📌 문제 설명
문자열
s가 주어졌을 때,s의 각 위치마다 자신보다 앞에 나왔으면서, 자신과 가장 가까운 곳에 있는 같은 글자가 어디 있는지 알고 싶습니다.
예를 들어, s="banana"라고 할 때, 각 글자들을 왼쪽부터 오른쪽으로 읽어 나가면서 다음과 같이 진행할 수 있습니다.
- b는 처음 나왔기 때문에 자신의 앞에 같은 글자가 없습니다. 이는 -1로 표현합니다.
- a는 처음 나왔기 때문에 자신의 앞에 같은 글자가 없습니다. 이는 -1로 표현합니다.
- n은 처음 나왔기 때문에 자신의 앞에 같은 글자가 없습니다. 이는 -1로 표현합니다.
- a는 자신보다 두 칸 앞에 a가 있습니다. 이는 2로 표현합니다.
- n도 자신보다 두 칸 앞에 n이 있습니다. 이는 2로 표현합니다.
- a는 자신보다 두 칸, 네 칸 앞에 a가 있습니다. 이 중 가까운 것은 두 칸 앞이고, 이는 2로 표현합니다.
따라서 최종 결과물은 [-1, -1, -1, 2, 2, 2]가 됩니다.
문자열s이 주어질 때, 위와 같이 정의된 연산을 수행하는 함수 solution을 완성해주세요.
✔️ 제한사항
- 1 ≤ s의 길이 ≤ 10,000
s은 영어 소문자로만 이루어져 있습니다.
✏️ 입출력

💡 코드
✅ 각 문자의 이전 인덱스에 위치한 문자들 중 같은 문자가 존재하는 경우, 두 문자열 간 인덱스 차이
idx는이번 문자 인덱스 - 이전 문자 인덱스이다. 같은 문자 중 가장 가까운 거리를 출력하라 했으므로, 같은 문자가 여러 개인 경우 최솟값을 저장해야 한다. 이 때, 조건에서s의 최대 길이가 10,000으로 주어졌기 때문에idx의 초기값을 임의로 가장 큰 값 10000으로 설정하였다.
판별을 마친 후,idx가 초기값인 10000이 아니면 같은 문자가 존재한다는 뜻이므로 가까운 거리idx를 저장하고, 초기값 그대로라면 같은 문자가 없다는 뜻이므로 -1을 저장한다.
class Solution {
public int[] solution(String s) {
int[] answer = new int[s.length()];
for(int i=0;i<answer.length;i++) {
int idx = 10000;
for(int j=0;j<i;j++) {
if(s.charAt(j) == (s.charAt(i)))
idx = Math.min(idx, i-j);
}
answer[i] = (idx != 10000)? idx : -1;
}
return answer;
}
}
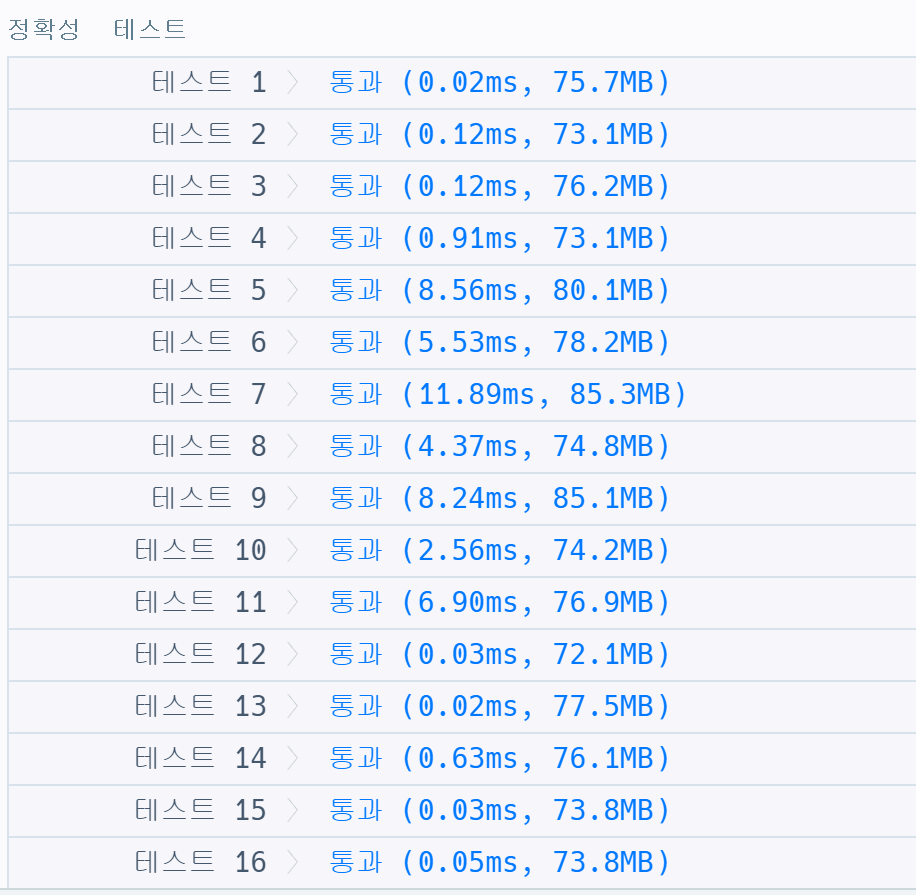
✅ 위 코드를 수행하면 처음부터 이전 문자까지 모든 인덱스를 탐색해야 하기 때문에, 문자열의 길이가 길어질수록 반복의 횟수가 많아져서 실행 시간이 계속 늘어나게 된다,,
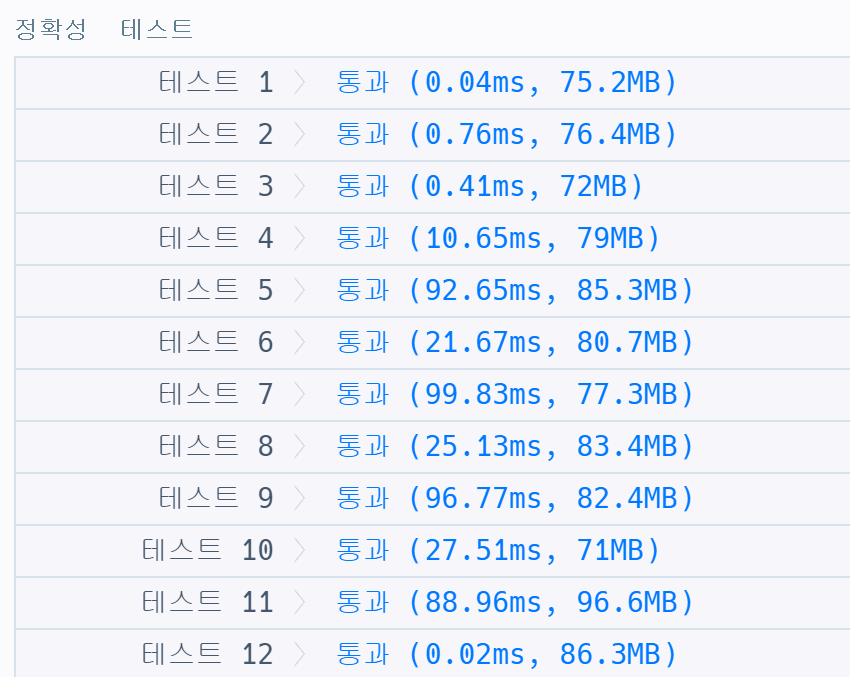
이를 해결하기 위해 이전 문자들을 처음부터 탐색하는 것이 아닌 바로 이전 문자부터 처음 문자 순서로 탐색을 수행하게 수정해보았다. 어차피 가장 가까운 같은 문자를 찾는 것이므로, 역순으로 탐색을 하다가 같은 문자가 나타나게 되면 해당 문자가 가장 가까운 같은 문자이므로idx에 거리를 저장하고 break문을 통해 반복문을 종료하여idx가 0이면 -1, 0이 아니면 거리idx를 저장하게 하였다. 이렇게 수정하니 실행 시간이 거의 1/10로 줄어들었다!
class Solution {
public int[] solution(String s) {
int[] answer = new int[s.length()];
for(int i=0;i<answer.length;i++) {
int idx = 10000;
for(int j=0;j<i;j++) {
if(s.charAt(j) == (s.charAt(i)))
idx = Math.min(idx, i-j);
}
answer[i] = (idx != 10000)? idx : -1;
}
return answer;
}
}