
4-1 하둡보안규칙
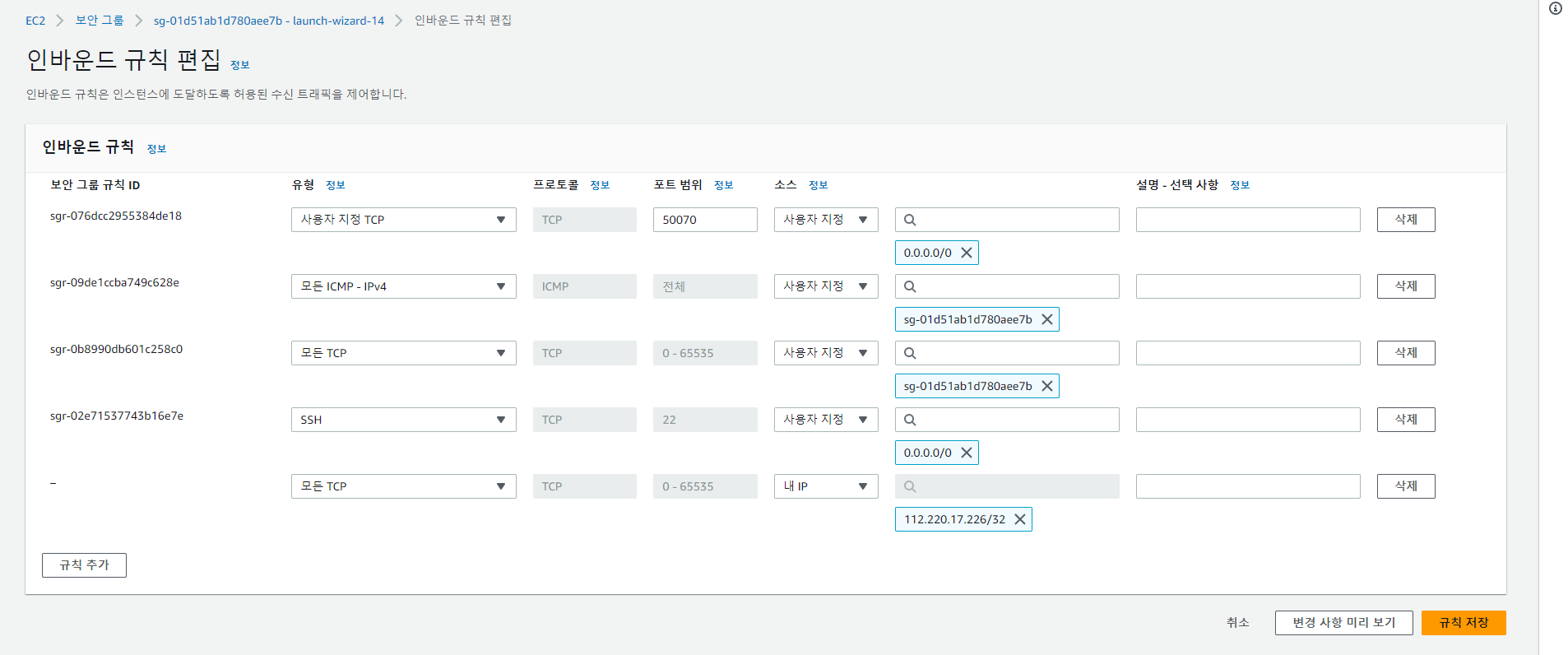
4-1-1 인바운드 규칙을 편집한다.
4-1-2 hosts 파일에 내 ip들을 추가해준다.
- 이과정은 각각의 모든 ip를 기억하기 힘들기 때문에 설정하는 것이다.
- 기존 사용하던 보안규칙에 모든 tcp 내 ip를 추가해준다.
- dns 서버보다 먼저 검색한다.
- C:\Windows\System32\drivers\etc
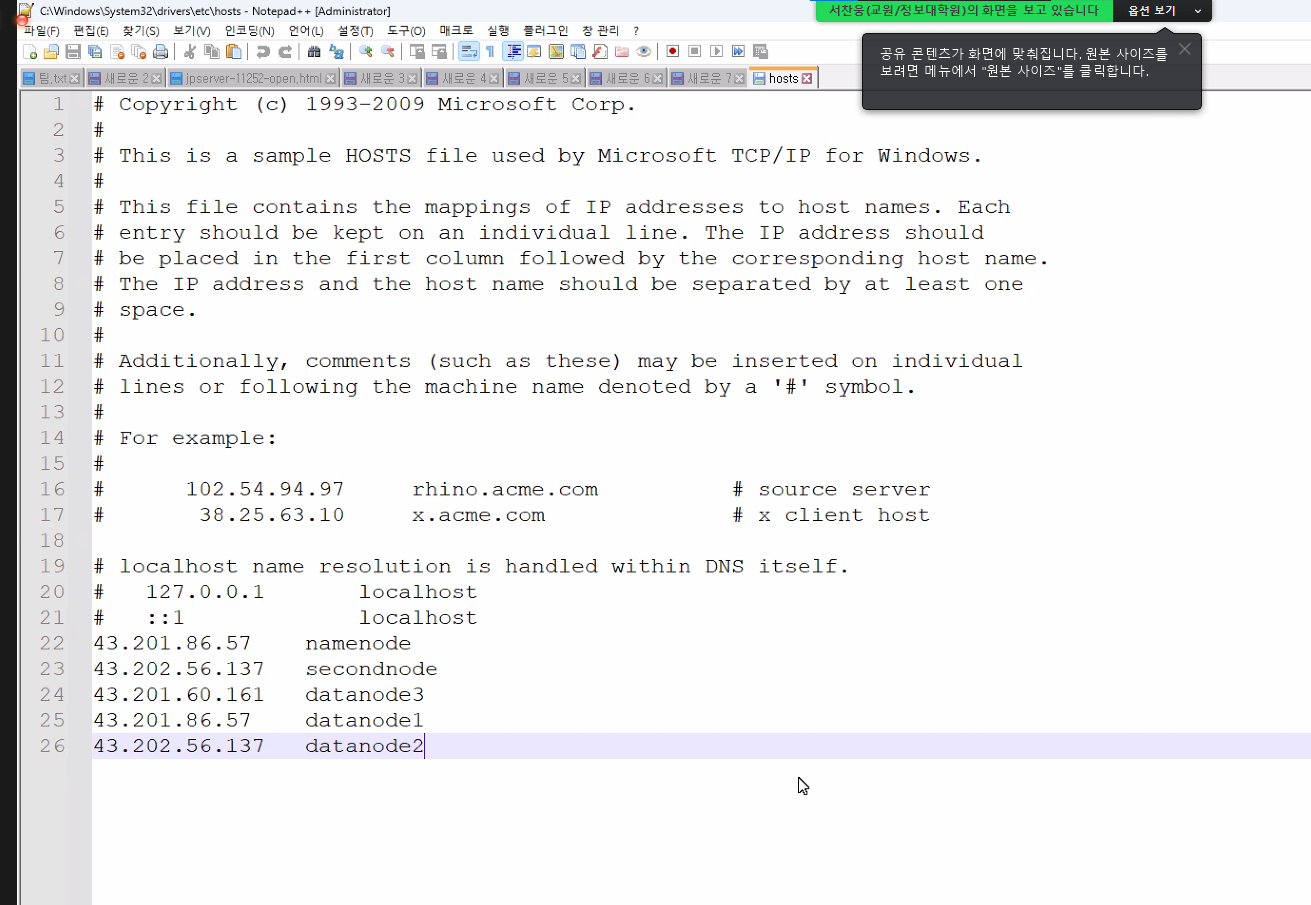
- 43.202.5.132 client
- 43.201.97.90 namenode
- 3.38.211.128 secondnode
- 43.201.254.2 datanode3
- 43.201.97.90 datanode1
- 3.38.211.128 datanode2
client 인스턴스1 / namenode, datanode1 인스턴스2 / secondnode, datanode2 * 인스턴스 3
4-2 client로 접속 이후 명령어를 실행
- start_dfs
- start_yarn
- start_mr
명령어를 실행하여 모든노드를 다 실행해준다.
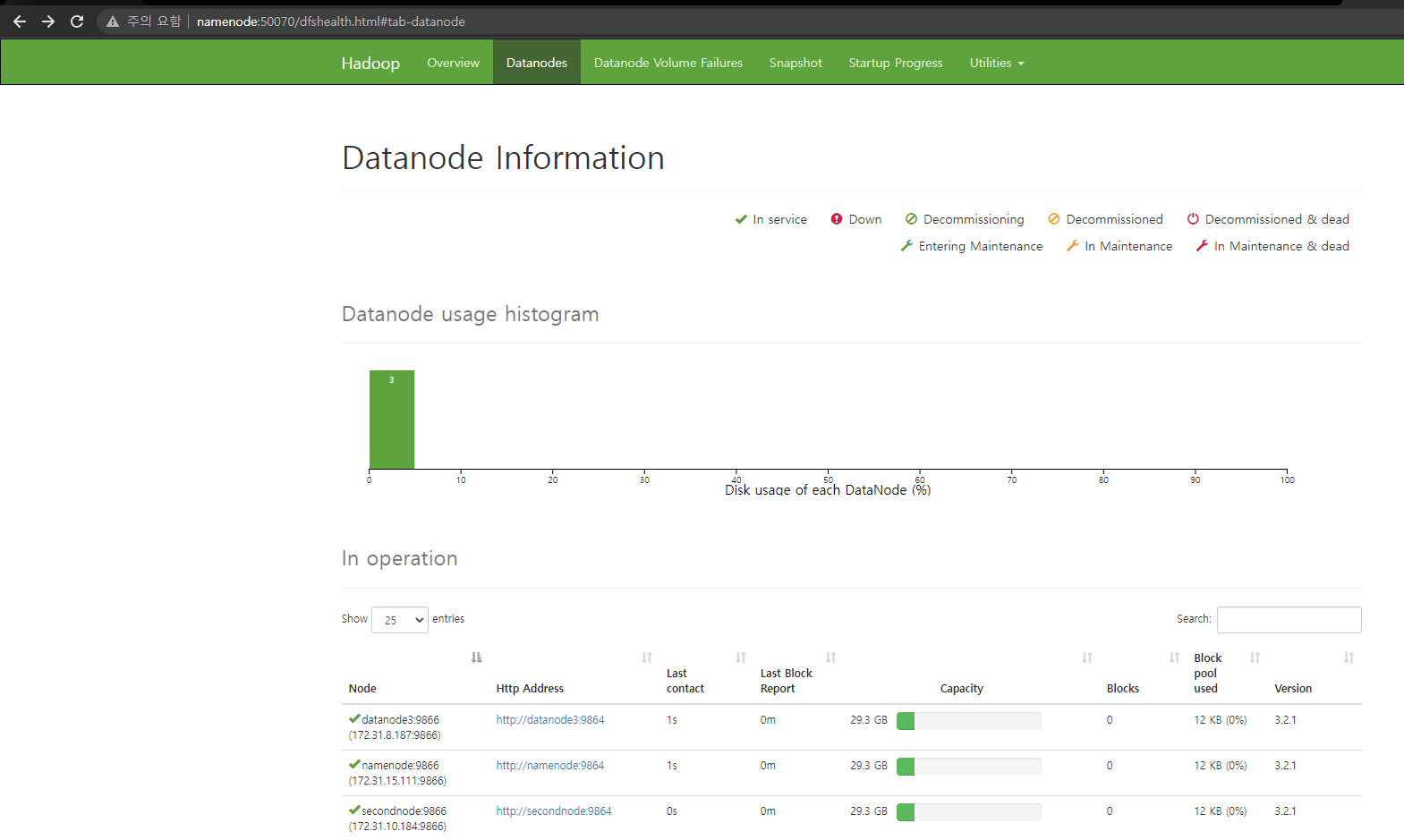
이후 미리 hosts 파일에 설정해놓았기때문에 namenode:50070으로 접속할 수 있다.
피싱당하는 것도 이런 방식으로
(host 파일을 먼저 보고 접속하기 때문에 해당 파일에서 피싱사이트에 접속하게 되어있으면 피싱당할 수가 있다.)
파일을 푸쉬하기 위한 작업.
4-3 하둡에 파일 넣고 워드카운트 해보기
hdfs dfs -put ~/hadoop/etc/hadoop/*.xml /mydata 로 xml 파일들을 다 넣어본다.
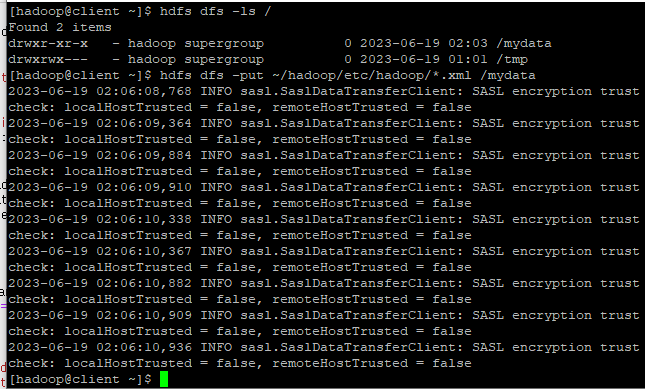
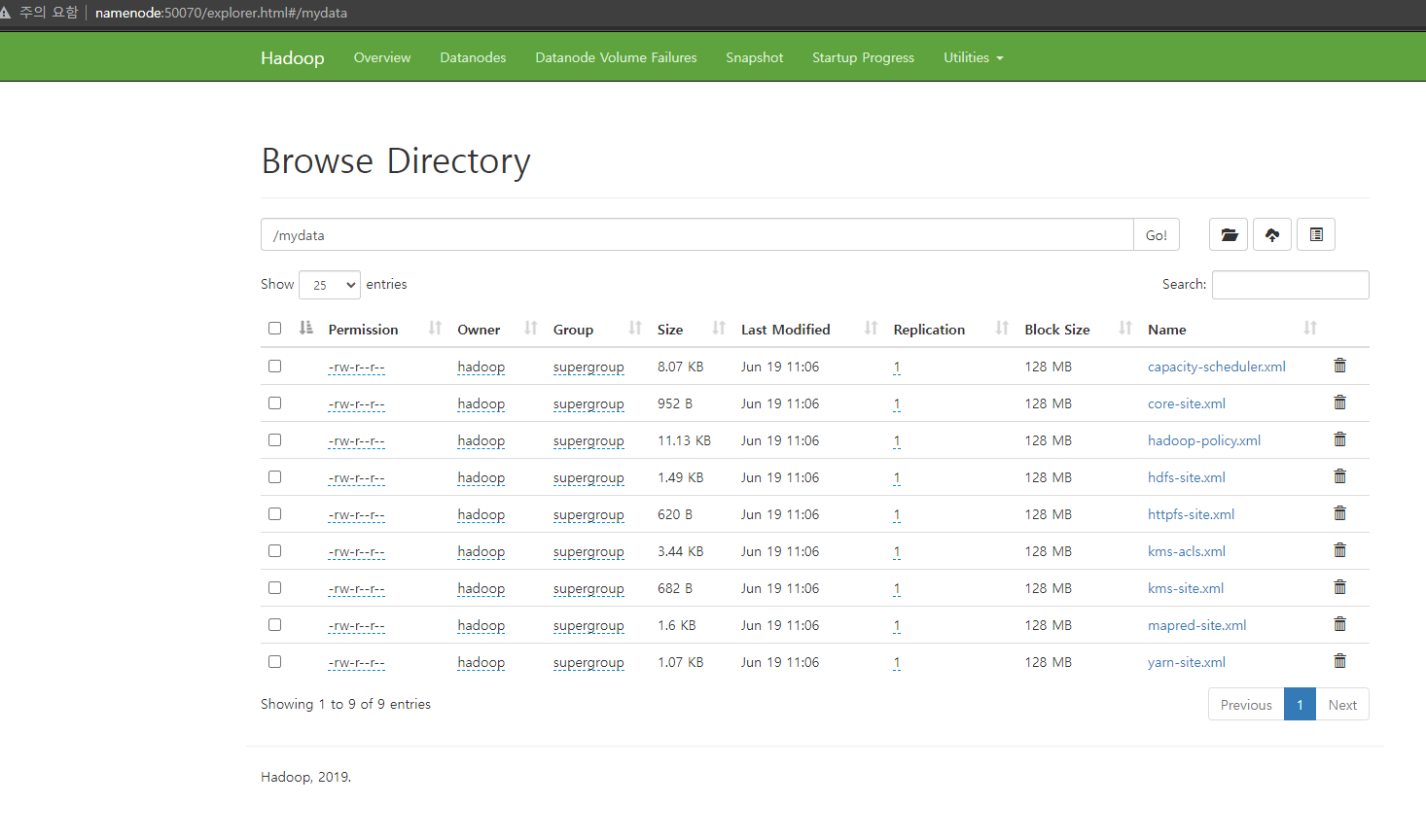
- 확인은 utilities에서 가능하다.
hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep /mydata /output2 'dfs[a-z.]+'
- hadoop: Hadoop 명령을 실행하는 Hadoop 실행 파일입니다.
- jar: JAR 파일을 실행하고자 한다는 것을 지정합니다.
- ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar: Hadoop MapReduce 예제가 포함된 JAR 파일의 경로.
- grep: 실행하고자 하는 특정 MapReduce 예제 프로그램으로, 파일에서 패턴 매칭 작업을 수행합니다.
- /mydata: 패턴을 검색하고자 하는 입력 경로 또는 디렉터리
- /output2: 패턴 매칭 결과를 저장할 출력 경로
- 'dfs[a-z.]+': 입력 파일 내에서 찾고자 하는 정규 표현식 패턴
위 명령어를 실행하면, Hadoop은 지정된 MapReduce 프로그램(grep)을 입력 데이터(/mydata)에 대해 실행합니다. 주어진 정규 표현식('dfs[a-z.]+')과 일치하는 문자열의 발생 여부를 확인하여 결과를 출력 디렉터리(/output2)에 저장
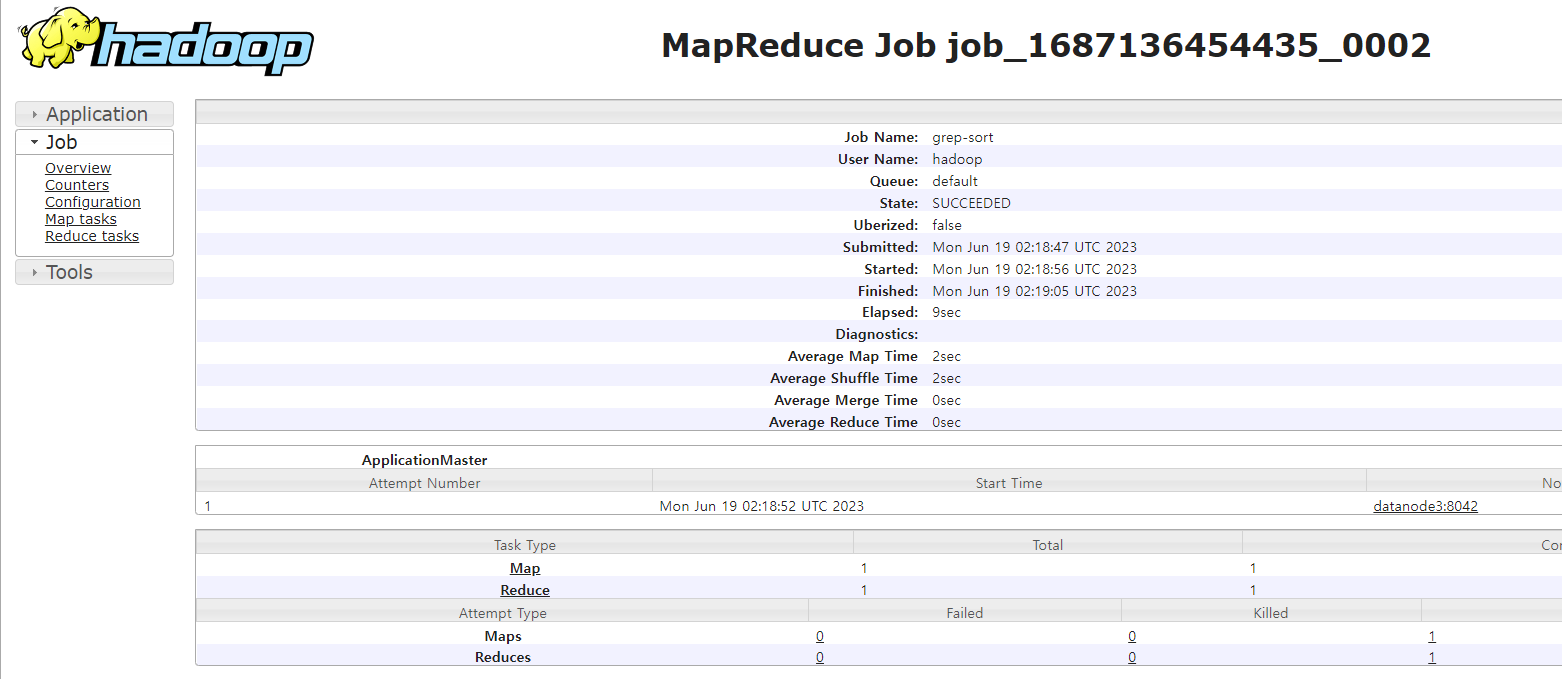
map은 조사 / reduce는 집계
- map
입력 데이터가 클러스터에서 병렬로 처리되며 이 맵 단계를 수행하는 mapper 함수는 원시 데이터를 key와 value의 쌍으로 변환- shuffle
변환된 데이터는 키를 기준으로 정렬돼 bucket으로 셔플링된다.
4-4 하둡 사용의 결과
- 하둡을 map reduce로 사용하기엔 비효율적이다.
- 하둡은 분산 저장 시스템으로 사용 → spark를 사용
4-5 하이브 사용(분석)
하이브(Hive)는 하둡 생태계 내에서 사용되는 데이터 웨어하우징(Data Warehousing) 및 SQL 쿼리 도구
- client 접속
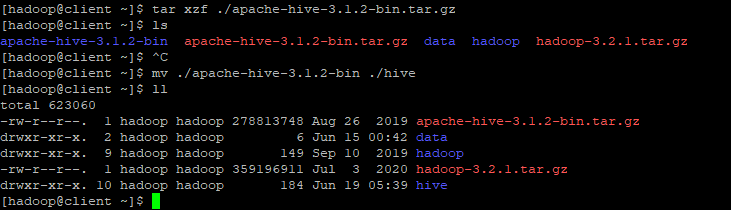
cdwget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gztar xzf ./apache-hive-3.1.2-bin.tar.gz- 압축을 푼 이후 해당 폴더를 hive로 이름을 바꾼다.
4-6 namenode에 마리아db설치 및 데몬 등록
sudo yum install mariadb-server -y
sudo systemctl enable mariadb --now
sudo systemctl status mariadb
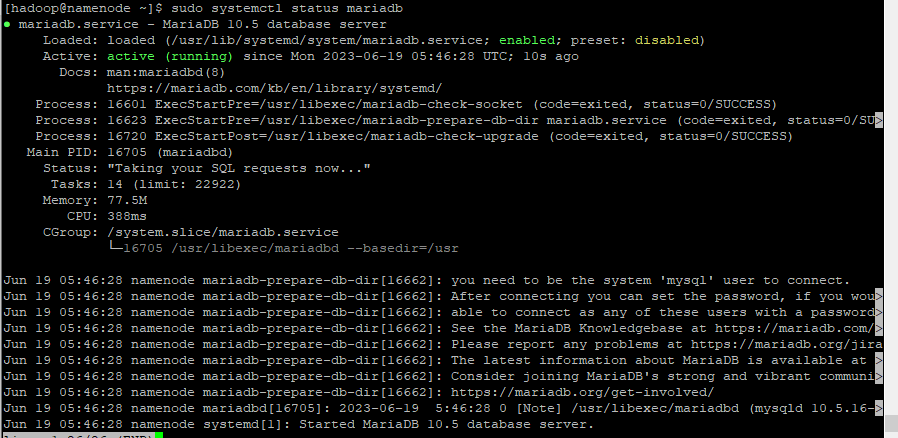
- mariadb의 상태를 봤을대 active(running) 이 되었는지 확인한다.
- mysql_secure_installation
4-7 하둡 하이브 다운
먼저 sql을 작업한다.
접속후
mysql -u{유저이름} -p{패스워드}
create database hivedb;: hivedb를 만든다.
create user hiveuser@localhost identified by 'hivepw';
: hiveuser"라는 이름의 사용자를 생성하고, 해당 사용자의 암호를 'hivepw'로 설정
grant all privileges on hivedb.* to hiveuser@localhost;
: "hivedb" 데이터베이스에 대한 모든 권한을 "hiveuser"에게 로컬 호스트(localhost)에서 부여
grant all privileges on hivedb.* to hiveuser@'client' identified by 'hivepw';
: "hivedb" 데이터베이스에 대한 모든 권한을 "hiveuser"에게 'client' 호스트에서 부여하고, 해당 호스트에서 접속할 때 암호를 'hivepw'로 설정
flush privileges;: 권한 변경 사항을 즉시 적용하기 위해 MySQL 서버의 권한 캐시를 비운다
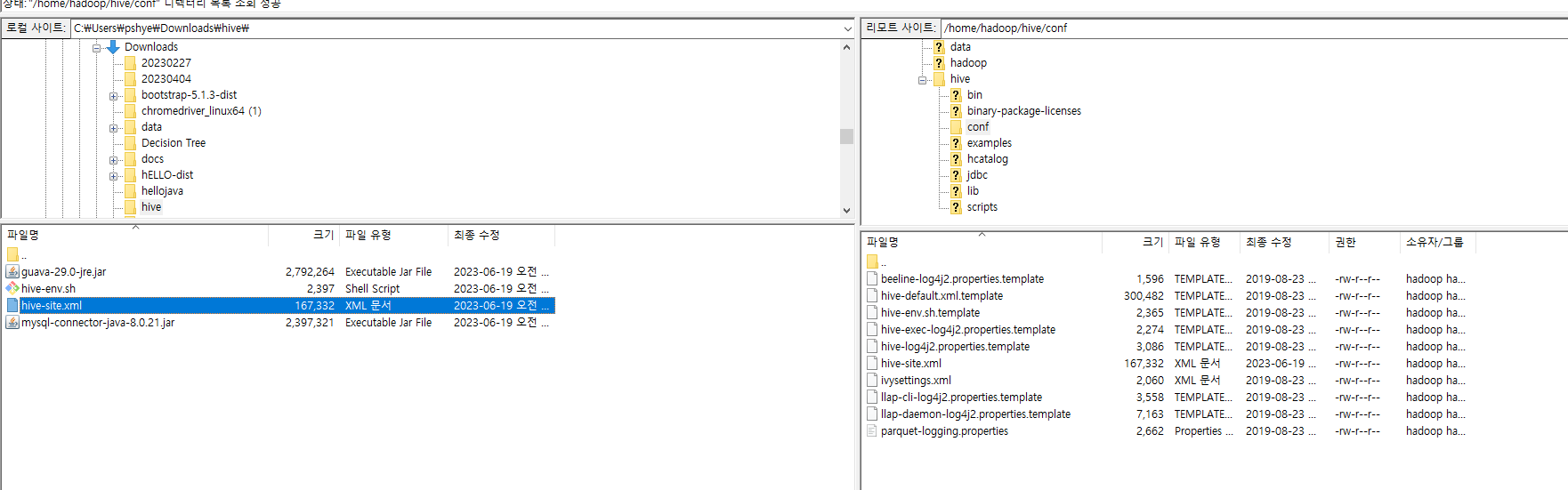
xml파일과 sh 파일을 hive 하위 conf 하위에 넣어준다.
/home/hadoop/hive/conf
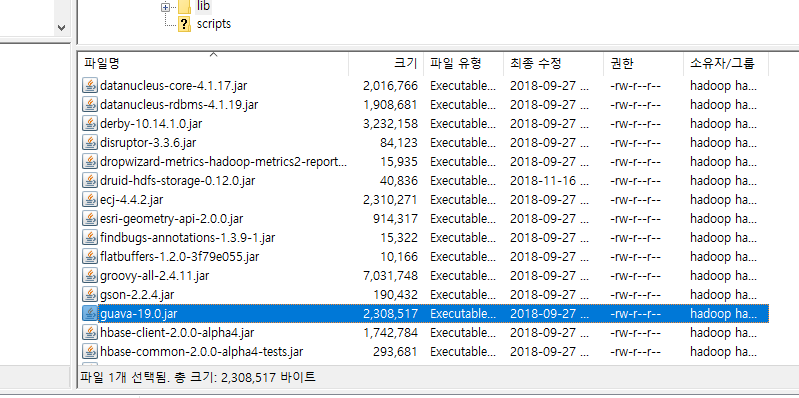
guava 버전을 맞추기 위해서 해당파일을 지우고 넣어준다.
lib 하위에 guava -29.0. 파일을 넣어준다.
mysql-connector-java-8.0.21.jar 도 넣어준다.
4-8 client에 접속 → hive를 등록해줘야한다.
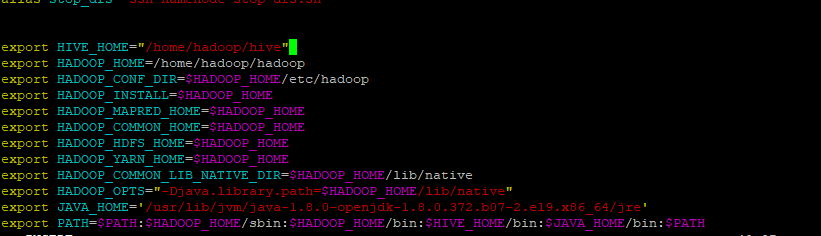
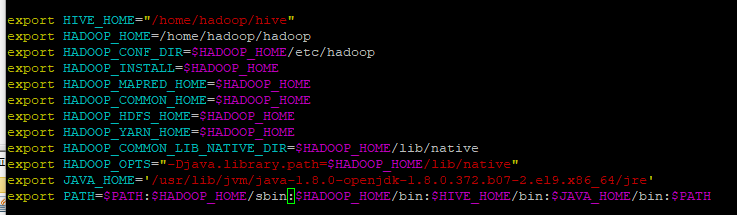
- hive home을 추가해줬다.
- 모든 운영체제는 path가 등록되어있어야지 접속이 가능하다.
- 따라서 bashrc에 bin:$HIVE_HOME이 있는지 확인한다.
hdfs dfs -mkdir -p /user/hive/warehouse: 디렉터리를 생성
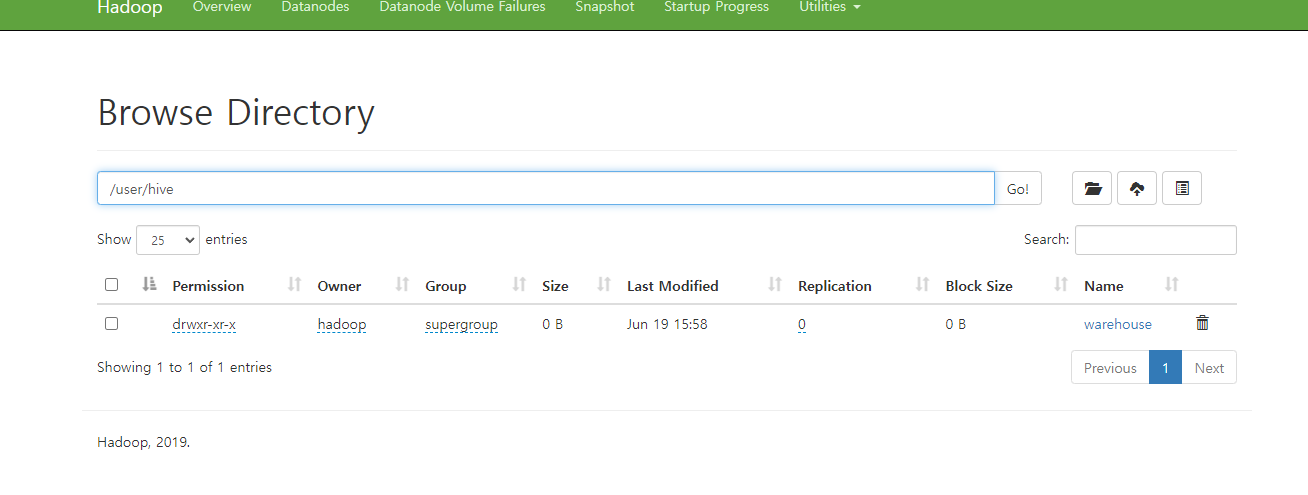
hdfs dfs -chmod g+w /user/hive/warehouse: 그룹(Group)에게 쓰기(Write) 권한이 추가
4-9 tmp 파일 생성
hdfs dfs -mkdir /tmp
hdfs dfs -chmod g+w /tmp
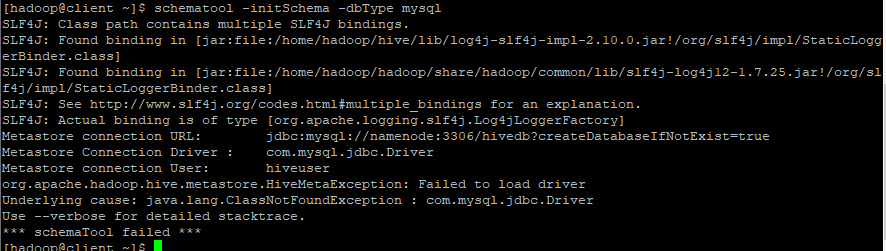
schematool -initSchema -dbType mysql
4-10 마지막 정리
wget https://mydatahive.s3.ap-northeast-2.amazonaws.com/tmdb.zip
tmdb 데이터를 사용할것이다.
zip파일이기 때문에 sudo yum install unzip
mkdir tmdb && unzip ./tmdb.zip -d ./tmdb
하이브에서 하려면 스키마를 만들어줘야한다.
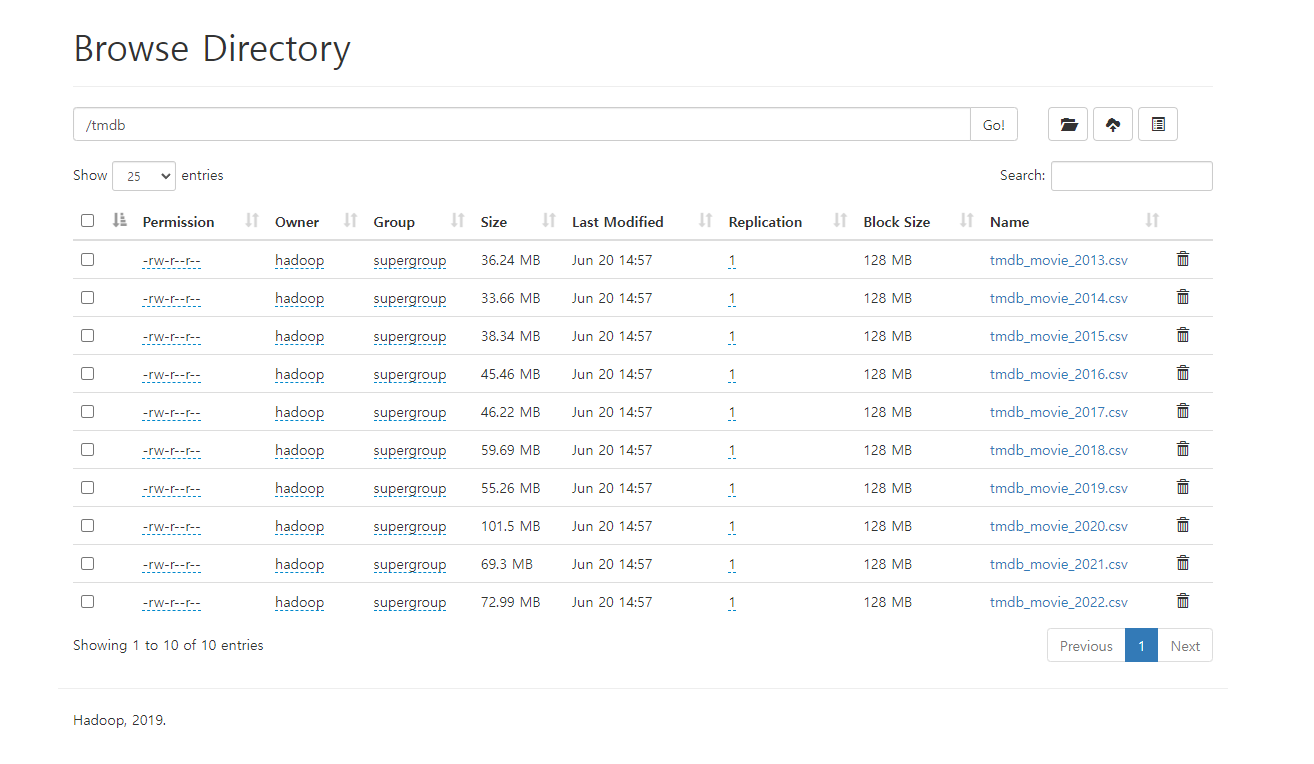
hdfs dfs -mkdir /tmdb
hdfs dfs -put ./*.csv /tmdb
자바 코딩을 하기 싫어서 페이스북 팀에서 만든게 하이브
