Text Preprocessing
컴퓨터가 텍스트를 이해할 수 있도록 하는 Data Preprocessing 방법
• HTML 태그, 특수문자, 이모티콘
• 정규표현식
• 불용어 (Stopword)
• 어간추출(Stemming)
• 표제어추출(Lemmatizing)
Preprocessing Pipeline
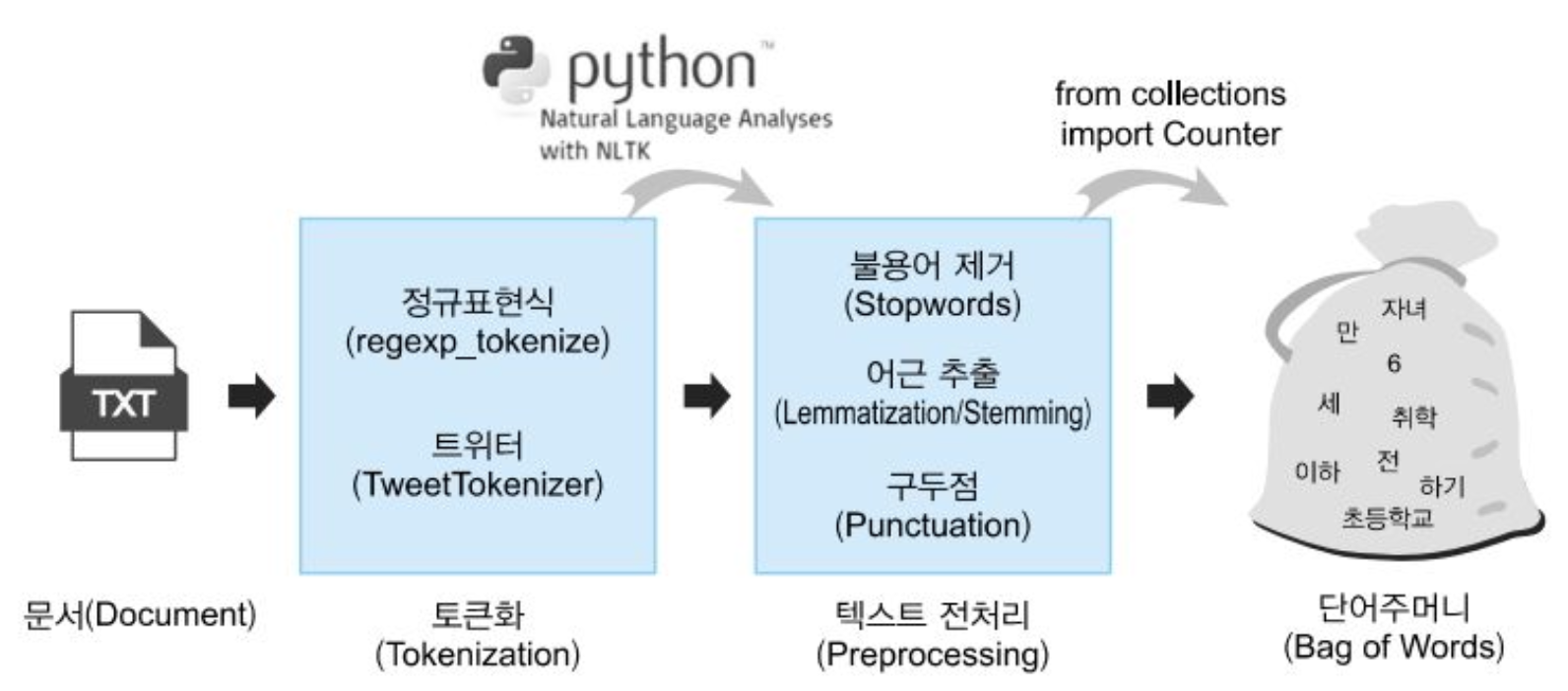
Tokenization
• 주어진 데이터를 토큰(Token)이라 불리는 단위로 나누는 작업
• 토큰이 되는 기준은 다를 수 있음(어절, 단어, 형태소, 음절, 자소 등)
• Character-based Tokenization / Word-based Tokenization / Subword-based Tokenization
문장 토큰화(Sentence Tokenizing)
• 문장 분리

단어 토큰화(Word Tokenizing)
• 구두점 분리, 단어 분리
“Hello, World!” -> “Hello”, “,”, “World”, “!”
Why Tokenize?
단어 의미를 밀집 벡터로 표현하기 위해 단어들을 사전화
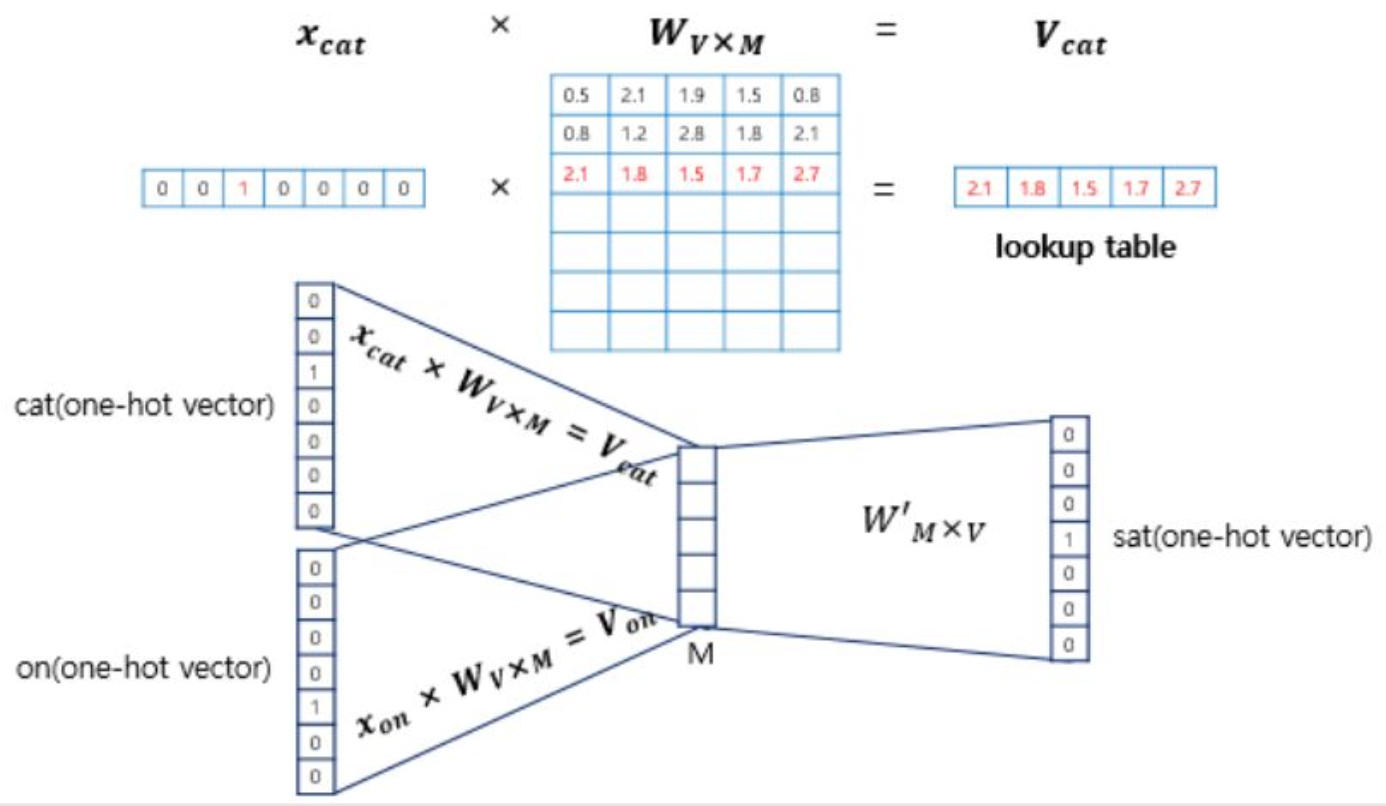
토큰화 시 고려사항
-
구두점이나 특수 문자를 단순 제외
ex. 21/02/06 -> 날짜 , $100,000 -> 돈을 나타낼 때 -
줄임말과 단어 내 띄어쓰기
ex. we're -> we are 의 줄임말
rock n roll -> 하나의 단어지만 띄어쓰기가 존재 -
문장 토큰화: 단순 마침표를 기준으로 자를 수 없음
ex. 서버에 들어가서 로그 파일 저장하고 메일로 결과 좀 보내줘. 그러고나서 점심 먹으러 가자.
한국어 토큰화의 어려움
영어는 New York과 같은 합성어나 he's 와 같이 줄임말에 대한 예외처리만 한다면, 띄어쓰기를 기준으로 하는 띄어쓰기 토큰화를 수행해도 단어 토큰화가 잘 작동
-
영어와는 달리 한국어에는 조사라는 것이 존재
ex. '그가', '그에게', '그를', '그와', '그는'과 같이 다양한 조사가 붙음. ⇒ 같은 단어임에도 서로 다른 조사가 붙어서 다른 단어로 인식 -
한국어는 띄어쓰기가 영어보다 잘 지켜지지 않음 ex. 띄어쓰기를안해도사람들은 이해/
형태소 단위의 토큰화가 필요
텍스트 정제 (Cleaning)
코퍼스 내에서 토큰화 작업에 방해가 되거나 의미가 없는 부분의 텍스트, 노이즈를 제거하는 작업
- 토큰화 전에 정제를 하기도 하지만, 이후에도 여전히 남아있는 노이즈들을 제거하기 위해 지속적으로 수행
- 노이즈는 특수 문자 같은 아무 의미도 갖지 않는 글자들을 의미하기도 하지만, 분석하고자 하는 목적에 맞지 않는 불필요한 단어들을 말함
- 대부분 정규표현식이나, 파이썬 내장함수를 통해 조작
- 주로 불용어, 특수문자 제거 / 대.소문자 통합 / 중복 문구 제거 / 다중 공백 통일 등으로 구성
불용어 (Stop Words)
- 분석에 큰 의미가 없는 단어로 코퍼스 내에 빈번하게 등장하나, 실질적으로 의미를 갖고 있지 않은 용어 • 전처리 시 불용어로 취급할 대상을 정의하는 작업이 필요
- NLTK에서는 여러 불용어를 사전에 정의

정규화 (Normalization)
Stemming (어간 추출)
- 어형이 변형된 단어로부터 접사 등을 제거하고 그 단어의 어간을 분리해내는 것
- 대표적으로 포터 스태머 알고리즘이 존재함

Lemmatization (표제어 추출)
- 품사 정보가 보존된 형태의 기본형으로 변환
- 표제어 추출에 가장 섬세한 방법은 => 형태학적 파싱
- 형태소란?: 의미를 가진 가장 작은 단위
- 어간(stem) : 단어의 의미를 담고 있는 단어의 핵심 부분
- 접사(affix) : 단어에 추가적인 의미를 주는 부분

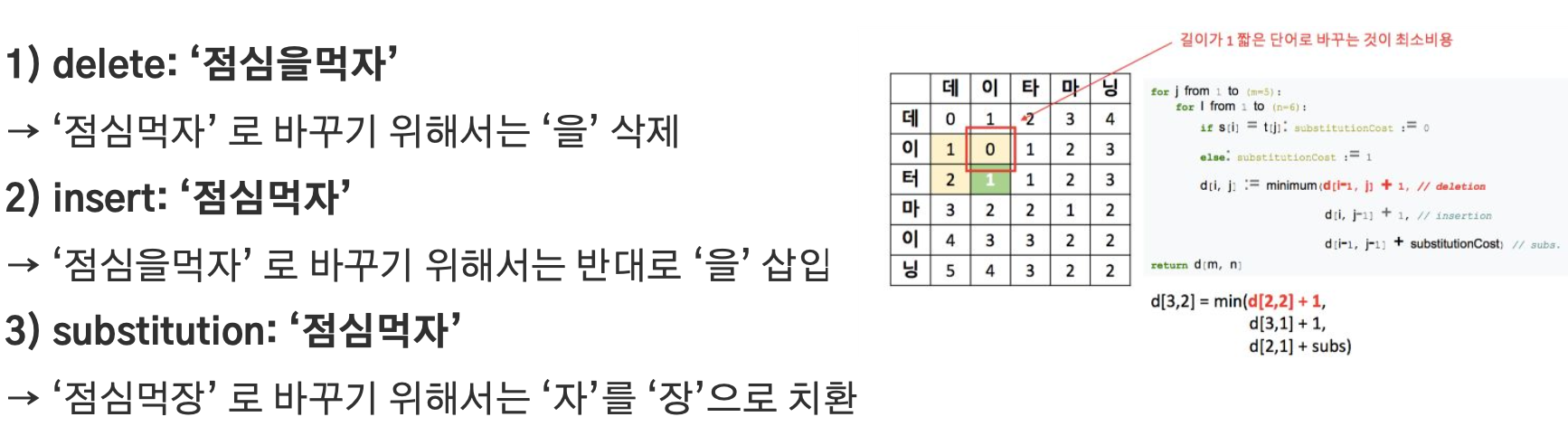
편집거리 (Edit distance)
Levenshtein distance
- 한 string s1 을 s2 로 변환하는 최소 횟수를 두 string 간의 거리. 거리가 낮을수록 유사한 문자열로 판단함
- s1 = ‘꿈을꾸는아이’ 에서 s2 = ‘아이오아이’ 로 바뀌기 위해서는 (꿈을꾸 -> 아이오) 로 바뀌고, 네번째 글자 ‘는’ 이 제거
- string 을 변화하기 위한 edit 방법을 세 가지로 분류
정규표현식(Regex)
- 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어
- 복잡한 문자열의 검색과 치환을 위해 사용되며, Python 뿐만 아니라 문자열을 처리하는 모든 곳에서 사용됨
- 원하는 규칙에 해당하는 문자만 남기거나 제거, 규칙에 맞는 문자열 반환 등 - 단 시간내에 텍스트가 갖는 모든 패턴의 형태를 처리
- 파이썬에서는 re 라이브러리를 이용해 사용이 가능함

