Ensemble Learning
-
대중의 지혜(집단지성)
- 무작위로 선택된 수천 명의 사람에게 복잡한 질문을 하고 대답을 모은다고 가정
- 많은 경우 이렇게 모은 답이 한 명의 전문가의 답보다 좋은 경우들이 많음
-
일련의 분류나 회귀 모델로부터 예측을 수집하면 가장 좋은 모델 하나 보다 더 좋은 예측 성능을 얻을 수 있음
➡️ 앙상블 학습 -
일반적으로 다양한 Machine Learning 기법들을 Ensemble 시켜주면 성능이 향상되는 효과를 얻을 수 있음
-
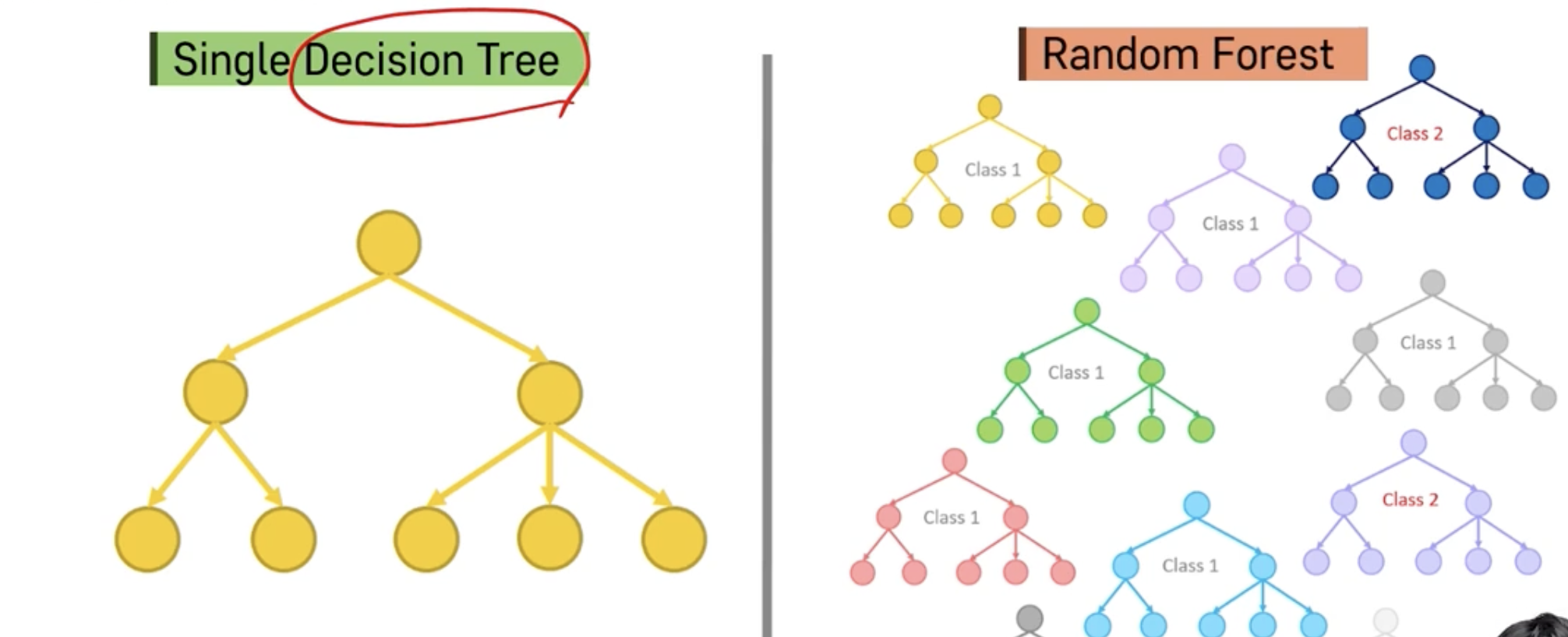
Random Forest는 Decision Tree의 Ensemble을 의미하고, 일반적으로 굉장히 Robust하고 좋은 예측 성능을 보이는 것으로 알려져 있음
RandomForest
투표 기반 분류기
- 정확도가 80%인 분류기 여러 개를 훈련시켰다고 가정
Weak Learner & Strong Learner
- 다수결 투표 분류기는 앙상블에 포함된 개별 분류기 중 가장 뛰어난 것보다도 정확도가 높을 경우가 많음
- 각 분류기가 약한 학습기(랜덤 추측보다 낮은 성능을 내는 분류기)일지라도 충분하게 많고 다양하다면 앙상블은 강한 학습기가 될 수 있음

- 동전을 던졌을 때 앞면이 51%, 뒷면이 49%가 나오는 조금 균형이 맞지 않는 동전이 있다고 가정
➡️ 앞면이 정답인 상황에서 동전은 일종의 분류기 - 이 동전을 1000번 던진다면 대략 510번은 앞면, 490번은 뒷면이 나올 것, 다수는 앞면이 됨
- 수학적으로 계산해보면 1000번을 던진 후 앞면이 다수가 될 확률은 75%에 가까움
(이항 분포 가정하고 계산) - 더 많이 던질 수록 확률은 증가
➡️ 큰 수의 법칙
- 51% 정확도를 가진 1000개의 분류기로 앙상블 모델을 구축한다 가정
- 가장 많은 클래스를 예측으로 삼는다면 75%의 정확도를 기대할 수 있지만 여기에는 중요한 가정이 있음
- 모든 분류기가 완벽하게 독립적이고 오차에 상관관계가 없다는 가정이 있어야 함
- 같은 데이터로 훈련시키다 보면 이런 가정이 맞지 않은 경우가 많고, 분류기들이 같은 종류의 오차를 만들기 쉬워서 실제 앙상블 정확도는 이론 정확도에 비해 낮아짐
➡️ 다양한 Machine Learning 방법에 손쉽게 적용 가능
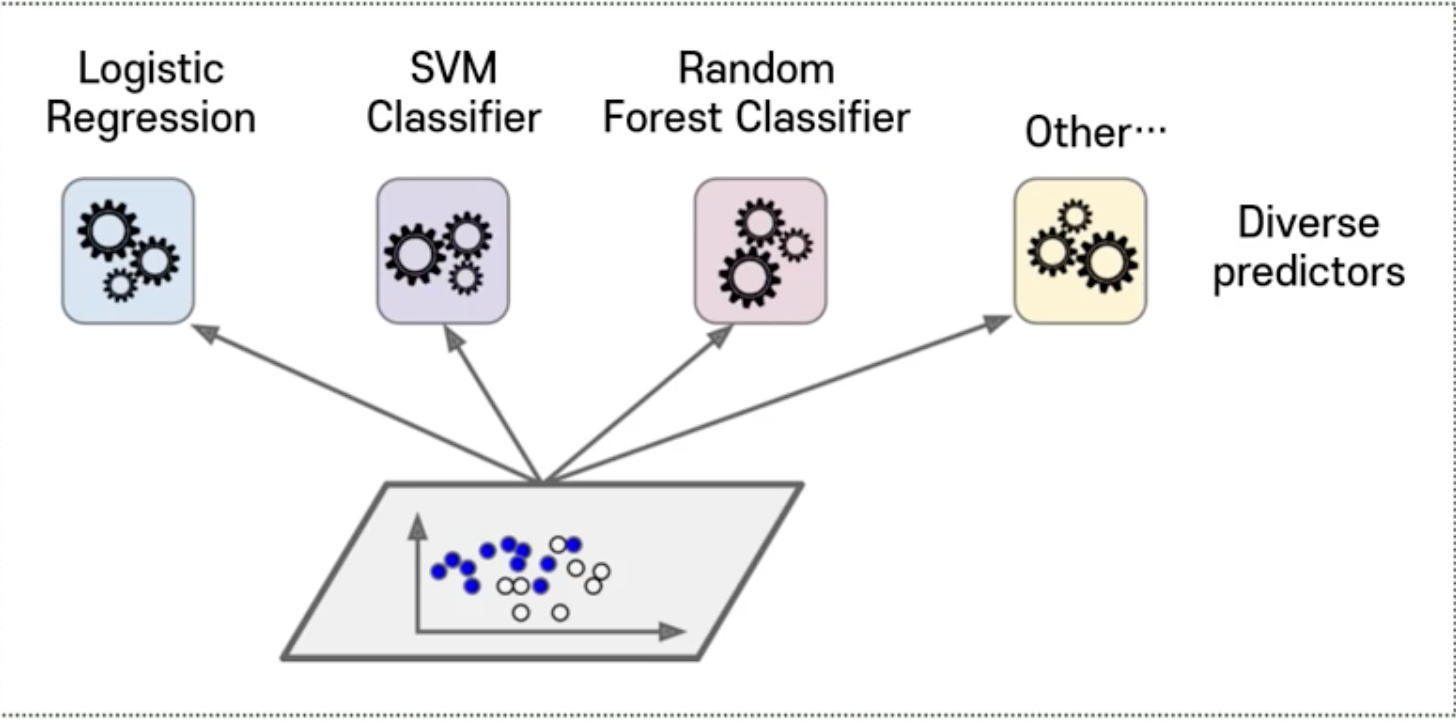
- Ensemble 할 때 다양한 분류기를 만드는 것이 중요
➡️ 첫 번째 방법 : 각기 다른 훈련 알고리즘 사용
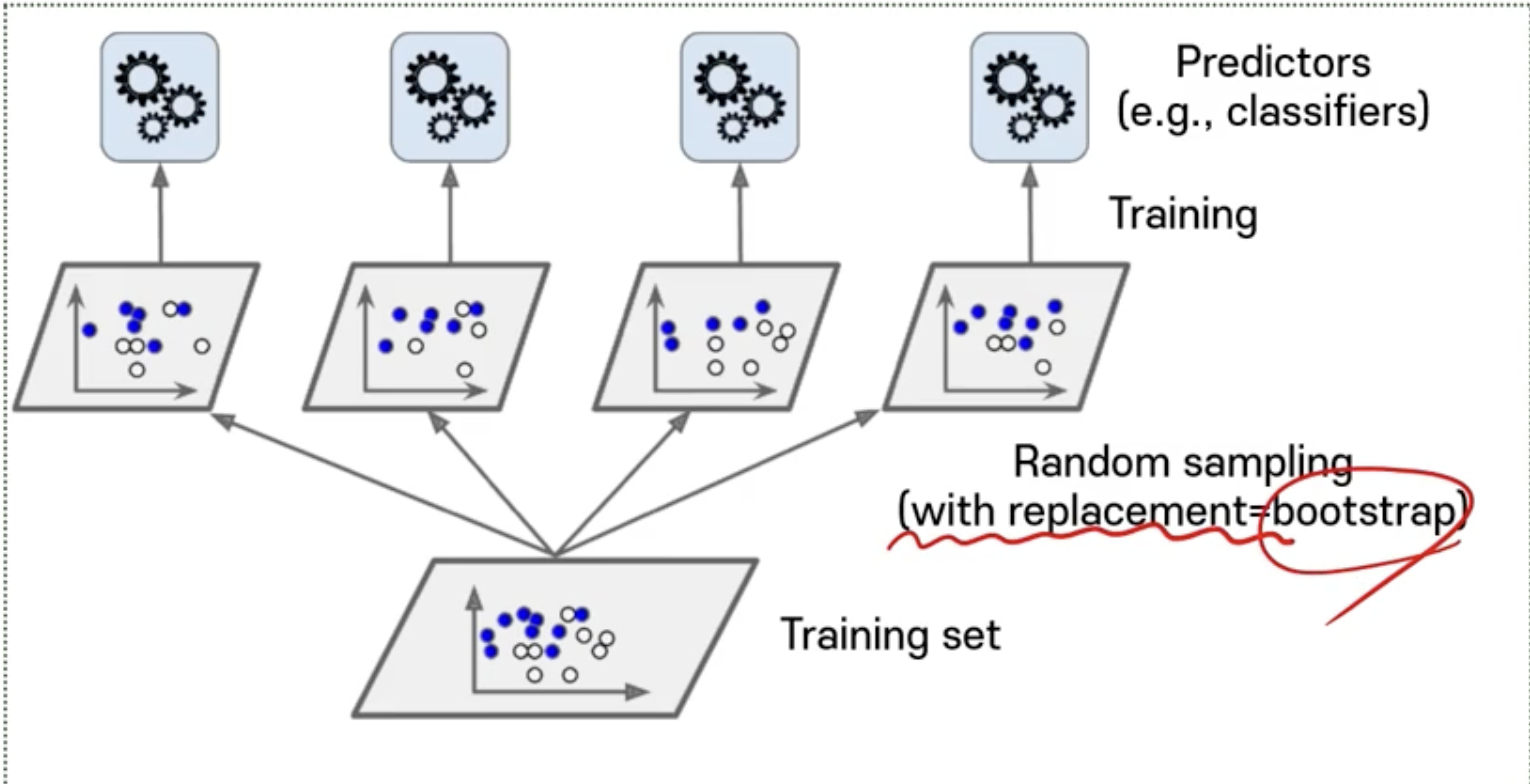
➡️ 두 번째 방법 : Training 데이터의 Subset을 무작위로 구성하여 분류기를 각기 다르게 학습시키는 방법
- Bagging (Bootstrap aggregating)
: Training 데이터에서 중복을 허용하여 샘플링하는 방식 (복원 추출) - Pasting
: 중복을 허용하지 않고 샘플링 하는 방식 (비복원 추출)
Bagging & Pasting
Out-of-Bag 평가
- Bagging을 이용하면 어떤 샘플은 한 예측기를 위해 여러 번 샘플링 되고 어떤 것은 전혀 선택되지 않을 수 있음
- m개의 Training 데이터에서 m개의 데이터를 중복을 허용해서 샘플링
- m개의 데이터 중 하나를 선택할 때 선택되지 않을 확률 1-(1/m)
- 여기서 이를 m번 반복했을 때 한 번도 선택되지 않을 확률 (1-(1/m)) ** m 이 때 m이 무한대가 되면 e ** -1 = 0.368로 수렴
- 즉 한 번도 뽑히지 않는 관측치가 37% 가까이 될 수 있음
- 예측기가 훈련되는 동안에 학습에 반영되지 않는 샘플은 OOB 샘플이라고 정의
- 앙상블의 평가는 각 에측기의 OOB 평가를 평균해서 얻을 수 있음
- 일종의 검증 데이터 역할을 하는 것
RandomForest
: 변수 중요도를 각각의 Tree에서 순수도를 높인 결과를 종합한 기준으로 계산할 수 있음
reference : K-MOOC 실습으로 배우는 머신러닝

Ⓓ🅰️🅣🄰 ♡♥︎