
DFS/BFS
재귀함수
재귀함수란 자기 자신을 다시 호출하는 함수를 의미한다. 컴퓨터 내부에서 재귀 함수 수행은 스택을 이용한다. 대표적인 예제로 팩토리얼 함수, 피보나치 수열 함수 등이 있다. 알고리즘에선 DFS가 대표적이다.
그래프
- 인접 행렬
배열 - 인접 리스트
연결리스트
| 인접 행렬 | 메모리 낭비 | 접근 속도 빠름 |
|---|---|---|
| 인접 그래프 | 메모리 효율적 | 접근 속도 느림 |
DFS
- Depth First Search
- 깊이 우선 탐색
- 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘
- 복잡도 O(N)
- stack, 재귀함수
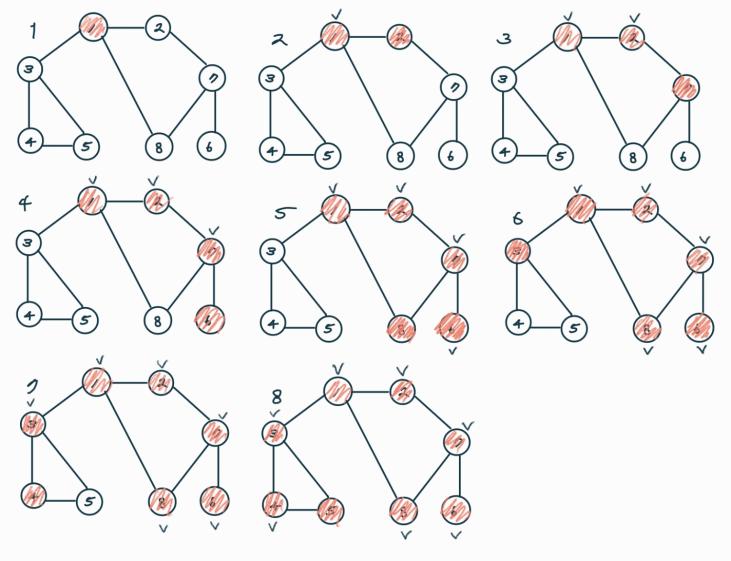 재귀함수는 컴퓨터 내부에서 스택으로 구현된다. 즉 이러한 DFS의 흐름을 스택으로 구현하면 버퍼에 들어가는 순서는 아래의 표와 같다.
재귀함수는 컴퓨터 내부에서 스택으로 구현된다. 즉 이러한 DFS의 흐름을 스택으로 구현하면 버퍼에 들어가는 순서는 아래의 표와 같다.
| 순서 |
|---|
| 5 |
| 4 |
| 3 |
| 8 |
| 6 |
| 7 |
| 2 |
| 1 |
BFS
- Breadth First Search
- 너비 우선 탐색
- 가까운 노드부터 탐색하는 알고리즘
- 복잡도 O(N)이나 실제 수행시간은 DFS보다 빠름
- queue(실제 구현 시 deque 추천)
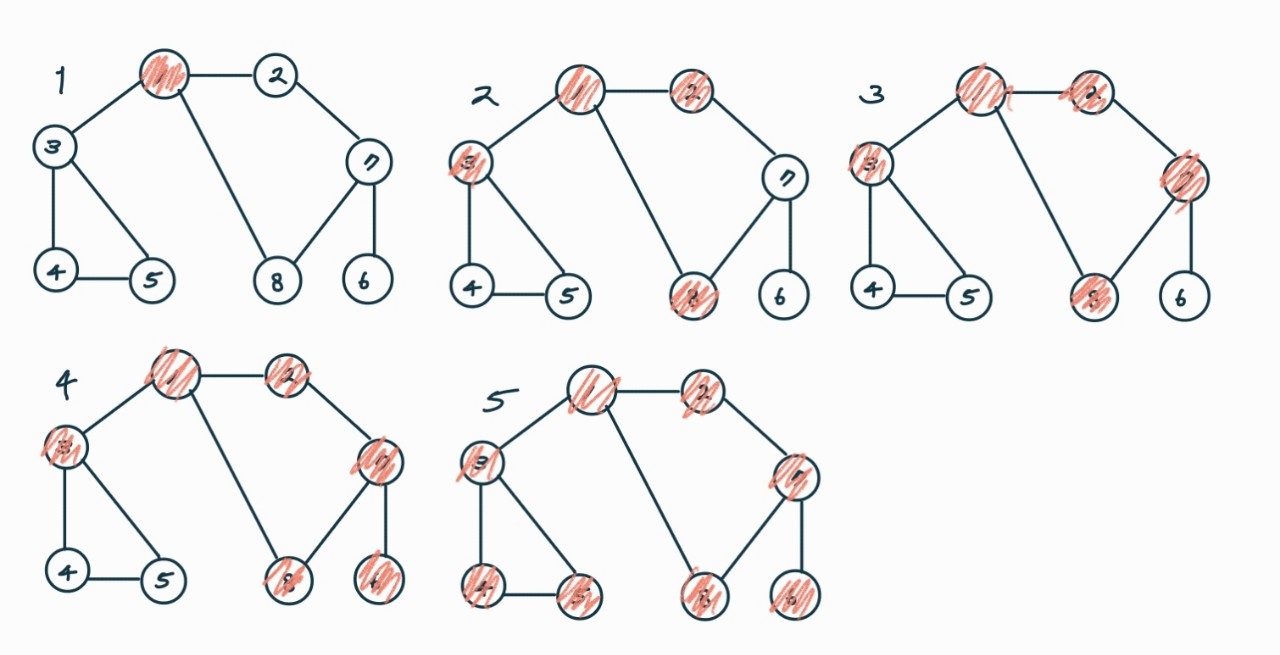
BFS는 큐로 구현 가능하다. 큐로 구현하면 버퍼에 들어가는 순서는 아래의 순서와 같다. 그림은 잘못되었다. 4번 그림에서 6번 노드가 아닌 4번, 5번 노드부터 방문해야 맞다.
| 순서 |
|---|
| 6 |
| 5 |
| 4 |
| 7 |
| 8 |
| 3 |
| 2 |
| 1 |
이러한 알고리즘을 코드로 구현하기 위해서는 노드에 방문했는지 체크하는 배열, 노드의 정보를 담을 배열 혹은 리스트가 필요하다.
문제풀이
음료수 얼려 먹기
이거 bfs로도 충분히 풀 수 있다고 생각했는데 풀이가 생각나질 않았다...ㅎㅎ 결국 dfs 뼈대만 만들어놓고 응용하는 내용은 저자의 코드를 참고했다.
- 얼음틀에 대한 정보를 입력받은 뒤 모든 얼음틀에 대해 각각 dfs를 실행한다.
- dfs가 실행되고 만약 해당 얼음틀이 뚫린 얼음틀(0)이고 방문한 적 없는 얼음틀이라면 현재의 얼음틀과 인접한 뚫린 얼음틀을 1로 바꾸고 true를 리턴한다.
간단한 알고리즘이었는데 왜 문제를 풀려고 하니 생각이 안 났는지 참... dfs/bfs 문제의 대부분이 해결방법에 대한 추상적인 생각은 가능하지만 실제 구현이 어렵다. 연습이 많이 필요할 것 같다.
#include <iostream>
using namespace std;
int graph[1000][1000];
int n, m;
bool dfs(int x, int y)
{
if (x < 0 || x >= n || y < 0 || y >= m)
{
return false;
}
if (graph[x][y] == 0)
{
graph[x][y] = 1;
dfs(x + 1, y);
dfs(x - 1, y);
dfs(x, y + 1);
dfs(x, y - 1);
return true;
}
return false;
}
int main()
{
int cnt = 0;
cin >> n >> m;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
cin >> graph[i][j];
}
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
if (dfs(i, j))
cnt++;
}
}
cout << cnt << "\n";
return 0;
}미로 탈출
이건 처음에 dfs로 풀어보려다가 코드 구현에 실패해서 책 찬스를 썼다. 경로 탐색에는 bfs를 쓰면 좋다는 이야기를 보고 bfs를 구현하려고 했으나...^^~~ 실패하고 저자의 깃허브를 참고했다.
- 입력되는 정보를 배열에 저장하고 해당 배열을 bfs 처리한다.
- 이동할 수 있는 경우는 상하좌우로 0~n-1/0~m-1이면서 해당 배열의 값이 1일 때.
- 모든 조건을 만족하는 경우 해당 배열에 이동횟수를 저장한다.
이동횟수를 배열에 직접 저장한다는 발상을 하지 못했기 때문에 이 문제를 풀지 못했다. 사실 dx, dy 배열도 이전에 비슷한 코드가 있었지만 이해하지 않고 넘어갔기 때문에 바로 생각하지 못했다.
무엇보다도 문제 자체는 그리 어려워보이지 않았으나 pair을 써야 된다는 생각을 못 했다. 떠올리긴 했으나 어떻게 vector와 결합해야 할 지, 그걸 응용해서 어떤 코드를 짤지 생각하지 못한 것이 가장 컸다. 풀이 방법은 대충 이해했고 stl을 미리 숙지하지 못했던 점이 문제를 풀지못한 가장 큰 이유였다.
pair은 이전에도 몇 번 다룬 적이 있었지만 vector와 같이 쓸 때 더 쉽게 사용할 수 있는 방법을 알게 됐다. 만족.
#include <iostream>
#include <utility>
#include <deque>
using namespace std;
int graph[201][201];
int n, m;
int ans = 0;
int dx[] = { 0,0,1,-1 };
int dy[] = { 1,-1,0,0 };
int bfs(int x, int y)
{
deque<pair<int,int>> buffer;
buffer.push_back({ x, y });
while (!buffer.empty())
{
int x = buffer.front().first;
int y = buffer.front().second;
buffer.pop_front();
for (int i = 0; i < 4; i++)
{
int ax = x + dx[i];
int ay = y + dy[i];
if (x >= n || y >= m || x < 0 || y < 0)
continue;
if (graph[ax][ay] == 0)
continue;
if (graph[ax][ay] == 1)
{
graph[ax][ay] = graph[x][y] + 1;
buffer.push_back({ ax, ay });
}
}
}
return graph[n - 1][m - 1];
}
int main()
{
cin >> n >> m;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
cin >> graph[i][j];
}
}
cout << bfs(0, 0) << "\n";
return 0;
}2606 바이러스

DFS를 연습하려고 찾아낸 문제인데 BFS로 풀었다. 그래프의 개념은 알지만 문제에 나왔을 때 사용하는 방법은 막막했는데, vector를 사용해서 하나의 노드에 연결정보를 저장하고 이후에 stack이나 queue에 그 정보를 사용하면 됐다. 이 문제로 며칠을 고민했는데 옛날에 정리했던 자료에서 답을 얻었다.
- 최대 node의 갯수만큼 vector를 생성한 뒤 받아온 edge를 각 노드에 푸시했다. vector특성 상 이미 생성된 노드에 push_back하게 되면 다차원 배열처럼 사용할 수 있다.
- 1번째 노드의 연결정보를 알아내기 위해 bfs함수를 만들었다.
- 큐 버퍼에 1번째 노드를 푸시한 뒤 팝할 때 노드에 연결된 다른 노드를 푸시한다.
- 팝 할때마다 카운트를 1씩 증가시키면 연결된 모든 노드를 알 수 있다.
예를 들어 아래와 같은 그래프가 있다고 생각해보면
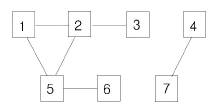
| 노드 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 연결된 노드 | 2, 5 | 1, 3, 5 | 2 | 7 | 1, 2, 6 | 5 | 4 |
이런 식으로 노드가 연결돼있다. 차례대로 queue버퍼의 연산과정을 표로 그려보면 처음에는 1번째 노드가 push된다.
| 노드 | 1 |
|---|
front인 1번노드가 pop되면 1번 노드의 인접노드인 2번, 5번 노드가 push된다.
| 노드 | 2 | 5 |
|---|
front인 2번 노드가 pop되면 2번 노드의 인접노드인 1번, 3번, 5번 노드가 push되지만 1번, 5번 노드는 이미 queue에 방문한 적이 있기 때문에 제외된다.
| 노드 | 5 | 3 |
|---|
front인 5번 노드가 pop되면 5번 노드의 인접노드인 1번, 2번, 6번 노드가 push되지만 1번, 2번 노드는 이미 queue에 방문한 적이 있기 때문에 제외된다.
| 노드 | 3 | 6 |
|---|
나머지 노드들도 같은 과정을 거친다.
| 노드 |
|---|
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
vector<int> node[101];
int visit[101];
int cnt = -1;
void bfs(int n)
{
queue<int> b;
b.push(n);
visit[n] = 1;
while (!b.empty())
{
int x = b.front();
b.pop();
cnt++;
for (int i = 0; i < node[x].size(); i++)
{
int y = node[x][i];
if (visit[y] == 0)
{
b.push(y);
visit[y] = 1;
}
}
}
}
int main()
{
int n, e;
cin >> n >> e;
for (int i = 0; i < e; i++)
{
int a, b;
cin >> a >> b;
node[a].push_back(b);
node[b].push_back(a);
}
bfs(1);
cout << cnt << endl;
return 0;
}정렬
선택정렬
- 시간복잡도 O(N^2)
데이터가 무작위로 있을 때 이 중에서 가장 작은 데이터를 선택해 맨 앞에 있는 데이터와 바꾸고, 그다음 작은 데이터를 선택해 앞에서 두번째 데이터와 바꾸는 과정을 반복하는 정렬
#include <iostream>
using namespace std;
int n = 10;
int arr[10] = {7, 5, 9, 0, 3, 1, 6, 2, 4, 8};
int main(void) {
for (int i = 0; i < n; i++) {
int min_index = i;
for (int j = i + 1; j < n; j++) {
if (arr[min_index] > arr[j]) {
min_index = j;
}
}
swap(arr[i], arr[min_index]);
}
for(int i = 0; i < n; i++) {
cout << arr[i] << ' ';
}
}삽입정렬
- 시간복잡도 O(N^2) (단, 현재 데이터가 거의 정렬된 상태라면 최대 O(N))
데이터를 하나씩 확인하여 각 데이터를 적절한 위치에 삽입하는 정렬
#include <iostream>
using namespace std;
int n = 10;
int arr[10] = {7, 5, 9, 0, 3, 1, 6, 2, 4, 8};
int main(void) {
for (int i = 1; i < n; i++) {
// 인덱스 i부터 1까지 감소하며 반복하는 문법
for (int j = i; j > 0; j--) {
// 한 칸씩 왼쪽으로 이동
if (arr[j] < arr[j - 1]) {
swap(arr[j], arr[j - 1]);
}
// 자기보다 작은 데이터를 만나면 그 위치에서 멈춤
else break;
}
}
for(int i = 0; i < n; i++) {
cout << arr[i] << ' ';
}
}퀵정렬
- 시간복잡도 O(NlogN)
기준 데이터(pivot)를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 정렬
#include <iostream>
using namespace std;
int n = 10;
int arr[10] = {7, 5, 9, 0, 3, 1, 6, 2, 4, 8};
void quickSort(int* arr, int start, int end) {
if (start >= end) return; // 원소가 1개인 경우 종료
int pivot = start; // 피벗은 첫 번째 원소
int left = start + 1;
int right = end;
while (left <= right) {
// 피벗보다 큰 데이터를 찾을 때까지 반복
while (left <= end && arr[left] <= arr[pivot]) left++;
// 피벗보다 작은 데이터를 찾을 때까지 반복
while (right > start && arr[right] >= arr[pivot]) right--;
// 엇갈렸다면 작은 데이터와 피벗을 교체
if (left > right) swap(arr[pivot], arr[right]);
// 엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체
else swap(arr[left], arr[right]);
}
// 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quickSort(arr, start, right - 1);
quickSort(arr, right + 1, end);
}
int main(void) {
quickSort(arr, 0, n - 1);
for (int i = 0; i < n; i++) {
cout << arr[i] << ' ';
}
}계수정렬
- 시간복잡도 O(N+K)
- 공간복잡도 중복된 데이터가 없을 때 매우 비효율적
정렬해야 하는 최대 데이터만큼의 배열을 선언하고 해당 데이터를 인덱스로 사용하여 값을 증가시킴
#include <iostream>
#define MAX_VALUE 9
using namespace std;
int n = 15;
// 모든 원소의 값이 0보다 크거나 같다고 가정
int arr[15] = {7, 5, 9, 0, 3, 1, 6, 2, 9, 1, 4, 8, 0, 5, 2};
// 모든 범위를 포함하는 배열 선언(모든 값은 0으로 초기화)
int cnt[MAX_VALUE + 1];
int main(void) {
for (int i = 0; i < n; i++) {
cnt[arr[i]] += 1; // 각 데이터에 해당하는 인덱스의 값 증가
}
for (int i = 0; i <= MAX_VALUE; i++) { // 배열에 기록된 정렬 정보 확인
for (int j = 0; j < cnt[i]; j++) {
cout << i << ' '; // 띄어쓰기를 기준으로 등장한 횟수만큼 인덱스 출력
}
}문제풀이
위에서 아래로
sort에 사용할 커스텀 컴페어함수를 만들었다. 이전에 백준에서 비슷한 문제를 풀었었는데 도움됐다. 아래 링크에 있는 문제가 내가 풀었던 문제다.
#include <iostream>
#include <algorithm>
using namespace std;
int arr[500];
bool compare_cus(int a, int b)
{
if (a < b)
return false;
return true;
}
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i++)
cin >> arr[i];
sort(arr, arr + n, compare_cus);
for (int i = 0; i < n; i++)
{
cout << arr[i] << " ";
}
return 0;
}성적이 낮은 순서로 학생 출력하기
utility 헤더의 pair와 vector헤더의 vector를 사용했다. 커스텀 컴페어 함수도 만들었다. dfs/bfs파트에서 풀었던 문제도 pair를 사용했었기 때문에 이번에는 쉽게 풀었다.
#include <iostream>
#include <utility>
#include <vector>
#include <algorithm>
using namespace std;
vector<pair<string, int>>v;
bool compare_cust(pair<string, int>a, pair<string, int>b)
{
if (a.second > b.second)
{
return false;
}
return true;
}
int main()
{
int n, b;
string a;
cin >> n;
for (int i = 0; i < n; i++)
{
cin >> a >> b;
v.push_back({ a,b });
}
sort(v.begin(), v.end(), compare_cust);
for (int i = 0; i < n; i++)
{
cout << v[i].first << " ";
}
return 0;
}두 배열의 원소 교체
로직은 맞는거 같은데 배열로 구현하니까 프로그램이 에러나서 결과가 안 나왔다. ㅋㅋ 그런데 백터로 자료를 수정해도 똑같이 에러가 났다. 에러명은 Debug Assertion Failed! 검색해보니 코드에 문제가 생길수 있다고 판단하면 나는 에러였다. 커스텀 컴페어함수를 수정하니 배열로도 정상적으로 작동됐다. 왜...오류가 날까. 여전히 알다가도 모르겠는 프로그래밍...
수정 전
#include <iostream>
#include <algorithm>
using namespace std;
int a[100001];
int b[100001];
bool com_cus(int a, int b)
{
if (a < b)
return false;
return true;
}
int main()
{
int n, k;
long long int ans;
cin >> n >> k;
for (int i = 0; i < n; i++)
{
cin >> a[i];
}
for (int i = 0; i < n; i++)
{
cin >> b[i];
}
sort(a, a + n);
sort(b, b + n, com_cus);
for (int i = 0; i < k; i++)
{
if (a[i] < b[i])
swap(a[i], b[i]);
else
break;
}
ans = 0;
for (int i = 0; i < n; i++)
ans = ans + a[i];
cout << ans << "\n";
return 0;
}수정 후
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int a[100001];
int b[100001];
bool com_cus(int a, int b)
{
return a > b;
}
int main()
{
int n, k;
long long int ans;
cin >> n >> k;
for (int i = 0; i < n; i++)
{
cin >> a[i];
}
for (int i = 0; i < n; i++)
{
cin >> b[i];
}
sort(a, a+n);
sort(b, b+n, com_cus);
for (int i = 0; i < k; i++)
{
if (a[i] < b[i])
swap(a[i], b[i]);
else
break;
}
ans = 0;
for (int i = 0; i < n; i++)
ans = ans + a[i];
cout << ans << "\n";
return 0;
}3273 두 수의 합

처음에는 이중for문 사용해서 풀었다. 시간 초과해서 틀렸다. 백준 내 질문 검색으로 찾아보니 투포인터 이용해서 풀라고 했다. 투포인터?라고 하면 quick sort만 생각나는데, 인덱스 양끝에 포인트를 둬서 구하는거다. 이름 그대로 빠른 정렬이라 복잡도 측면에서 좋은 알고리즘이었는데 시간초과 이슈가 있었기 때문에 여기서 영감을 얻었다. 결과는 맞았습니다~!ㅎㅎ
[ 수정 전]
#include <iostream>
#include <algorithm>
using namespace std;
int main()
{
int n, m, x, cnt;
int arr[100001];
cin >> n;
for (int i = 0; i < n; i++)
{
cin >> m;
arr[i] = m;
}
sort(arr, arr + n);
cin >> x;
cnt = 0;
if (n > 1)
{
for (int i = 0; i < n - 1; i++)
{
for (int j = i + 1; j < n; j++)
{
if (arr[i] + arr[j] == x)
cnt++;
}
}
}
cout << cnt << endl;
return 0;
}[수정 후]
#include <iostream>
#include <algorithm>
using namespace std;
int arr[100001];
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
int n, x, cnt, left, right;
cin >> n;
for (int i = 0; i < n; i++)
cin >> arr[i];
sort(arr, arr + n);
cin >> x;
cnt = 0;
left = 0;
right = n - 1;
while (left < right)
{
if (arr[left] + arr[right] == x)
{
cnt++;
right--;
}
else if (arr[left] + arr[right] > x)
right--;
else
left++;
}
cout << cnt << "\n";
return 0;
}