
하둡이란?
- 그냥 저장소라고 생각하면 된다.
- 적은 비용으로 빠르게 분석 할 수 있는 소프트웨어로 자바 소프트웨어 프레임워크
- 범용 하드웨어로 구축된 컴퓨터 클러스터의 방대한 데이터 세트를 분산해 저장하고 처리하는 오픈 소스 소프트웨어 플랫폼이다. 하둡은 Apache Software Foundation에서 개발된 분산 컴퓨팅 시스템으로, 수천 대 이상의 컴퓨터 클러스터를 활용하여 대용량 데이터를 효율적으로 저장하고 처리할 수 있다.
- 현재 하둡 이외의 다양한 대규모 데이터 처리 기술과 플랫폼들이 나와있기 때문에 하둡의 파이가 줄어드는 추세이다. (하지만 아직은 하둡의 파이가 큰편이다.)
하둡의 핵심
- 장애 허용 (fault tolence)
- 확장성을 높이기 위해 장애를 당연히 발생할 수 있는 일로 간주
- 기반 소프트웨어 시스템이 실패한 작업을 책임지고 재시도하게 설계
- 다소 불안정하지만 저렴한 하드웨어로도 매우 안정적인 시스템 구성이 가능하다.
- 분산 파일 시스템
- 리소스 관리자와 스케줄러
- 분산 데이터 처리 프레임 워크
하둡 에코 시스템
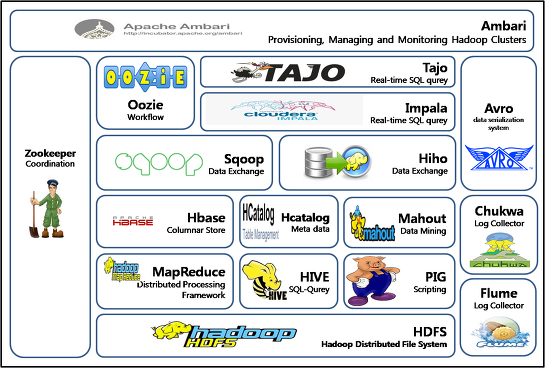
출처: https://1004jonghee.tistory.com/m/entry/1004jonghee-하둡에코시스템Hadoop-Eco-System-Ver-10?category=419383
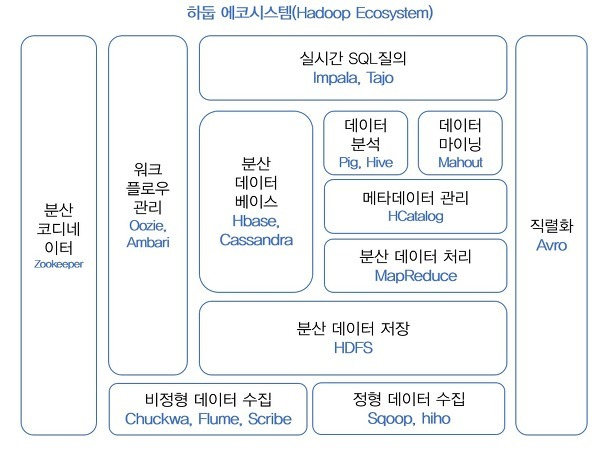
출처 : 시작하세요! 하둡 프로그래밍(위키북스)
하둡의 코어 프로젝트
- HDFS 분산데이터 저장
- MapReduce 분산 처리
하둡의 서브 프로젝트
- 나머지 프로젝트들
- 워크플로우 관리
- 데이터 마이닝
- 분석
- 수집
- 직렬화 등
Yarn
- 하둡 클러스터 내의 리소스를 관리하는 역할
- Resource Manager, Node Manager, Application - Master라는 세 가지 주요 구성 요소
- Resource Manager는 클러스터 전체의 리소스를 관리
- Node Manager는 개별 노드의 리소스를 관리
- Application Master는 각 애플리케이션의 실행을 관리
Pig
- 하둡 에코시스템 중에서 데이터를 모델링하고 프로세싱하는 경우 가장 많이 사용하는 데이터 웨어하우징용 솔루션
- Pig는 스크립트 언어를 기반으로 하여 ETL 작업을 수행
Hive
- 데이터 전처리를 위한 솔루션
- 하둡 환경에서 데이터를 SQL과 비슷한 구조로 처리할 수 있는 솔루션
- HQL(HiveQL)이라는 SQL과 비슷한 언어를 지원
- 쿼리를 작성하면 자동으로 맵리듀스 작업으로 변경돼 클러스터에서 실행
scoop
- 데이터 마이그레이션
- 하둡 내부와 외부 정형 데이터베이스 간의 효율적인 대용량 벌크 데이터 전송을 지원하는 도구
- 외부 시스템의 데이터를 HDFS로 가져와 HBase 테이블에 삽입 가능
spark
- 하둡과 비슷한 분산 시스템을 기반으로 대량의 데이터를 실시간으로 처리하는 빅데이터 처리 솔루션
- 메모리 기반으로 데이터 처리를 수행하므로 일반 하둡에 비해 빠른 속도
- Scala라는 언어를 사용해 스크립트 작성 / pyspark를 사용하기도 함.
HBASE
- 분산형 NoSQL 데이터베이스 기술
- 하둡의 HDFS와 연동하여 사용가능
Splunk
- 실시간 대용량 로그 데이터 처리 기술
- 다양한 데이터 소스로부터 데이터를 수집하고, 검색과 분석 등의 작업을 수행
아파치 이그나이트(Apache Ignite)
- 분산 데이터 관리 시스템
in-memory db(메모리에 올려서 쓰는거라 속도가 빠름) - 파티셔닝, 트랜잭션, 캐싱, 컴퓨팅 등 다양한 기능을 제공
하둡의 구성
하둡은 주로 두 가지 핵심 컴포넌트로 구성된다.
- 대용량 데이터를 여러 노드에 분산하여 저장하는 파일 시스템.
- 데이터는 여러 노드로 나뉘어 저장되며, 각 노드는 데이터의 복제본을 가지고 있어 데이터의 안정성과 내결함성을 보장한다.
Hadoop Distributed File System (HDFS)
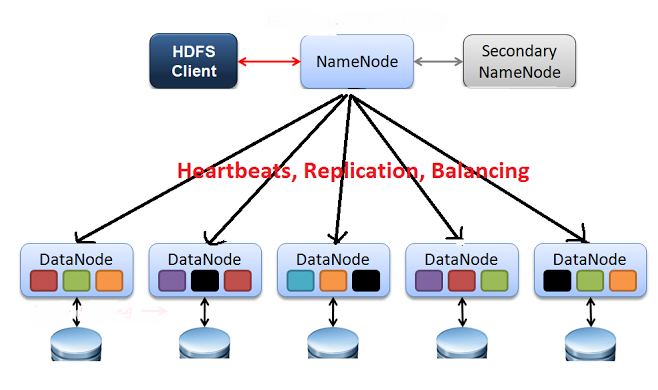
- 데이터 처리를 위한 분산 프로그래밍 모델.
- MapReduce는 데이터를 작은 조각으로 나누어 여러 노드에서 병렬로 처리하고, 결과를 다시 모아서 최종 결과를 생성한다.
- 대규모 데이터 집합을 효율적으로 분석하고 처리할 수 있다.
MapReduc

땅을 파다보면 흙과 물을 보겠지만, 코드를 파다보면 답이 보일것이다.