
활용 데이터
https://dacon.io/competitions/official/235745/overview/description
Data info
🏠 유형별 임대주택 설계 시 단지 내 적정 🅿️ 주차 수요를 예측
df_train.shape, df_test.shape, df_info.shape,
((2952, 15), (1022, 14), (16, 23))
# Train / Test Split 시 shape 예시
X_train.shape
(423, 23)
X_test.shape
(150, 23)
y_train.shape
(423,)
Feature Engineering
- 임대보증금 & 임대료
train.loc[train.임대보증금=='-', '임대보증금'] = np.nan
test.loc[test.임대보증금=='-', '임대보증금'] = np.nan
train['임대보증금'] = train['임대보증금'].astype(float)
test['임대보증금'] = test['임대보증금'].astype(float)
train.loc[train.임대료=='-', '임대료'] = np.nan
test.loc[test.임대료=='-', '임대료'] = np.nan
train['임대료'] = train['임대료'].astype(float)
test['임대료'] = test['임대료'].astype(float)
train[train.임대보증금.isnull()].공급유형.value_counts()
test[test.임대보증금.isnull()].공급유형.value_counts()
train[train.임대보증금.isnull()].자격유형.value_counts()
test[test.임대보증금.isnull()].자격유형.value_counts()
# 임대보증금과 임대료가 NULL인 경우는 0으로 대체
train[['임대보증금', '임대료']] = train[['임대보증금', '임대료']].fillna(0)
test[['임대보증금', '임대료']] = test[['임대보증금', '임대료']].fillna(0)- **도보 10분거리 내 지하철역 수 & 버스정류장 수**
subway_null_codes = train[train['도보 10분거리 내 지하철역 수(환승노선 수 반영)'].isnull()].단지코드.unique()
train.loc[train.단지코드.isin(subway_null_codes), '도보 10분거리 내 지하철역 수(환승노선 수 반영)'].value_counts(dropna=False)
bus_null_codes = train[train['도보 10분거리 내 버스정류장 수'].isnull()].단지코드.unique()
train.loc[train.단지코드.isin(bus_null_codes), '도보 10분거리 내 버스정류장 수'].value_counts(dropna=False)
cols = ['도보 10분거리 내 지하철역 수(환승노선 수 반영)', '도보 10분거리 내 버스정류장 수']
train[cols] = train[cols].fillna(0)
test[cols] = test[cols].fillna(0)- 자격유형
test[test.단지코드=='C2411']
test.loc[test.단지코드.isin(['C2411']) & test.자격유형.isnull(), '자격유형'] = 'A'
# 임대보증금과 임대료가 존재하는 경우 자격유형 C로 채우기
test.loc[test.단지코드.isin(['C2253']) & test.자격유형.isnull(), '자격유형'] = 'C'- 중복확인
train.shape, train.drop_duplicates().shape
test.shape, test.drop_duplicates().shape
train = train.drop_duplicates()
test = test.drop_duplicates()
train[train.단지코드=='C2483']
train.groupby(['단지코드']).nunique(dropna=False).sum(axis=0)- 임대건물구분, 공급유형, 전용면적, 전용면적별세대수, 자격유형, 임대보증금, 임대료는 하나의 단지코드에 대해 둘 이상의 항목 존재 ➡️ 각 항목들을 변수로 만들어 사용- 단지코드
train.groupby(['단지코드']).nunique(dropna=False).sum(axis=0)
총세대수 423
임대건물구분 456
지역 423
공급유형 488
전용면적 1898
전용면적별세대수 2230
공가수 423
자격유형 510
임대보증금 1277
임대료 1289
도보 10분거리 내 지하철역 수(환승노선 수 반영) 423
도보 10분거리 내 버스정류장 수 423
단지내주차면수 423
등록차량수 423
dtype: int64- 하나의 단지코드에 하나의 값만 존재하는 변수
# 총세대수, 지역, 공가수, 도보 10분거리 내 지하철역 수, 도보 10분거리 내 버스정류장 수, 단지내주차면수, 등록차량수
unique_cols = ['총세대수', '지역', '공가수',
'도보 10분거리 내 지하철역 수(환승노선 수 반영)',
'도보 10분거리 내 버스정류장 수',
'단지내주차면수', '등록차량수']
train_agg = train.set_index('단지코드')[unique_cols].drop_duplicates()
test_agg = test.set_index('단지코드')[[col for col in unique_cols if col!='등록차량수']].drop_duplicates()- 하나의 단지코드에 둘 이상의 값이 존재하는 변수들
# 임대건물구분, 공급유형, 전용면적, 전용면적별세대수, 자격유형, 임대보증금, 임대료
def reshape_cat_features(data, cast_col, value_col):
res = data.drop_duplicates(['단지코드', cast_col]).assign(counter=1).pivot(index='단지코드', columns=cast_col, values=value_col).fillna(0)
res.columns.name = None
res = res.rename(columns={col:cast_col+'_'+col for col in res.columns})
return res- 공급유형
pd.concat([train.공급유형.value_counts(), test.공급유형.value_counts()], axis=1) 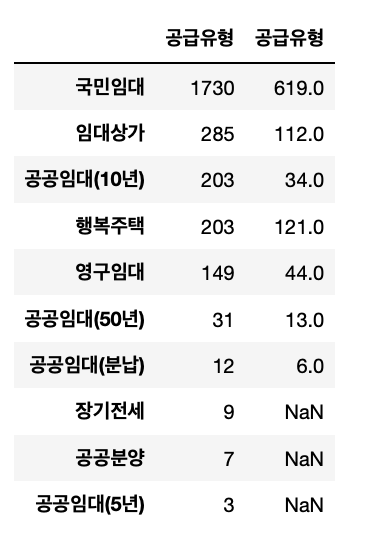
train.loc[train.공급유형.isin(['공공임대(5년)', '공공분양', '공공임대(10년)', '공공임대(분납)']), '공급유형'] = '공공임대(5년/10년/분납/분양)'
test.loc[test.공급유형.isin(['공공임대(5년)', '공공분양', '공공임대(10년)', '공공임대(분납)']), '공급유형'] = '공공임대(5년/10년/분납/분양)'
train.loc[train.공급유형.isin(['장기전세', '국민임대']), '공급유형'] = '국민임대/장기전세'
test.loc[test.공급유형.isin(['장기전세', '국민임대']), '공급유형'] = '국민임대/장기전세'- 자격유형
pd.concat([train.자격유형.value_counts(), test.자격유형.value_counts()], axis=1)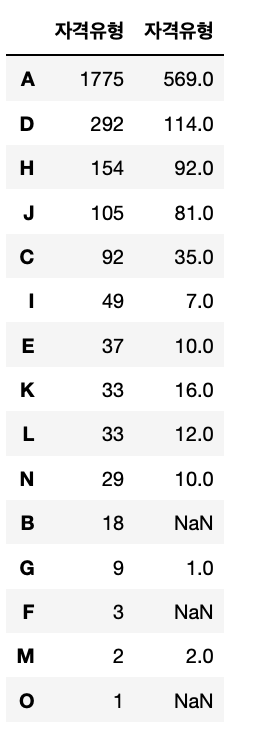
• B, F, O 가 train에만 존재하고 test에는 존재 X
train.loc[train.자격유형=="B", ['임대건물구분', '공급유형']].drop_duplicates()
train.loc[train.공급유형.isin(['국민임대/장기전세']), '자격유형'].value_counts()
train.loc[train.공급유형.isin(['영구임대']), '자격유형'].value_counts()
train.loc[train.공급유형.isin(['공공임대(5년/10년/분납/분양)']), '자격유형'].value_counts()
train.loc[train.공급유형.isin(['행복주택']), '자격유형'].value_counts()
# # 'J', 'L', 'K', 'N', 'M', 'O' 는 공급유형이 행복주택인 경우에서만 나타남
train.loc[train.자격유형.isin(['J', 'L', 'K', 'N', 'M', 'O']), '공급유형'].value_counts()
test.loc[test.자격유형.isin(['J', 'L', 'K', 'N', 'M', 'O']), '공급유형'].value_counts()
train.loc[train.자격유형.isin(['J', 'L', 'K', 'N', 'M', 'O']), '자격유형'] = '행복주택_공급대상'
test.loc[test.자격유형.isin(['J', 'L', 'K', 'N', 'M', 'O']), '자격유형'] = '행복주택_공급대상'
train.loc[train.자격유형.isin(['A']), '공급유형'].value_counts()
train.loc[train.자격유형.isin(['D']), '공급유형'].value_counts()
train.loc[train.자격유형.isin(['H']), '공급유형'].value_counts()
train.loc[train.자격유형.isin(['C']), '공급유형'].value_counts()
train.loc[train.자격유형.isin(['I']), '공급유형'].value_counts()
train.loc[train.자격유형.isin(['E']), '공급유형'].value_counts()
train.loc[train.자격유형.isin(['B']), '공급유형'].value_counts()
train.loc[train.자격유형.isin(['G']), '공급유형'].value_counts()
train.loc[train.자격유형.isin(['F']), '공급유형'].value_counts()- 'H', 'B', 'E', 'G' 는 국민임대/장기전세 공급대상
- 'C', 'I', 'F', 'G' 는 영구임대 공급대상
train.loc[train.자격유형.isin(['H', 'B', 'E', 'G']), '자격유형'] = '국민임대/장기전세_공급대상'
test.loc[test.자격유형.isin(['H', 'B', 'E', 'G']), '자격유형'] = '국민임대/장기전세_공급대상'
train.loc[train.자격유형.isin(['C', 'I', 'F']), '자격유형'] = '영구임대_공급대상'
test.loc[test.자격유형.isin(['C', 'I', 'F']), '자격유형'] = '영구임대_공급대상'
pd.concat([train.자격유형.value_counts(), test.자격유형.value_counts()], axis=1)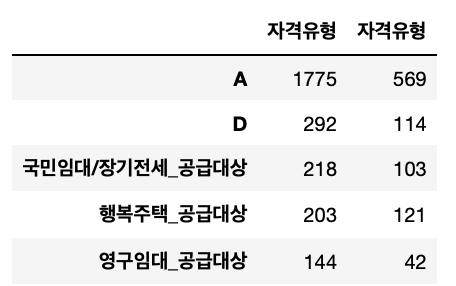
- Encoding
encoding_features = ['지역', '도보 10분거리 내 지하철역 수(환승노선 수 반영)']
for f in encoding_features:
mapping = train_agg.groupby([f])['등록차량수'].agg(['mean','median','std'])
mapping_values = []
for l in train_agg[f].values:
mapping_values.extend([mapping.loc[l].values])
bincount = pd.DataFrame(mapping_values, columns = [f+'_mean', f+'_median', f+'_std', ], index = train_agg.index)
train_agg = pd.concat([train_agg,bincount], axis= 1).drop(columns = [f])
mapping_values = []
for l in test_agg[f].values:
mapping_values.extend([mapping.loc[l].values])
bincount = pd.DataFrame(mapping_values, columns = [f+'_mean', f+'_median', f+'_std', ], index = test_agg.index)
test_agg = pd.concat([test_agg,bincount], axis= 1).drop(columns = [f])- Scaling
scailing_features = ['총세대수',
'공가수',
'도보 10분거리 내 버스정류장 수',
'단지내주차면수',
'지역_mean',
'지역_median',
'지역_std',
'도보 10분거리 내 지하철역 수(환승노선 수 반영)_mean',
'도보 10분거리 내 지하철역 수(환승노선 수 반영)_median',
'도보 10분거리 내 지하철역 수(환승노선 수 반영)_std'
]
scaler = RobustScaler()
loc_f = [ '지역_mean',
'지역_median',
'지역_std', ]
train_agg.loc[:, loc_f] = scaler.fit_transform(train_agg[loc_f])
test_agg.loc[:, loc_f] = scaler.transform(test_agg[loc_f]) scailing_features = ['총세대수',
'공가수',
'도보 10분거리 내 버스정류장 수',
'단지내주차면수',
'도보 10분거리 내 지하철역 수(환승노선 수 반영)_mean',
'도보 10분거리 내 지하철역 수(환승노선 수 반영)_median',
]
scaler = StandardScaler()
train_agg.loc[:, scailing_features] = scaler.fit_transform(train_agg[scailing_features])
test_agg.loc[:, scailing_features] = scaler.transform(test_agg[scailing_features]- Xgboost
import xgboost as xgb
xgb_model = xgb.XGBRegressor(max_depth=17, gamma=0.5, learning_rate= 0.1)- RandomizedSearchCV
param_distributions = {"max_depth" : np.random.randint(1, 100, 10)}
reg = RandomizedSearchCV(xgb_model, param_distributions=param_distributions,
n_iter=20, cv=5,
verbose=2, n_jobs=-1,
random_state=42
)- Cross-Validation
from sklearn.model_selection import cross_val_predict
y_valid_pred = cross_val_predict(xgb_model, X_train, y_train,
cv=5, n_jobs=-1, verbose=2)- MAE
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_train, y_valid_pred)
- submission


Ⓓ🅰️🅣🄰 ♡♥︎