데이터 전처리
train.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 1 to 891
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Name 891 non-null object
3 Sex 891 non-null object
4 Age 714 non-null float64
5 SibSp 891 non-null int64
6 Parch 891 non-null int64
7 Ticket 891 non-null object
8 Fare 891 non-null float64
9 Cabin 204 non-null object
10 Embarked 889 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 83.5+ KBtest.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 418 entries, 892 to 1309
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pclass 418 non-null int64
1 Name 418 non-null object
2 Sex 418 non-null object
3 Age 332 non-null float64
4 SibSp 418 non-null int64
5 Parch 418 non-null int64
6 Ticket 418 non-null object
7 Fare 417 non-null float64
8 Cabin 91 non-null object
9 Embarked 418 non-null object
dtypes: float64(2), int64(3), object(5)
memory usage: 35.9+ KBtrain.hist(figsize=(12, 7), bins=50);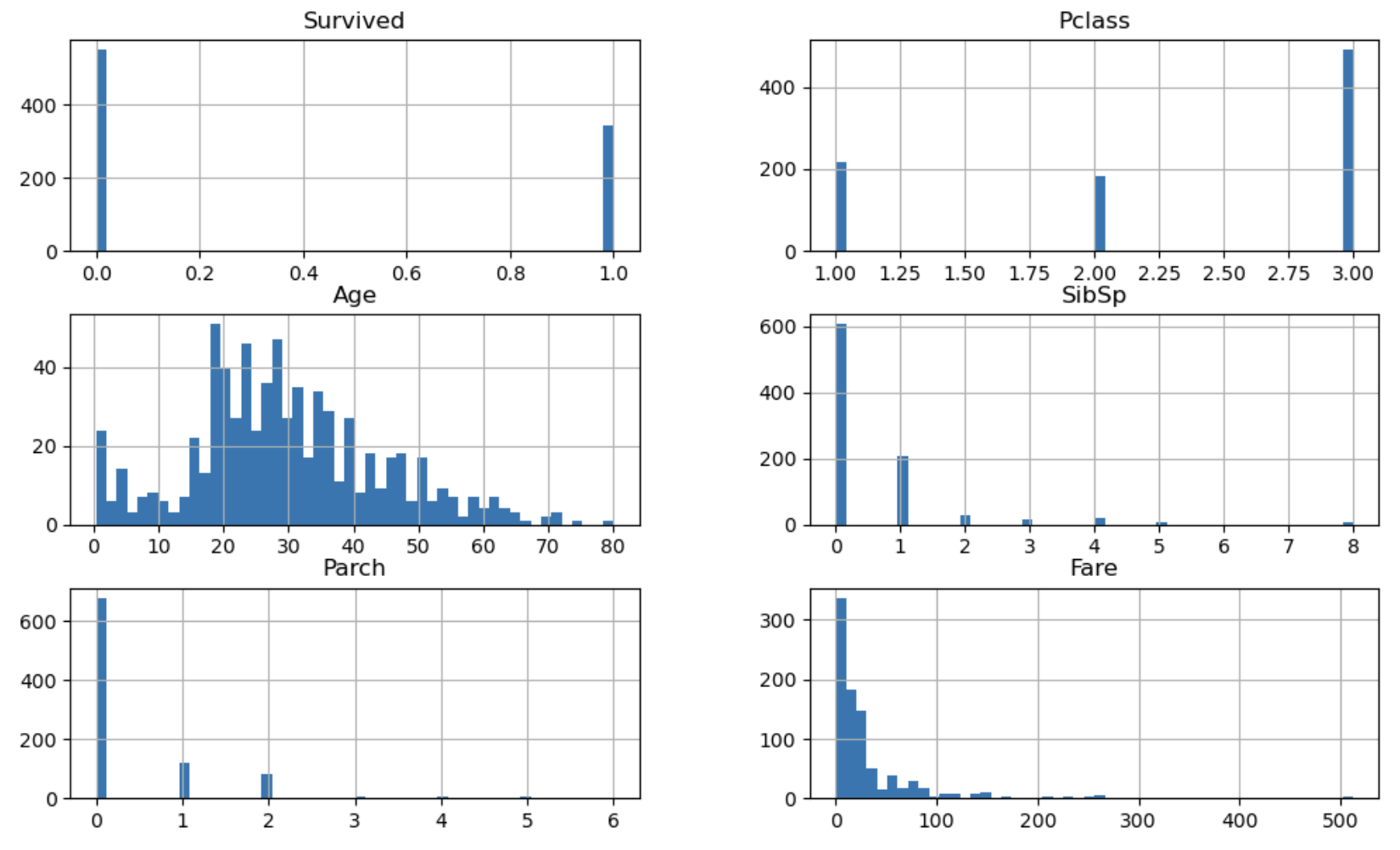
test.hist(figsize=(12, 7), bins=50)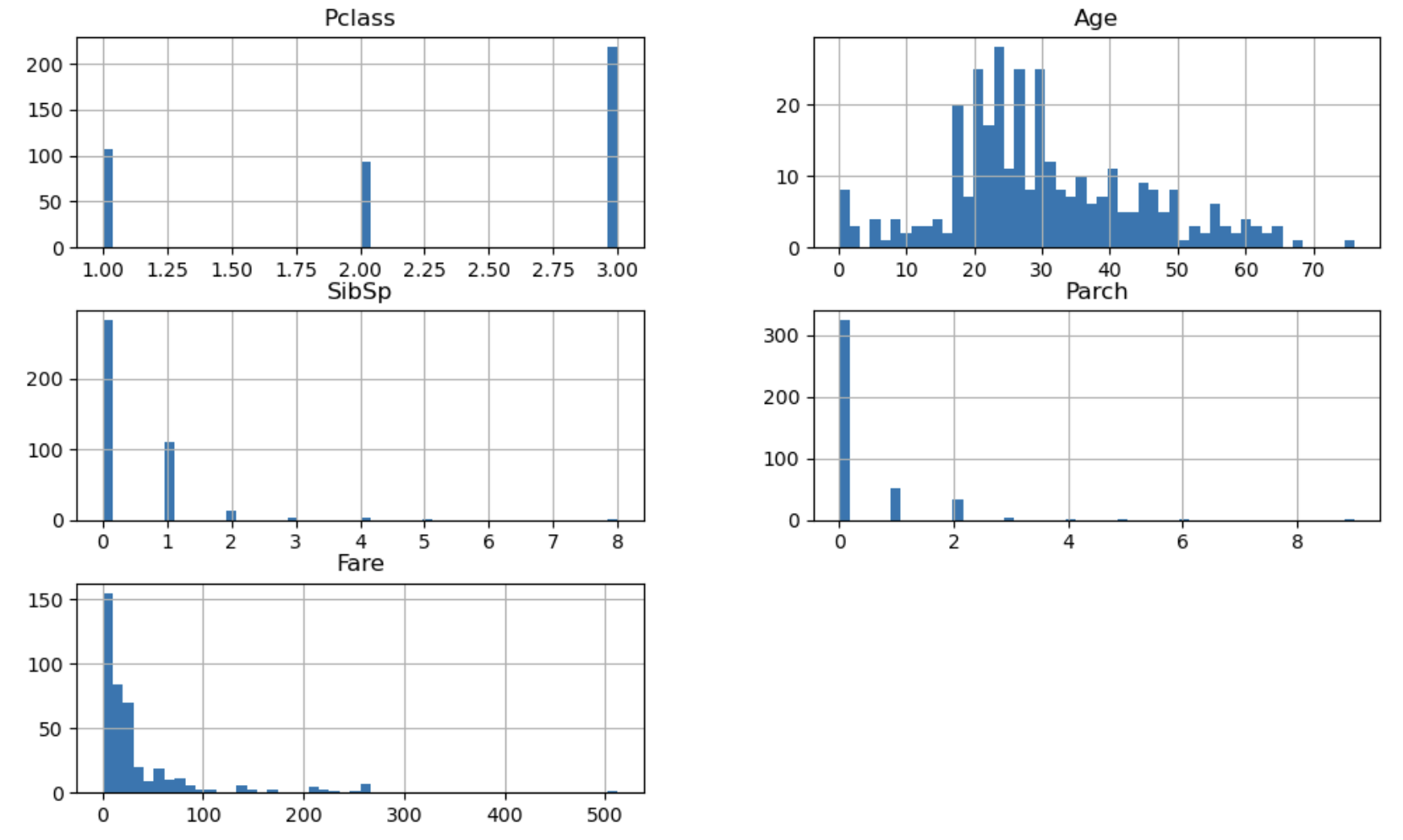
파생변수 만들기
가족의 수
# 가족의 수 == Parch + SibSp + 1(나)
train["FamilySize"] = train['Parch'] + train['SibSp'] + 1
test["FamilySize"] = test['Parch'] + test['SibSp'] + 1
display(train[["FamilySize", "Parch", "SibSp"]].sample(3))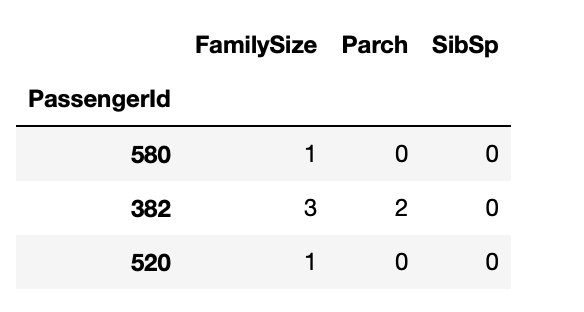
성별
train["Gender"] = train["Sex"] == "female"
test["Gender"] = test["Sex"] == "female"호칭
# Mr. , Miss.
train["Title"] = train["Name"].map(lambda x : x.split(".")[0].split(",")[-1].strip())
test["Title"] = test["Name"].map(lambda x : x.split(".")[0].split(",")[-1].strip())
train[["Name", "Title"]].head(3)
title_count = test['Title'].value_counts()
title_count
Mr 240
Miss 78
Mrs 72
Master 21
Col 2
Rev 2
Ms 1
Dr 1
Dona 1
Name: Title, dtype: int64
# train 에만 있는 호칭
set(train["Title"].unique()) - set(test["Title"].unique())
{'Capt',
'Don',
'Jonkheer',
'Lady',
'Major',
'Mlle',
'Mme',
'Sir',
'the Countess'}
#test 에만 있는 호칭
set(test["Title"].unique()) - set(train["Title"].unique())
{'Dona'}
# 호칭 기타 처리
title_count = train["Title"].value_counts()
title_not_etc = title_count[title_count > 2].index
title_not_etc
Index(['Mr', 'Miss', 'Mrs', 'Master', 'Dr', 'Rev'], dtype='object')train["TitleEtc"] = train["Title"]
train.loc[~train["Title"].isin(title_not_etc), "TitleEtc"] = "Etc"
print(train["TitleEtc"].nunique())
train["TitleEtc"].value_counts()
=>
7
Mr 517
Miss 182
Mrs 125
Master 40
Etc 14
Dr 7
Rev 6
Name: TitleEtc, dtype: int64test["TitleEtc"] = test['Title']
test.loc[~test["Title"].isin(title_not_etc), "TitleEtc"] = "Etc"
print(test["TitleEtc"].nunique())
test['TitleEtc'].value_counts()
=>
7
Mr 240
Miss 78
Mrs 72
Master 21
Etc 4
Rev 2
Dr 1
Name: TitleEtc, dtype: int64Cabin
train["Cabin_initial"] = train["Cabin"].str[0]
train["Cabin_initial"] = train["Cabin_initial"].fillna("N")
train["Cabin_initial"].value_counts()
N 687
C 59
B 47
D 33
E 32
A 15
F 13
G 4
T 1
Name: Cabin_initial, dtype: int64
# 객실번호 T의 개수 1 -> 다른 값으로 대체 필요
# 객실번호 T 요금과 유사한 객실로 대체하기 위한 전처리 작업
train.groupby('Cabin_initial')['Fare'].mean()
Cabin_initial
A 39.623887
B 113.505764
C 100.151341
D 57.244576
E 46.026694
F 18.696792
G 13.581250
N 19.157325
T 35.500000
Name: Fare, dtype: float64=> T 요금과 유사한 객실번호인 A로 대체
train['Cabin_initial'] = train['Cabin_initial'].replace("T", "A")
train['Cabin_initial'].unique()
=>
array(['N', 'C', 'E', 'G', 'D', 'A', 'B', 'F'], dtype=object)
train["Cabin_initial"].value_counts()
N 687
C 59
B 47
D 33
E 32
A 16
F 13
G 4
Name: Cabin_initial, dtype: int64# test 데이터도 전처리
test["Cabin_initial"] = test["Cabin"].str[0]
test["Cabin_initial"] = test["Cabin_initial"].fillna("N")
test["Cabin_initial"].value_counts()
N 327
C 35
B 18
D 13
E 9
F 8
A 7
G 1
Name: Cabin_initial, dtype: int64# nunique 유일값의 수가 같은지 비교
print(train['Cabin_initial'].nunique(), test["Cabin_initial"].nunique())
8 8
# train, test의 다른 값이 있는지 확인하기 위해
# train에만 있는 값이 있는지 확인
set(train['Cabin_initial'].unique()) - set(test["Cabin_initial"].unique())
set()Feature Engineering
One-Hot-Encoding
: categorical feature을 다른 bool 타입의 변수(0 or 1)로 대체하여 해당 컬럼에 대해
특정 레이블이 참인지 여부를 나타낸다.
- pandas : one-hot-encoding을 get_dummies 메서드로 지원
- sklearn : OneHotEncoder 객체로 지원
- pandas의 get_dummies 사용하면 trian, test 전처리를 하기 때문에 feature의 수, 종류가 다를 수 있다.
- sklearn OneHotEncoder 사용하면 train 데이터에만 있는 카테고리도 test데이터에 적용해줄 수 있다.
장점 : 해당 feature의 모든 정보를 유지
단점 : 해당 feature의 너무 많은 고유값이 있는 경우 feature을 지나치게 많이 사용된다.
# Ordinal-Encoding : S, C, Q -> 0, 1, 2 로 만들기 가능
# 순서가 있는 데이터(수치형 데이터) -> Ordinal-Encoding을 사용
# 만약 순서가 없는 데이터인데 Ordinal-Encoding을 사용하면 의도치 않은 연산이 될 가능성있음
# 순서가 없는 데이터(범주형 데이터) -> One-Hot-Encoding
# Pandas 사용하는 이유 : 수치형 데이터와 범주형 데이터 함께 넣어줌
# -> 수치 데이터는 그대로 두고 범주형 데이터만 인코딩 해줌
pd.get_dummies(train[["Fare", "Age", "Sex", "Embarked", "Cabin_initial"]])
결측치 대체
- 결측치가 있으면 머신러닝 알고리즘 내부에서 연산 불가능, 오류발생
- sklearn 에서 결측치 대체 해야한다.
train["Age_fill"] = train["Age"].fillna(train["Age"].median())
test["Age_fill"] = test["Age"].fillna(test['Age'].median())
# train에는 Fare값의 결측치가 없지만 test에 결측치가 존재함
# 새로운 변수를 만들어 채우고자 한다면, train에도 test와 동일한 변수 생성해야함
train["Fare_fill"] = train["Fare"]
test["Fare_fill"] = test['Fare'].fillna(test["Fare"].median())학습과 예측 과정
정답값(예측해야 될 값)
label_name = "Survived"학습, 예측 컬럼
train.columns
Index(['Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket',
'Fare', 'Cabin', 'Embarked', 'FamilySize', 'Gender', 'Title',
'TitleEtc', 'Cabin_initial', 'Embarked_S', 'Embarked_C', 'Embarked_Q',
'Age_fill', 'Fare_fill'],
dtype='object')
feature_names = ['Pclass', 'Gender', 'Embarked',
'TitleEtc', 'Cabin_initial', 'Age_fill', 'Fare_fill']
train[feature_names].head(2)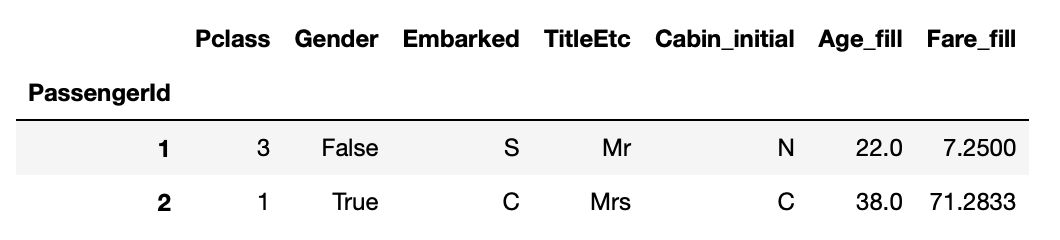
학습, 예측 데이터셋
X_train = pd.get_dummies(train[feature_names])
print(X_train.shape)
X_train.head(2)
(891, 22)
X_test = pd.get_dummies(test[feature_names])
print(X_test.shape)
X_test.head(2)
(418, 22)
# y_train : label_name 에 해당 되는 컬럼만 train에서 가져온다
y_train = train[label_name]
print(y_train.shape)
y_train.head(2)
(891,)
PassengerId
1 0
2 1
Name: Survived, dtype: int64머신러닝 알고리즘
DecisionTree
- 수치 자료, 범주 자료 모두 적용 가능하다.
- 안정적, 해당 모델의 추리 기반이 되는 명제가 손상되었을지라도 잘 동작한다.
- 대규모의 데이터셋에서도 잘 동작한다.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=5, max_features = 0.9, random_state=42)Cross validate
- cross_validate : Evaluate metric(s) by cross-validation and also record fit/score times.
- cross_val_score : Evaluate a score by cross-validation.
- cross_val_predict : Generate cross-validated estimates for each input data point.
from sklearn.model_selection import cross_validate, cross_val_score, cross_val_predict
# 실행, 점수 계산 시간, 점수가 나옴
pd.DataFrame(cross_validate(model, X_train, y_train, cv=5))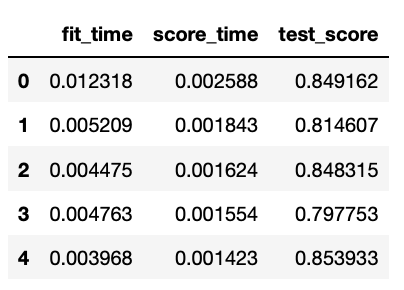
# cv 조각별 스코어
cross_val_score(model, X_train, y_train).mean()
0.8327537505492437
y_valid_pred = cross_val_predict(model, X_train, y_train)Accuracy
valid_accuracy = (y_train == y_valid_pred).mean()
valid_accuracy
0.8327721661054994학습(훈련)
model.fit(X_train, y_train)
DecisionTreeClassifier(max_depth=5, max_features=0.9, random_state=42)
# feature의 중요도 구하기
model.feature_importances_
array([0.130983 , 0.02352634, 0.0592672 , 0.16427973, 0.00156775,
0. , 0. , 0. , 0. , 0.02255705,
0. , 0.53690565, 0. , 0.04056031, 0. ,
0. , 0. , 0.0070138 , 0.00271707, 0. ,
0. , 0.0106221 ])
sns.barplot(x=model.feature_importances_, y=model.feature_names_in_)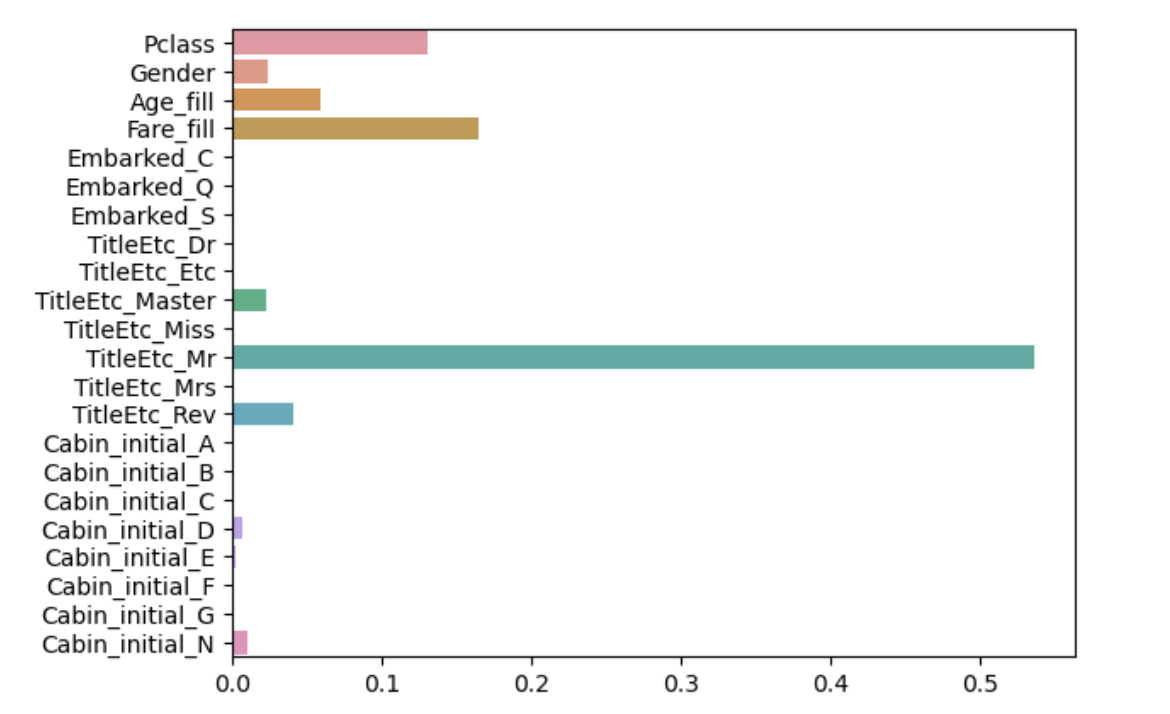
예측
y_predict = model.predict(X_test)Kaggle 제출
submit = pd.read_csv('data/titanic/gender_submission.csv', index_col="PassengerId")
submit["Survived"] = y_predict
# kaggle에 제출할 파일명
# cross validation으로 측정한 train set에 대한 검증 점수를 함께 기입
file_name = f"data/titanic/submit_{valid_accuracy:.5f}.csv"
file_name
=>
'data/titanic/submit_0.83277.csv'
submit.to_csv(file_name)

Ⓓ🅰️🅣🄰 ♡♥︎