본 내용은 인프런 강의 <데이터 분석을 위한 판다스>를 수강하며 중요한 점을 정리한 글입니다.
판다스 튜토리얼
https://pandas.pydata.org/pandas-docs/stable/getting_started/intro_tutorials/index.html
2. How do I read and write tabular data?
- 판다스는 csv, xls, html, json, sql 등 여러가지 데이터 소스와 같이 작업을 할 수 있다.
데이터 읽어오는 법
: 데이터 다운 -> 경로복사 -> 코드 작성해와서 테이블 출력
location = '/content/drive/MyDrive/Colab Notebooks/titanic.csv'
pd.read_csv(location)혹은
pd.read_csv('https://raw.githubusercontent.com/pandas-dev/pandas/master/doc/data/titanic.csv')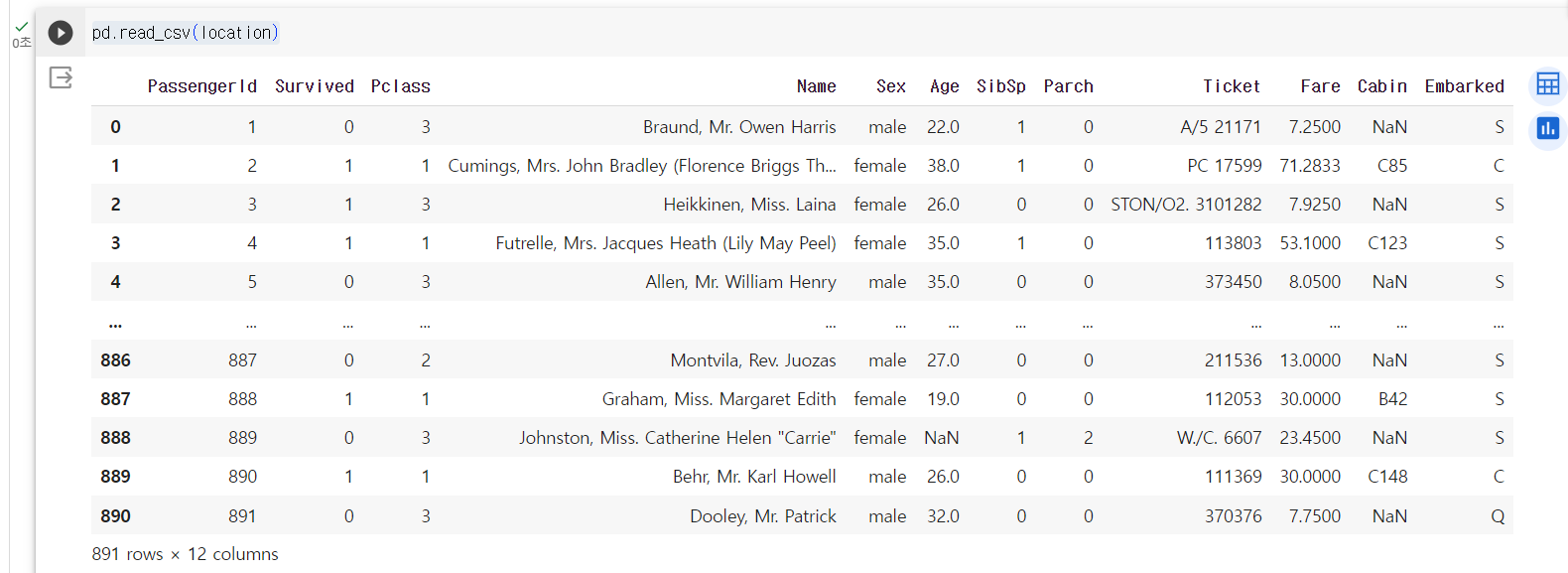
데이터 샘플 확인하기
: 데이터 프레임과 시리즈에 동시에 적용이 가능하다.
titanic # 전체 테이블
titanic.head() # 인덱스 상위 5개(5개가 디폴트값)
titanic.head(8) # 인덱스 상위 8개
titanic.tail(8) # 인덱스 하위 8개
titanic.sample() # 섞어서 8개
titanic['Age'].head() # Age 컬럼에서 5개
titanic['Age'].sample(8) # Age 컬럼에서 섞어서 8개데이터 타입 확인하기
dtypes는 함수가 아니라 속성이라서 괄호를 열고 닫지 않는다.
titanic.dtypes
->
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object또는
titanic['Age'].dtypes
->
dtype('float64')method와 attribute의 차이
- method(메소드, 함수)
: 오브젝트가 할 수 있는 일. 실행할 수 있는 함수. 인자를 받는다. 파라미터(변수)를 줘서 일을 시킨다. 앞의 예시에서 head, tail, sample.
titanic.head()
: head는 titanic이라는 데이터프레임 오브젝트가 지원하는 메소드
renee.drive('판교')
: renee라는 오브젝트가 판교로 운전한다.- attribute(속성)
: 오브젝트가 가지고 있는 특징. 앞의 예시에서 dtypes.
print(renee.gender)
print(renee.age)※ 파이썬의 경우, 둘 간의 경계가 모호하다.

데이터분석 공부로그