컬렉션 프레임워크
- 자료구조들을 자바 클래스로 구현한 모음집으로 오랫동안 jvm에 최적화 시켜놔서 그냥 사용하면 됨
- 장점
- 인터페이스와 다형성을 이용한 oop 설계로 표준화되어서 재사용하기 좋음
- 데이터 구조와 알고리즘 고성능 구현을 제공해줌
- 참고로 컬렉션 프레임워크에는 오로지 객체만 저장할 수 있어서 기본 자료형은 저장 못함. 저장하려면 wrapper 타입으로 변환해 Integer 객체나 Double 객체로 boxing해 저장해야됨.
- 컬레션 프레임워크는 두개로 나뉨 1.Collection 인터페이스(Collection의 인터페이스는 공통적인 부분이 많아서 하나로 묶음)
- 참고로 순회할때 사용하는 객체
Iterable을 상속받았으므로 Iterable 사용 가능함
- Map 인터페이스(Map은 key,value로 달라서 나뉨)
- Iterable을 상속받지 않아서 사용 못함. 대신에 stream을 사용하거나 key를 collections으로 반환 후 루프문으로 순회함
- 참고로 순회할때 사용하는 객체
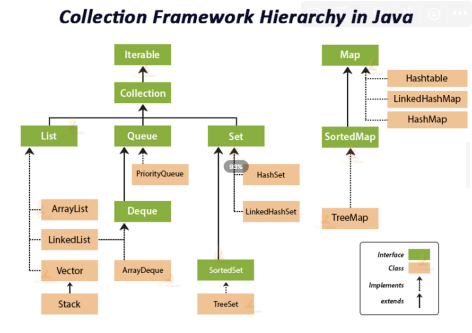
Collection 인터페이스
- 실질적인 최상위 컬렉션 타입으로, 해당 인터페이스에 기본적인 삽입/삭제/탐색 등의 메소드가 선언되어있어 업캐스팅으로 다양한 종류의 컬렉션 자료형을 받아 사용 할 수 있음(다형성)
참고로 자바 1.8부터는 함수형 프로그래밍을 위해 parallelStream, stream, forEach 디폴트 메소드 등이 추가됨.
get()메소드는 이 인터페이스들에게 선언이 안되어있음. 왜냐면 순서가 없는 Set 인터페이스같은 경우 인덱스에 저장된 값을 리턴할 수 없음. ISP(인터페이스 분리 원칙)에 따라 공통된 기능만 구현하려고.
List 인터페이스
- 저장 순서가 유지되고 같은 요소의 중복 저장이 허용됨
- 배열과 다른점은, List는 자료형 크기가 고정이 아니고 동적으로 변한다는 점+요소들 사이에 빈 공간이 허용되지 않아 중간을 삭제하면 원소들이 앞으로 이동함
ArrayList 클래스 vs LinkedList 클래스
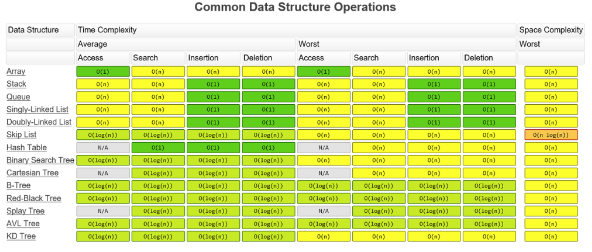
- Array: 조회는 인덱스로 바로 할 수 있어서 O(1)이지만 중간 삽입/삭제는 O(n)
- LinkedList: 조회 메소드
get(index)의 실제 코드를 보면 for문으로 돌아서 찾기 때문에 O(n)임. ArrayList의 삽입/삭제 문제를 O(1)로 해결해줌.- List 인터페이스와 Queue 인터페이스를 동시에 상속받고 있어서 stack,queue로도 사용할 수 있음(실제로 스택/큐와 관련된 메소드를 지원해줌=push(),pop(),poll(),offer(),peek() 등)
- 실제 스택,큐는 LinkedList를 쓰는지 코드 보자~
- stack, queue, tree 등의 구조의 근간이 됨
- List 인터페이스와 Queue 인터페이스를 동시에 상속받고 있어서 stack,queue로도 사용할 수 있음(실제로 스택/큐와 관련된 메소드를 지원해줌=push(),pop(),poll(),offer(),peek() 등)
Vector 클래스
- arrayList의 구형 버전으로 거의 비슷하지만 유일하게 다른 점이 모든 메소드가 동기화(synchronized)되어 있어 thread-safe하다는 점
- 잘 쓰이지 않음. 컬렉션에 동기화가 필요하면
Collections.synchronizedList()메소드를 사용해 arrayList를 동기화함
Stack 클래스
Vector를 상속해 만들어진 클래스라 실제로 잘 안쓰이고 대신ArrayDeque를 사용함
Queue 인터페이스
- LinkedList를 기반으로 구현이 되었나 확인?????
PriorityQueue 클래스
- 우선 순위를 가지는 큐로, 각 원소마다 우선순위를 부여해 우선순위가 높은 순으로 정렬되고 꺼내짐(우선순위의 값이 작을수록 우선순위는 높은 거임)
- 수행할 작업이 여러개 있고 시간이 제한되어있을때 우선순위순으로 수행할때 사용됨(네트워크 제어, cpu 스케줄링)
- 여기에 저장할 객체는 무조건
Comparable인터페이스를 구현해야함. - null 저장이 불가능함
- 저장공간으로 배열을 사용하고 각 요소를 힙 형태로 저장한다 ??????
- 힙은 이진트리의 한 종류로 우선순위가 가장 높은 자료를 루트 노드로 갱신한다는 점으로, 가장 큰 값/작은값을 빠르게 찾을 수 있음
- 직접 객체 생성
// 우선순위 큐에 저장할 객체는 필수적으로 Comparable를 구현 class Student implements Comparable<Student> { String name; // 학생 이름 int priority; // 우선순위를 저장필드가 있어야함 public Student(String name, int priority) { this.name = name; this.priority = priority; } @Override public int compareTo(Student user) { // Student의 priority 필드값을 비교하여 우선순위를 결정하여 정렬 if (this.priority < user.priority) { return -1; } else if (this.priority == user.priority) { return 0; } else { return 1; } } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", priority=" + priority + '}'; } } // 우선순위가 가장 높은 값을 참조 System.out.println(priorityQueue.peek()); // Student{name='홍길동', priority=1} // 차례대로 꺼내기(우선순위 높은 순대로 자동정렬되어있어서 그거 순서대로 꺼내짐..) System.out.println(priorityQueue.poll()); // Student{name='홍길동', priority=1} System.out.println(priorityQueue.poll()); // Student{name='임꺽정', priority=2}
Deque 인터페이스
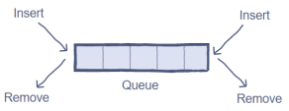
- 스택과 큐를 합쳐놓은것 같아 스택으로 사용할 수도 있고 큐로 사용할 수도 있음
- 구현체로
ArrayDeque와LinkedList가 있음
ArrayDeque 클래스
- 스택으로 사용할땐 stack 클래스보다 빠르고(
push(),pop()), 대기열로 사용할때는 LinkedList 보다 빠름(offer(),poll()) - 사이즈에 제한이 없음
- null은 저장 안됨
Set 인터페이스
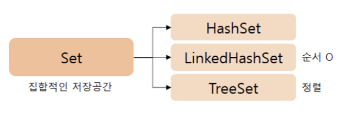
- 중복이 없고 순서를 유지하지 않음.→ 따라서
get(index)도 존재할 수 없음- 중복이 안되므로
null도 하나만 저장할 수 있음
- 중복이 안되므로
HashSet 클래스
- 배열+연결 노드를 결합한 자료구조 형태
- 추가/삭제/검색 등 전반적으로 매우 빠르나 순서를 알 수가 없음
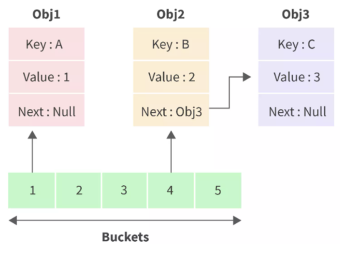
- 버킷(배열)에 저장하지만 그 버킷 안은 연결 리스트로 되어있음
LinkedHashSet 클래스
- 중복은 여전히 안되지만 순서는 유지되는 set 구현 클래스
TreeSet 클래스
- 이진 검색 트리 자료구조로 데이터가 저장됨
- set 인터페이스 그대로 중복 불가하고 순서도 없으나, 데이터가 자동 정렬되어 저장되어있음→그래서 검색, 범위 검색이 빠름
enumSet 추상 클래스
- enum 클래스와 함께 동작하는 set 컬렉션으로, 중복되지 않은 상수 그룹을 나타낼떄 사용됨
enum Color {
RED, YELLOW, GREEN, BLUE, BLACK, WHITE
}
public class Client {
public static void main(String[] args) {
// 정적 팩토리 메서드를 통해 RegularEnumSet 혹은 JumboEnumSet 을 반환
// 만일 enum 상수 원소 갯수가 64개 이하면 RegularEnumSet, 이상이면 JumboEnumSet 객체를 반환
EnumSet<Color> enumSet = EnumSet.allOf(Color.class);
for (Color color : enumSet) {
System.out.println(color);
}
enumSet.size(); // 6
enumSet.toString(); // [RED, YELLOW, GREEN, BLUE, BLACK, WHITE]
}
}Map 인터페이스
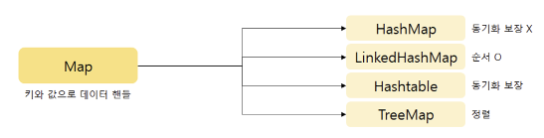
- (key,value) 쌍으로 이뤄진 데이터 집합으로, 저장 순서가 유지되지 않음
- key는 중복될수 없으나 value는 중복될 수 있음. 만약 key가 중복돼서 저장되면 가장 마지막에 저장한 값이 저장됨
- 실제로
entrySet(),keySet()같이 key를 리턴하는 함수는 중복이 허용되지 않아서 Set 타입이고,values()같이 value를 리턴하는 함수는 중복이 허용돼서 Collection 타입으로으로 반환됨
- 실제로
Map.Entry 인터페이스 <<<<뭔지?
- Map 인터페이스 안에 있는 내부 인터페이스로, Node 내부 클래스에서 이를 구현함
- map 자료구조를 보다 객체지향적인 설계를 하려고 사용함
Map<String,Integer> map=new HashMap<>();
map.put("a",1);
System.out.println(map); // {a=1}
Set<Map.Entry<String, Integer>> entry = map.entrySet();
System.out.println(entry); // [a=1]HashMap 클래스
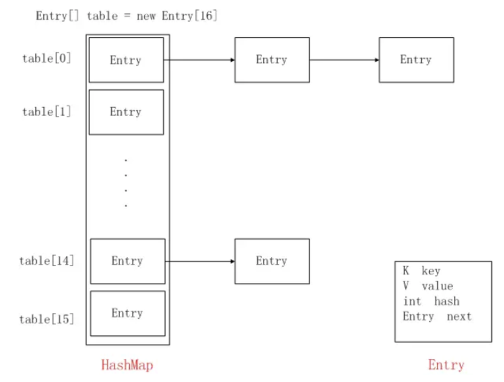
- Hashtable을 보안한 컬렉션으로, 배열과 연결리스트가 결합된 hashing 형태로, 키와 값을 하나의 데이터로 저장함
- 중복 허용 안되고 순서도 보장 안됨
- 키와 값으로 null이 허용됨
- HashMap은 비동기로 작동해 멀티 스레드 환경에서는 어울리지 않음(
currentHashMap을 사용함) - 참고로 이 클래스 포함
Hash~로 시작하는 자료형은 해당 자료형에 내가 만든 객체를 저장한다면 그 객체에hashCode()와equals()메소드를 재정의해서 모두 true가 나와야 동등 객체로 판별해줌 =직접 만든 클래스라면 같은 객체로 판별하기 위해hashCode(),equals()를 재정의하자- 다만 String 문자열은 기본적으로 재정의 되어있어 같은 문자열일 경우 동등한 객체로 판별돼서 값이 덮어씌워질 수 있음
LinkedHashMap 클래스
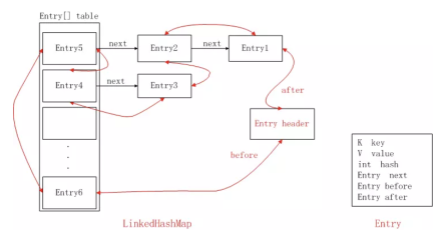
- HashMap을 상속하기 때문에 흡사하지만 entry들이 연결리스트를 구성해서 데이터의 순서가 보장됨
TreeMap 클래스
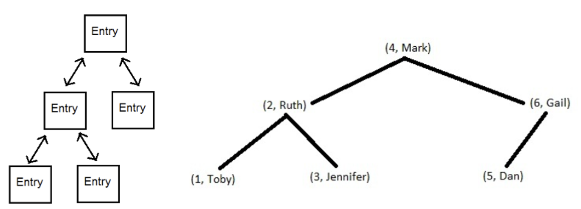
- 이진 검색 트리 형태로 키와 값으로 데이터가 저장됨(treeSet과 같은 원리)
sortedMap인터페이스를 구현하고 있어서 key값을 기준으로 정렬되어 있음→ 그래서 검색 빠름→ 키와 값 저장+정렬해야돼서 저장시간이 오래 걸림
HashTable 클래스
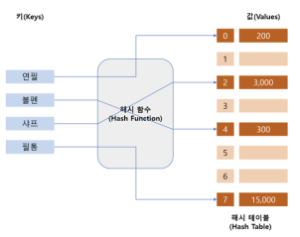
- 자바 초기에 나온 레거시 클래스로, key를 해시 함수로 해싱한 후에 배열의 인덱스로 사용했음
- HashMap보다 느리지만 vector(synchronized)처럼 동기화된 메소드로 구성되어 있어 멀티 스레드에서 안전함
Properties 클래스
- 환경 설정과 관련된 속성파일인
.properties를 읽거나 설정할때 사용함
컬렉션 프레임워크 선택 시점
지금 까지 자바의 컬렉션 프레임워크 자료구조 종류에 대해 간단히 알아보았다. 워낙 종류도 많고 똑같은 자료구조 이지만 각 쓰임새와 특징에 따라 나누니 정리하기가 까다롭다.
그렇다고 컬렉션 마다 일일히 특징을 외우기 보다는, 아래 그림을 통해 언제 어느때에 어떤 컬렉션을 선택하여 사용하면 좋을지 추적해보자.

- ArrayList
- 리스트 자료구조를 사용한다면 기본 선택
- 임의의 요소에 대한 접근성이 뛰어남
- 순차적인 추가/삭제 제일 빠름
- 요소의 추가/삭제 불리
- LinkedList
- 요소의 추가/삭제 유리
- 임의의 요소에 대한 접근성이 좋지 않음
- HashMap / HashSet
- 해싱을 이용해 임의의 요소에 대한 추가/삭제/검색/접근성 모두 뛰어남
- 검색에 최고성능 ( get 메서드의 성능이 O(1) )
- TreeMap / TreeSet
- 요소 정렬이 필요할때
- 검색(특히 범위검색)에 적합
- 그래도 검색 성능은 HashMap보다 떨어짐
- LinkedHashMap / LinkedHashSet : HashMap과 HashSet에 저장 순서 유지 기능을 추
- Queue : 스택(LIFO) / 큐(FIFO) 자료구조가 필요하면 ArrayDeque 사용
- Stack, Hashtable : 가급적 사용 X (deprecated)
stack vs queue
- stack: LIFO
- queue: FIFO, 인터페이스로 가장 대표적인 구현 클래스가
PriorityQueue임
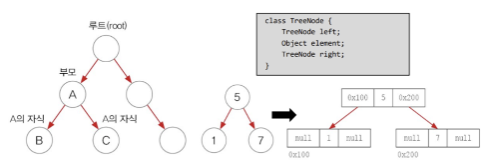
Tree
List,queue등 연속적으로 값이 저장되는 선형 구조가 아닌 비연속적으로 값이 저장되는 비선형 자료구조- 대표적으로 이진트리, BST(Binary Search Tree)가 있음
- 이진 트리: 포화 이진 트리, 완전 이진 트리, 정 이진 트리
- BST(Binary search Tree): 효율적인 탐색을 위해 왼쪽 자식 노드와 오른쪽 자식 노드에 각기 작은 값과 큰 값을 저장해놓고 찾는 트리를 의미함. (이걸 위해 배열보다 데이터를 저장할 메모리 영역을 많이 사용함)
- 그러나 오름차순이거나 내림차순일떄처럼 한쪽으로만 노드가 추가되는 상황에서는 공간 복잡도를 늘인게 허무해질정도로 시간 복잡도가 비효율적이게 됨. 해결하려면 이진 트리에서 균형을 잡아야되는데 이걸 rebalancing이라 하고 가장 대표적인 리밸런싱이 레드 블랙 트리임
- binary heap=최대힙/최소힙
- tree형식으로 된 완전 이진 트리임. 정렬이 되어있어 검색이 쉬움
- 레드 블랙 트리=RBT
- BST를 기반으로 구현했고 거기서 최대한 균형있게 완전 이진 트리로 구현하는 트리. 덕분에 BST의 depth를 최소화해서 시간복잡도를 줄일 수 있음
- 각 노드에 레드,블랙 색상을 둠
- RBT 는 BST 의 삽입, 삭제 연산 과정에서 발생할 수 있는 문제점을 해결하기 위해 만들어진 자료구조이다. 이를 어떻게 해결한 것인가?
Collection에서 TreeMap,HashMap에도 사용되는 자료구조로 매우 중요한 자료구조임
HashTable
- 내부적으로 배열을 사용해서 데이터를 저장함→ 검색이 매우 빠름(데이터 고유의 인덱스로 찾기 때문에 O(1)). 근데 문제는 이 고유의 인덱스에 저장되는 key값이 너무 불규칙함→ 그래서 특별한 알고리즘을 사용해 저장할 데이터와 연관된 고유의 숫자를 만들고 이를 인덱스로 사용함
- 여기서
Hash가 바로 특별한 알고리즘인 해시 함수를 의미함. 그리고 이 해시함수에 의해 반환된 고유의 값을hashcode라고 함 - 하지만 문제는 어설픈 해시 함수를 통해서 key 값을 결정하면 동일한 값이 나오는 경우가 발생함. 동일한 key값에 여러개의 데이터가 존재하는거가 바로
collision임 - 그렇다면 어떤 조건을 만족해야 좋은 해시 함수가 되는가?
- 해시 함수는 키의 일부분이 아니라 키 전체로 해시 값을 만들어야 함.
- 어짜피 해시 함수를 1:1로 만드는건 현실적으로 불가능하고 그렇게 만들어봤자 필요한 메모리 용량도 커지고 array와 다를게 없음. 결국은 collision을 최소화하는 방향으로 만들고 어쨌든 collision이 발생할텐데 이걸 어떻게 처리할지가 중요한 해시 함수를 결정함=최대한 적은 collision이 발생하는 해시 함수를 만들고 collision이 발생했을떄 어떻게 할지가 중요하다~
- 그렇다면 collision 발생시 어떻게 해야될까?= 해싱된 인덱스에 이미 다른값이 있다면 새 데이터를 저장할 위치를 어떻게 찾아야될까?
- open address(개방 주소법)
- 해시 충돌(collision)이 발생하면 다른 해시 버킷(데이터 저장하는 공간)에 자료를 저장하는 방법
- linear probing: 순차적으로 탐색해 비어있는 버킷을 찾을때까지 계속 진행함
- quadratic probing: 2차 함수를 이용해 탐색할 위치를 찾음
- double hashing probing: 하나의 해시 함수에서 충돌이 발생하면 2차 해시 함수를 이용해 새로운 주소를 할당함. 가장 많은 연산량이 요구됨
- 근데 worst case로 이런 과정을 거쳤는데도 비어있는 버킷을 못찾고 탐색을 시작한 처음 위치로 되돌아올 경우가 발생할 수 있음
- 해시 충돌(collision)이 발생하면 다른 해시 버킷(데이터 저장하는 공간)에 자료를 저장하는 방법
- separate chaining(분리 연결법)
- 해시 버킷을 채운 밀도가 높아질수록 worst case 발생 빈도가 높아지는 open chaining 기법과 비교해, 이 방식은 보조 해시 함수를 조절해 worst case를 줄일 수 있어서 open chaining보다 훨씬 빠름
- separate chaining을 구현하는 방식
- LinkedList를 사용한 방식
- 버킷들을 LinkedList로 만들고 만약 collision이 발생하면 해당 버킷에 새로운 list를 추가하는 방식(연결 리스트 특징인 삽입과 삭제가 쉬우나 그 단점인 작은 데이터들을 저장할때는 연결 리스트 자체의 오버헤드가 부담이 됨)
- RBT를 사용한 방식
- LinkedList 대신에 tree를 사용하는 방식. tree가 linkedList보다 메모리 사용량이 많기 때문에 적은 데이터는 LinkedList를 사용하는 방식을 이용해야됨.
- LinkedList를 사용한 방식
- open address(개방 주소법)
