
이 글은 한 권으로 읽는 컴퓨터 구조와 프로그래밍을 읽고 정리한 내용입니다.
1. 병렬 컴퓨터 구조 – 왜, 어떻게 구성되는가?
멀티코어는 전혀 새로운 것이 아니며, 결국 병렬 컴퓨터 구조의 새로운 제조 형태일 뿐입니다.
과거에는 독립적으로 있었던 프로세서들이 반도체 기술 덕택에 하나의 칩에 제조될 수 있으니, 이것이 바로 멀티코어 프로세서의 탄생입니다. 따라서 병렬 컴퓨터 구조 자체를 먼저 살펴볼 필요가 있습니다.
1) 병렬 컴퓨터란?
여러 개의 **계산 장치(PE)**가 협력해 큰 문제를 더 빠르게 푸는 시스템
- 계산 장치를 모은다 (코어 집합)
- 서로 데이터를 주고받는다 (통신)
- 함께 문제를 푼다 (협력)
2) 어떤 계산 장치를 모을까?
| 유형 | 특징 | 예시 |
|---|---|---|
| 강력한 소수 코어 | 코어 수는 적지만 성능이 강력 | 데스크탑 CPU (듀얼/쿼드코어) |
| 작지만 다수 코어 | 단순한 코어를 수백~수천 개 | GPU |
| 이종 결합 | 성능 코어 + 효율 코어 | CPU + GPU 조합 (예: 스마트폰 SoC) |
현재 데스크탑에 쓰이는 듀얼/쿼드 코어는 수는 적지만 매우 강력한 코어를 모은 것입니다. 이 반대로 작지만 그 수가 많은 병렬 구조도 있어요.
대표적인 예가 바로 GPU인데, GPU는 간단한 구조의 작은 프로세서를 수백 개의 단위로 모아놓은 것이에요.
또한 어느 정도 강력한 코어 몇 개와 작지만 많은 코어를 섞어 놓을 수도 있습니다다. 혹은 전혀 다른 프로세서, 예를 들어 CPU와 GPU를 모아 멀티코어를 만들 수 있습니다.
3) 계산 장치 간의 통신 구조
서로 데이터를 주고받는 방식에 따라 구조가 달라집니다.
- 공유 메모리 구조: 같은 메모리 공간 공유 (ex. 다중 코어 CPU)
- 분산 메모리 구조: 각 프로세서가 메모리를 따로 가짐 (ex. 클러스터)
- 물리적 관점: 칩 내/칩 간/메모리 간 통신 → 인터커넥션 기술 중요
4) 계산 장치 간의 협력 방식
(1) 구조적 구분 – 플린(Flynn)의 분류
| 유형 | 설명 |
|---|---|
| SISD | 일반적인 단일 코어 |
| SIMD | 하나의 명령으로 여러 데이터 처리 (예: GPU 벡터 연산) |
| MISD | 여러 명령, 같은 데이터 처리 (거의 안 씀) |
| MIMD | 각각의 명령과 데이터를 병렬 처리 (멀티코어 CPU) |
(2) 실행 수준 – 병렬성의 세분화
| 수준 | 설명 |
|---|---|
| ILP (명령어 수준) | 싱글코어에서 내부 명령을 병렬 실행 |
| TLP (스레드 수준) | 여러 스레드를 동시에 실행 |
| ➕ 루프 수준 / 태스크 수준 / 프로그램 수준 병렬성도 존재 |
5) 병렬 메모리 구조 – 실제 멀티코어는 어떻게 구성되는가?
멀티코어가 병렬 컴퓨터 구조의 실현이라면, 그 구체적인 구현 방식은 메모리 구조와 크게 관련이 있습니다.
즉, 여러 계산 장치가 같은 메모리를 바라보느냐, 아니면 각자 고유의 메모리를 가지느냐에 따라 병렬 시스템의 동작 방식이 달라집니다.
(1) 공유 메모리 구조 – 함께 메모리를 본다
우리가 사용하는 대부분의 멀티코어 컴퓨터가 여기에 해당합니다. 여러 프로세서(코어)가 같은 주소 공간의 메모리를 공유합니다.
이 구조에서는 각 코어가 서로 동일한 메모리 공간에 접근할 수 있기 때문에 멀티스레드 프로그래밍이 자연스럽습니다.
또한 이 공유 메모리 구조는 다음과 같이 세부 구현 방식에 따라 나뉘게 됩니다:
▸ 칩 멀티프로세서 (CMP)
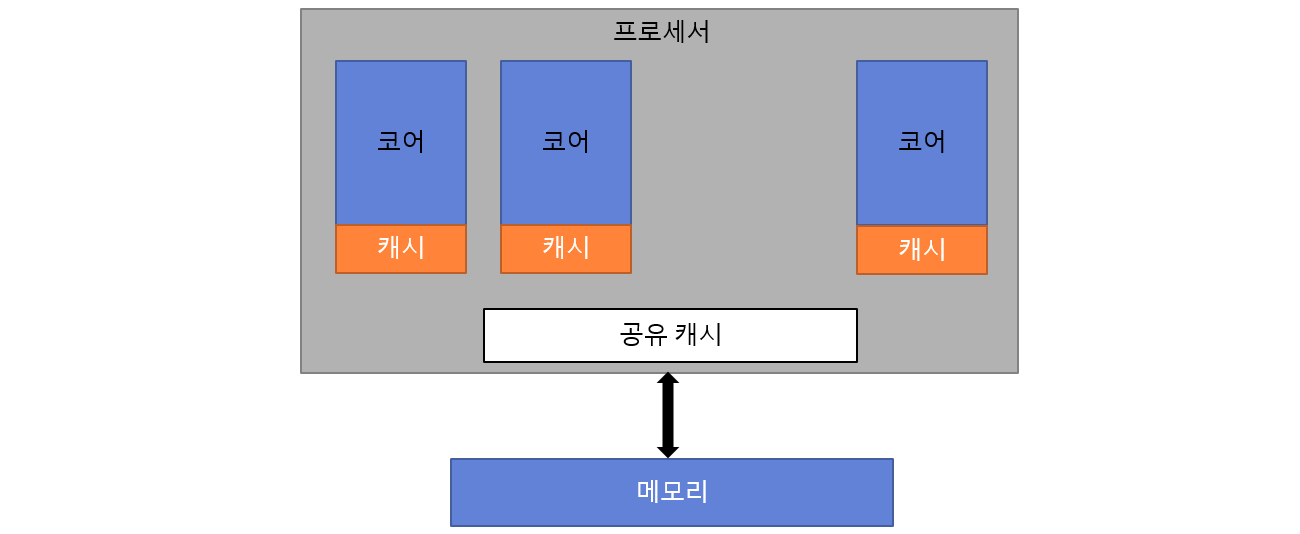
- 하나의 칩 안에 여러 개의 코어를 집적한 구조입니다.
- 코어 간 거리가 가까워, 공유 캐시 구조를 활용할 수 있습니다.
- 현재 우리가 사용하는 대부분의 멀티코어 CPU(Intel, AMD)는 CMP 구조입니다.
▸ 대칭형 멀티프로세서 (SMP)
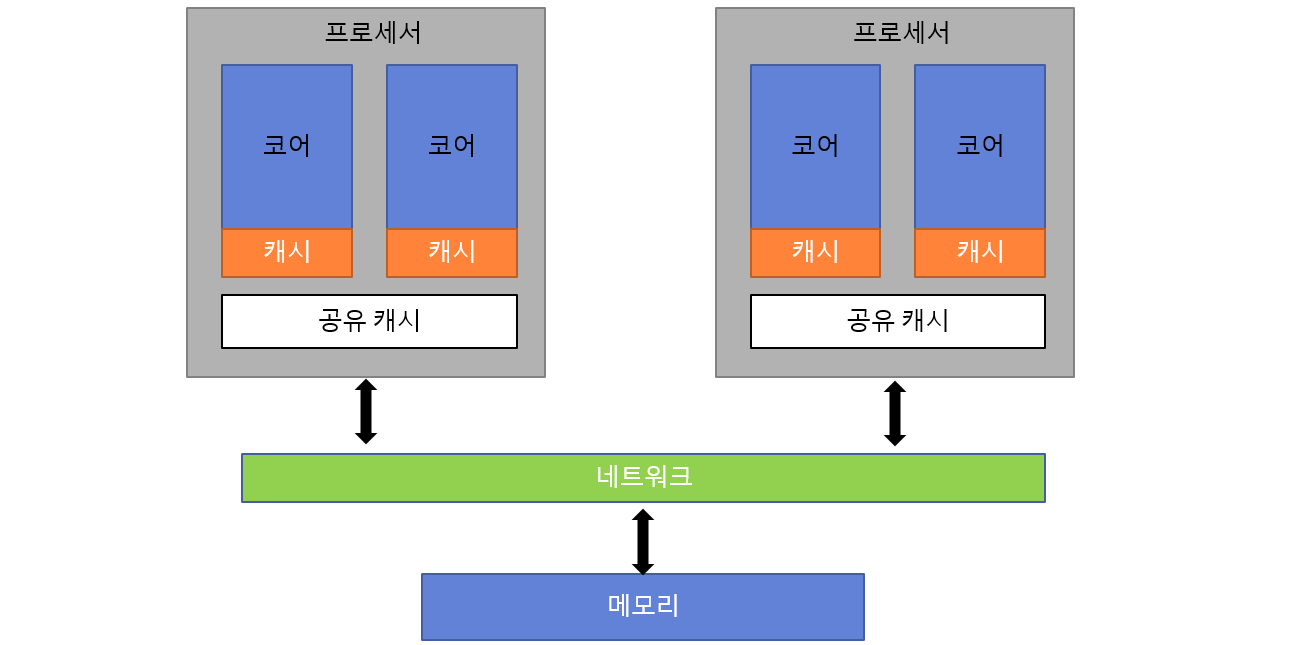
- 서버용 메인보드에서 흔히 볼 수 있는 구조로, 동일한 종류의 CPU를 여러 개 장착합니다.
- 개념적으로 CMP와 같지만, 물리적으로 다른 소켓에 분산된 프로세서들이 네트워크를 통해 연결됩니다.
- 예전에는 FSB(Front Side Bus), 요즘은 QPI(Intel), HTT(AMD) 같은 인터커넥션이 사용됩니다.
▸ 분산 공유 메모리 (NUMA)
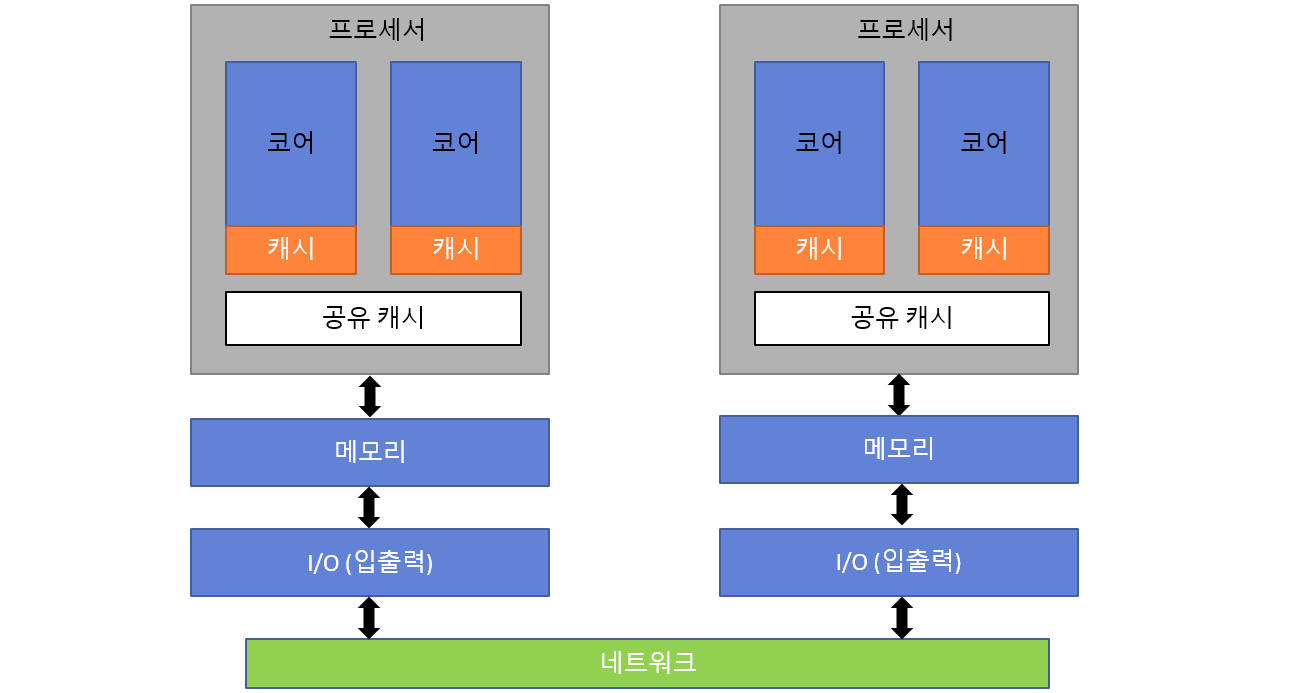
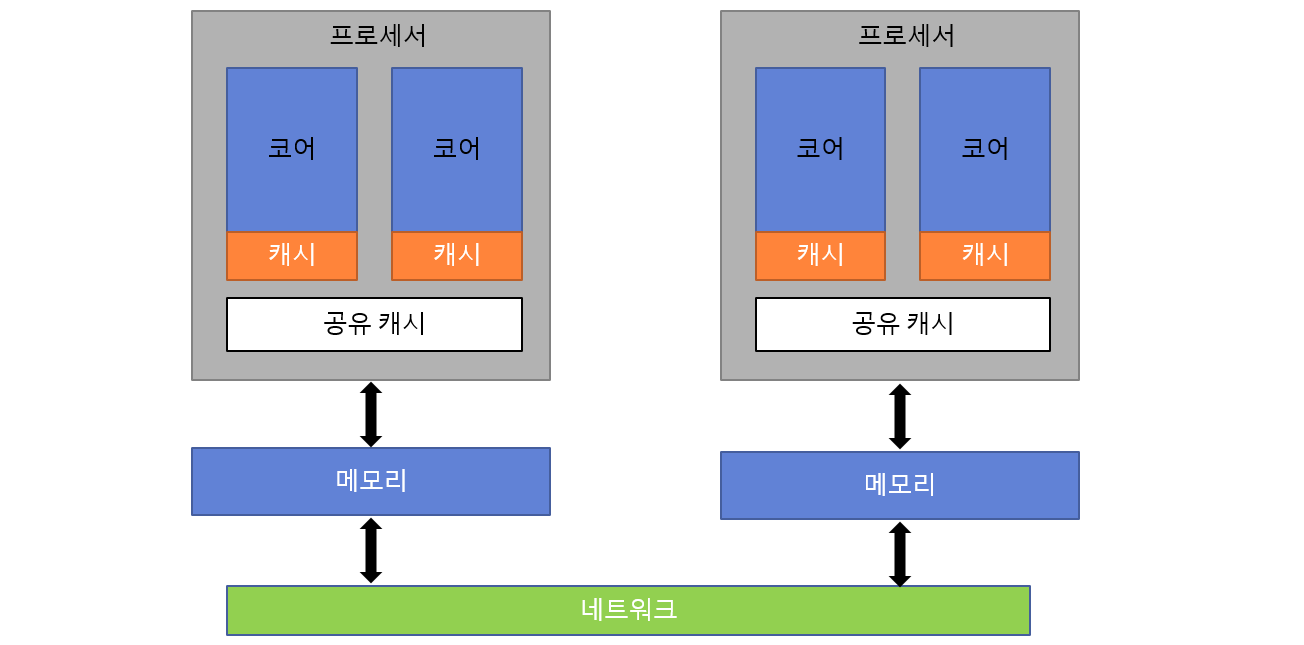
- 대규모 시스템에서 사용하는 구조입니다.
- 전체 메모리 주소 공간은 논리적으로 공유되지만, 물리적으로는 프로세서마다 메모리가 분산되어 있습니다.
- 예: 64개 CPU를 가진 서버 → 내 코어에 가까운 메모리는 빠르게 접근 가능, 먼 메모리는 느림 → 메모리 접근 속도가 비균일해지는 구조.
✅ NUMA는 확장성과 성능을 동시에 고려한 구조로, 멀티코어 최적화 시 반드시 고려해야 하는 아키텍처입니다.
(2) 분산 메모리 구조 – 각자 메모리를 갖는다
각 프로세서가 독립적인 메모리를 갖고 있으며, 서로 데이터를 주고받기 위해선 반드시 명시적 메시지 교환이 필요합니다.
이 구조는 흔히 클러스터, 그리드 컴퓨팅, 슈퍼컴퓨터에서 사용됩니다.
수천~수만 개의 노드로 구성되며, 프로그래밍 방법도 완전히 달라집니다.
- 프로세서 간에는 고속 네트워크가 필요하며, 대표적인 예로 **MPI (Message Passing Interface)**를 사용합니다.
- 로컬 메모리 접근은 빠르지만, 다른 노드 메모리에 접근할 경우 명시적인 네트워크 통신이 필요하므로 더 느립니다.
✅ 마무리
이처럼 병렬 메모리 구조는 멀티코어 프로세서가 어떤 방식으로 데이터를 공유하고 처리할지 결정하는 핵심 요소입니다.
멀티코어는 단순히 코어가 여러 개라는 의미를 넘어서, 그 내부에서 어떤 구조로 연결되고, 어떤 방식으로 협력하는가에 따라 성능과 동작 방식이 크게 달라집니다.
이처럼 병렬 컴퓨터는 다양한 방식으로 계산 장치를 구성하고 협력하게 만들어 더 빠른 처리를 가능하게 해줍니다.
그리고 이 병렬 구조의 핵심 개념은, 이제 하나의 칩에 여러 코어를 집적한 멀티코어 프로세서라는 형태로 우리 일상 속 컴퓨터나 스마트폰 안에 구현되고 있죠.
그렇다면, 멀티코어는 구체적으로 어떻게 동작하고, 어떤 병렬 처리를 가능하게 하는 걸까요? 이제부터 멀티코어 시스템 내부를 좀 더 깊이 들여다보겠습니다.
2. 멀티코어 시대의 두 얼굴 – 협력과 충돌
1) 지금 이 순간, 컴퓨터는 '진짜'로 여러 일을 동시에 하고 있다
불과 몇십 년 전까지만 해도, 컴퓨터는 사실상 멀티태스킹의 흉내만 내고 있었습니다. CPU는 단 하나였고, 여러 프로그램을 조금씩 번갈아 실행하며 동시성처럼 보이게 만들었죠.
하지만 이제는 다릅니다. 여러분이 쓰는 스마트폰, 노트북, 심지어 냉장고조차도 멀티코어 시스템입니다.
멀티프로세싱(Multiprocessing)은 더 이상 슈퍼컴퓨터의 전유물이 아닙니다.
여러분의 손안에서 이미 ‘진짜 동시 실행’이 일어나고 있습니다.
2) 멀티코어 vs 멀티 프로세서 – 차이점과 시스템 활용
물론입니다. 아래는 해당 글의 내용을 핵심적으로 정리한 내용입니다. 멀티코어와 멀티 프로세서의 차이, 장단점, 그리고 멀티 프로세서를 활용한 시스템 구조까지 정리했습니다.
핵심 개념 비교
| 항목 | 멀티코어(Multi-Core) | 멀티프로세서(Multi-Processor) |
|---|---|---|
| 구조 | 하나의 CPU 안에 여러 개의 코어 탑재 | CPU 자체가 여러 개 존재 (물리적으로 분리된 CPU들) |
| 속도 | 코어 간 데이터 공유가 빠름 (같은 칩 내부 공유 캐시 활용) | CPU 간 통신은 느림 (버스 공유, 메모리 접근 경합 발생) |
| 전력 효율 | 전력 소비가 적고 열 방출도 적음 | CPU가 많아질수록 전력 소비와 발열 증가 |
| 일관성 문제 | 코어 간 캐시 일관성 유지가 상대적으로 쉬움 | 각 CPU의 캐시 일관성 문제 발생 가능 |
| 확장성 | 물리적 제약이 있으므로 확장 한계 존재 | CPU를 더 추가하면 병렬 성능을 계속 확장할 수 있음 |
| 사용 예 | 일반 데스크탑, 스마트폰, 노트북 등 | 서버, 고가용성 시스템, 클러스터, 클라우드 인프라 등 |
멀티코어 – 하나의 칩, 여러 개의 코어
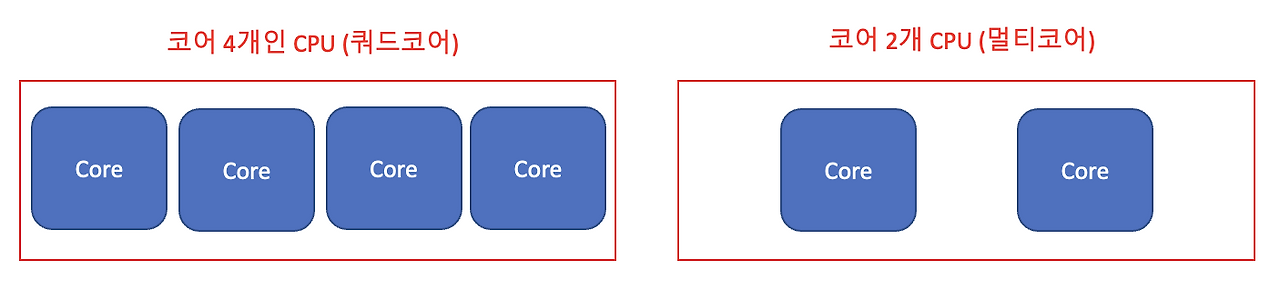
하나의 CPU 내부에 두 개 이상의 독립적인 core가 있는 기술.
- 연산 결과나 캐시 데이터 공유가 빠르며 전력 효율도 높음
- 일반적인 개인용 컴퓨터, 모바일 장치 등에서 사용됨
- 하나의 core 처리하는 작업을 여러 개의 core가 분담하여 처리 가능.
멀티프로세서 – 여러 개의 CPU를 함께 쓰기
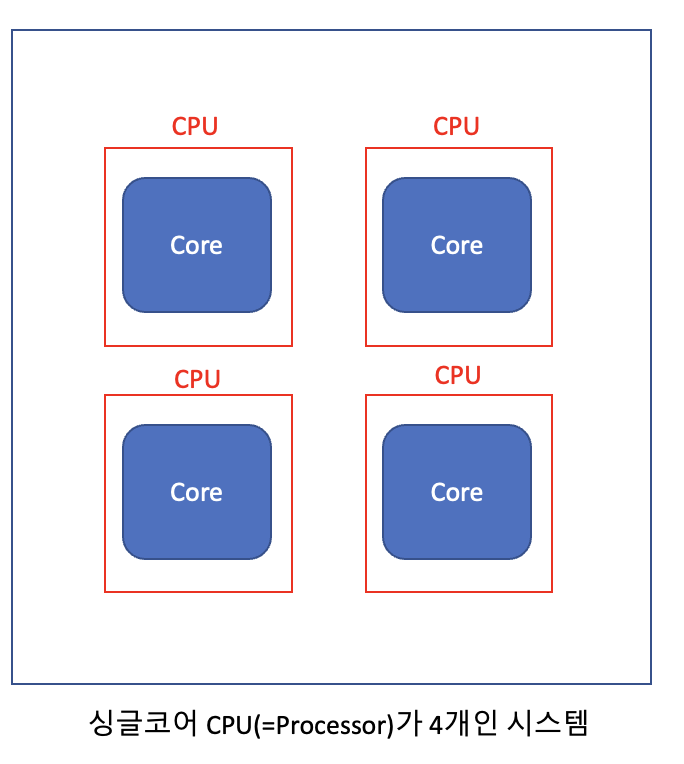
여러 개의 Processor(=CPU)를 사용하는 것.
- 여러 개의 CPU가 각각 독립적으로 작업을 처리.
- 물리적으로 분리된 CPU들이 같은 시스템에서 협력
- 고성능 서버, 고가용성 시스템에 주로 사용
- 단점: 메모리 공유 시 병목 현상, 캐시 불일치, 자원 경합
최근 멀티 프로세서의 시스템이 각광받고 있는데, 그 이름은 바로 클라우드입니다.
클라우드의 정의란, 여러 개의 분산 시스템을 하나의 자원으로 묶어서, 컴퓨팅 자원을 활용하는 방식입니다.
하나의 컴퓨터 내의 멀티 프로세서를 사용하는 경우는 여러 가지 단점들이 존재하지만, 분산된 시스템을 멀티 프로세서 개념으로 묶어서 처리한다면, 멀티 프로세서의 단점은 없어지고 장점이 더 돋보이게 됩니다.
출처 : 멀티 프로세서와 멀티 코어의 차이점
멀티코어프로세서(Multi-core processor)
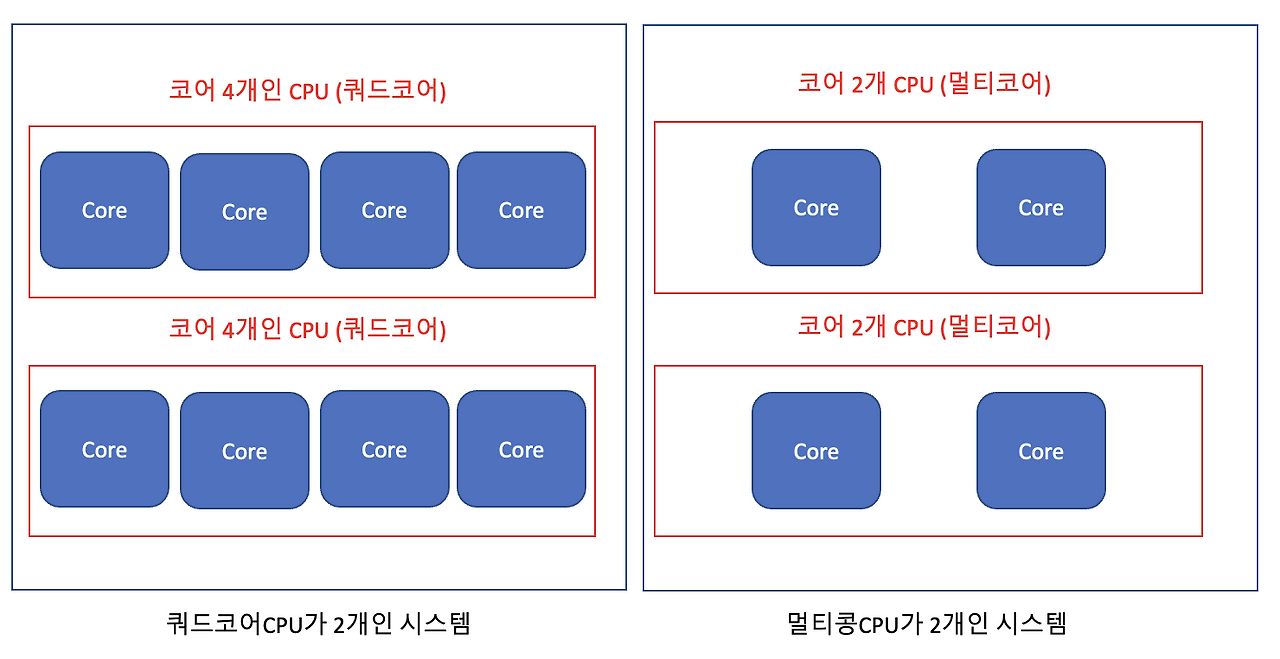
- 멀티코어 + 멀티프로세스
- 하나의 CPU 내부에 두개 이상의 core가 있고, 이러한 멀티코어 CPU가 여러 개 존재.
멀티프로세서 기반 시스템 구조
(1) SMP (대칭형 멀티프로세서)
- 각 CPU가 메모리와 버스를 공유
- 서로 대등한 관계로 모든 작업을 처리 가능
- 캐시 공유 또는 독립 → 구조적으로 CMP와 유사
- 예: 일반적인 멀티코어 CPU 기반 서버
(2) Blade Server
- 하나의 프레임 위에 프로세서/스토리지/네트워크 보드들을 집약
- 공간 절약, 모듈화된 서버 형태
(3) 클러스터 시스템
-
여러 독립 컴퓨터를 LAN으로 연결하고, 마치 하나의 컴퓨터처럼 동작
-
고가용성(HA) 제공 목적 → 장애 대비 구조 구성 가능
-
종류
- 대칭형 클러스터링: 모든 머신이 서비스 구동, 서로를 모니터링
- 비대칭형 클러스터링: 한 머신이 서비스, 다른 머신이 감시 후 대체
(4) 클라우드 컴퓨팅
- 클러스터 개념을 전 세계 분산 환경으로 확장
- 이기종 시스템 간에도 자원을 통합, 가상화하여 유연하게 운영
- 클러스터와 달리, 물리적 위치나 장치의 동질성 제약 없음
| 용어 | 설명 |
|---|---|
| Fail-over | 한 시스템이 실패할 경우, 다른 시스템이 즉시 이를 대체 |
| Graceful Degradation | 일부 시스템 장애에도 전체 서비스가 완전히 중단되지 않도록 함 |
| Fault Tolerant | 장애 발생 시에도 시스템이 정상 작동하도록 설계 |
| SAN(Storage Area Network) | 고속 네트워크로 스토리지를 클러스터링하여 공유 |
멀티코어와 멀티프로세서는 하드웨어의 병렬성을 실현하는 방식이며, 각각 장단점과 활용처가 다릅니다.
클라우드 시대에서는 이 개념들이 분산 시스템, 고가용성 구조와 결합되어 더욱 확장된 형태로 사용됩니다.
기본 구조의 차이를 이해하면, 클라우드, 고가용성, 병렬 컴퓨팅 등 다양한 시스템 아키텍처를 더 잘 설계하고 이해할 수 있습니다.
3) 동시에 실행되면, 동시에 꼬일 수도 있다 – 경합 조건의 공포
멀티코어가 멋지기만 한 건 아닙니다. 처리 순서가 중요한 작업에서는 '동시 실행'이 오히려 독이 되기도 하죠.
📦 실생활 예시: 공동 계좌에서 돈 빼기
- 현재 잔고: 100만 원
- 배우자는 ATM에서 75만 원 인출 중
- 여러분은 은행 창구에서 50만 원 인출 시도 중
💥 만약 동시에 인출을 허용한다면?
- 총 인출: 75 + 50 = 125만 원
- 계좌 잔고: -25만 원 → 초과 인출(overdraw)! ❌
이 문제는 바로 **Race Condition (경합 조건)**이라고 합니다.
둘 이상의 연산이 같은 자원을 동시에 사용하려 할 때, 실행 순서에 따라 결과가 달라지는 오류죠.
4) 프로세스의 진화 이야기: 옛날 옛적 CPU 나라에서
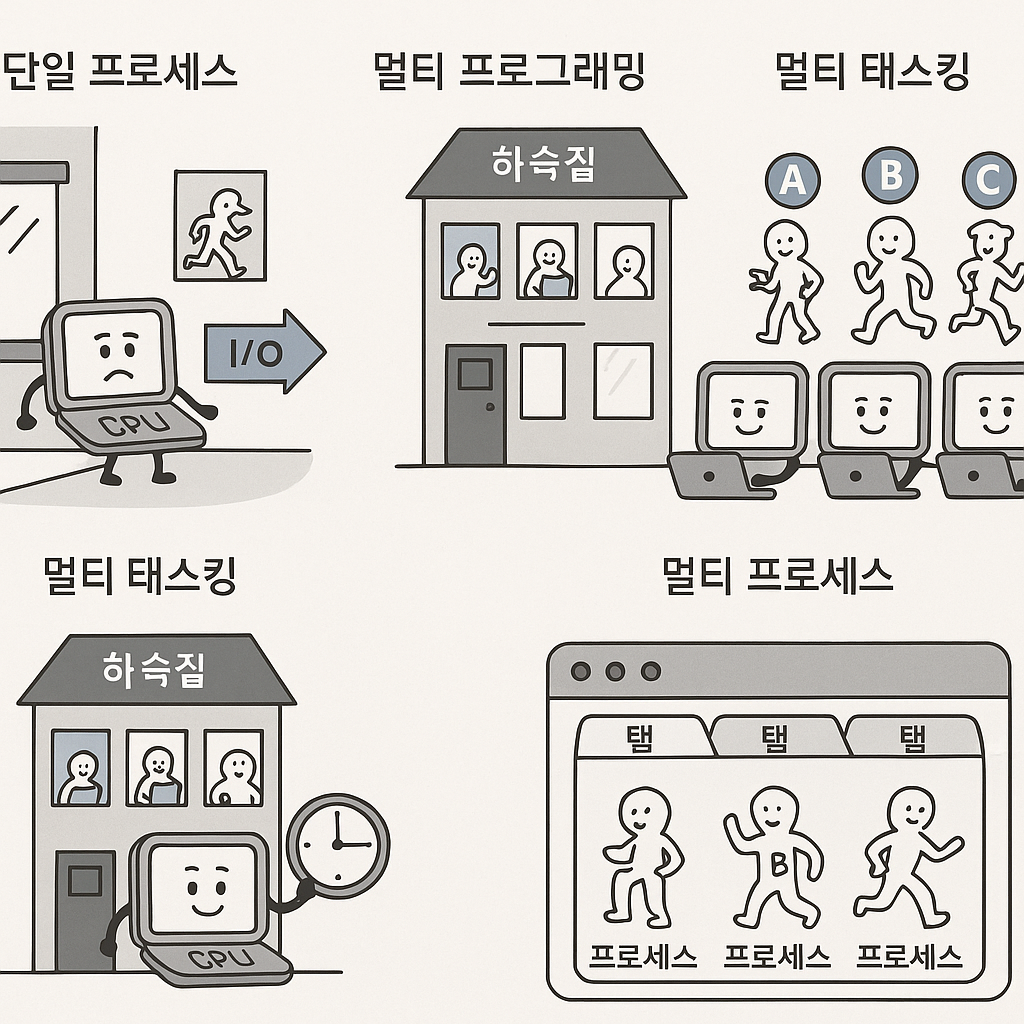
(1) 단일 프로세스 시대 – “혼자 사는 집 CPU 씨”
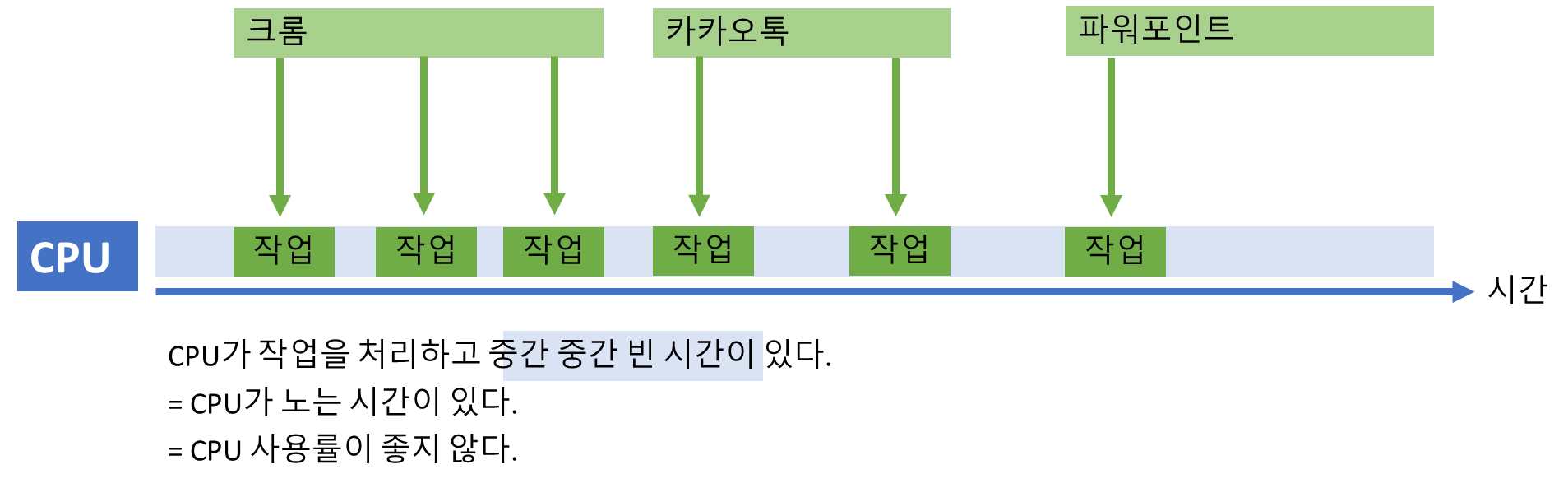
옛날 옛적, CPU 나라에는 혼자 사는 CPU 씨가 있었습니다.
그는 매우 착하고 성실한 친구였지만, 한 번에 단 한 손님만 집에 들일 수 있었어요.
예를 들어, A라는 손님이 집에 와서 요리를 하다가, **식재료가 다 떨어져 시장(I/O)**에 가버리면…
CPU 씨는 빈 집에서 멍하니 기다려야 했죠.
"이거 너무 비효율적인데… 누가 시장 갔는지 알면서도 멍하니 기다리는 나…"
이것이 바로 단일 프로세스 시스템입니다.
- 한 번에 하나의 작업만 처리 가능
- I/O 작업 중에는 CPU가 아무 일도 못하고 멈춤
💡 I/O란?
- 키보드/마우스 입력
- 파일 읽고 쓰기
- 네트워크 통신 등
즉, CPU 외의 다른 장치와 데이터를 주고받는 행위를 말합니다.
(2) 멀티 프로그래밍 – “하숙생을 들이기 시작한 CPU 씨” (시간제한 없음, 아직은 동시처리 아님)
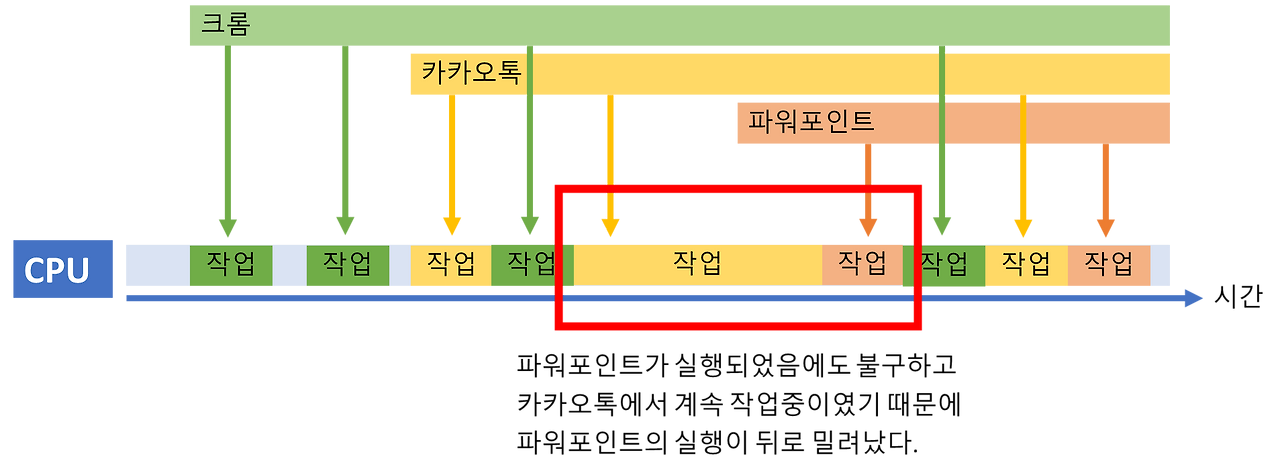
어느 날, CPU 씨는 친구의 조언을 듣고 이렇게 말했어요.
“그래! 집에 여러 명을 들여놓고 빈 시간 없이 번갈아 일 시키면 되잖아!”
그는 이제 하숙생(A, B, C…)을 여러 명 들였습니다.
A가 요리하다 식재료 사러 가면, 곧바로 B가 청소를 시작합니다.
B가 빨래를 하러 나가면, 다시 돌아온 A가 일을 이어가는 식이죠.
이것이 바로 멀티 프로그래밍(Multi Programming입니다.
- 여러 프로그램을 메모리에 동시 탑재
- CPU는 하나지만, I/O 중 대기 없이 다른 작업 전환
- 목표: CPU 낭비 최소화
하지만 문제가 하나 있었죠…
A라는 하숙생이 말이 너무 많아 요리를 엄청 오래하면?
“내 차례는 도대체 언제 오는 거야!” – B의 분노 😡
아무래도 CPU의 처리속도가 빠르다보니 번갈아가면서 처리하는 것이 우리 눈에는 "동시에" 처리되는 것으로 보이지만 실제로 "동시에"는 아니다!
(3) 멀티 태스킹 – “정확한 시간표로 돌아가는 CPU 씨네 하숙집”(시간제한 있음, 아직은 동시처리 아님)
그래서 CPU 씨는 큰 결심을 했습니다.
모든 하숙생에게 공정한 시간표를 나눠주기로요.
“너희 모두 1분씩만 써! 시간 되면 바로 바꾸자!”
이제 A가 요리하다 1분이 지나면 B가 청소, C가 세탁기 돌리기를 하며
작업이 교대로, 빠르게 이어졌죠.
이 방식이 바로 멀티 태스킹(Multi Tasking)입니다.
- 각 작업에게 시간 조각(= 타임 슬라이스)을 분배
- 시간 단위로 빠르게 작업 교체
- 사용자 입장에선 동시에 실행되는 것처럼 보임
💡 핵심 개념: 문맥 교환 (Context Switching)
- CPU가 작업을 바꿀 때 A의 상태를 저장, B의 상태를 복원해야 함
- 이 과정이 무겁기 때문에 너무 자주 바꾸면 오히려 손해
(4) 멀티 프로세싱 – “여러 명의 CPU 씨가 사는 연립 하숙촌”
시간이 흐르고, CPU 씨는 쌍둥이 형제들과 함께 살기로 합니다.
A CPU, B CPU, C CPU…
이제는 A가 요리하고, B가 청소하고, C가 빨래를 동시에!
이것이 바로 **멀티 프로세싱(Multi Processing)**입니다.
- CPU(코어)를 여러 개 사용
- 진짜 병렬 처리 가능
- 4코어 8스레드 같은 구조
💡 비유:
- 멀티 태스킹 = 한 사람이 빠르게 여러 일 처리
- 멀티 프로세싱 = 여러 사람이 동시에 다른 일 처리
(5) 멀티 프로세싱 + 멀티 태스킹 – “꿈의 CPU 마을”
현대의 컴퓨터는 이 둘을 동시에 사용합니다.
각 CPU는 멀티 태스킹을 수행하고,
여러 CPU는 멀티 프로세싱으로 병렬 작동!
| 방식 | 구성 | 설명 |
|---|---|---|
| 멀티 태스킹 | 1 CPU + 여러 작업 | 시간 분할 처리 |
| 멀티 프로세싱 | 여러 CPU | 병렬 작업 처리 |
| 둘의 조합 | 여러 CPU + 각 CPU가 멀티 태스킹 | 동시에 여러 작업 + 빠른 응답성 |
(6) 멀티 프로세싱 vs 멀티 프로세스 – “CPU냐, 프로그램이냐”
여기서 헷갈리기 쉬운 개념!
멀티 프로세싱 vs 멀티 프로세스
| 구분 | 의미 | 목적 | 예시 |
|---|---|---|---|
| 멀티 프로세싱 | 여러 CPU 사용 | 빠른 병렬 처리 | 4코어 CPU |
| 멀티 프로세스 | 하나의 프로그램이 여러 프로세스로 구성됨 | 안정성, 격리성 확보 | 크롬 브라우저 (탭마다 프로세스 분리) |
즉, 하나는 하드웨어가 멀티이고,
다른 하나는 프로그램(소프트웨어)이 멀티입니다.
🔍 요약 정리
| 용어 | 핵심 개념 | 특징 |
|---|---|---|
| 단일 프로세스 | 하나의 프로그램만 실행 | I/O 동안 CPU는 멈춤 |
| 멀티 프로그래밍 | 여러 프로그램을 메모리에 올림 | I/O 대기 중 다른 작업 실행 |
| 멀티 태스킹 | 작업 시간 쪼개서 번갈아 처리 | 문맥 교환 필요, 응답성 향상 |
| 멀티 프로세싱 | 여러 CPU 코어가 병렬 처리 | 성능 향상, 진짜 동시에 실행 |
| 멀티 프로세스 | 프로그램이 여러 프로세스로 나뉨 | 안정성 향상, 예: 웹 브라우저 |
위의 경우, 하나의 주문에 하나의 작업대를 무조건 만들어야 합니다. 즉, 100개의 햄버거를 만들기 위해서는 100개의 작업대가 필요하다는 것이죠..
이번 단체 주문은 햄버거 100개를 한꺼번에 주문했네요. 그런데 각 요리마다 작업대를 새로 깔려고 하는게 여간 시간이 오래 걸리는 일이 아니었습니다. 100개의 작업대를 순서대로 깔다가 지친 커넬은 다시 고민에 빠지게 됩니다.
“어차피 레시피랑 재료는 같은데, 한 작업대에서 같은 요리를 여러 개 만들 수 있지 않을까?”
비슷한 작업을 반복하는 거면 굳이 새 작업대를 깔 필요도 없었고, 한 작업대에서 음식을 조리하니 시간도 절약되었죠.
뭔가 깨달은 커널은 커널은 새 요리사를 한 명 더 고용했습니다. 이제 주방에는 두 명의 요리사가 있습니다. 커널은 두 요리사에게 하나의 작업대만 갖다주며 이야기합니다.
“햄버거를 100개 만들어야 하는데, 어차피 레시피랑 재료가 같잖아? 작업대를 100개 깔면 시간이 오래 걸리니까 이번에는 한 작업대에서 각각 50개씩 햄버거를 만들도록 해.”
이 명령을 들은 CPU들은 요리해야 할 양을 절반씩 나누어 만들기 시작합니다. 뭐, 커널의 말대로 레시피랑 재료가 같으니 그저 각자 조리 중인 햄버거가 섞이지 않게만 조심하면 문제가 없을 것 같네요. 친절한 커널은 CPU를 배려해서, 하나의 작업대에서 여러 요리를 만들 때에도 주문표에 각 요리사들이 어디까지 조리를 했는지를 적어줍니다
-
쓰레드(Thread) 는 프로세스 내에서 실행되는 CPU 스케줄링의 기본 단위이다. 하나의 프로세스 내에서 여러 개의 쓰레드가 실행될 수 있으며 이를 멀티 쓰레드 라고 부른다.
-
각 쓰레드는 자기 자신만의 실행 컨텍스트를 가질 수 있기 때문에, 서로 다른 CPU에서도 동작할 수 있다. 이 덕분에 여러 CPU를 단일 회로로 통합한 멀티 코어 프로세서를 이용하면 물리적으로 병렬 처리가 가능하다.
-
기본적으로 하나의 프로세스 내에서 실행되는 각 쓰레드는 프로세스의 메모리를 공유한다. 하지만 쓰레드 별로 실행 중인 코드 위치와 컨텍스트가 다를 수 있기 때문에, 프로그램 카운터는 따로 저장하고 스택은 분할해서 사용한다.
-
각 쓰레드의 정보를 저장하기 위해 커널은 쓰레드 제어 블록(TCB, Thread Control Block) 을 만들어 PC 메모리에 저장한다.
5) 멀티 작업에서 경합 조건 어떻게 해결할까? 락과 동기화의 필요성
이런 상황을 막기 위해, 우리는 ‘락(Lock)’이라는 개념을 도입합니다.
계좌 인출 코드처럼 서로 영향을 주는 연산은 한 번에 단 한 사람만 접근할 수 있게 막는 것이죠.
🔒 한 사람의 인출이 끝나기 전까지, 다른 사람은 잠깁니다.
→ 이것이 동기화(synchronization)의 핵심입니다.
요약: 협력과 충돌의 균형
| 항목 | 설명 |
|---|---|
| 멀티태스킹 | 여러 작업을 동시에 처리 (진짜 동시 또는 번갈아 실행) |
| 멀티프로세싱 | 실제로 여러 CPU/코어가 동시에 실행 |
| 경합 조건 | 여러 작업이 공유 자원에 동시에 접근해 실행 순서에 따라 결과가 달라지는 현상 |
| 락(Lock) | 공유 자원에 한 번에 한 작업만 접근하도록 막는 장치 |
| 문제점 | 락이 너무 많아지면 → 속도 느려짐, 락이 없으면 → 에러 발생 |
“멀티코어는 강력하지만, 우리가 신중하지 않다면 서로 충돌하고 말 것이다.”
– 병렬성의 이득은 동기화의 대가를 감수할 준비가 될 때 비로소 온전히 누릴 수 있습니다.
읽어보면 좋은 글 : 레스토랑에 비교해서 알아보는 운영체제
3. 경합 조건(Race Condition)과 스레드의 세계
1) 경합 조건이란?
- 정의: 둘 이상의 프로그램(또는 스레드)이 같은 자원에 동시에 접근할 때, 실행 순서에 따라 결과가 달라지는 현상
- 예시: 두 프로그램이 동시에 은행 계좌에 입금할 경우, 타이밍에 따라 최종 잔액이 달라질 수 있음
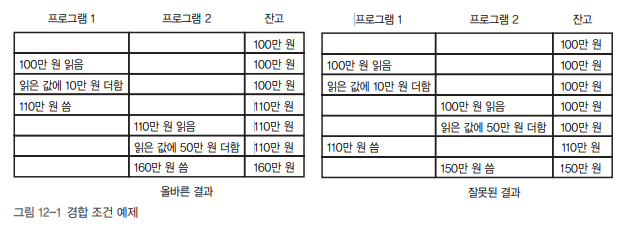
- 잘못된 결과: 입금 전후 순서가 꼬여, 일부 입금이 반영되지 않음
2) 공유 자원(shared resource)
- 대표 예: 메모리, I/O 장치(프린터, USB), FPGA, 네트워크 소켓 등
- 메모리 공유는 직접적인 충돌을 일으킬 수 있음
- 운영체제는 사용자 대신 일부 I/O 작업을 처리해 충돌을 방지하려 함
3) 프로그램이 어떻게 같은 데이터를 공유할까?
-
프로세스는 독립된 메모리 공간을 사용하지만,
공유 자원을 사용하려면 반드시 통신(IPC) 또는 공유 메모리 등으로 연결되어야 함. -
병렬 실행이 무조건 경합 조건을 만드는 건 아님.
자원을 공유해야만 경합이 발생함.
프로세스는 자원을 마법처럼 공유하지 못한다
-
서로 다른 프로세스가 자원을 공유하려면 명시적으로 설정되어야 함.
-
대표적인 자원 공유 예:
- 프린터, USB 컨트롤러, FPGA 같은 하드웨어
- 공통 설정 파일, 공용 메모리 블록
3) 프로세스 vs 스레드
스레드(Thread)의 탄생과 구조
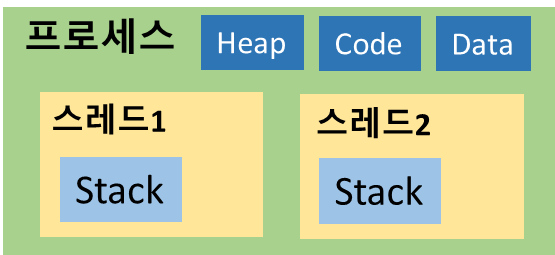
-
프로세스 안에서 여러 작업을 병렬로 처리할 수 있게 해주는 실행 단위
-
스레드는 다음을 공유함:
- 정적 데이터 영역
- 힙 메모리
-
하지만 스택과 **레지스터(문맥 상태)**는 각 스레드가 별도로 소유
📌 그래서 스레드는 하나의 프로그램 안에서 자체 흐름을 갖는 독립 실행 경로입니다.
스레드? 프로세스 안에 여러 작업자를 만들어서 동시에 작업하자는 것이에요.
1명이 3가지 역할을 가지고 있기보단, 3명이 1가지 역할을 맡는 것처럼 스레드는 여러 작업 중에 하나를 맡아 할 사람을 추가하는 것입니다.
기존의 프로세스 개념만 있었을때는
프로세스자체가 작업을 처리하는 단위였지만, 이제 프로세스는 스레드를 감싸는 "컨테이너"의 개념이 되었고
스레드가 작업을 처리하는 단위로 바뀌었습니다.
| 항목 | 프로세스 | 스레드 |
|---|---|---|
| 메모리 공간 | 독립적 | 같은 프로세스 내 공유 |
| 문맥 전환 비용 | 높음 | 낮음 (경량 프로세스) |
| 사용 예 | 독립 실행 프로그램 | 병렬 처리, 핸들러 분리 |
- 스레드는 독립적인 스택, 프로그램 카운터, 레지스터 상태를 갖고 있음
- 힙, 정적 데이터는 공유
4) 스레드 문맥 전환
- 스레드는 CPU 레지스터만 저장/복원하면 되므로 프로세스보다 훨씬 빠름
- 이 점 때문에 스레드를 **lightweight process (경량 프로세스)**라고 부름
5) 스레드 사용 시의 문제점 (주의사항)
- ❗ 보안 위험: 스레드는 데이터 공유 → 악의적 접근 or 무결성 훼손 가능
- ❗ 신뢰성 저하: 한 스레드가 문제 생기면 전체 프로세스 멈춤 가능
- ❗ 리소스 고갈: 한 스레드의 무한 루프 → 전체 시스템 반응 저하
6) 역사적 배경과 GUI의 등장
- 과거: 스레드 기반 단순한 서버 구조 (ex. 프린트 서버)
- 현재: GUI와 이벤트 기반 프로그래밍은 복잡한 액티비티 대기와 재개 필요
- 해결책: 핸들러마다 별도 스택 → 스레드 구조 도입
4. 병렬 프로그래밍의 진짜 적 – 공유 자원이 아니라 원자성(Atomicity) 이다

1) 문제의 본질은 "공유 자원"이 아니라 원자적 처리
우리(개발자)가 실제로 처리해야 할 문제는 공유 자원이 아닌, 실제로 처리해야 할 문제는 여러 작은 연산으로 이뤄진 작업을 어떻게 원자적(Atomic) 으로 만들 수 있을까 하는 문제를 다뤄야 한다고 합니다.
저자는 컴퓨터에 '은행 잔고를 조정하라' 와 같은 명령어가 있다면 위와 같은 문제를 논할 필요도 없을 것이라고 합니다.
- 경합 조건은 결국 여러 연산이 중간에 끊기지 않고 하나처럼 실행되어야 할 때 발생
- 컴퓨터에 “잔고 갱신” 같은 명령이 하나의 원자 연산으로 존재하지 않기 때문에 생김
2) 그렇다면 어떻게 원자적으로 만들 수 있을까..? 원자적 처리란 뭘까?
중간에 나눌 수 없고 인터럽트되지 않는 연산 블록
예:읽기 → 계산 → 쓰기가 중간에 끊기면 잘못된 결과 발생
먼저 정리부터: 공유 자원 vs 원자성 문제
| 구분 | 설명 |
|---|---|
| 공유 자원 문제 | 여러 스레드/프로세스가 같은 데이터(메모리, 프린터 등)를 접근함 |
| 원자성 문제 | 연산이 중간에 끊기지 않고 한 덩어리로 실행돼야 하는데, 그렇지 못해서 문제가 생김 |
“공유 자원만 조심하면 돼!” → ❌ 틀린 말
“공유 자원을 어떻게 끊기지 않게 다룰까?” → ✅ 정확한 고민
🔍 예시: 은행 잔고 입금
상황:
- 잔고: 100만 원
- 두 스레드가 동시에 입금 요청
프로그램 A
잔고를 읽음 → 100만 원
+ 10만 원 → 110만 원
잔고에 씀 → 110만 원 프로그램 B
잔고를 읽음 → 100만 원
+ 50만 원 → 150만 원
잔고에 씀 → 150만 원 이 두 연산이 동시에 실행되면?
A와 B가 동시에 읽음 → 둘 다 100만 원으로 읽음
A가 먼저 씀 → 110만 원 됨
B가 나중에 씀 → 150만 원 됨 (A의 결과 덮어씀)❌ 결과: 입금 60만 원인데, 실제로는 50만 원만 반영됨
핵심은 “읽기 → 계산 → 쓰기” 이 세 단계를 하나의 블록처럼 묶어야 한다는 것
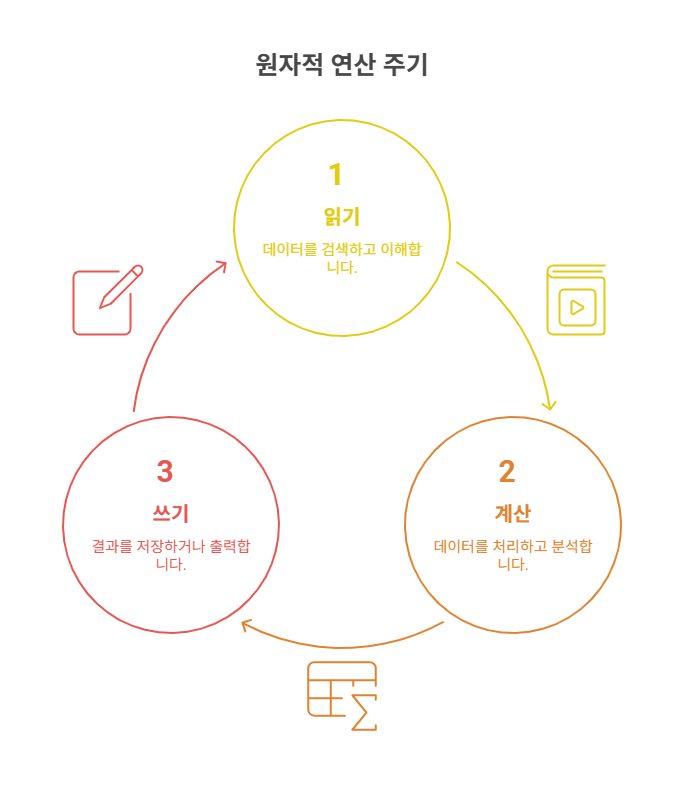
이 세 단계를 중간에 끊을 수 없게 해야 해요.
그게 바로 원자적(Atomic) 연산이라는 거예요.
그래서 결론은?
“우리 개발자가 처리해야 할 진짜 문제는
‘데이터 공유 자체’가 아니라
그 데이터를 다루는 연산 블록이 원자적이지 않다는 것이다.”
- CPU는
잔고를 조정하라는 명령어를 하나로 실행할 수 없음 - 우리는 결국
읽기 → 계산 → 쓰기3단계를 중간에 끊기지 않게 묶어줘야 함 - 그래서 락, 세마포어, 트랜잭션, 원자적 명령어 같은 개념이 필요해짐
🛠 그래서 원자성을 보장하는 방법들
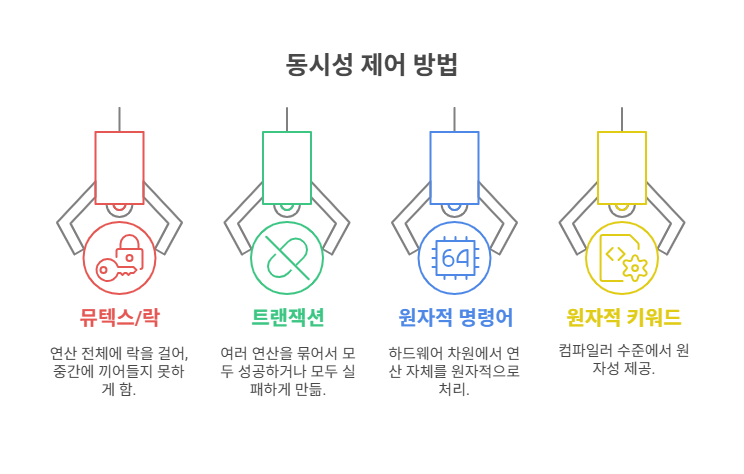
| 방법 | 설명 |
|---|---|
| 뮤텍스/락 | 연산 전체에 락을 걸어, 중간에 끼어들지 못하게 함 |
| 트랜잭션 | 여러 연산을 묶어서 모두 성공 or 모두 실패하게 만듦 |
| 원자적 명령어 (CAS, Test-and-Set) | 하드웨어 차원에서 연산 자체를 원자적으로 처리 |
C언어 atomic 키워드 | 컴파일러 수준에서 원자성 제공 |
공유 자원보다 무서운 건, 그 자원을 다루는 연산이 중간에 끊긴다는 사실이다.
그래서 우리는 데이터를 보호하는 게 아니라,
"연산 전체 흐름"이 끊기지 않게 보호해야 한다는 겁니다. 💡
2) 상호 배제(Mutual Exclusion): 락(Lock)의 탄생
명령어를 만들고 처리하기 위해 우리는 코드에 중요한 부분을 상호 배제(mutual exculusion) 메커니즘을 통해 원자적으로 처리하게 만듭니다.
이런 목표의 프로그램을 만들면서 충돌을 피하기 위해 어드바이저리 락(advisory lock)을 만든듭니다.
결국 우리는 요구사항들에 필요한 추상화된 원자 단위의 명령어로 만들어요.
이 때 데이터의 무결성을 유지하고, 충돌을 방지하기 위해 락(Lock)을 사용하게 됩니다.
💡 어드바이저리 락(advisory lock)
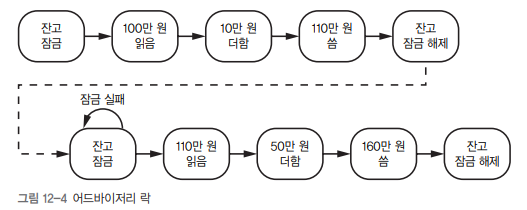
위쪽 프로그램이 락을 먼저 얻었다. 따라서 아래쪽 프로그램은 락이 해제될 때까지 기다려야 합니다.
- 프로그램이 스스로 지키기로 약속한 락
- 강제성 없음 → 약속 위반 시 무의미
- 하지만 공유 자원을 관리하는 "은행(자원 관리자)"이 락을 지키게 만들면 강제됨
📌 락의 위치가 중요하다
예: 은행이 락을 지키게 만들면 신뢰 가능 (그림 12-5)

3) 트랜잭션(Transaction): 연산 묶음 처리
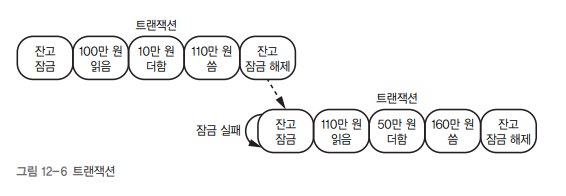
- 여러 연산을 모두 성공하거나, 모두 실패하도록 묶기
- 데이터베이스 뿐 아니라 운영체제, 파일 시스템, 메모리 동기화 등에서 사용됨
💡 트랜잭션 단위로 락을 최소화해야 동시성이 좋아짐
락 크기 = 작을수록 좋다 (fine-grained)
4) 락의 세부 개념
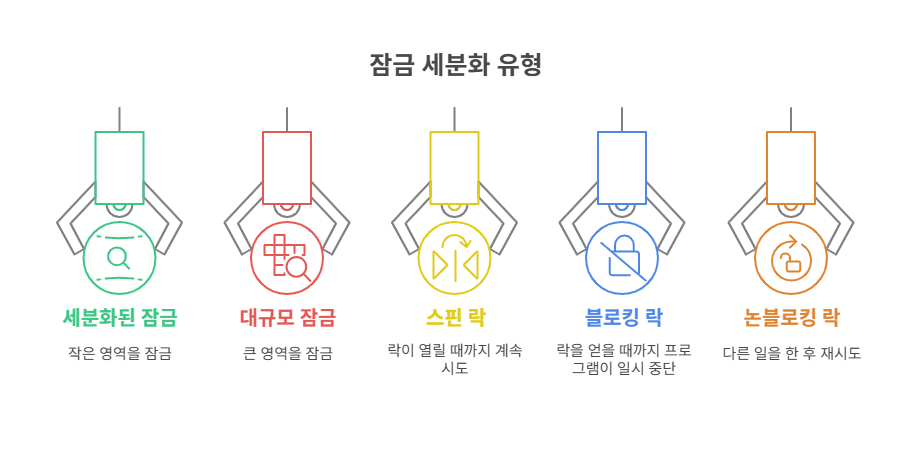
| 종류 | 설명 |
|---|---|
| Fine-grained Lock | 작은 영역만 잠금 (예: 한 계좌) |
| Coarse-grained Lock | 큰 범위 잠금 (예: 전체 은행) |
| 스핀 락(Spin Lock) | 락이 열릴 때까지 계속 시도 (busy wait) |
| 블로킹 락 | 락 얻을 때까지 프로그램 일시 중단 |
| 논블로킹 락 | 락 못 얻으면 다른 일 하다가 재시도 |
5) 💣 교착 상태(Deadlock): 락을 물고 물리는 상황
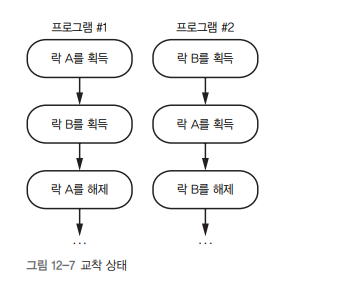
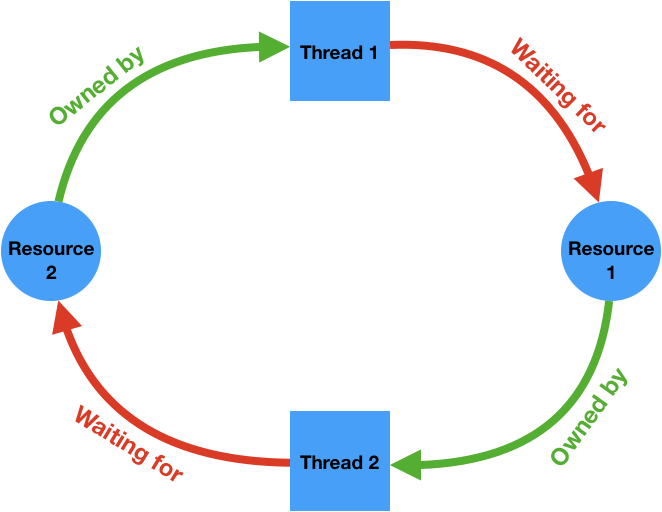
- 프로그램 #1은 성공적으로 락 A를 얻고, 프로그램 #2는 성공적으로 락 B를 얻습니다.
- 다음으로 프로그램 #1은 락 B를 얻으려 시도하지만 프로그램 #2가 락 B를 갖고 있기 때문에 락 B를 얻을 수 없습니다.
- 마찬가지로 프로그램 #2는 락 A를 얻으려고 하지만 프로그램 #1이 이 락을 갖고 있다.
- 두 프로그램 모두 자신이 갖고 있는 락을 해제하는 지점으로 진행할 수가 없습니다.
이런 상황을 교착 상태deadlock라고 합니다.
이 상황은 두 악당이 서로 상대방의 머리에 권총을 겨누고 있는 상황과 같습니다.
교착 상태 4대 조건
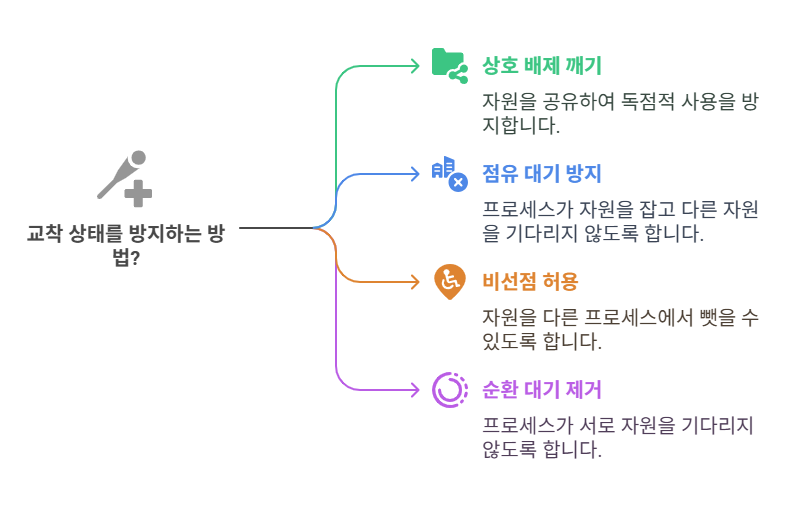
- 상호 배제: 자원을 독점적으로 사용해야 함
- 점유 대기: 자원을 잡고 다른 자원을 기다림
- 비선점: 자원을 뺏을 수 없음
- 순환 대기: 프로세스들이 서로 자원을 기다림
✅ 이 중 하나라도 깨면 교착 상태는 발생하지 않음
교착 상태 해결 방법
| 전략 | 예시 |
|---|---|
| 공유 자원으로 바꾸기 | 읽기 전용 자원은 락 없이 사용 |
| 자원 한번에 요청 | 모든 자원을 동시에 요구 |
| 선점 허용 | 타이머 초과 시 락 회수 |
| 자원 순서 고정 | 자원마다 우선순위 지정 |
6) 락 구현의 내부 – 하드웨어 명령어 사용
| 명령어 | 기능 |
|---|---|
| Test and Set | 값이 0이면 1로 바꾸고 락 성공, 아니면 실패 |
| Compare and Swap | 값이 기대값이면 새로운 값으로 교체 |
✅ 원자적(Atomic) 명령어로, CPU가 중간에 끊지 않도록 보장
이 명령어들은 대부분 시스템 모드에서만 실행 가능
→ 사용자 영역에선 고수준 API와 라이브러리 사용 (예: pthread_mutex_lock())
7) 장기 락: 파일 기반 잠금
-
문서 편집 프로그램 등에서 긴 시간 동안 자원 독점 필요
-
파일 락(File Lock)을 사용해 구현
- 동일 이름 파일을 배타적으로 생성
- 이미 존재하면 다른 프로세스는 실패
✅ 병렬 처리에서의 올바른 설계 철학
단순히 "공유 자원"을 막는 것이 아니라
"중요한 연산은 원자적으로 만들어야 한다"
📌 좋은 락 설계의 조건
- 가능한 짧게 잡아라 (락 지속 시간 최소화)
- 가능한 작게 잡아라 (작업 크기 최소화)
- 병렬 구조에 맞는 락 방식 선택 (spin, blocking, non-blocking)
- 교착 상태 4요소를 염두에 두고 락 설계
8) 트랜잭션 처리 미비 or 트랜잭션 분리 실제 문제
회사에서 이전에 쓰던 api를 재사용 했는데 일부 사용자만 쿠폰 발급이 안되는 현상이 있었습니다.
모니터링을 확인해보니 트랜잭션이 select => update => select을 해오는 구조였는데...일부 사용자에서는 update는 잘 되나 commit이 되기전 select를 하면서 문제가 생긴 것 그 때 코드를 일부 보면 아래와 같습니다.
if (조건문) {
Map<String, Object> map = 서비스.getCoupon(reqMap);
if (map == null) {
서비스.updateCoupon(reqMap); // DB 갱신
tmap = 서비스.getCoupon(reqMap); // 다시 조회
}
}updateCouponInfo()는 실행됐지만,
그 다음 getCouponInfo()에서는 여전히 null로 보이는 현상이 발생했죠?
🍱 음식점에서 밥을 시켰어 → 그런데 바로 다음에 음식을 달라고 하니까
어떤 손님한테는 밥이 오고, 어떤 손님한테는 “아직 안 지어졌어요”라고 하는 거야.
이유 1. 밥은 만들고 있는데 "포장"을 안 했어 (== 트랜잭션 커밋 안 됨)
updateCouponInfo()는 DB에 값을 넣긴 했는데- 그게 정식으로 확정(커밋) 되지 않았으면
- 다른 사람은 그걸 아직 못 본다
트랜잭션 시작
→ update 실행
→ (커밋 안 됨)
→ 다른 데서 select → 데이터 안 보여요 ❌이유 2. 너는 "밥 짓는 중"인데, 옆 사람은 "다른 공간"에서 밥 찾는 중 (== 트랜잭션이 다르다)
이게 진짜 문제야!
// Controller
서비스.updateCouponInfo(); // 트랜잭션 A
서비스.getCouponInfo(); // 트랜잭션 B ← 분리된 트랜잭션➡ update는 트랜잭션 A 안에서 했고
➡ get은 트랜잭션 B (또는 아예 트랜잭션 없음)에서 하니까
아직 A에서 커밋 안 된 내용이 B에는 안 보여요!
💡 이런 구조가 보통 트랜잭션 경계가 다르면 생김
예시 상황
// Controller
서비스.getCoupon() // 트랜잭션 A 없이 실행됨
서비스.updateCoupon() // 트랜잭션 B 시작, 근데 아직 커밋 전
서비스.getCoupon() // 트랜잭션 A에서 읽음 → 아직 안 보임해결방안 1. 컨트롤러에서 트랜잭션 하나로 묶기
@Transactional
public Map<String, Object> handleCoupon(Map<String, Object> reqMap) {
Map<String, Object> tmap = 서비스.getCoupon(reqMap);
if (tmap == null) {
서비스.updateCouponInfo(reqMap);
tmap = 서비스.getCoupon(reqMap);
}
return tmap;
}➡ 이렇게 하면 조회-수정-재조회가 같은 트랜잭션 안에서 처리되므로 문제 없음.
해결방안2 update한 값을 직접 리턴하거나 캐싱해서 쓰기
굳이 다시 DB에서 읽지 않고 update에서 값을 만들어서 넘겨도 OK.
진짜 해결법: "밥 짓고 → 확인"은 같은 공간(트랜잭션) 안에서 처리해야 돼!
✅ 정답 구조
@Service
public class CouponService {
@Transactional
public Map<String, Object> getOrUpdateCoupon(Map<String, Object> reqMap) {
Map<String, Object> tmap = getCoupon(reqMap); // 트랜잭션 A
if (tmap == null) {
updateCoupon(reqMap); // 같은 트랜잭션 A
tmap = getCoupon(reqMap); // 같은 트랜잭션 A ← OK!
}
return tmap;
}
}➡ 이렇게 하면 update한 내용을 get에서 확실히 볼 수 있어요
왜냐하면 둘 다 같은 트랜잭션 안에서 일어나니까!
update랑get이 같은 서비스 메서드 안에 있도록 만들기- 그리고 그 서비스 메서드에
@Transactional붙이기
락 관련 더 자세히 정리 한 글 : 나는 select만 했을 뿐인데.. 조회도 방심 금물, 트랜잭션이 묶이는 이유
6. 자바스크립트는 어떻게 '단일 스레드'로도 동시성을 처리할까?
1) 자바스크립트는 왜 '단일 스레드'인가요?
자바스크립트는 처음부터 멀티스레드 환경에서 동작하기 위해 만들어진 언어가 아닙니다.
그 기원은 **"사용자 경험 향상과 트래픽 절감"**에 있었습니다.
초기의 자바스크립트 목적은 단순했습니다.
"사용자 입력을 서버로 보내기 전에 브라우저에서 먼저 확인해보자!"
예를 들어, 신용카드 번호 입력란에 숫자가 아닌 글자가 들어가면, 굳이 서버에 데이터를 보내고 응답받을 필요 없이 브라우저에서 즉시 오류를 보여주는 것이죠.
이렇게 간단하고 빠른 피드백을 줄 수 있도록, 브라우저 안에서 사용자와 상호작용하는 작은 프로그램으로 자바스크립트가 시작된 것입니다.
그래서 자바스크립트는 단일 스레드(single-thread) 환경에서 동작합니다.
즉, 한 번에 하나의 작업만 처리할 수 있는 구조죠.
2) 단일 스레드인데 어떻게 "동시성" 문제가 생길 수 있죠?
이 질문은 자바스크립트의 핵심 비밀인 "이벤트 루프(event loop)"를 이해하면 풀립니다.
🎢 자바스크립트의 이벤트 루프란?
자바스크립트는 이렇게 일합니다:
- 이벤트가 발생하면 → 이벤트 큐에 추가
- 이벤트 루프가 → 큐에서 하나씩 꺼내 처리
- 이벤트 코드 실행이 끝나야 → 다음 이벤트 처리
즉, 이벤트 하나 처리 → 다음 이벤트 순서로 진행하는 구조죠.
이건 일종의 가상의 동시성입니다. 실제로 동시에 처리하는 게 아니라, 빠르게 번갈아가며 처리하는 것이죠.
📦 실제 예시: 앨범 커버 불러오기
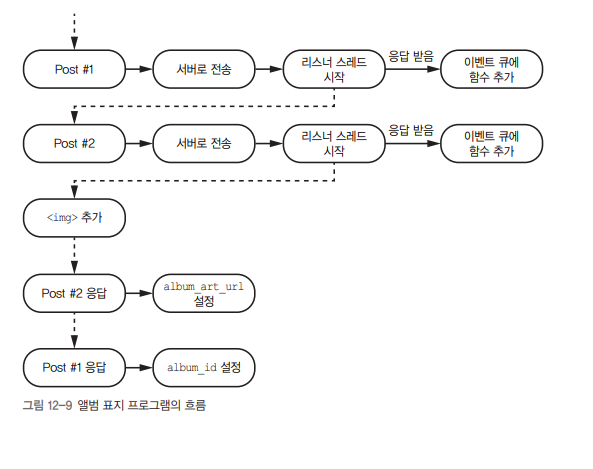
var album_id;
var album_art_url;
$.post("/get_album_id", { artist: "아이유" }, function(data) {
album_id = data.album_id;
});
$.post("/get_album_art", { id: album_id }, function(data) {
album_art_url = data.url;
});
$(body).append('<img src="' + album_art_url + '"/>');이렇게 짜면 앨범 ID가 아직 도착하기도 전에 album_art_url을 요청하고, 심지어 img 태그도 먼저 추가될 수 있어요.
왜냐하면, 각각의 요청은 서버에 갔다가 응답을 받는 비동기 작업(asynchronous task) 이기 때문이에요.
실제 실행 순서를 보장할 수 없다는 말이죠!
3) 자바스크립트가 비동기를 다루는 방법 3가지
자바스크립트는 이런 동시성 문제를 해결하기 위해 세 가지 방법을 제시해왔어요:
① 콜백(callback) – 초창기의 해결책
콜백 함수는 요청이 끝났을 때 실행될 함수를 인자로 전달하는 방식입니다.
$.post('/get_album_id', { artist }, function(data) {
$.post('/get_album_art', { id: data.album_id }, function(data) {
$(body).append('<img src="' + data.url + '"/>');
});
});이런 구조를 계속 중첩하면 어떤 문제가 생길까요?
📉 바로 '죽음의 피라미드(Pyramid of Doom)'입니다.
중첩이 깊어지면 가독성이 떨어지고, 에러 핸들링도 점점 어려워집니다.
② 프로미스(Promise) – 코드의 신뢰성을 높이다
ES6부터 자바스크립트는 Promise 객체를 통해 비동기 코드를 순차적으로 연결할 수 있는 방법을 제공합니다.
post("/get_album_id", { artist })
.then((data) => post("/get_album_art", { id: data.album_id }))
.then((data) => {
$(body).append('<img src="' + data.url + '"/>');
})
.catch((err) => console.error(err));이 방식의 장점:
- 중첩을 줄일 수 있음
- 에러를
.catch()하나로 처리 가능 - **함수 체이닝(then().then())**으로 흐름을 제어할 수 있음
③ async / await – 비동기 코드를 마치 '동기'처럼
async/await는 프로미스 기반 위에 더 직관적인 코드 흐름을 제공해 줍니다.
async function loadAlbumArt() {
const albumIdData = await post("/get_album_id", { artist });
const artData = await post("/get_album_art", { id: albumIdData.album_id });
$(body).append('<img src="' + artData.url + '"/>');
}await는 '기다려줘!' 라는 뜻입니다.
이 방식은:
- 가독성이 좋고
- 유지보수도 편하고
- 동기 코드처럼 작성할 수 있다는 점에서 가장 이상적인 구조입니다.
단, await는 async 함수 내부에서만 사용 가능합니다.
4) 자바스크립트 동시성의 본질
자바스크립트는 단일 스레드입니다. 하지만:
- 브라우저 내부에는 I/O, 타이머, 네트워크 등의 작업을 처리하는 백그라운드 스레드가 존재합니다.
- 이들이 응답을 주면 → 자바스크립트의 이벤트 큐에 함수가 들어가고
- 이벤트 루프가 → 하나씩 꺼내 실행합니다.
결국 자바스크립트의 동시성은 이벤트 루프와 콜백 큐의 협업을 통해 이루어집니다.
5) 왜 이렇게 복잡하게 비동기를 다룰까요?
자바스크립트는 브라우저에서 멈추지 않고 사용자와 상호작용하기 위해 이런 구조를 택했습니다.
만약 post()가 동기적으로 작동한다면, 네트워크 요청이 끝날 때까지 브라우저 전체가 멈추게 될 것입니다.
즉, 비동기 구조는 사용자의 흐름을 끊지 않기 위한 선택이었고, 그 때문에 우리는 callback, promise, async/await와 같은 기법을 활용하게 된 것이죠.
정리하면?
| 방식 | 설명 | 장점 | 단점 |
|---|---|---|---|
| 콜백 함수 | 함수 안에 함수 넣기 | 간단한 구조, 오래된 방식 | 중첩 발생, 에러 처리 어려움 |
| 프로미스 | then().then().catch() 체인 연결 | 에러 관리, 흐름 명확 | 문법이 복잡할 수 있음 |
| async/await | 비동기 코드를 동기처럼 표현 | 가독성 최고, 유지보수 쉬움 | 구버전 브라우저 지원 제한, 예외 처리 주의 |
🔚 마무리
단일 스레드 환경에서도 자바스크립트는 놀라운 방식으로 동시성과 비동기성 문제를 해결해왔습니다.
처음에는 단순한 사용자 이벤트만 처리하던 언어가, 이제는 대규모 서버 백엔드도 가능할 만큼 강력한 언어가 되었죠.
이 모든 것의 핵심은:
"하나의 흐름 안에서도, 여러 흐름을 유연하게 다루는 방법"을 제공한다는 것입니다.
자바스크립트는 단일 스레드이지만, 이벤트 루프, 프로미스, async/await의 조합을 통해
복잡한 비동기 세계를 지능적으로 다뤄내는 동시성의 대표 주자입니다.
8. 자바스크립트의 이벤트 루프 좀 더 자세히 알아보자
🧠 브라우저는 어떻게 ‘작은 운영체제’가 되었는가 – 이벤트 루프와 비동기 처리의 탄생
1) 📜 이야기는 이렇게 시작됩니다 – 클릭 한 번으로 바뀌는 세계
여러분이 웹페이지에서 버튼을 클릭하면 어떤 일이 벌어질까요?
단순히 글씨가 바뀌거나, 이미지가 나타나는 걸로 보일 수 있지만, 이 작디작은 변화 하나를 위해 브라우저 내부에서는 어마어마한 일이 벌어집니다. HTML이 펼쳐지고, JavaScript가 실행되고, DOM이 조작되고, 스타일이 다시 계산되고, 레이아웃이 조정되며, 마지막에 다시 그려지는 과정을 거칩니다. 그런데 여기서 가장 핵심적인 건 뭘까요?
바로 브라우저는 사용자의 요청을 "기다리고", 응답하는 "이벤트 기반 구조"를 갖춘 일종의 작은 운영체제처럼 행동한다는 사실입니다.
2) 🧩 브라우저 내부는 어떻게 생겼을까?
일단 브라우저는 단순히 웹페이지를 보여주는 도구가 아닙니다. 다음과 같은 요소들이 합쳐진 거대한 프로그램입니다:
| 구성 요소 | 설명 |
|---|---|
| HTML 파서 | 마크업 언어를 파싱해서 DOM 트리를 구성 |
| CSS 파서 | 스타일을 파싱해서 렌더 트리 생성 |
| JavaScript 엔진 (예: V8) | JS 코드를 해석하고 실행 |
| 렌더링 엔진 | DOM, CSSOM을 기반으로 실제 레이아웃과 픽셀 출력 |
| 네트워킹 스택 | 요청과 응답을 처리하는 통신 모듈 |
| 이벤트 루프 | 사용자 인터랙션과 스케줄된 작업을 처리하는 구조 |
{% hint style="danger" %}
이 모든 것을 조화롭게 연결하는 핵심은 무엇일까요?
{% endhint %}
바로 이벤트 루프(Event Loop)입니다.
3) 🔁 이벤트 루프란 무엇인가?
브라우저가 한 번에 하나의 작업만 할 수 있는 단일 스레드(single-threaded) 환경이라면, 우리는 어떻게 동시에 여러 가지 일을 할 수 있을까요?
바로 "이벤트 루프" 덕분입니다.
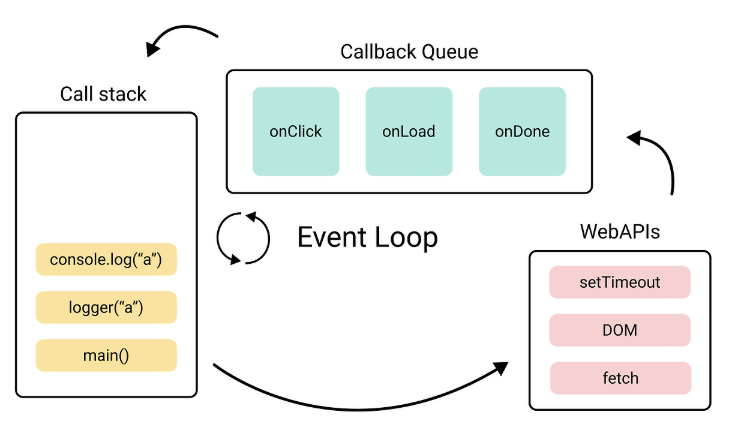
브라우저의 동작 타이밍을 제어하는 관리자라고 보면 됩니다.
이벤트 루프의 동작 과정을 간단히 살펴보자면, 자바스크립트의 setTimeout이나 fetch 와 같은 비동기 자바스크립트 코드를 브라우저 Web APIs에게 맡기고, 백그라운드 작업이 끝난 결과를 콜백 함수 형태로 큐(Callback Queue)에 넣고 처리 준비가 되면 호출 스택(Call Stack)에 넣어 마무리 작업을 진행합니다.
이벤트 루프를 이용한 프로그램 방식을 이벤트 기반(Event Driven) 프로그래밍이라고 합니다.
이벤트 기반 프로그래밍은 프로그램의 흐름이 이벤트에 의해 결정되는 방식이에요. 예를 들어 사용자의 클릭이나 키보드 입력과 같은 이벤트가 발생하면, 그에 맞는 콜백 함수가 실행하는데. 대표적으로 자바스크립트의 addEventListener(이벤트명, 콜백함수) 입니다.
이벤트 기반 프로그래밍은 비동기 작업을 쉽게 처리할 수 있고, 멀티 스레드 언어에 비해 단순하고 직관적인 코드 작성을 가능하게 하며, 브라우저와 같은 환경에서도 안정적인 실행을 가능하게 하여 사용자와의 상호작용을 높일 수 있습니다.
따라서 이를 이해하고 적절한 방식으로 비동기 작업을 처리하는 것은, 자바스크립트를 이용한 웹 애플리케이션 개발에 있어서 매우 중요합니다.
이벤트 루프를 알기 전 자바 스크립트의 특징을 알아보자

자바스크립트는 HTML에 종속되어있는 언어입니다. HTML 조작과 변경을 위해 사용합니다.
💡 HTML은 웹페이지에 글쓰고, 그림넣는 언어이다.\
특징 ) 안 움직임, 글 넣고 그림 넣고 끝
정적 언어인 HTML을 조작해서 웹페이지를 다이나믹하게 바꿔주는 기능을 하는게 자바스크립트입니다.
JavaScript는 싱글쓰레드 언어라고 많이 알려져 있습니다. 싱글쓰레드라고 한다면 여러 개의 작업이 있더라도 한 번에 하나의 작업만 수행할 수 있습니다. 하지만 JavaScript를 사용해 보면 멀티쓰레드처럼 동시에 여러 작업을 수행할 수 있다는 것을 알 수 있습니다.
{% hint style="danger" %}
그렇다면 JavaScript는 정말 싱글쓰레드 언어가 맞을까요?
{% endhint %}
맞습니다. 그 이유는 JavaScript의 메인쓰레드인 이벤트 루프가 싱글 쓰레드이기 때문입니다. 반면 Java 나 Python은 멀티 스레드를 지원하여 원하는 코드 로직을 동시에 수행 시키는 멀티 작업이 가능합니다.
하지만 JavaScript 이벤트 루프만 독립적으로 실행되는것이 아닌 웹 브라우저나 NodeJS 같은 멀티쓰레드 환경에서 실행되고 이를 적절하게 사용함으로써 멀티쓰레드처럼 사용이 가능한 것입니다.(다만 Web worker 최신 기술을 통해 자바스크립트도 멀티 스레드 구현이 가능해졌습니다. )
🤔HTML은 자바스크립트가 조작한다면 자바스크립트 해석은 누가할까요?
바로 브라우저입니다. 브라우저에는 자바스크립트 해석 엔진이 있습니다. 기존에는 자바스크립트를 인터넷 브라우저 위에서만 실행할 수 있었습니다.
그러나 2008년에 구글이 V8 엔진을 사용하여 크롬을 출시했습니다. V8 엔진은 엄청 빨랐고, 오픈 소스로 코드도 공개되었습니다. V8 엔진이 너무 뛰어나서 기능을 좀 더 더해서 V8 엔진 기반에 노드 프로젝트를 시작했고, Node.js(V8) 등장했습니다. Node.js는 브라우저 내에서 말고도 다른 환경에서 자바스크립트를 사용할 수 있게 해줍니다.
따라서 Node.js는 JavaScript 실행 환경(=런타임)입니다. (V8과 Node.js에 대한 설명은 뒤에서)
웹 애플리케이션에서는 네트워크 요청이나 이벤트 처리, 타이머와 같은 작업을 멀티로 처리해야 하는 경우가 많은데.. 만일 싱글 스레드로 브라우저 동작이 한번에 하나씩 수행하게 되면, 우리가 파일을 다운로드 받을 동안 브라우저는 파일을 다 받을 때까지 웹서핑도 못하고 멈춰 대기해야 할 것입니다.
따라서 파일 다운, 네트워크 요청, 타이머, 애니메이션 이러한 오래 걸리고 반복적인 작업들은 자바스크립트 엔진이 아닌 브라우저 내부의 멀티 스레드인 Web APIs에서 비동기 + 논블로킹으로 처리됩니다.
비동기 + 논블로킹(Async + Non blocking)Visit Website는 메인 스레드가 작업을 다른 곳에 요청하여 대신 실행하고, 그 작업이 완료되면 이벤트나 콜백 함수를 받아 결과를 실행하는 방식을 말합니다.
비동기로 동작하는 핵심요소는 자바스크립트 언어가 아니라 브라우저라는 소프트웨어가 가지고 있다고 보면 됩니다. Node.js 에서는 libuv 내장 라이브러리가 처리합니다.
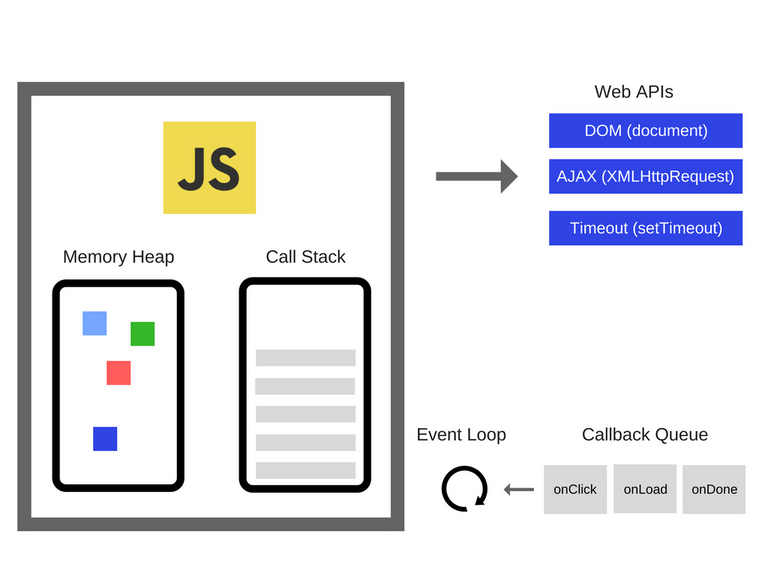
이벤트 루프는 브라우저 내부의 태스크 스케줄러 역할을 합니다. 비동기적인 요청과 사용자 인터랙션을 큐에 넣어 하나씩 처리하며, 이로써 동시성을 흉내낼 수 있게 해줍니다.
이벤트 루프는 JavaScript의 실행 컨텍스트와 콜백 큐, 마이크로태스크 큐, 태스크 큐를 조율합니다.
먼저, JavaScript 엔진이란?
자바스크립트(JavaScript)는 그 자체로는 "명령어의 나열일 뿐"입니다. 이걸 실제로 실행시켜주는 게 바로 JavaScript 엔진입니다.
JavaScript 엔진은 코드를 이해하고 실행을 도와주는 역할을 합니다.
💡 마치 "배우가 대본을 해석하고 연기하는 것"처럼, 엔진은 JS 코드를 해석하고 실행해줍니다.
브라우저는 각자 자신만의 JS 엔진을 가지고 있는데요:
- Chrome / Edge → V8 (구글 제작)
- Firefox → SpiderMonkey
- Safari → JavaScriptCore (또는 Nitro)
그중에서도 가장 유명한 엔진이 바로 V8 엔진입니다. 구글이 만든 이 엔진은 빠른 실행 속도와 효율적인 메모리 처리로 유명하죠.
📦 자바스크립트 엔진 내부 구조
엔진은 코드를 실행할 때 내부적으로 두 개의 핵심 구조를 사용합니다:
1. 🧠 Memory Heap (메모리 힙)
- 말 그대로 "어디에 무엇을 저장해둘지 결정하는 공간"입니다.
- 자바스크립트에서 변수, 객체, 배열 등을 선언하면 이곳에 저장됩니다.
- 동적으로 메모리를 할당하는 공간이며, 크기가 유동적입니다.
📦 예시:\
const cat = { name: "복이", age: 3 }\
→ 이 객체는 메모리 힙에 저장됩니다.
2. 🧾 Call Stack (호출 스택)
- 함수 호출이 일어날 때마다, 실행 순서를 기억하는 작업 목록이라고 볼 수 있어요.
- 후입선출 (LIFO) 구조로 작동하며, 가장 나중에 호출된 함수가 먼저 실행되고 끝나면 그다음 함수로 넘어갑니다.
📞 예시:
function hello() { console.log("안녕!"); } hello();→
hello()가 호출되면 Call Stack에 쌓이고, 실행 후 제거됩니다.
둘의 관계는?
- Memory Heap은 "무엇을 저장할까?"
- Call Stack은 "무엇을 언제 실행할까?"
예를 들어, 여러분이 add(2, 3) 같은 함수를 호출하면:
- Call Stack에
add()가 올라가고 - 내부 연산을 위해 필요한 변수는 Memory Heap에 저장됩니다
- 함수 실행이 끝나면 Call Stack에서 제거되고, 메모리도 정리됩니다 (Garbage Collection)
🔥 부가 설명: 왜 이걸 알아야 할까요?
이 구조를 알면 다음과 같은 자바스크립트 동작을 이해하기 쉬워집니다:
- 왜 함수 안에서 선언한 변수는 밖에서 접근할 수 없을까? (→ 스코프 + 스택 구조 이해)
- 왜 무한 재귀 호출을 하면
Maximum call stack size exceeded에러가 뜰까? - 메모리 누수는 왜 발생할까?
시각적 정리
┌───────────────┐
│ Memory Heap │ ← { name: '복이' }
└───────────────┘
┌───────────────┐
│ Call Stack │ ← hello()
│ │ ← main()
└───────────────┘Memory Heap & Call Stack
먼저 Memory Heap에 있는 사용자가 작성한 코드들은 Call Stack에서 Stack 방식으로 쌓이며 코드를 실행하게 되는데 이때 동기 함수들은 그대로 실행하게 되고 비동기 함수들은 Web API로 처리하게 되며 일을 분배합니다.
- Stack : 후입선출(LIFO)로 마지막에 들어간 것이 먼저 나가는 방식
브라우저 내부 구성도
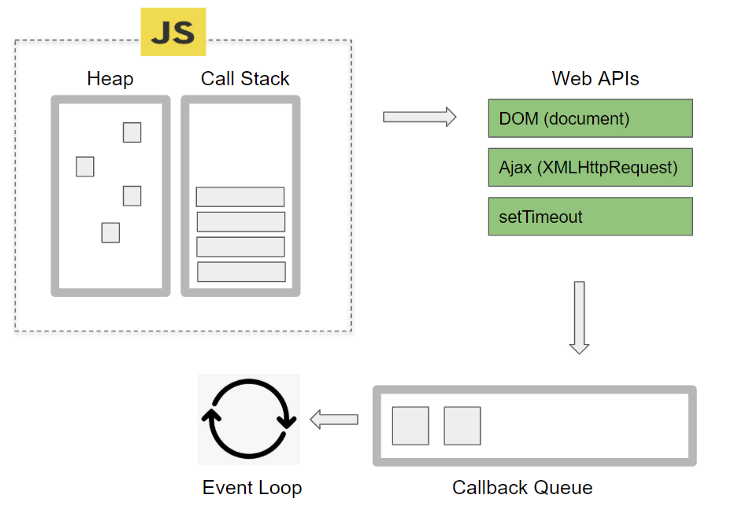
브라우저 전체 구성도를 보면 위와 같다.
| 구성 요소 | 역할 |
|---|---|
| Call Stack | 현재 실행 중인 코드의 함수 호출이 쌓이는 공간 (LIFO 구조) |
| Memory Heap | 동적으로 생성된 객체, 함수 등 데이터가 저장되는 공간 |
| Web APIs | 브라우저가 제공하는 비동기 API 집합 (AJAX, Timer 등) |
| Callback Queue | 완료된 비동기 작업의 콜백들이 대기하는 큐 (setTimeout 등) |
| Microtask Queue | Promise와 같은 고우선 비동기 작업의 콜백 대기 공간 |
| Event Table | 이벤트와 콜백의 관계를 관리하는 ‘주소록’ 역할 |
| Event Loop | Call Stack이 비어 있는지 감시 → Queue에서 콜백 실행 |
Web API – 브라우저의 비동기 도우미들
Javscript를 사용하면서 우리가 많이 사용하는 API 들은 사실 JavaScript에서 지원하는 것이 아닌 웹 브라우저에서 제공하는 API로 DOM ,AJAX, Timeout 등이 있습니다.
자바스크립트 자체에는 비동기 기능이 없음
→ 브라우저가 비동기 동작을 Web API로 제공함
Call Stack에서 실행된 비동기 함수는 Web API에서 처리를 하게 되고 그동안에 Call Stack은 나머지 동기 함수들을 처리하게 됩니다.
Web API는 비동기 함수들을 처리하며 작업이 완료된 비동기 함수들을 Callback Queue로 넘겨주게 됩니다.
주요 예시
| API 종류 | 설명 | 동기/비동기 |
|---|---|---|
| DOM API | 요소 선택, 조작 등 | 동기 |
| Timer API | setTimeout, setInterval | 비동기 |
| XHR / Fetch | 서버와 비동기 통신 | 비동기 |
| Canvas API | 그래픽 렌더링 | 동기 |
| Geolocation | 위치 정보 제공 | 비동기 |
| Console API | 로그 출력 | 동기 |
구조 상 비동기 Web API는 별도의 스레드로 작동 → 메인 스레드를 블로킹하지 않음
Callback Queue
- Web API가 작업을 마치면 콜백을 Queue에 넣음
- 이 Queue는
Event Loop가 Call Stack이 비면 하나씩 꺼내 실행함
Callback Queue는 비동기 함수들을 보관하는 장소로 Event Loop에서 비동기 함수를 꺼내기 전까지는 계속 Queue방식으로 보관하게 됩니다.
- Queue : 선입선출(FIFO)로 먼저 들어간 것이 먼저 나가는 방식
Event Loop
Event Loop는 Call Stack과 Callback Queue를 상태를 계속 감시하며 Call Stack에 함수들이 존재하지 않는다면 Callback Queue에 있는 비동기 함수들을 Call Stack에 밀어 넣게 됩니다. 그 후 Call Stack에서 비동기 함수를 실행시키게 됩니다.
Microtask Queue
- 비동기 중에서도 우선순위가 높은 큐
Promise.then,process.nextTick,MutationObserver등이 여기에 들어감- Call Stack이 비자마자 가장 먼저 실행됨
Promise가
setTimeout보다 먼저 실행되는 이유는 이 구조 때문입니다
예시로 살펴보는 이벤트 루프
console.log('A');
setTimeout(() => {
console.log('B');
}, 0);
Promise.resolve().then(() => {
console.log('C');
});
console.log('D');출력 순서는 어떻게 될까요?
A
D
C
B왜 이런 순서로 출력될까요?
| 단계 | 설명 |
|---|---|
| A, D | 동기 실행 – 콜 스택에서 바로 실행 |
| C | 마이크로태스크 큐 → 이벤트 루프는 스택이 비면 우선 처리 |
| B | setTimeout의 콜백 → 태스크 큐에 들어가고, 마이크로태스크 다음에 실행 |
결국, Event Loop은 전체를 연결하는 조율자입니다.
- Call Stack이 비었는지 계속 감시
- Stack이 비면 Microtask Queue → Callback Queue 순서로 콜백 실행
- 매 프레임마다 한 번씩 돌면서 애플리케이션을 부드럽게 실행
4) 🛠️ 이벤트 루프는 브라우저 안에서 어떻게 동작할까?
이벤트 루프의 동작 순서를 간단히 그림으로 표현해보면 다음과 같습니다:
1. 콜 스택 실행
2. 마이크로태스크 큐 처리
3. 렌더링 단계
4. 태스크 큐에서 콜백 처리 (setTimeout, 이벤트 등)
5. 다시 반복이 구조는 CPU 스케줄러와 유사하게 작동하며, 태스크 간 우선순위와 대기열을 관리합니다.
이를 통해 브라우저는 다음과 같은 일을 효율적으로 처리할 수 있습니다:
- 마우스 클릭 이벤트
- setTimeout / setInterval
- XMLHttpRequest / fetch
- DOM 조작 / 렌더링
- Promise.then
비유: "자바스크립트의 오케스트라"
| 역할 | 구성 요소 | 설명 |
|---|---|---|
| 지휘자 | Event Loop | 큐와 스택을 관리하며 타이밍을 조율함 |
| 무대 위 배우 | Call Stack | 현재 실행되는 함수들 |
| 대기실 | Task Queue, Microtask Queue | 순서에 따라 무대에 오를 콜백들 |
| 조명/효과팀 | Web APIs | 타이머, 네트워크, 이벤트를 처리하는 브라우저 기능들 |
브라우저 성능 최적화를 위한 팁
| 최적화 항목 | 설명 |
|---|---|
Promise를 활용해 순차 실행 | Microtask로 빠르게 처리 가능 |
requestAnimationFrame | 애니메이션 최적 타이밍에 실행됨 |
setTimeout(..., 0) 남용 자제 | Task Queue는 한 프레임 지연됨 |
대량의 DOM 조작은 DocumentFragment 사용 | Stack이 과도하게 쌓이지 않도록 조절 |
- 자바스크립트는 싱글 스레드지만, 브라우저는 멀티 스레드 구조
- Web API, Event Loop, Queue가 협업하여 비동기 코드를 처리
- Microtask가 Task보다 먼저 실행된다는 점은 반드시 기억!
