내 지식이 허접하다
지금 하고 있는 프로젝트에서 AWS elastic beanstalk을 이용해서 서버 환경을 구성했다. 오토 스케일링과 배포 정책 지정하고, 깃허브 액션으로 간단한 ci/cd 파이프라인도 구축했다. 왜 잘 굴러가는지는 모르겠지만 어쨌든 잘 굴러가는 서버를 배포할 수 있었다.
그런데 디벨롭 과정을 거치다보니 http만 사용하던 서비스에 웹소켓을 도입해야 했다.
기능 구현 자체는 금방 끝났다. 로컬에서 실행시켰을 때는 아무런 문제가 없었기 때문에 당연하게 배포에도 문제가 없을 줄 알고 그대로 PR올리고 배포했다.
문제 발생 - 웹소켓 연결 실패
배포된 서버에서 포스트맨으로 웹소켓 요청을 보냈을 때 다음과 같이 연결되지 않고 Connecting만 뜨는 문제가 발생했다.

이 상태로 방치해놓고 다른 작업을 했는데 몇십분동안 연결중이라고만 떴다. (곤란해요)
찾아보니 ec2에서 웹소켓을 사용하기 위해서는 기본으로 제공하는 설정에서 별도의 load balancer을 적용해야 한다고 했다. 사실 EB 설정할 때 로드밸런서를 설정한 기억이 있는데, 그게... 그게 뭔지 잘 몰라서 내가 뭘 쓰고 있는지도 몰랐다.
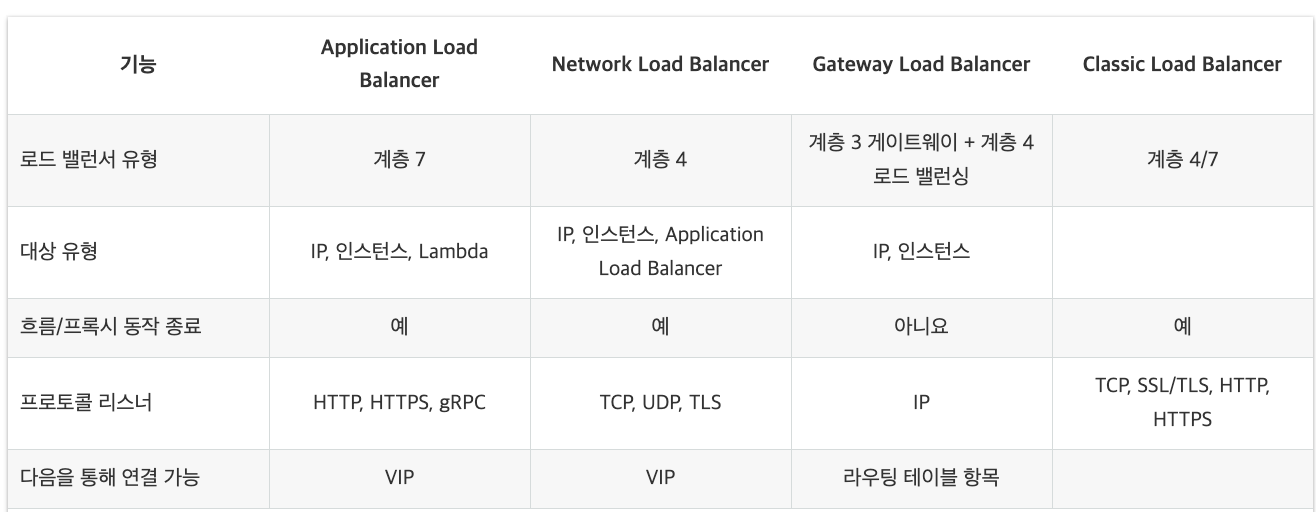
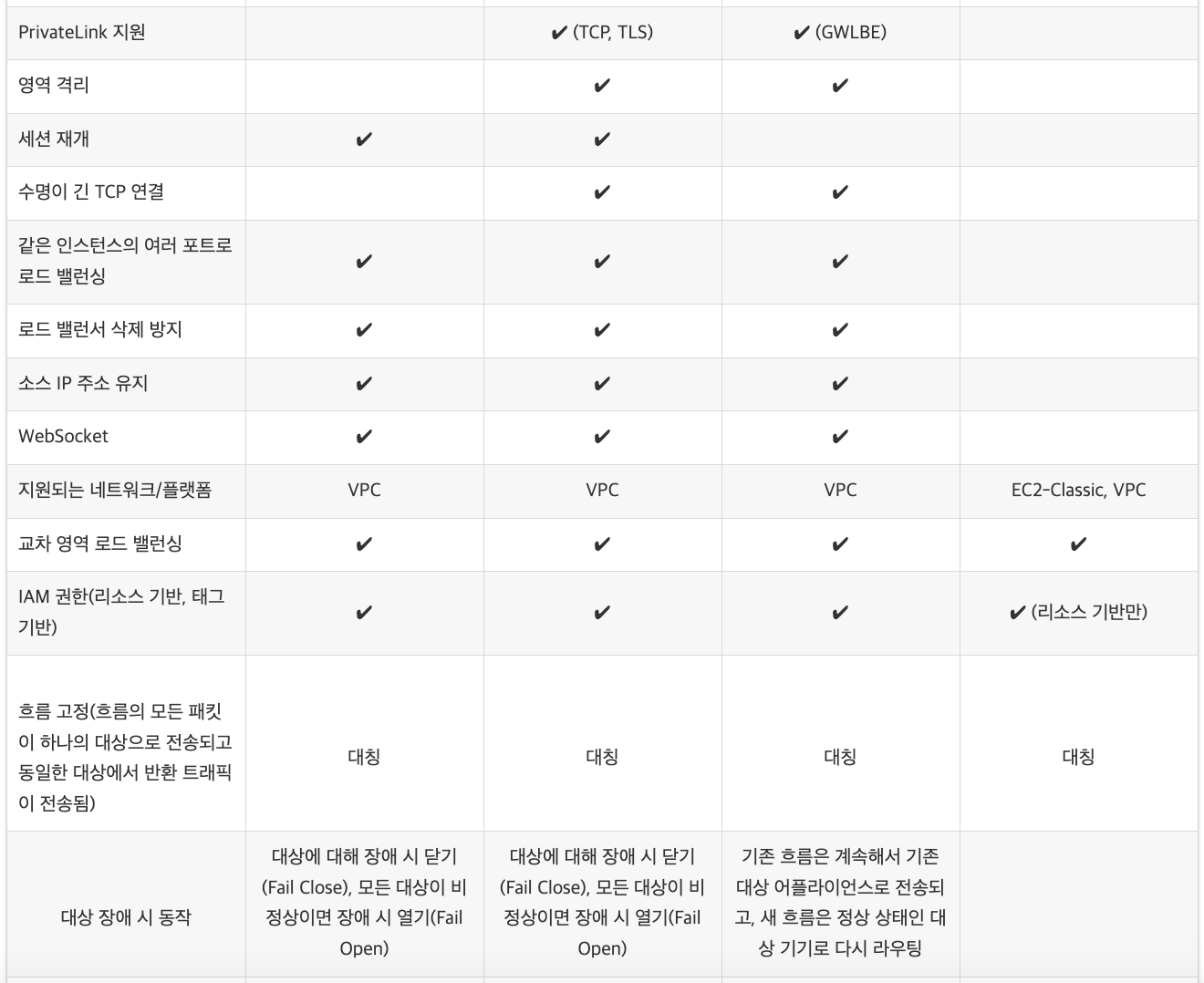
일단 안 되니까 아래의 표를 참고해서 내가 사용하고 있는게 Classic Load Balancer라고 생각하고 설정을 고치려고 찾아봤다.
아마존의 친절한 기능 비교
그래서 load balancing이...뭐죠...?

Load Balancing
로드밸런싱은 어플리케이션의 리소스 풀 전체에 네트워크 트래픽을 균등하게 배포하는 방법이라고 한다.
수많은 사용자를 동시에 처리해야 하는 어플리케이션에서 데이터들을 빠르고 안정적으로 배포해야 하는데, 이 때 로드밸런싱을 통해 모든 리소스 서버가 동일하게 사용되도록 해서 사용자가 안정적으로 서비스를 사용할 수 있게 해주는 기능이다. (가용성, 확장성, 보안, 성능 등 많은 장점이 있다고 함)
성능 측면에서 CDN과 비슷한 효과가 있는 것 같다. 나중에 찾아보니까 일단 ELB를 설정하면 그 위에서 CDN설정이 가능한 듯 (cloud front)
아마존에서 제공하는 로드밸런싱은 ELB로 묶어서 부르는 것 같고, 그 안에서 나뉜 종류를 확인하려면 아까 확인한 표를 보는게 제일 정확할 것 같다.
기능에 대한 이해는 이 블로그를 주로 참고했다. 어려워서 반쯤 흘려들었다.
아무튼 웹소켓 웨 안되?
그런데 내가 도입했던건 처음부터 ALB였다. elastic beanstalk으로 서버 구성 시 로드밸런서 설정하면 기본으로 ALB가 적용된다. 특정 단어에 대한 충분한 이해 없이 허접하게 튜토리얼 그대로 서버를 구성하다보니 내 서버가 어떤 요소를 갖고 있는지 몰라서 시간을 낭비한 것이다.
로드밸런서의 문제가 아닌 것을 찾았으니 다른 원인을 찾아야 했다. 그런데 원인은 의외로 별거 아닌 곳에서 찾을 수 있었다. 서버에 로그 하나 찍히지 않는게 이상해서 엔드포인트를 확인해 봤더니 "http://" 를 쓰고 있었던 것이다. ㅋㅋ; ㅋㅋ; (머쓱)
"ws://"로 수정해주니 연결이 잘 됐다.
그리고 새로운 문제가 생겼다.
문제 발생 2 - 연결 지속시간 짧음
굳이 웹소켓을 사용하는 이유는 기존 코드가 http로 1초에 한번 씩 서버에 같은 요청을 보내고 있었기 때문이었다. 이왕 보내주는거 통신비용도 절약하고 응답도 빠르게 보낼 겸 웹소켓으로 리팩토링을 하게 된 것이다. 그런데
배포된 서버에서 연결이 1분마다 끊겼다.

헬스케어 서비스는 1분 1초가 중요한 서비스인데, 1분마다 웹소켓 재연결에 드는 시간 비용을 감당하면 리팩토링한 의미가 없어질 것 같았다.
이런 문제를 예방하고자 ping/pong을 구현해놨는데... 이번에도 로컬에서는 잘 돌아가는데 배포 서버에서는 의도대로 돌아가지 않았다.
배포된 서버에서만 웹소켓이 끊긴다
로컬에서는 잘만 돌아가던 기능이 배포된 서버에서만 제대로 동작하지 않는다면 단순히 웹소켓의 연결 말고도 외부 요인이 개입했을 것이라고 생각했다.
로컬서버와 배포서버의 차이점은 너무 많았지만 조금 크게 보면 데이터베이스, 운영체제와 nginx의 사용여부라고 생각했다.
연결은 잘 되는데 지속시간이 1분밖에 안 되는 것이 문제였기 때문에 해당 주제와 더 가까운 nginx를 의심했다.
nginx 설정
nginx의 서버 연결 관련된 설정부터 고쳤다. nginx를 쓰는 이유는 프록시 서버를 사용하기 위해서였기 때문에 해당 설정을 찾아봤다.
proxy_read_timeout 3600s;
proxy_send_timeout 3600s;
proxy_connect_timeout 3600s;위의 프록시 관련 설정을 로케이션 블록 안에 추가했다.
proxy_connect_timeout를 따로 설정하지 않았을 때 기본값이 60s라고 한다. 내 소켓 지속시간도 딱 1분이었으니 가능성이 있었다.
추가하고 나니 적어도 30분 이상 연결이 안 끊기고 지속되는 것을 확인할 수 있었다. 예상하기로는 한시간 지나면 칼같이 연결이 끊길거다. 이건 임시방편이고, 클라이언트 개발 팀원에게 끊겼을 때 자동으로 재연결 요청하는 코드를 부탁했다.
내 서버가 공격받는다
웹소켓에 대한 문제를 해결하고 나니 서버 운영에 크게 어려운건 없었다. 그리고 생각치도 못한 문제가 발생했다.
문제 발생
서버 로그에 수상한 내역이 찍혀있는 것을 발견했다.
낯선 외부 IP와 무더기의 수상한 PHP 요청들...
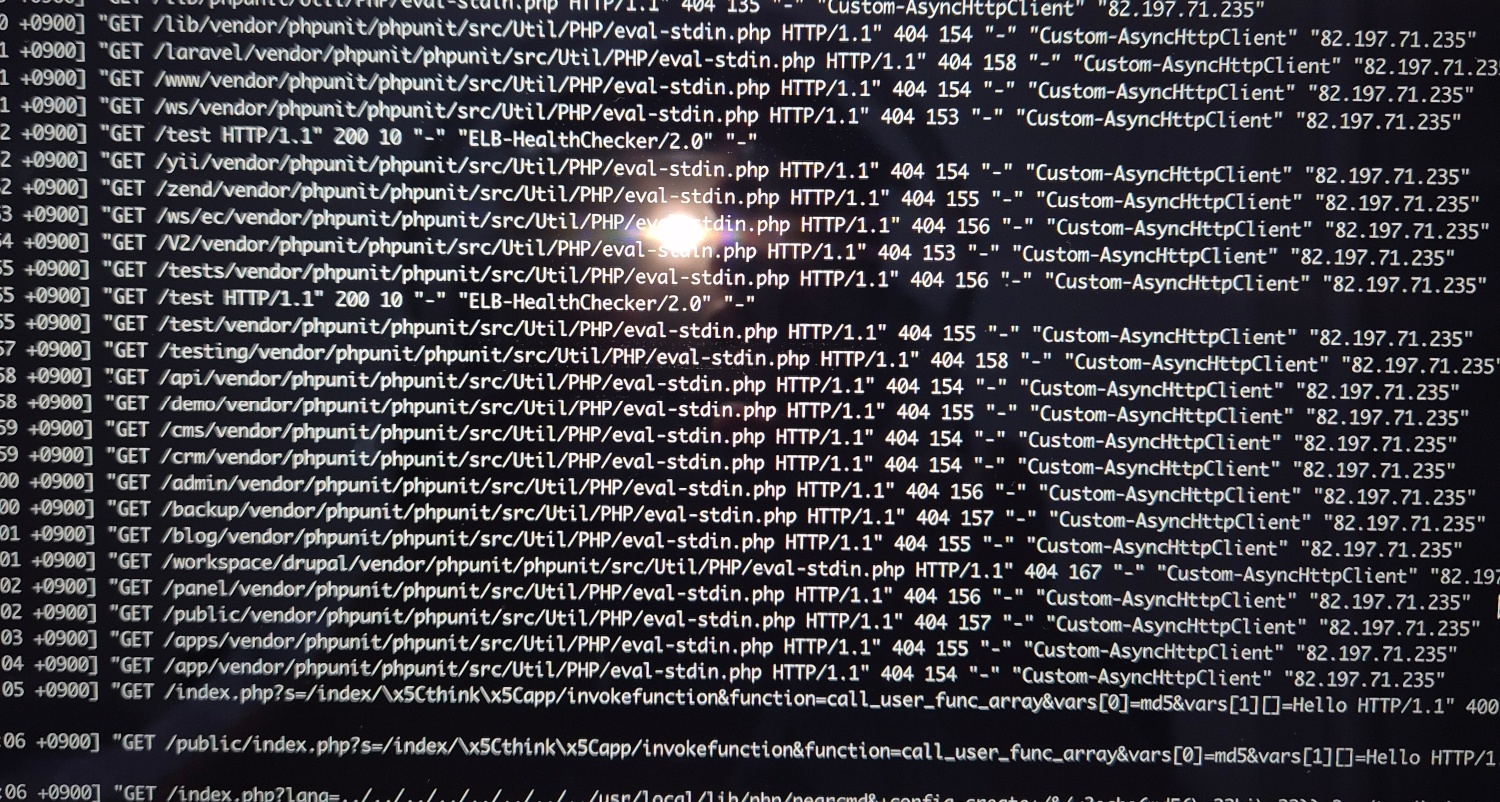
순간 등골이 서늘해짐.
주마등처럼 스쳐지나가는 "OO님 서버가 해킹당해서 서버비가 150만원이 나왔다더라" 가십처럼 떠들던 이야기... 내 일은 아닐거라고 생각했던 이야기가 생각났다.
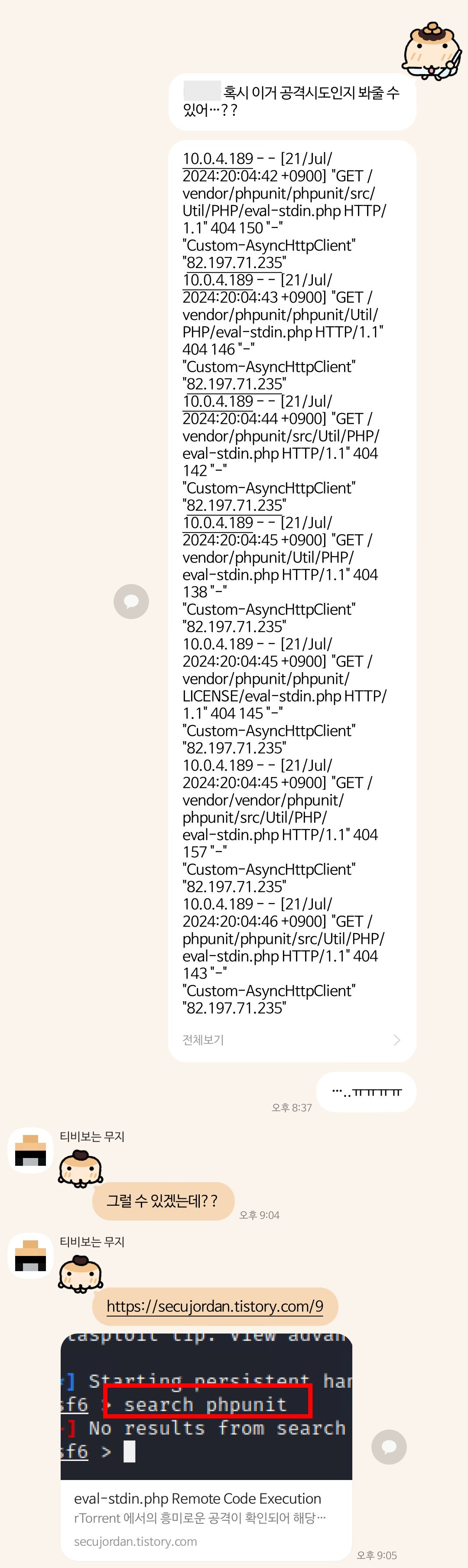
정보보호 전공의 친구에게 물어봤을 때 블로그를 하나 보여줬는데 보안 상의 문제가 발견된 레거시 파일에 접근 요청을 던져서 응답이 성공하면 그대로 뭔가를 뜯어가는 그런 공격이었다. 난생 처음보는거라 제대로 이해한건진 모르겠다.
급한 불 끄기
급한대로 서버에 해당 IP를 차단하고 아래의 설정도 추가했다.
location ~ ^/public/ {
deny all;
}
location ~ \.php$ {
deny all;
}
다행히 로그를 전부다 확인했을 때 저런 비정상적인 요청은 모두 400번대 혹은 500번대 응답이 갔다.
nginx 서버 수정하고 재부팅했다.
사실 이 문제는 아직도 해결되지 않았다. 인스턴스를 계속 바꾸는데 어떻게 알고 공격을 보내는지 정말 다양한 IP에서 다양한 방식의 공격이 들어오고 있다.
지금도 로그를 계속 보고 있는데 이번엔 Go로 작성한 새로운 공격이 들어왔다. (어지러워요) 
완전 럭키디프리야🍀
공짜 취약점 검사라고 생각하기로 했다. 완전 럭키 디프리잖아🍀
이번 프로젝트 하면서 이렇게 장기간 서버 운용한 것은 처음인데, 이런 문제가 생기다보니 주기적인 로그 모니터링의 필요성을 느꼈다.
보안은 진짜 모르는 분야라서 이 공격 시도가 단 한번이라도 성공하게 됐을 때의 후폭풍이 많이 무섭다. 원래 사건이 터지고 대처하는 것보다는 예방이 싸게 먹히는 법이니, 하루빨리 도메인 구매하고 인증서 발급하자.
결론
개발에만 몰두하려고 ci/cd를 구축했는데 서버 관리에 시간을 더 쏟고 있다.
서버 개발자가 나 하나인데, 그 와중에 개발 외의 것들도 관리해야 하니 시간이 배로 들고 있는 것 같다. 공격시도 받는거 알았을 때는 세상이 무너지는 기분이었는데, 스프링 시큐리티 도입한 덕에 200번대 응답도 없고 잘 막아주고 있는 것 같다. 그래도 소 잃고 외양간 고치는건 소용이 없으니까 저렴한 도메인 구매해서 재정비해야 할 것 같다.
확실한건 내 어쩌구가 건강해지고 있다는거임
