인프런 강의 <데이터 분석을 위한 고급 SQL>을 듣고, 중요한 점을 정리한 글입니다.
문제(틀림/완전히 이해되지 않음)
풀이
- 나의 풀이
DELETE
FROM Person
WHERE ID = 3
ORDER BY ID: 이렇게 해도 정답이라고 나옴. 그런데, 꼼수같기도 하고... 이렇게 풀어도 상관없나?
- 선생님 풀이1
DELETE
FROM person
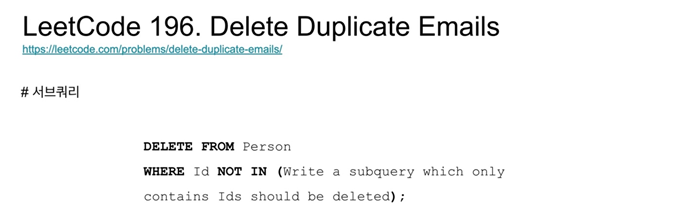
WHERE Id NOT IN (
SELECT sub.min_id
FROM (
SELECT Email, MIN(Id) AS min_id
FROM Person
GROUP BY Email
) sub)- 선생님 풀이2 (INNER JOIN 즉, 셀프조인 활용)
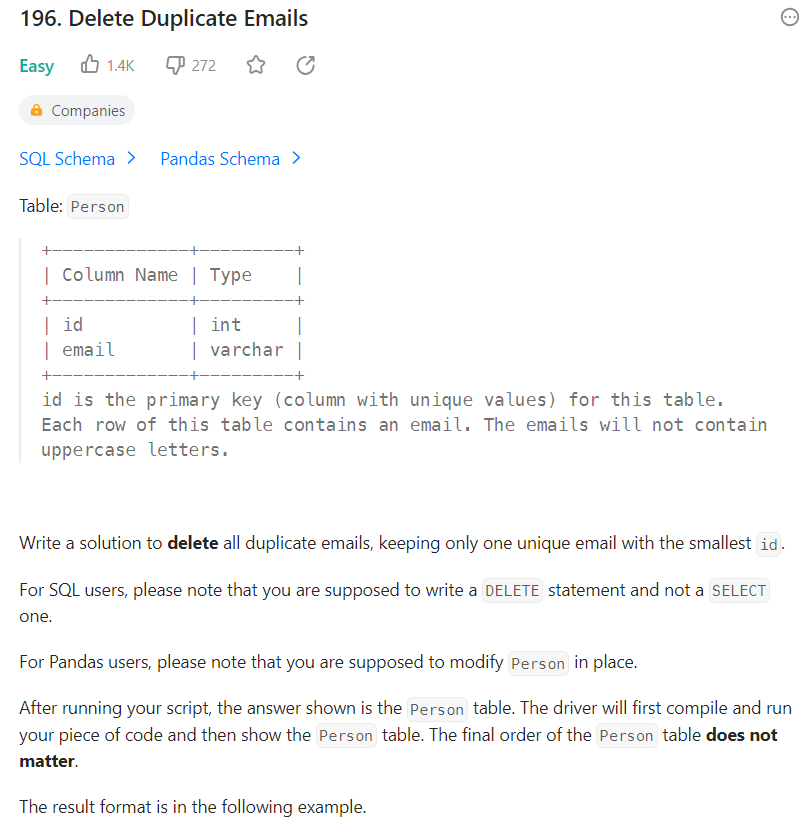
DELETE P1
FROM Person P1
INNER JOIN Person P2 ON P1.Email = P2.Email
WHERE P1.Id > P2.Id
셀프조인 결과값
->
제시된 SQL 쿼리에서 DELETE P1과 DELETE P2는 서로 다른 동작을 수행합니다. 이에 대한 이유는 SQL의 작동 방식과 조인된 테이블의 데이터에 따라 다릅니다.
DELETE P1을 사용한 경우:
이 쿼리는 "Person" 테이블에서 P1과 P2가 조인된 결과에 대해 조건 WHERE P1.Id > P2.Id를 만족하는 모든 레코드를 삭제합니다.
이렇게 하면 P1과 P2 모두에 해당하는 레코드가 삭제될 수 있습니다. 즉, 같은 이메일 주소를 가진 여러 사람 중에서 P1과 P2가 조건을 만족하는 경우 모두 삭제됩니다.
DELETE P2를 사용한 경우:
이 쿼리는 "Person" 테이블에서 P1과 P2가 조인된 결과에 대해 조건 WHERE P1.Id > P2.Id를 만족하는 모든 레코드를 삭제하지만, P2에 해당하는 레코드만 삭제합니다.
따라서 P1에 해당하는 레코드는 삭제되지 않고, P2에 해당하는 레코드만 삭제됩니다.
-> 이 부분 이해 완전히 안 됨. 다시 볼 것!


: 'DELETE t2 ~'일 경우, 2의 첫번째 행의 데이터만 삭제됨
배운점
-
FROM절 서브쿼리
: 연산한 결과물을 테이블로 다시 이용하고 싶을 때, FROM절에 ()로 감싸주고 테이블 명을 다시 지어주는 것
-
WHERE절 서브쿼리
: 쿼리의 결과물로 나온 것을 ()로 감싸고 그것과 같았으면 좋겠다고 구현.

-> 두번째 쿼리문
: 최근 5일동안 발생했던 범죄들을 레코드들을 다 보고 싶을 때 -
WHERE ~ IN ()
: 조건문인데 () 안에 여러 개중 하나라도 있었으면 좋겠다 싶을 때 쓰는 문법
SELECT Email, MIN(Id) AS min_id
FROM Person
GROUP BY Email: GROUP BY 해준 각 이메일이 가지고 있는 가장 작은 숫자의 아이디는 무엇인지 출력
-> john은 ID 1번,bob은 ID 2번 출력
- 'WHERE Id NOT IN' 뒤에 ()는 keeping 해야 하는 ID들.
