 말한다. 소스 파일은 컴파일러와 어셈블러에 의해 목적 파일로 전환된다. 목적 파일은 소스 파일에 대한 컴파일 또는 어셈블 결과를 나타내는 파일로 기계어로 나타내어진다. 목적 파일을 링크가 실행파일로 바꾼다. 실행파일은 링크의 결과로 나타난 파일이다. 링크는 하드디스크에 들어가 있는 다양한 내장 함수(Library)들을 실행하기 위해 연결해주는 과정이다. 만들어진 실행 파일을 메모리에 적재하는 과정을 하는 것은 로더이다. 실행 파일은 로더에 의해 적재되어야만 실행이 가능하다.
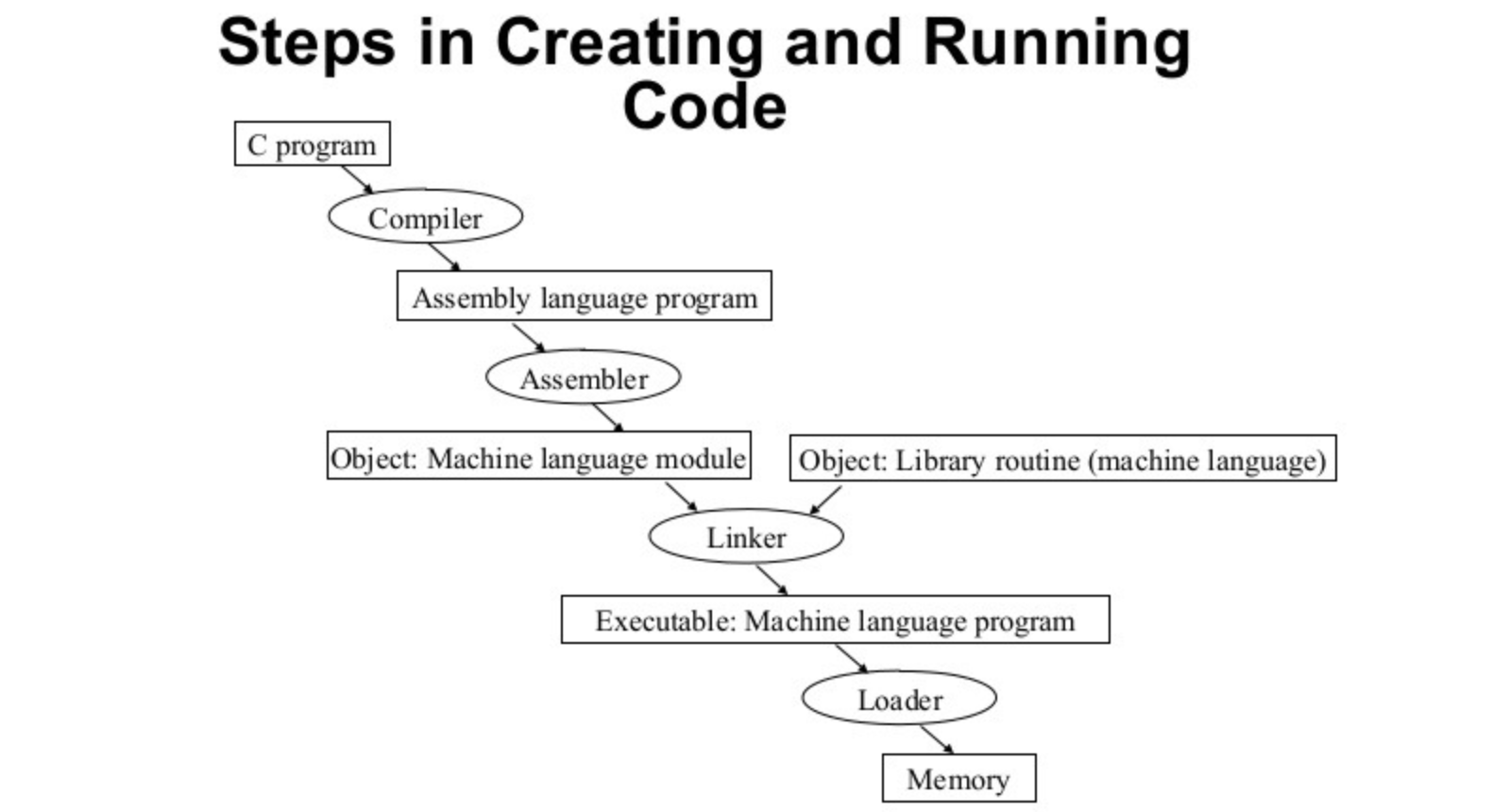
하나의 프로그램이 실행되기 위해서는 코드와 데이터, 스택을 가지고 있어야한다. 코드의 경우에는 앞에서 작성한 파일들이 될 수 있다. 데이터의 경우는 프로그램이 실행될 때 넣어주어야 할 값이 된다. 예를 들어 두 수 중 큰 수를 나타내어 주는 프로그램이 있으면 큰 수를 나타내게 해주는 작업을 해주는 부분이 코드이고 두 수를 입력하는 값이 데이터이다. 스택은 함수를 호출했을 때 돌아오는 줏와 지역변수를 저장하는 공간이다.
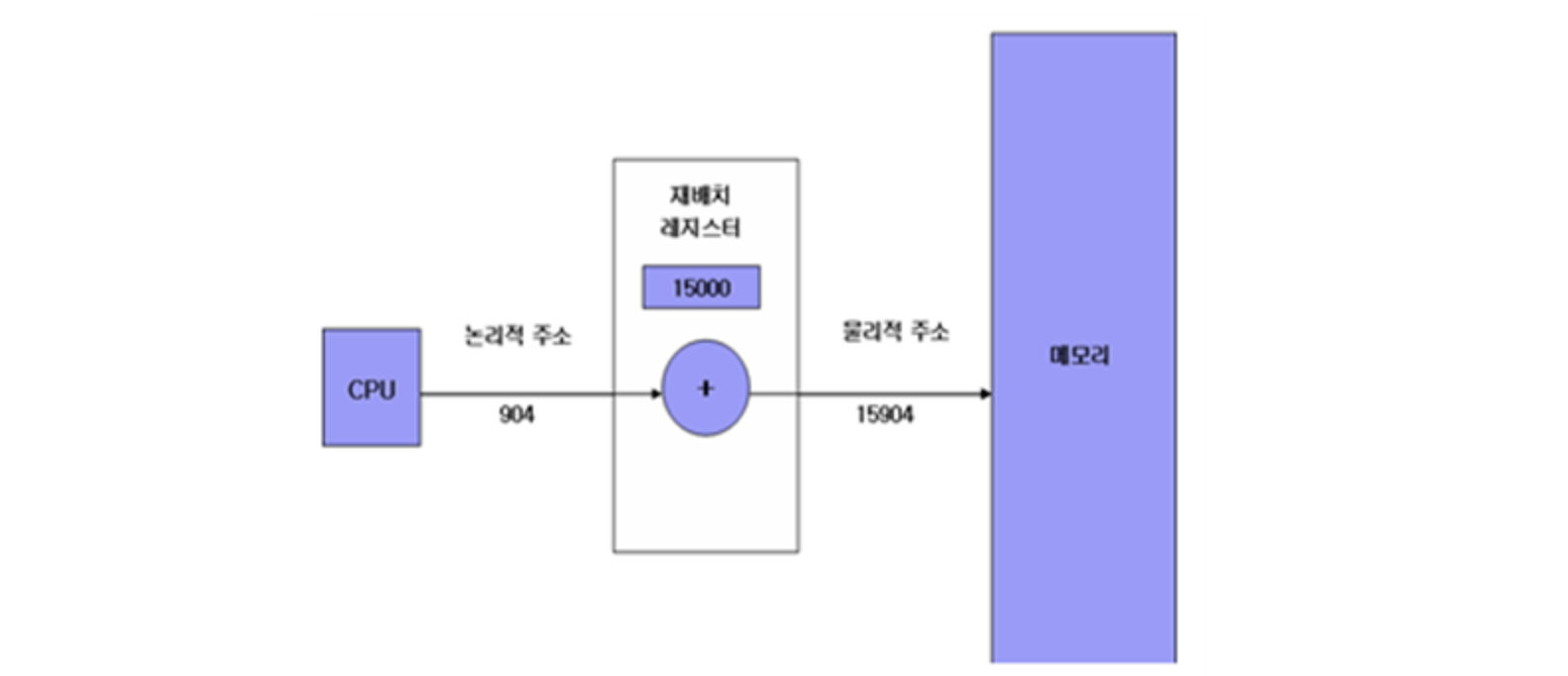
실행 파일이 만들어지면 로더에 의해 메모리에 올려진다고 했다. 운영체제는 이 실행 파일을 메모리의 어디 부분에 올릴지를 결정한다. 다중 프로그래밍 환경에서 메모리에 프로그램을 넣어주고 다시 하드디스크로 보내주고 하는 과정들을 모두 운영체제에서 담당하여 처리한다. 사실 고수준언어를 작성할 때에는 주소를 사용하여 작성하진 않지만 목적 파일로 바뀌어 실행 파일을 사용하면 주소의 값을 통해 코드를 이동하고 작동을 하게 된다. 따라서 메모리에 적재할 때 적절한 메모리 위치에 프로그램을 넣지 않으면 문제가 발생할 수 있다. 이러한 문제를 해결하는 것이 MMU이다. MMU는 주소의 영역을 정해주는 역할을 한다. MMU에는 재배치 레지스터가 존재하는데 이는 코드가 원하는 주소를 만들어주는 역할을 한다. 예를 들어 코드에서 0번지에 들어가야하는 프로그램이 작성되어 있는데 메모리에서 빈 공간이 주소가 500번지인 곳에 있다고 했을 때, 재배치 레지스터에서 500이라는 값을 더해주어 500번지에서 실행하는 것이 맞게 해주는 것이다.
2. 메모리 낭비 방지
하드디스크에 존재하는 프로그램들은 메모리의 특정 부분에 적재되어 실행된다. 프로그램이 만들어지기까지 소스 파일, 목적 파일, 실행 파일을 거쳐 로더에 의해 메모리에 올려지게 되는데, 적절한 위치에 적재를 해야 실행시킬 수 있다. 앞장에서 MMU의 재배치 레지스터를 이용하면 부분적으로 적절한 위치에 프로그램을 올릴 수 있다.
MMU가 메모리를 관리하는 방법에 대해 조금 더 상세히 들어가 보면,
MMU는 프로그램이 동작할 때 필요한 데이터나 동작들을 메모리의 특정 주소 위치로부터 가지고와야 하는데 이는 프로그램이 만들어질 때 코드화되어 있다. 따라서 항상 같은 위치의 메모리 주소로부터 데이터를 불러오게 된다. 하지만 메모리에 프로그램을 적재할 때 항상 같은 위치에 프로그램을 올릴 수는 없다. 어떤 날에는 0번지에 올리기도 하고 다른 날에는 500번지에 올리기도 한다.
이는 메모리 공간에서 빈 공간을 찾아 프로그램을 올리기 때문에 알 수가 없다. 그래서 이를 맞추어 조절해주는 역할을 하는 것이 바로 MMU의 재배치 레지스터이다. 재배치 레지스터는 CPU가 프로그램을 실행시킬 때 코드를 읽어서 들어가는데 코드에서 특정 위치의 메모리 주소로부터 데이터를 가지고 오라는 동작을 할 때 도움을 준다. CPU는 분명 특정 위치를 가르쳐 줬지만 재배치 레지스터는 이 주소에서 메모리에 프로그램이 있는 위치 주소를 더해서 계산해서 CPU에서 원하는 데이터 위치와 메모리상에 프로그램의 위치가 맞게 맞추어 준다. 여기서 CPU에서 MMU로 보내는 주소를 논리 주소라 하고, MMU에서 메모리로 보내는 주소를 물리 주소라고 한다.
-
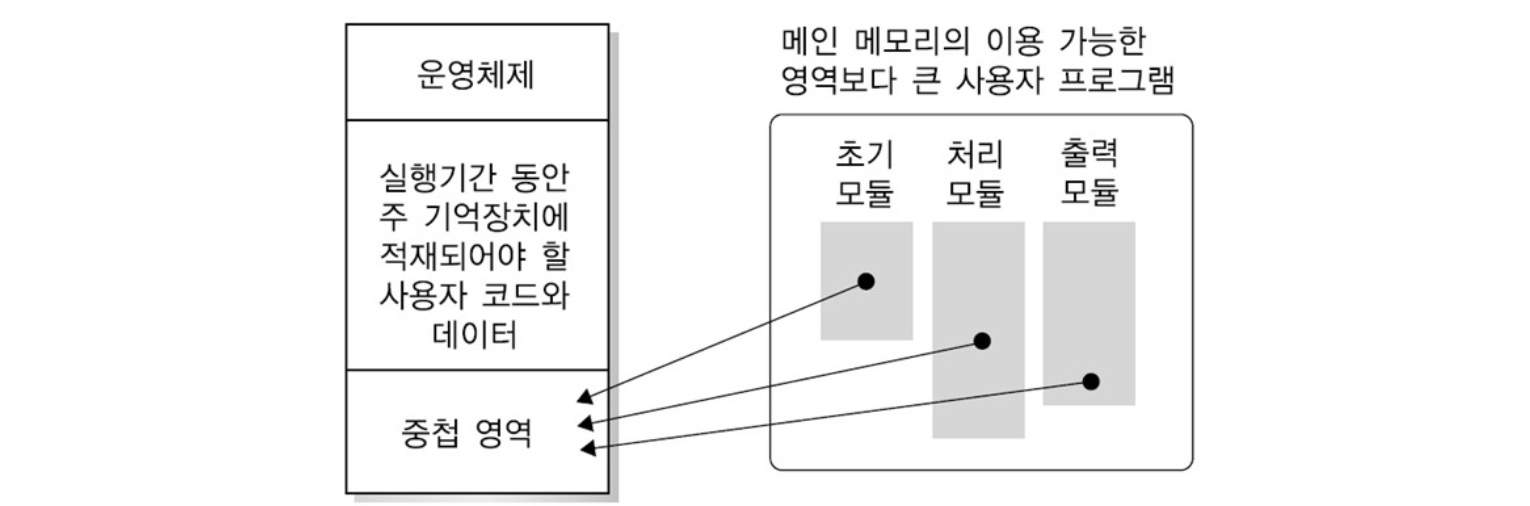
동적 적재(Dynamic Loading)
- 프로그램 실행에 반드시 필요한 루틴/데이터만 적재하는 것을 의미한다.
- 모든 루틴과 데이터가 다 사용되는 것이 아니기 때문에, 실행 시 사용을 할 경우에만 메모리로 적재한다. -> 오류처리나 사용하지 않는 데이터는 항상 필요하지 않다.
- 메모리의 효율을 높일 수 있다.
-
동적 연결(Dynamic Linking)
- 여러 프로그램에 공통 사용되는 라이브러리를 관리하는 방법이다.
- 라이브러리 루틴 연결을 컴파일 시점에 하는 것이 아닌 실행 시점까지 미루는 기법이다.
공통 라이브러리 루틴은 한 라이브러리 루틴만 메모리에 적재해 연결하도록 하게 해서 메모리의 효율을 높인다. - 동적 연결을 하지 않으면 각각의 프로그램에 필요한 라이브러리가 각각 메모리에 적재되게 되어 메모리가 낭비된다.
-
스와핑(Swapping)
- 메모리 관리를 위해 사용되는 기법이다.
- 메모리에 적재되어 있으나 현재 사용되지 않고 있는 프로세스는 저장장치의 Swap 영역으로 이동해 메모리를 확보한다.
- 컨텍스트 스위칭으로 인한 오버헤드가 발생할 수 있고 속도가 느려지지만, 메모리 공간 확보에는 효율적이다.
- 표준 스와핑방식으로는, 라운드로빈과 같은 스케줄링의 다중 프로그래밍 환경에서 CPU 할당 시간이 끝난 프로세스의 메모리를
backing store(보조기억장치, e.g 하드디스크)로 내보내고(swap-out), 다른 프로세스의 메모리를 불러들인다.(swap-in)
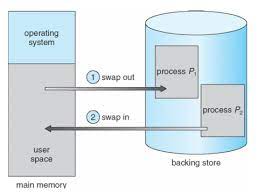
위의 과정을 swap(스왑시킨다)이라 한다. 주 기억장치(RAM)로 불러와 메모리로 적재해서 올려주는 과정을 swap-in, 보조 기억장치(backing store)로 내보내는 과정을 swap-out 이라고 한다. MMU의 재배치 레지스터를 사용하므로 적재 위치는 메모리의 빈 공간 어디에도 적재가 가능하다. 이런 작용으로 메모리의 활용도를 높일 수 있어 효율이 높아진다.
하지만 프로세스의 크기가 크면 backing store 입출력에 따른 부담이 크다. 다시 말하면, swap에는 큰 디스크 전송시간이 필요하기 때문에 현재에는 메모리 공간이 부족할 때 스와핑이 시작된다.
3. 메모리 관리 전략
1. 연속 메모리 할당
- 프로세스를 메모리에 연속적으로 할당하는 기법이다.
- 할당과 제거를 반복하다보면 Scattered Holes가 생겨나고 이로 인한 외부 단편화가 발생한다.
연속 메모리 할당에서 외부 단편화를 줄이기 위한 할당 방식
a. 최초 적합(First fit)
- 메모리의 처음부터 검사해서 크기가 충분한 것 중 가장 처음 만나는 빈 메모리 공간에 프로세스를 할당한다.
- 속도가 빠르다.
b. 최적 적합(Best fit)
- 빈 메모리 공간의 크긱와 프로세스의 크기 차이가 가장 적은 곳에 프로세스를 할당한다.
c. 최악 적합(Worst fit)
- 빈 메모리 공간의 크기와 프로세스의 크기 차이가 가장 큰 곳에 프로세스를 할당한다.
- 이렇게 생긴 빈 메모리 공간에 또 다른 프로세스를 할당할 수 있을 거라는 가정에 기인했다.
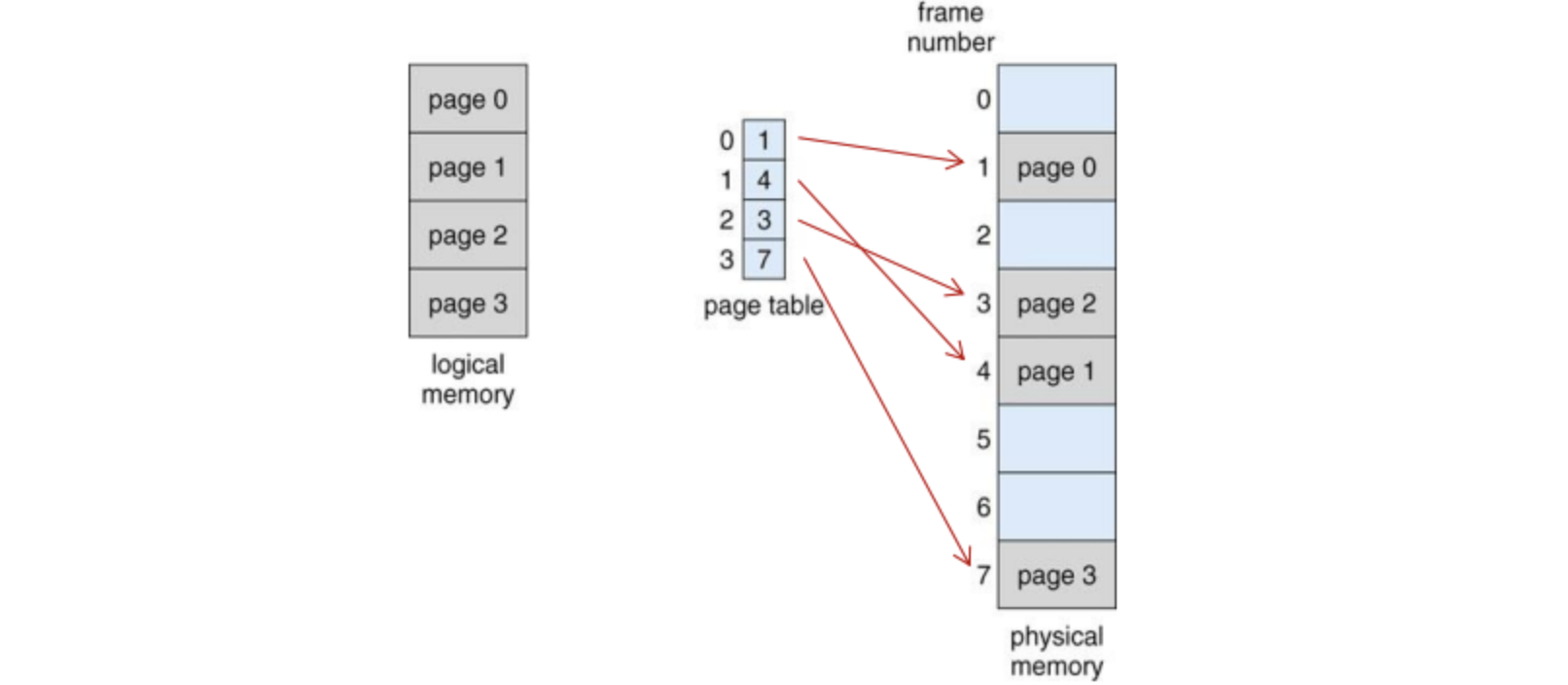
2. 페이징(Paging)
- 메모리 공간이 연속적으로 할당되어야 한다는 제약조건을 없애는 메모리 관리 전략이다.
- 논리 메모리는 일정 크기의 페이지, 물리 메모리는 페이지와 같은 크기의 프레임 블록으로 나누어 관리한다.
- 프로세스를 여러 개의 페이지로 나누어 관리하고, 개별 페이지는 순서에 상관없이 물리 메모리에 있는 프레임에 매핑되어 저장한다.
- 프로세스를 나눈 페이지마다 MMU의 재배치 레지스터 방식를 만들어 놓아서 CPU가 마치 프로세스가 연속된 메모리에 할당된 것처럼 인식하도록 한다. 왜냐하면 재배치 레지스터에서 메모리 적재 공간의 값을 더해주어 CPU를 속이기 때문이다.
- 내부 단편화가 발생한다.
즉, 주기억장치는 일정 크기의 프레임으로 나뉜다. 각 프로세스는 프레임들과 같은 크기를 가진 페이지들로 나뉜다. 같은 크기로 페이지와 프레임이 잘라져 있기 때문에 페이지를 프레임에 할당하면 딱 맞아 떨어진다. 이 때 페이지를 관리하는 MMU는 페이지 테이블이 된다. 페이지 테이블 안에 있는 개수는 프로세스를 몇 등분 하는가에 따라 결정된다. 프로세스의 모든 페이지가 프레임에 적재되어야 하며 이 페이지를 저장하는 프레임들은 연속적일 필요는 없다.
CPU가 내는 주소는 논리 주소(Logical address)라고 한다. CPU에서 보낸 논리 주소는 MMU 인 페이지 테이블을 통해 물리 주소(Physical address)로 바뀌어서 메모리에서 찾게 된다.
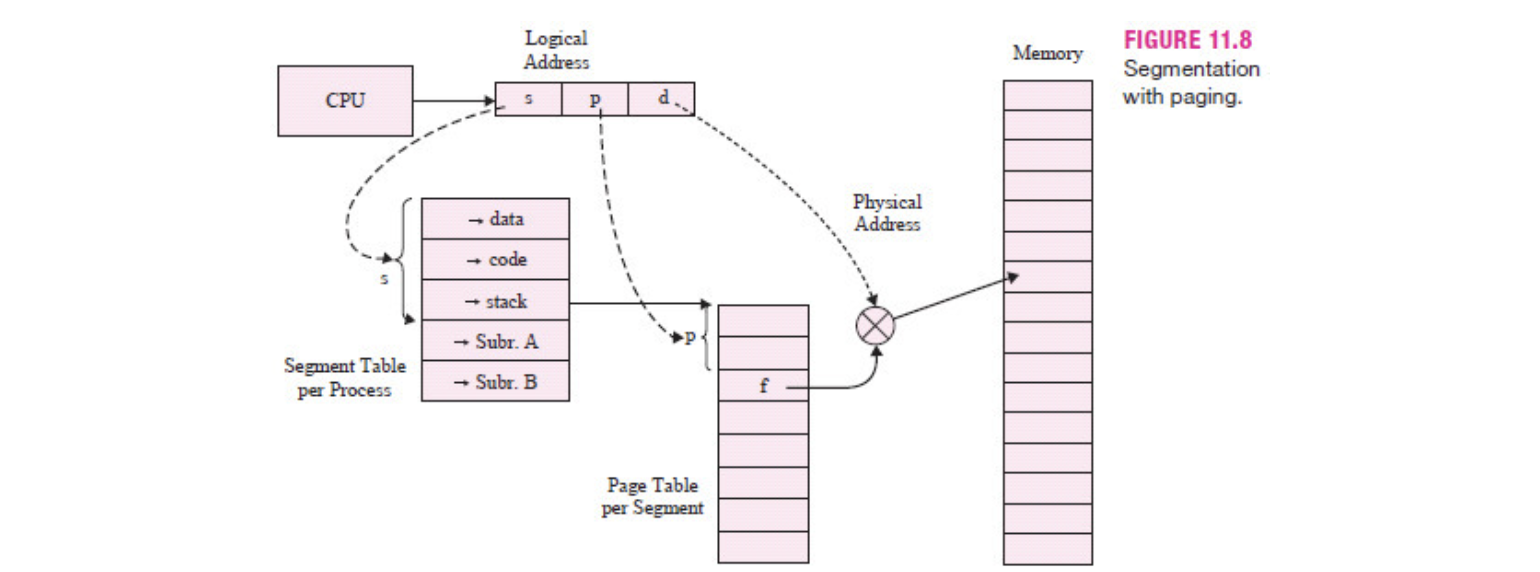
3. 세그멘테이션(Segmentation)
- 페이징 기법과 반대로 논리 메모리와 물리 메모리를 같은 크기의 블록이 아닌, 서로 다른 크기의 논리적 단위인 세그먼트로 분할한다. 프로세스의 모든 세그먼트가 적재되어야 한다.
- 세그멘테이션은 물리적인 크기의 단위가 아닌 논리적 내용의 단위(의미가 같은)로 자르기 때문에 세그먼트들의 크기는 일반적으로 같지 않다.
- 프로세스를 어떻게 자르는가에 대한 방법 빼고 메모리에 할당하는 방법은 페이징과 같다. MMU 내의 재배치 레지스터를 이용해 논리 주소를 물리 주소로 바꾸어 주는 방식을 취한다.
- MMU는 세그먼트 테이블로 CPU에서 할당한 논리 주소에 해당하는 물리 주소의 위치를 가지고 있다.
- 외부 단편화가 발생한다.
4. 페이징과 세그멘테이션의 차이점
- 페이징이 프로그래머한테 투명한데 비해, 세그먼테이션은 보통 프로그래머가 각 세그먼트를 지정할 수 있으며 프로그램과 데이터를 편의대로 나누기 위한 수단으로 제공된다.
- 구조적 프로그래밍을 위해 프로그램 또는 데이터가 더 세분화된 여러 세그먼트들로 나뉠 수 있다. 이런 세그먼트 기법을 사용하는 데 있어 가장 불편한 점은 프로그래머가 세그먼트의 최대 크기를 알아야한다는 것이다. (페이징은 몰라도 된다.)
5. 페이징과 세그멘테이션 혼용 기법
- 페이징과 세그멘테이션도 각각 내부 단편화와 외부 단편화가 발생한다.
- 페이징과 세그멘테이션을 혼용해 이러한 단편화를 최대한 줄이는 전략이다.
- 프로세스를 세그먼트(논리적 기능 단위)로 나눈 다음 세그먼트를 다시 페이지 단위로 나누어 관리한다.
- 매핑 테이블을 두 번 거쳐야하므로 속도가 느려진다.
4. 단편화(Fragmentation)
메모리 공간이 충분함에도 프로세스가 메모리에 적재되지 못해 메모리가 낭비되는 현상이다.

1. 내부 단편화(Internal Fragmentation)
- 프로세스가 사용하는 메모리 공간에 포함된 남는 부분이다.
- 고정 분할 방식에서 프로세스가 실제 사용해야할 메모리보다 더 큰 메모리를 할당받아 메모리가 낭비되는 현상이다.
- 예를 들어 메모리 분할 자유 공간이 10,000B있고 프로세스A가 9,998B를 사용하게 되면 2B의 차이가 존재하게 되고, 이 현상을 내부 단편화라 칭한다.
2. 외부 단편화(External Fragmentation)
- 메모리 공간 중 사용하지 못하게 되는 일부분이다.
- 가변 분할 방식에서 프로세스가 적재되고 제거되는 일이 반복되면서, 여유 공간이 충분함에도 불구하고 이러한 여유 공간들이 조각으로 흩어져 있어(Scattered Holes) 메모리에 프로세스를 적재하지 못해 메모리가 낭비되는 현상이다.
- 즉, 물리 메모리(RAM)에서 사이사이 남는 공간들을 모두 합치면 충분한 공간이 되는 부분들이 분산되어 있을 때 발생하는 현상이다.
3. 압축
- 외부 단편화를 해소하기 위한 방법으로 Scattered Holes를 모으는 방법이다.
- Scattered Holes를 합치는 과정에서 메모리에 적재된 프로세스를 정지시키고 한쪽으로 이동시키는 작업이 필요해 비효율적이다.
- 또한, Scattered Holes를 어느 자유공간을 기준으로 모을지 결정하는 알고리즘도 모호하다.
위의 메모리 현황을 압축 작업을 하게 되면 아래와 같이 바뀐다.

가상메모리
1. 가상메모리란?
- 프로세스 전체가 메모리 내에 적재되지 않더라도 실행이 가능하도록 하는 기법이다.
- 가상 메모리 기법을 통해 물리 메모리 크기에 제약받지 않고 더 많은 프로그램을 동시에 실행할 수 있다.
- 프로세스에서 필요한 영역만 메모리에 적재함으로써 메인 메모리에 적재하는 프로세스의 크기를 줄일 수 있다.
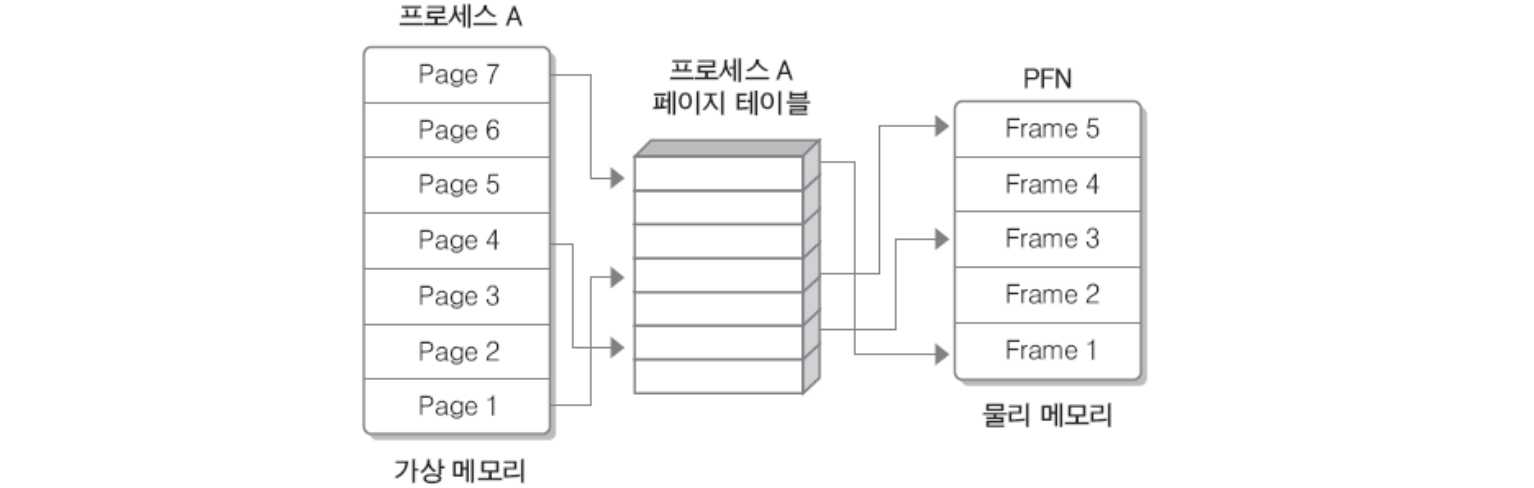
2. 가상메모리를 사용하는 이유?
1. 보다 많은 프로세스를 주기억장치에 유지할 수 있다.
각 프로세스에 대해 일부 블록들만 적재하므로 많은 프로세스를 적재할 수 있다. 이로 인해 임의 시점에 하나 이상의 프로세스가 준비 상태에 있을 가능성이 커지므로 프로세서의 활용도가 높아진다.
2. 주기억장치보다 큰 프로세스를 수행할 수 있다.
프로그래밍에 있어 가장 근본적인 제약점 중 하나가 제거된다. 이 기법을 적용하지 않을 경우, 프로그래머는 얼마나 많은 메모리 공간을 사용할 수 있는지 정확히 인식해야한다. 프로그램이 클 경우, 오버레이 같은 기법을 적용하여 분할 적재할 수 있도록 프로그램을 여러 블록으로 구조화할 수 있는 방법을 모색해야 한다.
3. 가상메모리의 크기
- 가상메모리의 크기는 이론상 CPU bit, 버스 대역폭에 따르게 된다.
- CPU 비트 수로 표현할 수 있는 주소값의 범위이다.
- 32 bit CPU에서 가상메모리의 크기 : 2^32 - 1 (4GB)
- 64 bit CPU에서 가상메모리의 크기 : 2^64 - 1(16,000,000 TB)
4. 가상메모리 관리방법
- TLB(Translation Lookaside Buffer)
원칙적으로 모든 가상메모리 참조는 두 번의 물리메모리 참조를 수반한다. 한 번은 해당 페이지테이블 항목을 참조하기 위함이고, 다른 한 번은 요구된 데이터를 접근하기 위함이다. 이런 가상메모리 방식은 두 배의 메모리 접근 시간을 갖게 한다. 이러한 문제 해결을 위해 대부분의 가상메모리 방식은 페이지테이블 항목들에 대한 특수 고속캐시를 사용하는데 이를 일반적으로 TLB라 부른다. - 장점 : 속도가 빠르다.
5. 요구 페이징(Demand Paging)
- 가상 메모리에서 프로그램 실행을 위해 초기에 필요한 것만 적재하는 전략이다.
- 프로세스 내의 개별 페이지들은 페이저에 의해 관리된다.
- 프로세스 실행에 실제 필요한 페이지만 메모리에 적재해 사용되지 않을 페이지를 가져오는 시간과 메모리 낭비를 줄인다.
- 원리
프로세스의 이미지를 backing store에 저장한다. backing store은 swap device로 하드웨어의 부분인데 페이지를 임시로 보관하는 공간이다. 프로세스는 페이지의 조합이기 때문에 필요한 페이지만 메모리에 올린다. 이를 요구되는 페이지만 메모리에 올린다는 의미로 요구 페이징이라고 부른다.
6. 페이지 결함(Page Fault)
-
요구 페이징에서는 프로그램에 대한 모든 내용이 물리 메모리에 올라오지 않기 때문에 메모리에 없는 페이지에 접근하려할 때 페이지 폴트가 발생한다.
-
페이지 폴트가 발생하면 원하는 페이지를 저장 장치에서 가져오게 되고, 만약 물리 메모리가 가득 차있는 상태라면 페이지 교체가 이루어진다.
-
페이지 폴트 처리 과정
1) 페이지 폴트 발생
2) 디스크에서 해당 페이지 찾음
3) 빈 페이지 프레임을 찾음
4) 페이지 교체 알고리즘을 통해 Victim 페이지 선택
5) Victim 페이지를 디스크에 저장
6) 비워진 페이지 프레임에 새 페이지를 읽어옴
7) 재시작
7. 지역성의 원리
CPU가 프로세스 내의 명령어 및 데이터에 대한 참조가 군집화 경향이 있음을 뜻한다.
메모리 접근은 시간적, 공간적으로 지역성을 가진다.
지역성의 원리에 의해 페이지 결함으로 인한 컴퓨터의 효율이 떨어지는 확률이 많이 낮아진다.
1. 시간 지역성
- 한 번 읽었던 코드를 다시 읽을 확률이 높다는 것 (e.g while, for문)
= 참조했던 메모리는 빠른 시간내에 다시 참조될 확률이 높다 - 맨 처음에 페이지를 메인 메모리에 적재한 후에는 다시 적재할 필요가 없기 때문에 페이지 결함의 확률이 매우 낮다.
2. 공간 지역성
-
코드를 읽을 때 현재 코드의 주변에 있는 코드를 읽을 확률이 높다는 것
= 참조된 메모리의 근처 메모리는 참조될 확률이 높다 -
페이지 결함이 일어나 하드디스크에서 페이지를 가져올 때 주변 코드들을 블록 단위로 가져오게 되면 주변 코드를 읽을 확률이 높으니 페이지 결함의 확률이 낮아지는 것이다.
-
지역성의 원리는 참조된 메모리의 근처 메모리를 참조하는 공간 지역성의 원리, 참조했던 메모리는 빠른 시간내에 다시 참조될 확률이 높다는 시간 지역성의 원리, 데이터가 순차적으로 액세스되는 것을 말하는 순차 지역성 등이 있다.
8. 페이지 교체 알고리즘
요구 페이징은 요구되어지는 페이지만 backing store에서 가져와 메인 메모리에 적재하는 방법이다.
필요한 페이지만 메인 메모리에 올리므로 메모리의 낭비를 줄이는 방법으로 사용되었다.
하지만 프로그램 실행이 계속 진행되면서 요구 페이지가 늘어나게 되고 언젠가는 메모리가 가득 차게 될 것이다.
페이지를 backing store에서 가져와 메모리에 올려야 되는데 메모리에 자리가 없는 경우, 메모리에 있는 특정 페이지를 내보내고 그 자리에 필요한 다른 페이지를 올려야 한다. 이를 페이지 교체라고 한다.
메모리가 가득차면 추가로 페이지를 가져오기 위해 어떤 페이지는 backing store로 몰아내고 그 빈 공간으로 페이지를 가져온다.
backing store로 페이지를 몰아내는 것을 page-out이라고 하고, 반대로 빈 공간으로 페이지를 가져오는 것을 page-in이라고 한다. 여기서 몰아내는 페이지를 victim paged라고 말한다.
1. FIFO(First-In-First-Out)
- 선입 선출 즉, 물리 메모리에 먼저 올라온 페이지를 먼저 내보낸다는 알고리즘이다.
- FIFO는 가장 오래 전에 반입된 페이지는 이제 사용되지 않을 것이라는 전제하에 메모리에 가장 오래 머물렀던 페이지를 교체한다.
- 큐를 이용해 쉽게 구현이 가능하다.
- 오히려 페이지 부재율을 높일 수 있으며, Belady의 모순이 발생할 수 있다.
- Belady의 모순 : 페이지 프레임의 개수를 늘려도 페이지 부재가 줄어들지 않는 모순 현상
2. 최적 페이지 교체(OPT, Optimal Page Replacement)
- 가장 오랫동안 사용하지 않을 페이지를 찾아 교체하는 알고리즘이다.
- 가장 낮은 페이지 부재율을 보장한다.
- 하지만 운영체제가 미래에 일어날 사건들에 대해 완벽히 알 수 없으므로 이 정책의 구현은 어렵다.
3. LRU 페이지 교체(Least-Recently-Used Page Replacement)
- 가장 오랫 동안 참조되지 않은 페이지를 교체하는 알고리즘이다.
- 최적 페이지 교체에 근사한 알고리즘이다.(FIFO보다 낮은 페이지 부재율을 보장한다.)
-> 지역성의 원리에 따른다면, 이 페이지는 가까운 미래에 참조될 가능성이 가장 적을 것으로 예상되는 페이지가 분명하기 때문이다. - 우선순위 큐, Double Linked Queue & HashTable로 구현이 가능하다.
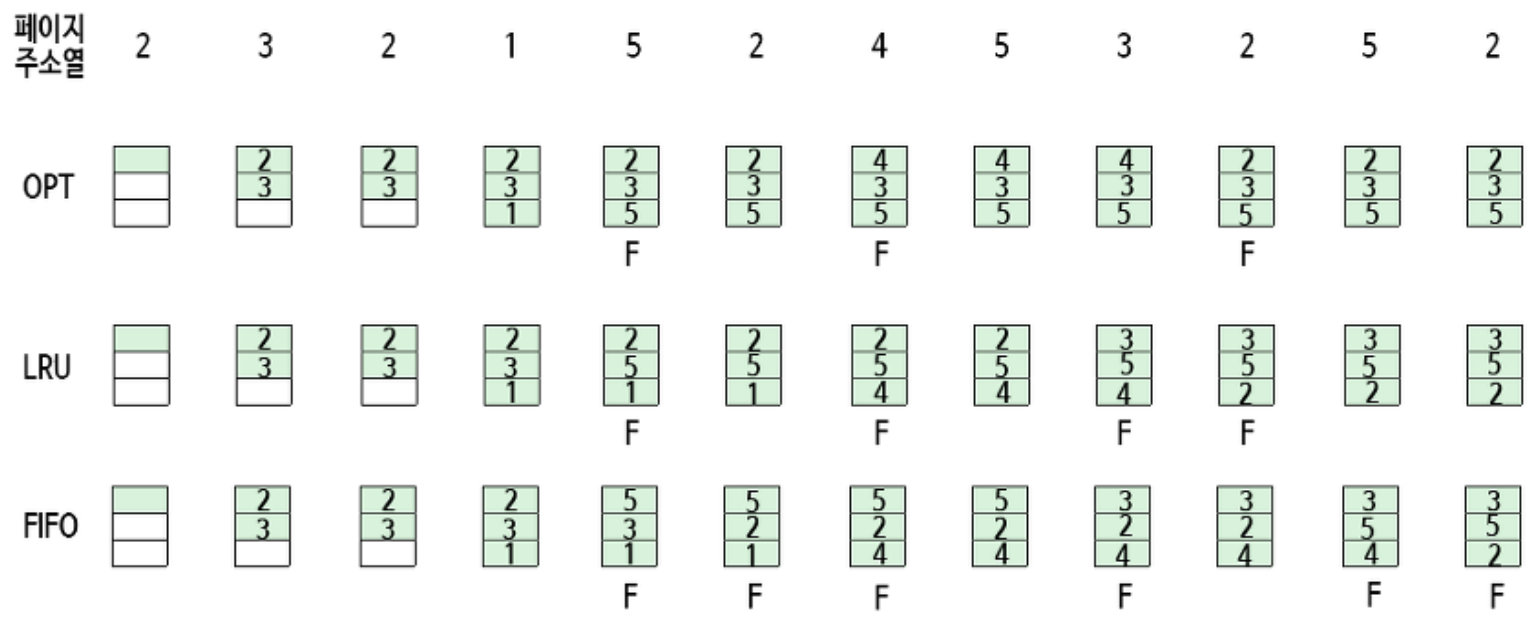
- 여기서 LRU는 페이지 2나 5가 다른 페이지보다 자주 참조된다는 것을 인식하지만, FIFO는 그렇지 않다.
9. 쓰레싱(Thrashing)
- 메모리에 페이지 부재율이 과도하게 높아지는 현상이다.
- 심각한 성능저하를 초래한다.
1. 원인
크게 두가지 원인이 있다.
1) CPU 이용률이 너무 낮아질 때
운영체제는 CPU 이용률이 너무 낮아질 때, 새로운 프로세스를 추가해 멀티프로그래밍 정도를 높이려 하는데, 이때 전역 페이지 교체 알고리즘으로 어떤 프로세스의 페이지인지에 대한 고려없이 페이지 교체를 수행한다.
그런데, 교체된 페이지들이 해당 프로세스에서 필요로 하는 자원이 있으면 페이지 폴트를 발생시키게 되고 그러면 swap in/out을 위해 페이징 장치를 사용해야 하는데 프로세스들이 페이징 장치를 기다리는 동안 CPU 이용률은 떨어지게 되고, CPU 스케줄러는 이용률이 떨어지는 것을 보고 멀티프로그래밍 정도를 더 높이려 하게 되어 쓰레싱이 일어나게 된다.
2) CPU 이용률이 너무 높아질 때
멀티 프로그래밍 정도가 높아짐에 따라 CPU 이용률이 최대값에 도달했을 때, 멀티프로그래밍 정도가 그 이상으로 커지게 되면 쓰레싱이 일어나게 되고 CPU 이용률은 급격히 떨어진다.
2. 해결 방법
지역 교체 알고리즘이나 우선순위 교체 알고리즘을 사용해 제한한다.
지역 교체 알고리즘에서는 한 프로세스가 쓰레싱을 유발하더라도 다른 프로세스로부터 페이지 프레임을 뺏어올 수 없으므로 다른 프로세스는 쓰레싱에서 자유로울 수 있다.
3. 방지법
- 각 프로세스가 필요로 하는 최소한의 프레임 개수를 보장한다.
- 페이지 프레임을 늘린다.
참고
https://sunday5214.tistory.com/7
https://velog.io/@deannn/CS-%EA%B8%B0%EC%B4%88-%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EA%B4%80%EB%A6%AC-%EC%A0%84%EB%9E%B5
https://copycode.tistory.com/88?category=740133
https://dheldh77.tistory.com/entry/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%EA%B0%80%EC%83%81%EB%A9%94%EB%AA%A8%EB%A6%ACVirtual-Memory
https://jwprogramming.tistory.com/56
