인프런 강의 <파이썬입문과 크롤링기초 부트캠프>을 듣고, 중요한 점을 정리한 글입니다.
크롤링이란
: 웹사이트에서 내가 원하는 내용을 자동으로 추출하는 기능
1. 라이브러리 임포트
- 필요 라이브러리
- requests : 웹페이지 가져오기 라이브러리
- bs4(BeautifulSoup) : 웹페이지 분석(크롤링) 라이브러리
import requests
from bs4 import BeautifulSoup2. 웹페이지 가져오기
- res.content 확인해보기
res = requests.get('https://n.news.naver.com/mnews/article/001/0014225865?rc=N&ntype=RANKING')
res.content- 웹브라우저로 웹페이지를 가져온다
: 인터넷 환경에서 특정 주소에 가서 특정 컴퓨터에게 특정한 HTML로 된 파일을 가져오는 것
3. 웹페이지 파싱하기
-
파싱이란?
: 문자열의 의미 분석 -
이것을 어떻게 일일이 코드로 만들까?
‑> BeautifulSoup 라이브러리가 있습니다. -
soup 에 HTML 파일을 파싱한 정보가 들어감!
soup = BeautifulSoup(res.content, 'html.parser')
soup4. 필요한 데이터 추출하기
- 이 부분이 크롤링 핵심!
- soup.find() 함수로 원하는 부분을 지정하면 됨
- 변수.get_text() 함수로 추출한 부분을 가져올 수 있음
- 이를 위해 HTML 언어로 어떻게 웹페이지를 만드는지, 기본 내용을 이해할 필요가 있음!
mydata = soup.find('h2')5. 추출한 데이터 활용하기
- 필요한 데이터를 변수에 넣으면 이후 활용은 프로그래밍 영역
mydata.get_text()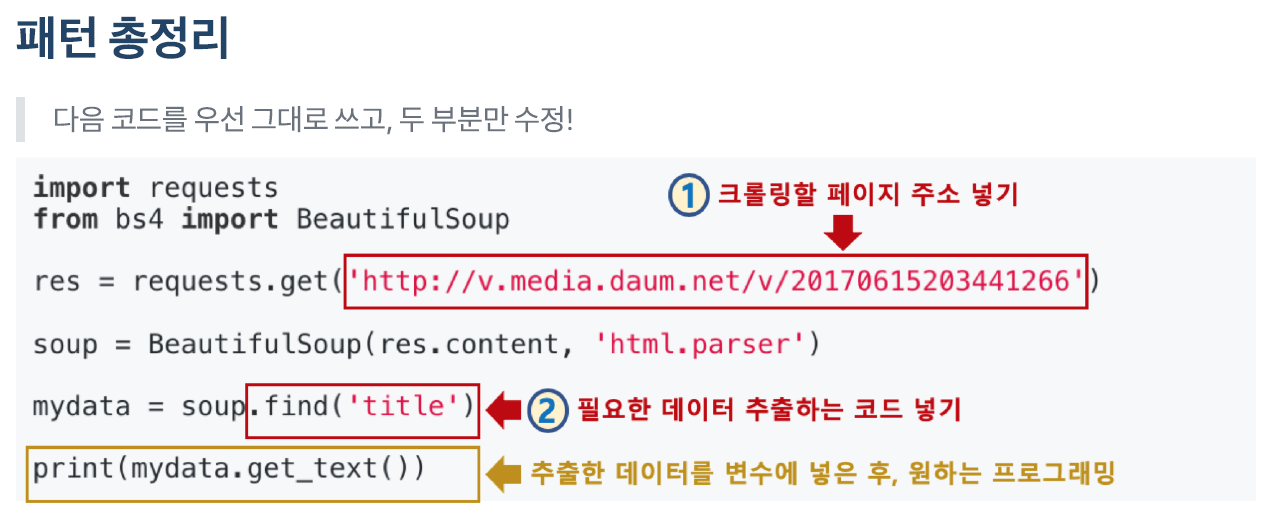

데이터분석 공부로그