
환경 변수 설정
AWS에서 모든 인스턴스를 다 실행해준다. client의 경우 접속을 해야하기때문에 ip 주소를 확인해놓는다.
→ 항상 켜놓으면 좋지만 4개에 t2.medium이면 시간당 약 2달러씩 사라지기때문에… 꺼놓는다.
→ 항상 쉽게 접속하기위해 탄력적 ip를 설정하면 되지만 이것도 비용…
→ 편하려면 모든지 돈이 있으면 된다…(돈 많이 벌어야지)
- 하둡 환경파일에 접속한다
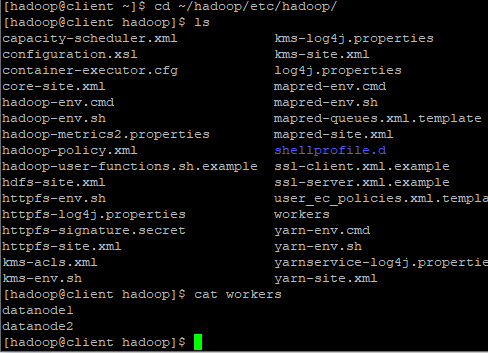
-cd ~/hadoop/etc/hadoop
-ls입력 : 환경파일을 확인한다.
-cat worksers입력 : workers를 확인한다.
- datanode를 3개 추가한다 : 3곳에 저장이 되게 설정
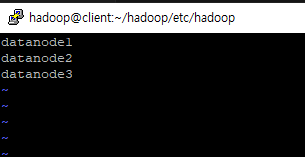
SCP로 파일 복사

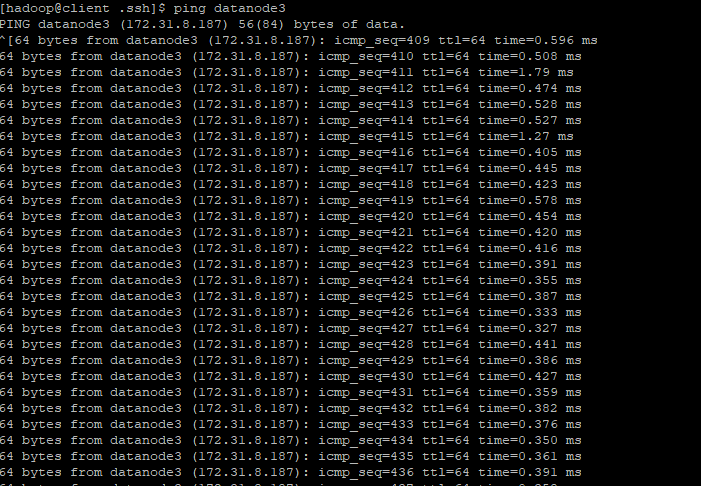
ping으로 해당 서버와 통신이 가능한지 확인해본다.
→응답이없다… 들어가려면 해당 접근을 허용해줘야하는데 보안그룹 설정이 안되어있어서 발생하는 문제
- scp를 사용하려했지만 해당 기능을 사용해주기 위해서는 보안그룹 설정 → 인바운드 규칙 수정이 선행되어야한다.

- 기본적으로 설정되어있는 ssh 22번 포트는 원격접속을 위한 포트로 서버작업을 하려면 해당 포트는 무조건 열려있어야한다.
- 파일 이동을 허용하기 위한 모든 TCP를 추가
- TCP : 통신하고자 하는 양쪽 단말(Endpoint)의 통신 준비 상태, 데이터가 제대로 전송여부, 데이터 이동 중 변질 여부, 수신자가 얼마나 받았고 빠진 부분은 없는지 등을 점검한다.
해당 작업을 해준 이후 ping이 확인되며, 파일을 주고 받을 준비가 되었다는 것을 알 수 있다.
하둡 실행을 해보자
하둡 실행하기 위해서 환경변수 수정
- 환경변수 수정의 늪이다.
vim ~/.bashrc입력 후 export JAVA_HOME을 해준다. 자바 홈의 이름이나 위치가 제대로 설정되어있는지 확인한 후 추가 이 작업중 java-1.8~~~ 하위에 jre라는 폴더가 하나 더 있어서 실행하는데 시간이 더 많이 걸렸다.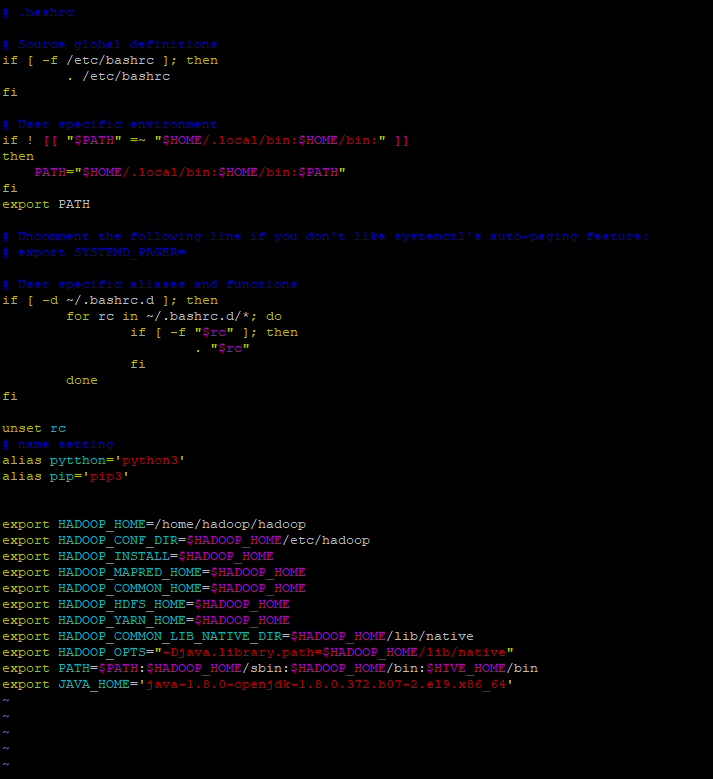
수정한 파일을 모든 노드에 보내기
scp ./.bashrc client:/home/hadoopscp ./workers namenode:/home/hadoop/hadoop/etc/hadoopscp ./.bashrc datanode3:/home/hadoop
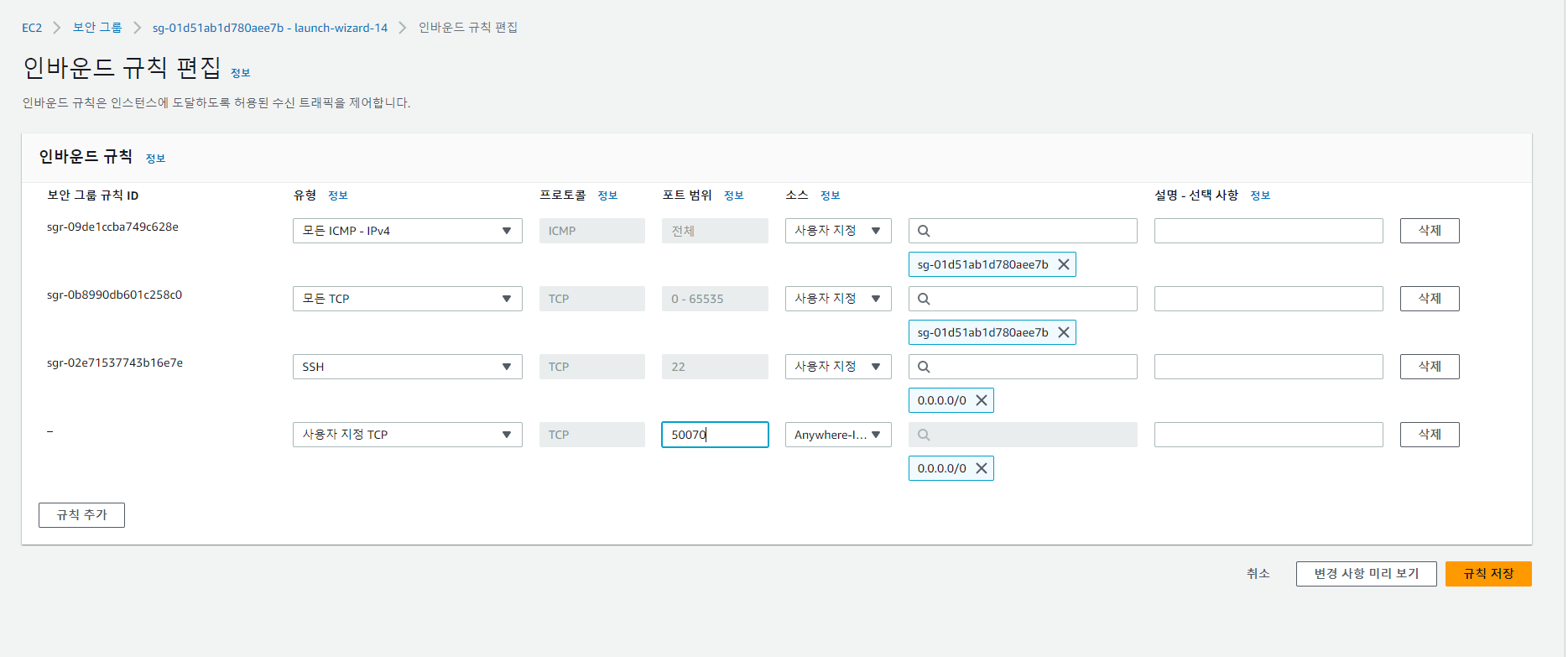
하둡 연결 포트 개방
- 사용자 지정 포트를 열어준다.
- 보안 그룹에서 하둡의 known port를 추가해준다. 50070번 포트
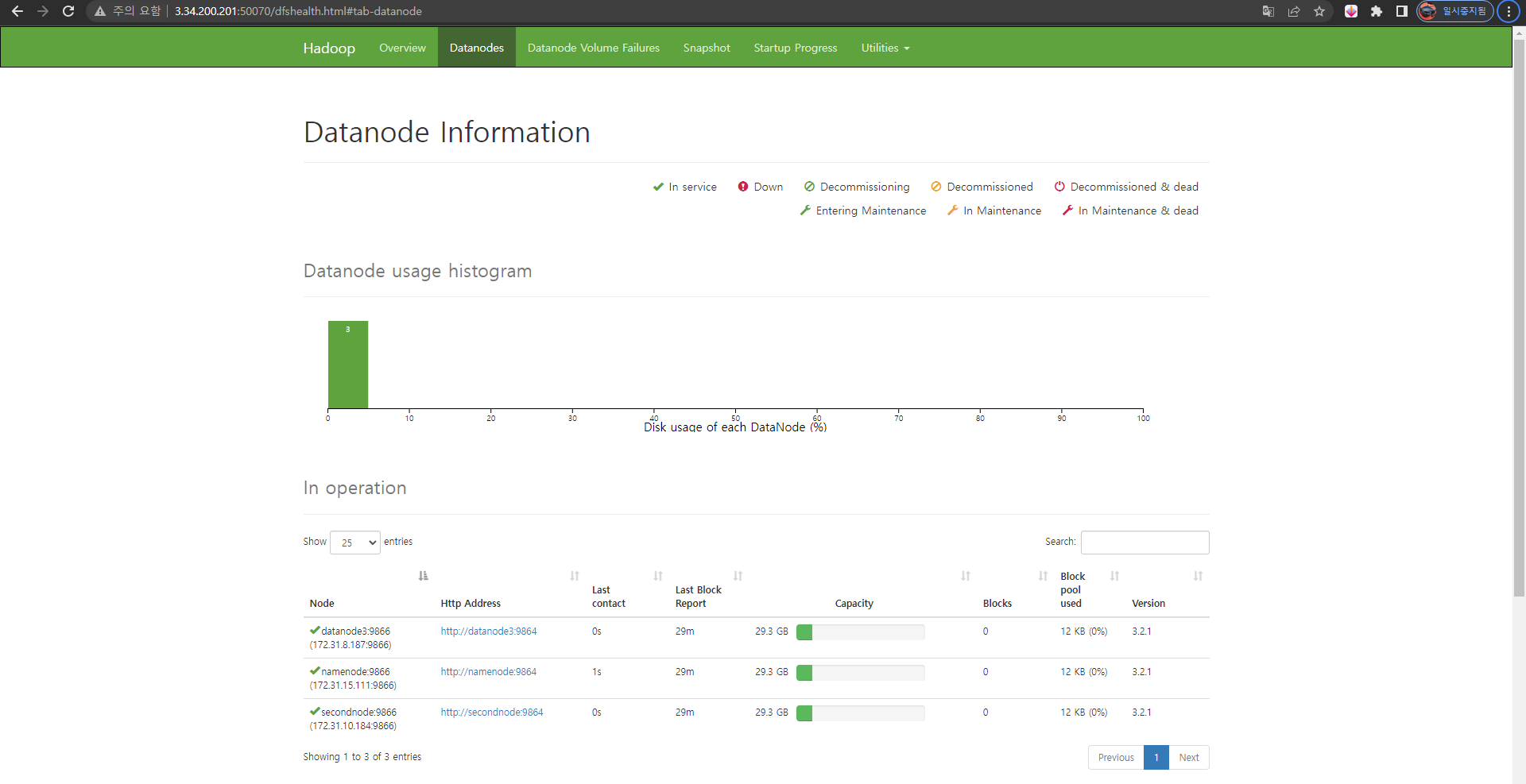
- 연결이 잘된다.
dfs / yarn / mr
각각의 용도
아직 익숙하지가 않은 각각의 용도 chatgpt의 설명
DFS (Distributed File System): Hadoop에서 분산 파일 시스템(Distributed File System, DFS)은 대용량 데이터에 대한 견고하고 확장 가능한 저장소를 제공하는 주요 저장 시스템입니다. Hadoop 분산 파일 시스템(Hadoop Distributed File System, HDFS)은 Hadoop 클러스터에서 일반적으로 사용됩니다.
Yarn: YARN (Yet Another Resource Negotiator)은 Apache Hadoop의 프레임워크로, 클러스터의 리소스를 관리하고 작업을 예약하는 역할을 합니다. 이를 통해 MapReduce, Apache Spark, Apache Flink 등 다양한 데이터 처리 엔진이 동일한 클러스터에서 실행될 수 있습니다.
MR (MapReduce): MapReduce는 Hadoop에서의 분산 처리를 위한 프로그래밍 모델 및 처리 프레임워크입니다. 이 모델은 Map과 Reduce라는 두 단계로 처리를 분할합니다. Map 단계는 데이터를 병렬로 처리하고, Reduce 단계는 Map 단계의 결과를 결합합니다.
dfs : 분산 파일 시스템 (HDFS) 서비스
yarn : 노드를 분산해주는 개념(지원부서)
mr : mapreduce
따라서 하둡을 실행 및 종료를 위해서는 다음의 순서대로 실행해주면 된다.
실행 순서 : HDFS -> YARN -> MR-History Server
종료 순서 : YARN -> MR-History Server -> HDFS
하둡을 편하게 실행
client에서 각각의 작업을 환경변수에 별명을 붙여주는 것이다.
vim ~/.bashrc
alias start_dfs="ssh namenode start-dfs.sh"
alias start_yarn="ssh secondnode start-yarn.sh"
alias start_mr="ssh namenode mr-jobhistory-daemon.sh start historyserver"
alias stop_mr="ssh namenode mr-jobhistory-daemon.sh stop historyserver"
alias stop_yarn="ssh secondnode stop-yarn.sh"
alias stop_dfs="ssh namenode stop-dfs.sh"
client를 Putty로 접속 → su hadoop으로 계정을 전환 → start-dfs / start-yarn / start-mr 노드들의 역할을 on이 가능하다.
jps
jps로 해당 기능들이 제대로 실행되었는지 확인 할 수 있다.
hdfs 명령어
하둡을 사용하려면 다음의 명령어들은 숙지해놓는게 좋다.
hdfs dfs -cat [경로]
경로의 파일을 읽어서 보여줌
리눅스 cat 명령과 동리함hdfs dfs -count [경로]
경로상의 폴더, 파일, 파일사이즈를 보여줌hdfs dfs -cp [소스 경로] [복사 경로]
hdfs 상에서 파일 복사hdfs dfs -df /user/hadoop
디스크 공간 확인hdfs dfs -du /user/hadoop
파일별 사이즈 확인hdfs dfs -dus /user/hadoop
폴더의 사이즈 확인hdfs dfs -get [소스 경로] [로컬 경로]
hdfs 의 파일 로컬로 다운로드hdfs dfs -ls [소스 경로]
파일 목록 확인hdfs dfs -mkdir [생성 폴더 경로]
폴더 생성hdfs dfs -mkdir -p [생성 폴더 경로]
폴더 생성, 부모 경로까지 한번에 생성hdfs dfs -put [로컬 경로] [소스 경로]
로컬의 파일 hdfs 상으로 복사hdfs dfs -rm [소스 경로]
파일 삭제, 폴더는 삭제 안됨hdfs dfs -rmr [소스 경로]
폴더 삭제hdfs dfs -setrep [값] [소스 경로]
hdfs 의 replication 값 수정hdfs dfs -text [소스 경로]
파일의 정보를 확인하여 텍스트로 반환
gz, lzo 같은 형식을 확인후 반환해줌hdfs dfs -getmerge hdfs://src local_destination
hdfs 경로상의 파일을 하나로 합쳐서 로컬로 가져온다.
리듀스 결과가 여러개일 경우 하나의 파일로 만들기 위해 사용 가능.
주의할 점은 로컬 경로로 가져온다는 것이다. hdfs 상에는 생성 불가.
