인프런 <데이터분석을 위한 중급 SQL 문제풀이> 강의에서 나온 문제를 풀이한 과정을 정리했습니다.
문제

풀이
SELECT SUM(POPULATION)
FROM CITY
WHERE COUNTRYCODE = 'JPN'배운점
- 쉬워서 무난하게 풀었다.
문제
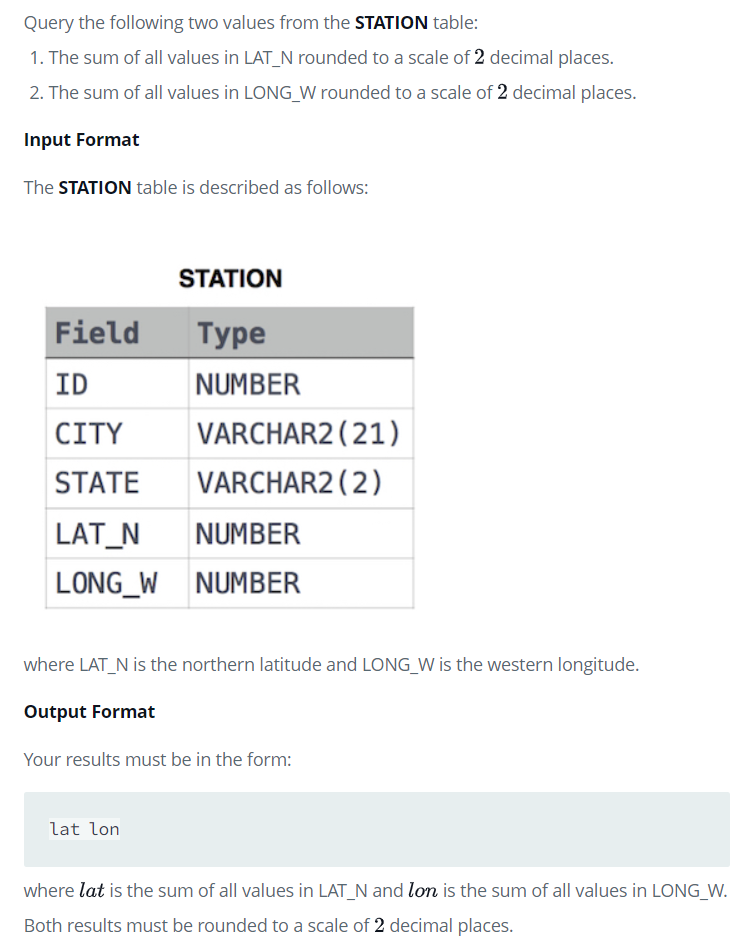
풀이
SELECT ROUND(SUM(LAT_N), 2) AS lat
, ROUND(SUM(LONG_W), 2) AS lon
FROM STATION배운점
문제

풀이
SELECT ROUND(ABS(MIN(LAT_N)-MAX(LAT_N)) + ABS(MIN(LONG_W)-MAX(LONG_W)), 4)
FROM STATION배운점
- on a 2D plane: '2D 평면에서'라는 의미
- 절대값 -> ABS()
문제(틀림)
https://www.hackerrank.com/challenges/the-company/problem?isFullScreen=true
풀이
- 나의 풀이
SELECT C1.company_code
, C1.founder
, COUNT(DISTINCT C1.lead_manager_code)
, COUNT(DISTINCT C1.senior_manager_code)
, COUNT(DISTINCT C1.manager_code)
, COUNT(DISTINCT C1.employee_code)
FROM C1.Company
LEFT JOIN C1.Lead_Manager ON C1.Company.company_code = C1.Lead_Manager.company_code
ORDER BY C1.company_code: 왜 틀렸을까? Sample Input을 보고, C1, C2 회사만 있는 경우로 이해하고 그대로 구현하려고 했다. 그러다보니 C2도 구현해야 하는데 '그러면 UNION을 해야 하나?' 하다가 일단 러닝해보니 쿼리문에 오류가 있다고 나옴.
- 선생님이 얘기한 자주 틀리는 풀이
SELECT C.company_code
, C.founder
, COUNT(DISTINCT E.lead_manager_code)
, COUNT(DISTINCT E.senior_manager_code)
, COUNT(DISTINCT E.manager_code)
, COUNT(DISTINCT E.employee_code)
FROM Company C
INNER JOIN Employee E ON C.company_code = E.company_code
GROUP BY C.company_code, C.founder
ORDER BY C.company_code: 왜 틀렸을까? 문제 설명 끝까지 안 읽어서! company 테이블과 employee 테이블로만 풀려고 하다 틀릴 수 있다. 물론, 이 문제는 테이터가 누락된 부분이(사람수 0명인 직급) 없어서 문제가 안 생겼지만, 전체 테이블이 공개된 건 전체 테이블을 활용하라는 거다.
- 선생님 풀이
SELECT C.company_code
, C.founder
, COUNT(DISTINCT LM.lead_manager_code)
, COUNT(DISTINCT SM.senior_manager_code)
, COUNT(DISTINCT M.manager_code)
, COUNT(DISTINCT E.employee_code)
FROM Company C
LEFT JOIN Lead_Manager LM ON C.company_code = LM.company_code
LEFT JOIN Senior_Manager SM ON LM.lead_manager_code = SM.lead_Manager_code
LEFT JOIN Manager M ON SM.Senior_Manager_code = M.Senior_Manager_code
LEFT JOIN Employee E ON M.Manager_code = E.Manager_code
GROUP BY C.company_code, C.founder
ORDER BY C.company_code배운점
-
LEFT JOIN을 해준 이유? 어떤 직급의 직원수가 0명일 가능성도 있으니, 그런 상황에서도 company는 출력되어야 하므로. 즉, 왼쪽 테이블에는 데이터가 있는데 오른쪽 테이블에는 데이터가 없는 상황 -> LEFT JOIN!
-
lead_manager의 명수를 셀 때는 lead_manager 테이블에 있는 lead_manager 수를 세줘야 함.
-
'LEFT JOIN Senior_Manager SM ON LM.lead_manager_code = SM.lead_manager_code'에서 두 테이블 붙여주는 기준 컬럼이 'company_code'가 아니라 'lead_manager_code'인 이유?
: lead manager 아래의 senior manager를 같이 봐야하므로, 둘을 이어줄 수 있는 칼럼인 'lead_manager_code'로 연결해줘야 한다.
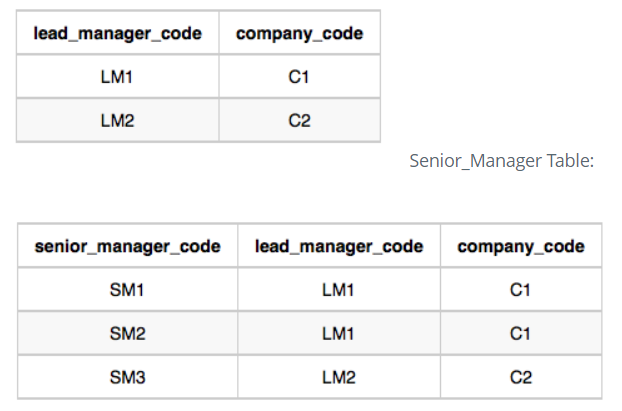
-
GROUP BY를 해주는 이유?
: 이 쿼리문에서 'GROUP BY C.company_code, C.founder'를 사용하는 이유는 다음과 같습니다: -
집계 (Aggregation): GROUP BY 절을 사용하면 특정 열(여기서는 C.company_code 및 C.founder)을 기준으로 데이터를 그룹화할 수 있습니다. 이 경우, 각 회사 (company_code)와 해당 회사의 창립자 (founder) 별로 데이터가 그룹화됩니다.
-
집계 함수 사용: COUNT(DISTINCT ...) 함수를 사용하여 각 그룹 내에서 고유한 값들의 수를 계산합니다. 이 경우, 각 회사 그룹 내에서 고유한 리드 매니저, 시니어 매니저, 매니저 및 직원의 수를 계산하려는 것으로 보입니다.
-
결과 집계: GROUP BY 절을 사용하면 결과 집합에는 각 회사 및 그 회사의 창립자 별로 한 행이 표시됩니다. 각 행은 회사 코드, 창립자, 해당 회사에 대한 고유한 리드 매니저 수, 시니어 매니저 수, 매니저 수 및 직원 수를 보여줍니다.
즉, GROUP BY를 사용하여 데이터를 그룹화하고 집계 함수를 사용하여 각 그룹 내에서 원하는 정보를 계산하고 결과를 정리하여 각 회사의 정보를 요약한 행을 얻을 수 있습니다.
출처) ChatGPT
