메타 데이터 종류
● 기술용 메타데이터
- 정보 자원의 검색을 목적으로 하는 메타데이터
- 발견, 식별, 선정, 병치, 평가, 링크, 가용성
- 전통적 도서관 인덱스 역할● 관리용 메타데이터
- 자원 관리를 용이하게 하기 위한 메타데이터
- 보존용 메타데이터의 요소 ● 구조용 메타데이터
- 복합적인 디지털 객체들을 묶어주기 위한 메타 데이터
- 오디오와 텍스트 결합 (Ex.오디오 + EBook)1. 데이터 정제
[데이터 모순점 발견]
-
잘못 설계된 데이터 입력폼이 존재
-
데이터 입력에서 사람의 실수로 발생
-
응답자가 자신의 정보를 숨기기 위한, 의도적인 오류
-
만료된 데이터 (바뀐 주소)
-
데이터 표현의 모순 (동일주소, 다른 우편번호)
-
일치하지 않는 코드의 사용
-
데이터를 기록하는 계측 장치의 오류나 시스템 오류4
[데이터 통합]
- 서로 다른 데이터 세트가 호환 가능하도록 통합
메타데이터 활용의 중요
EX.
A 데이터베이스 성별값 : M, F 사용
B 데이터베이스 성별값 : 1, 2 사용
--> 종합적으로 판단하여 통합해야함
--> 다른 부작용이 생기지 않는지도 파악해야함
-데이터 값 충돌 탐지 및 해결
동일한 개체(item)에 대해서도 속성 값이 다를 수 있음
EX. 거리 단위 : m , km
--> 여러 유형의 문제들을 신중하게 해결하여 통합 데이터의 중복과 불일치 문제를 최소화
-중복해결
일반적으로 데이터베이스 성능을 높이기 위해 유도속성 도입 -> 중복허용
유도속성은 성능향상에 도움이 되지만 데이터 중복을 허용하는 과정으로 데이터 불일치 문제 발생
[데이터 변환]
-데이터를 다른 형식이나 다른 구조로 변환
● 수치형 데이터 이산화
--> 엔트로피-기반 이산화
--> 카이제곱 결합
● 범주형 데이터 계층화
--> 상위 개념으로 일반화
[데이터 축소]
: 데이터 용량을 줄이되, 내용/결과는 동일하게 유지
○ 속성 부분 집합 선택
-
소모적 탐색법
-
경험적 방법
○ 차원 축소(변수 축소)
-
주성분 분석
-
웨이블릿 변환
○ 수량 축소 (레코드 축소)
: 위험한 방법이 될 수 있다
-
표본 추출
-
히스토그램
-
군집화
2. 데이터 파이프라인
개념
: 다양한 원본에서 데이터를 수집하고
: 비즈니스 규칙에 따라 데이터를 변환하고
: 대상 데이터 저장소로 로드하는 데 사용되는 데이터 파이프라인
★ 데이터 ETL 파이프라인 (Extract, Transform, Load)
: 다양한 원본에서 데이터 수집
: 비즈니스 규칙에 따라 데이터 변환
: 대상 데이터 저장소로 로드하데 사용되는 데이터 파이프라인
--> 비교적 저용량 데이터 수집에 적합
--> "변환 후 저장" 개념 : 변환에 시간이 걸리므로, 실시간 처리가 어려움
--> 기존 서버 구조에는 적합
하지만 현대에 와서 LOAD와 Transform을 한꺼번에 하는 방법인..
★ 데이터 ELT 파이프라인 (Extract, Load, Transform)
: ETL과 다르게 별도 변환 엔진을 사용하는 대신 --> 클라우드로 가능!
: 대상 데이터 저장소의 처리 기능을 사용하여
: 데이터를 변환하는 데이터 파이프라인
--> 데이터 -> 일단 저장 -> 나중에 필요하면 변환하자
--> 요구사항 1:일단 저장 - 대용량 저장 공간 필요
--> 요구사항 2:필요하면 변환 - 컴퓨팅 파워가 있는 저장 공간 필요
--> 결과적으로, 클라우드 환경에 적합
--> 장점 : 대용량 데이터, 실시간 처리 가능한 효과적인 파이프라인
[Cloud Computing]
-고성능 컴퓨터/서비스를 대여하자
-data center
3. 데이터 저장
3-1. 네트워크 스토리지
네트워크를 통해서 클라이언트들이 접근하여
데이터를 저장, 복사하는 등
디스크 작업을 할 수 있는 저장장치
EX. 넷플릭스 서비스
전세계 AWS 클라우드 서버에 분산 저장
구성유형
● DAS Direct Attached Storage
-외장 하드와 같이
-PC / 서버 컴퓨터에 직접 연결해서 사용하는 스토리지
-서버-스토리지가 1:1로 직접 연결
-각 서버는 직접 파일 시스템을 관리
-빠르고, 확장하기 쉽지만, 용량에 한계
● NAS Network Attaced Storage
-서버-네트워크-스토리지 구조로 간접 연결되는 방식
-스토리지는 보통 전용 운영체제로 데이터 저장 전용 컴퓨터처럼 작동
-장점 : 확장성, 유연성, 경제적, 설치/유지보수 용이
-단점 : 반응속도 느림, 보안 취약, 백업 어려움
● SAN Storage Area Netowork
-스토리지 디바이스 풀을 상호 연결하여 여러 서버에 동시 제공
-전용 고속 네트워크를 활용한 스토리지
-NAS 보다 고속의 광채널 스위치로 연결
-별도의 SAN 스위치가 반드시 필요(단 비용이 고가..)
● SDS Software Defined Storage
-네트워크를 통해서 클라이언트들이 접근하여 데이터를 저장, 복사 등 디스크 작업을 할 수 있는 저장장치
-소프트웨어로 구현된 컨트롤러가 전체 저장장치 시스템을 관리하는 방식
-스토리지 가상화 : 물리자원을 통합하여 단일 POOL 구성
-다양한 인터페이스 : 블록, 오브젝트, 파일의 다양한 저장장치 인터페이스 제공
-정책 기반 관리를 통해 사용자 요구에 부합하는 저장장치 자원 할당
[스토리지 서비스 유형]
○ 블록 스토리지
: 균등한 크기로 정의된 블록에 데이터를 저장
○ 파일 스토리지
: 네트워크를 이용한 파일 공유 목적
: 서버와 클라이언트 구조
: 클라이언트가 마운트(mount) 방식으로 파일 사용
○ 오브젝트 스토리지
: 오프젝트 = 데이터 본체 + 부가정보
: 데이터 본체 : 파일과 유사
: 부가 정보 : 메타 데이터
: 오브젝트 단위로 처리
3-2. 데이터 웨어하우스
DataWarehouse(DW)
: 기업의 대단위 데이터를 사용자 관점에서 주제별로 통합하여 축적하여 별도의 장소에 저장해 놓은 자료
: 단순한 데이터의 저장고가 아니라, 관계형 DB를 근간으로 많은 데이터를 다차원 분석하여 의사결정에 도움을 주는 시스템
소스데이터로부터 자료를 이관하는 ETT/ELT과 ODS, 마트데이터 등으로 구성
데이터 마트 ⊂ 데이터 웨어하우스(주제형 창고)
[DW 구성]
○ ODS Operational Data Store 운영계 정보 저장소
: 비즈니스 프로세스/AP 중심적 데이터
: 기업의 실시간성 데이터르 추출/가공/전송을 거치지 않고 DW에 저장
○ DW DB
: 어플리케이션 중립적, 주제 지향적/불변적/통합적/시계열적 공유 데이터 저장소
○ Data Mart
: 특화된 소규모의 DW(부서별, 분야별)
: 특정 비즈니스 프로세스, 부서, AP 중심적인 데이터 저장소
○ OLAP (Oline Analytical Processing)
: 온라인 처리 분석, 사용자가 대화형, 다양한 방식으로 데이터 분석
[DW 구축단계 및 구축방법]
비즈니스 요구사항 정의
↓
데이터 모델링
↓
데이터소스 확인 및 식별
↓
데이터 추출 변환
↓
데이터웨어하우스 구축
↓
사용자 교육
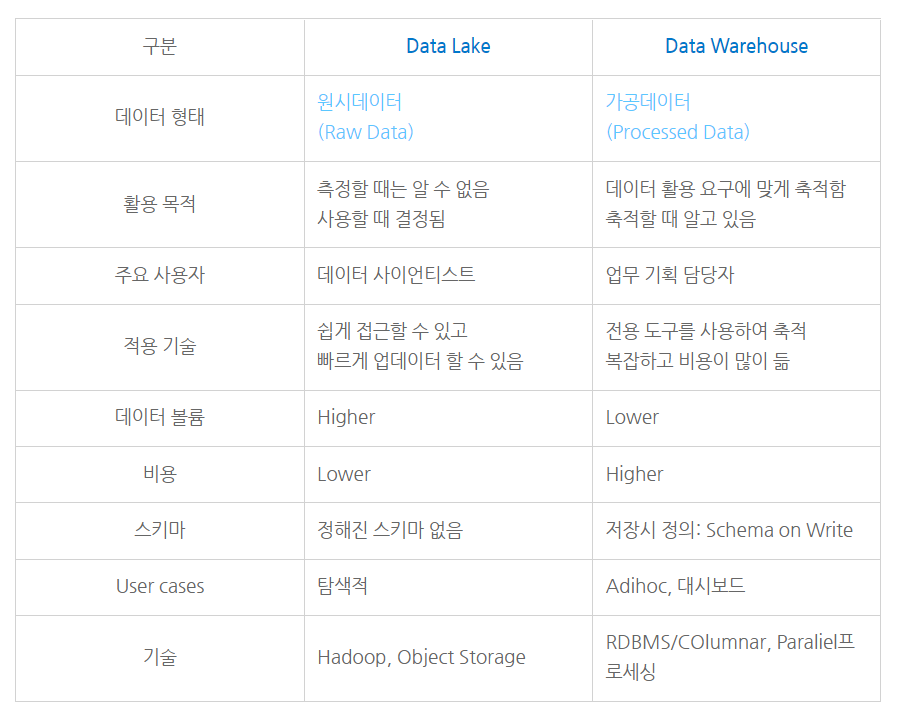
3-3. 데이터 레이크
DataLake
: 대용량의 정형 및 비정형 데이터를 원시형태 그대로 저장하고 손쉽게 접근할 수 있게하는 대규모 저장소 (리포지토리 - 이력관리)