Convolution
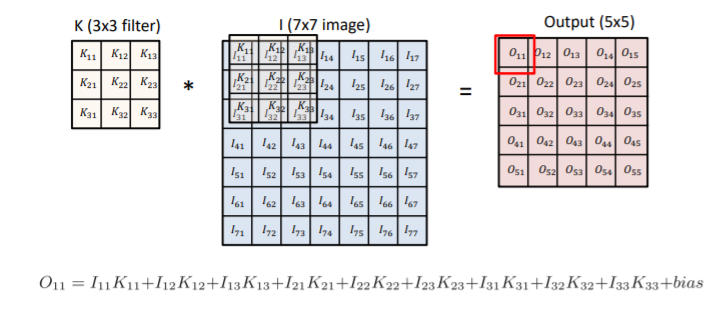
- convolution filter를 적용하고자 하는 img에 찍고 그것을 output에 기록
Continuous Convolution
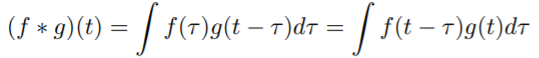
- 두 개 함수 f랑 g를 mix해주는 operator 함수
Discrete Convolution
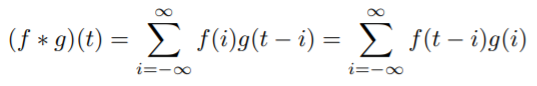
2D image Convolution
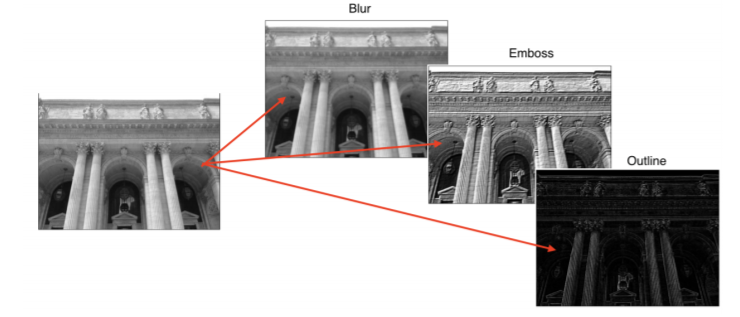
- 적용하고자 하는 filter의 image에 대해서 convolution output이 다르게 나올 수 있음
- 강조하거나 외곽선 따기 가능
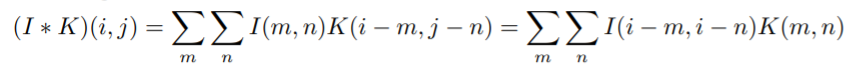
- I는 전체 이미지 공간
- K는 적용하고자 하는 convolution filter
RGB Image Convolution
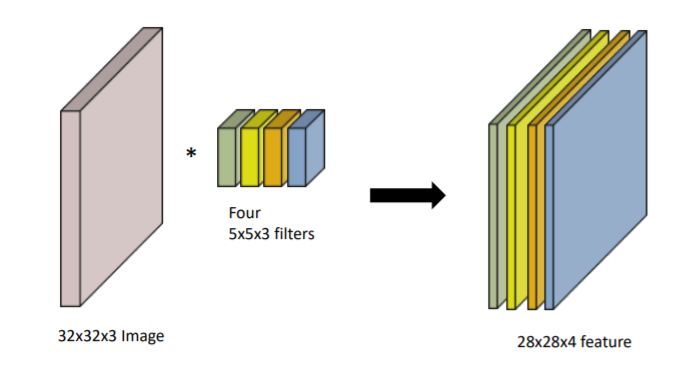
- 이 때 3은 RGB의 이유 때문
- filter의 크기는 항상 같음
- input channel과 output convolution feature map의 channel 알면 여기에 적용되는 convolution feature의 크기 계산 가능
- convolution filter의 개수도 알 수 있음
Stack of Convolutions
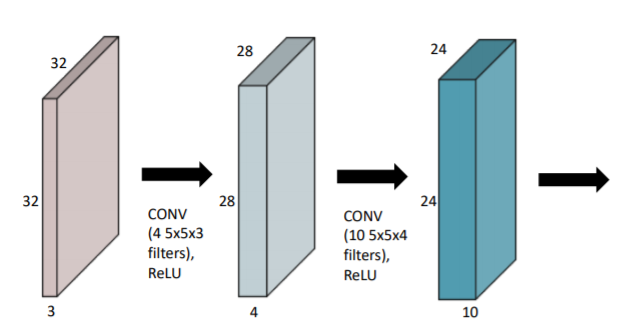
- 연산을 정의하는 데에 필요한 parameter 숫자 잘 생각해야
- convolution의 feature size 5x5
convolution이 적용되는 channel의 숫자 3
output의 숫자 4 이용해서 parameter 수 구할 수 있음 - 이때 ReLU는 활성함수의 type. 활성함수와 함께 convolution 진행
Convolutional Neural Networks
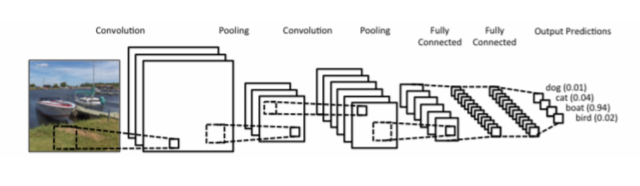
- Model은 deep하게, Parameter 숫자는 줄이는 데에 집중
- Convolution Layer, Pooling Layer, Fully Connected Layer로 구성
- Convolution Layer : Convolution feature를 통해 도장 찍고 값 얻어내는 역할- Pooing Layer : 2x2, average, max, ...
- Fully Connected Layer : 다 합쳐서 최종적으로 원하는 결과로 만들어줌. Parameter 숫자에 dependent
- Convolution과 Pooling layer는 img에서 유용한 정보 뽑아냄
- Fully Connected Layer는 decision making. 회귀 문제에서 원하는 출력값 얻어낼 수 있도록 도와줌. 분류 문제에서 사용
- Parameter 숫자 늘어날수록 학습 어렵고, generalization performance가 떨어지게 됨
- Generalization Performance : 학습에서 얻어진 data가 실제 test data에서 얼마나 잘 동작할지
Stride
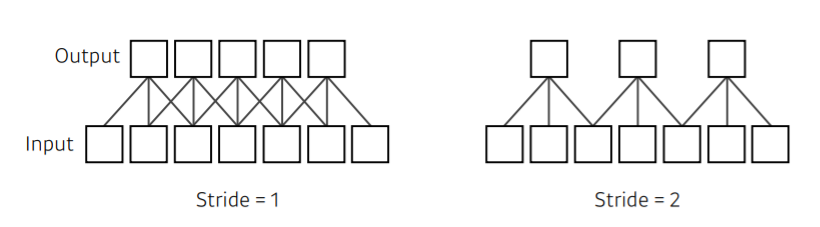
- Stride는 convolution filter를 얼마나 자주, dense, sparse하게 찍을지에 대한 기준
- Stride = 1 : kernel의 convolution filter를 매 pixel마다 적용
- Stride = 2 : 한 번 찍고 두 칸 옮겨서 찍고... - 2D일 경우, stride가 width / height 방향으로 두 개 나옴
Padding
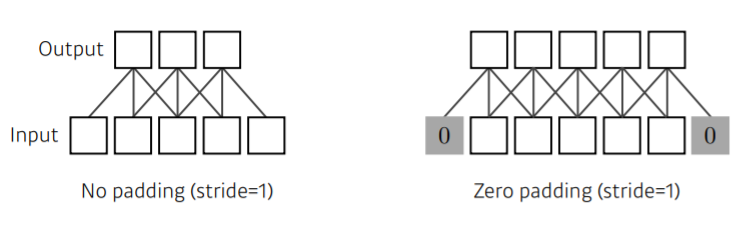
- 쉽게 말해서, padding을 통해 값을 덧대준다고 생각하면 됨!
- padding으로 input과 output의 공간적 차원이 같아지게 됨
Stride? Padding?
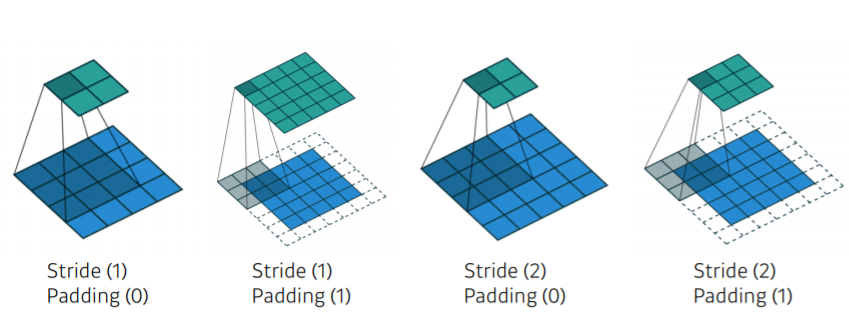
1) 한 칸씩 옮기면서 진행
2) 적절한 크기의 zero-padding 사용함으로써 입력과 출력의 feature map의 spatial dimension이 항상 같아지게 됨
3) stride가 2이므로 한 칸 건너서 가게 됨
4) 한 칸 건너서 가나, spatial dimension을 맞춰주고자 함
Convolution Arithmetic
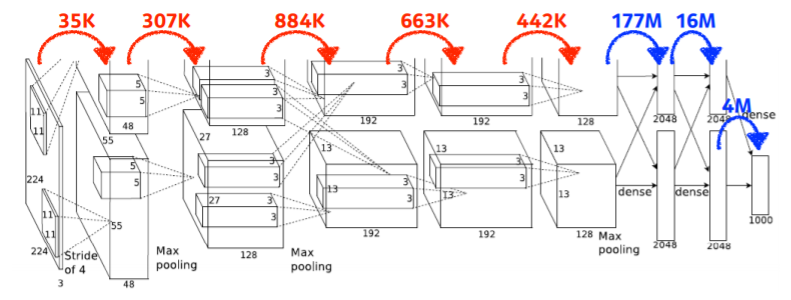
- 빨간색은 Convolution Layer, 파란색은 Dense Layer(Multi-Level Perceptron)
- Params # = kernel size kernel size channel size(== input dimension) * output channel size
1) 11 x 11 x 3 x 48 x 2 ≒ 35k
- 이 때 x 2는 GPU 사양에 맞추기 위함
2) 5 x 5 x 48 x 128 x 2 ≒ 307k
3) 3 x 3 x 128 x 2 x 192 x 2 ≒ 884k
4) 3 x 3 x 192 x 192 x 2 ≒ 663k
5) 3 x 3 x 192 x 128 x 2 ≒ 442k
6) 13 x 13 x 128 x 2 x 2048 2 ≒ 177M
- channel 값 channel 값 channel 숫자 ( 2) 마지막 출력값 ( 2)
7) 2048 2 x 2048 2 ≒ 16M
8) 2048 * 2 x 1000 ≒ 4M
1x1 Convolution
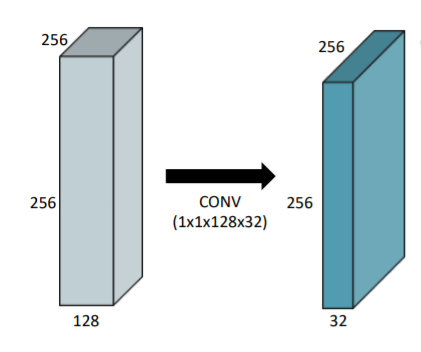
- 차원을 줄이기 위해 사용
- convolution layer 깊게 쌓으면서 parameter 숫자 줄이기 위해
- image를 1x1 pixel로 보고 channel 방향을 줄이기 위해 사용
- bottleneck architecture에서 자주 사용

세진니의 눈물 가득 블로그