본 내용은 인프런에서 데이터리안님의 강의 <데이터 분석을 위한 판다스>를 수강하며 중요한 점을 정리한 글입니다.
특정 컬럼 삭제하기
df = air_quality[['datetime', 'station_paris']]air_quality.drop(['station_antwerp', 'station_london'], axis=1)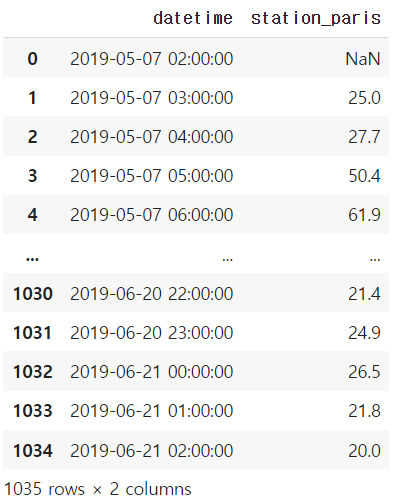
특정 로우 삭제하기
df = air_quality.drop([0, 1])
df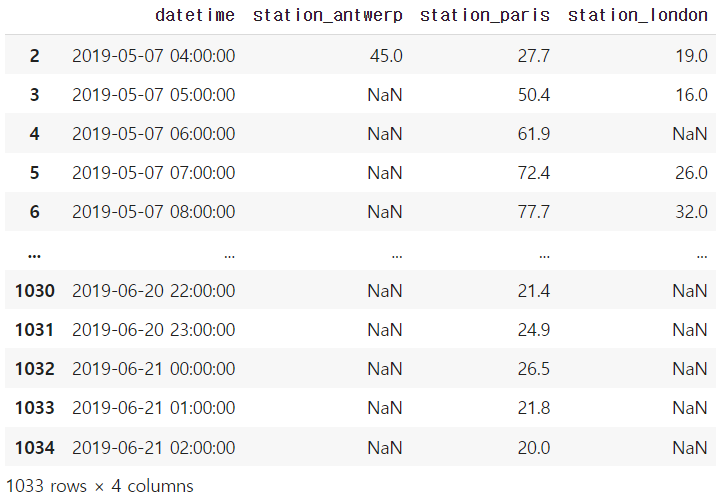
중복 데이터 삭제하기
df = pd.DataFrame({'one': [1, 2, 1], 'two': [0, 0, 0]})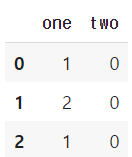
->
df.drop_duplicates()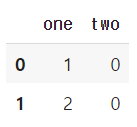

데이터분석 공부로그