
영화 추천 사이트 주제로 진행한 프로젝트에서 신규 영화에 대한 정보를 가져오기 위해 사용한 airflow의 구성에 대해 설명해보고자 한다.
깃허브
크롤링
- 팀원 각자 OTT 사이트 + 알파로 크롤링을 진행하였는데, ott 정책상 셀레니움을 이용하여 가져올 수 밖에 없었다.
- 또한 새로운 데이터의 경우 서버에서 selenium으로 실행하는데 한계가 있었고,
(각 OTT별 계정을 계속 구독을 해야하는문제가..)- 따라서 영화 3사의 데이터 크롤링 + 다음 영화사이트에서의 티빙, 왓챠 신작을 크롤링을 진행했다.
1. 첫시도
- 첫 시도는 각각의 영화사이트를 크롤링, 각 사이트별 컬랙션을 생성하여 정보를 저장하려고 하였다.

2. 문제점
- 각 사이트별로 가져올 수 있는 정보의 차이가 있었기에 처음에 어떤 정보를 사용할 것인지 대략적으로 논의만 하고 진행하다보니 크롤링 코드를 다시 통일시키고 없는 정보는 "" 값으로 넣는 전처리 문제가 있었다.
- 위의 문제와 함께, 각 사이트별 같은 제목이더라도
- 각 컬랙션을 생성하였을때 이 정보를 한번에 영화 리스트에서 보여줌에 있어서 문제가 있었다.
- 컬랙션별로 django model에 정의를 해줬어야했으며, title로 따로 비교해야하는 문제였다.
- 롯데시네마.... GCP를 막아뒀다. 로컬에서 진행할때는 잘 되었는데 에어플로우를 설치한 compute engine에서 실행이 되지 않았다.
3. 개선방안
- 각 사이트별 크롤링코드를 매개변수로 할당하여 파일별로 작성하고, 새로운 키값을 추가하여 title을 정규식으로 전처리한 값을 추가하였다.
title을 비교하고 동일한 title이 있을경우 ott키 값에 value를 추가하는 방식으로 바꾸어 중복 값을 최소화 하였다.- 또한 각 이미지의 포스터를 mongodb에 적재되는 id를 기준으로 구글 스토리지에 저장하게 하였는데, 이때 중복된 영화를 줄여 2~3개로 중복저장될 것을 하나로 저장되게 하였다.
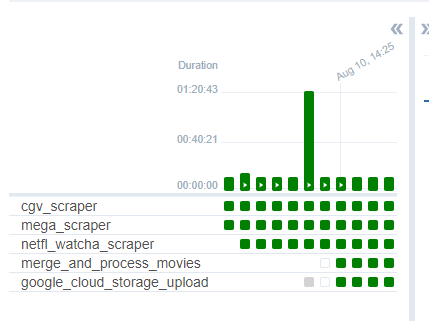
- 몽고db 적재과정에서 동시에 실행될 경우 error가 발생할 수도 있기에 각 과정을 순차적으로 진행되게 하나의 덱으로 설정하게 되었다.
- 영화 저장과정에서 새로 추가되는 데이터에 대해서만 poster를 저장하기 위해, xcom에 key를 푸쉬하고 merge_and_process_movies라는 작업을 추가하여 각 사이트에서 크롤링하여 적재한 데이터를 합치게 되었다.
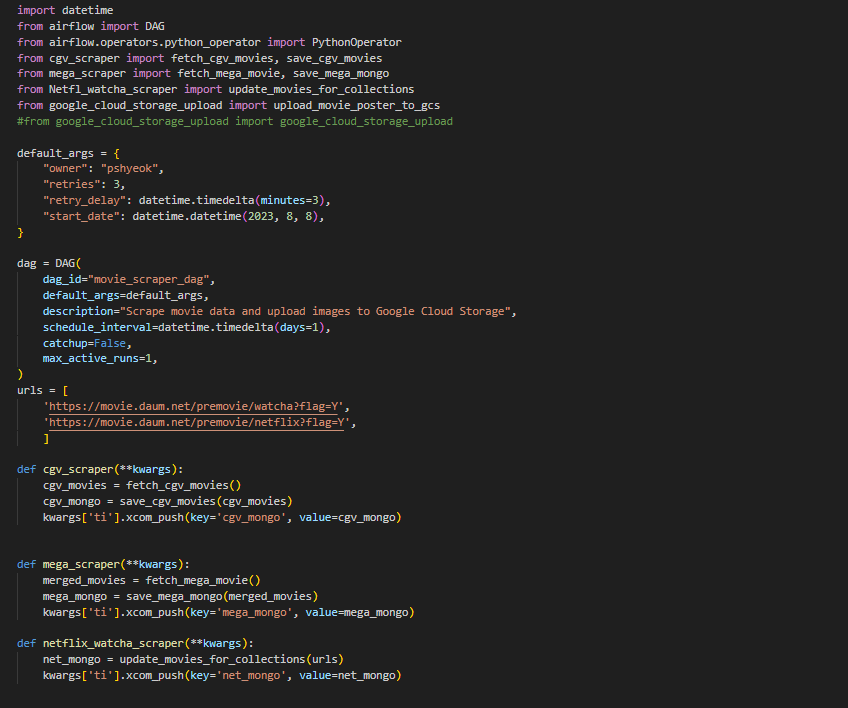
4. 개선점
- 롯데시네마 사이트 크롤링 덱을 실행하지 못하였고, 해당 정보를 빼게 되었다.
사이트 자체에서 막았을경우 어떻게 해결해야 할지에 대해 생각해보아야겠다.

땅을 파다보면 흙과 물을 보겠지만, 코드를 파다보면 답이 보일것이다.