Boosting
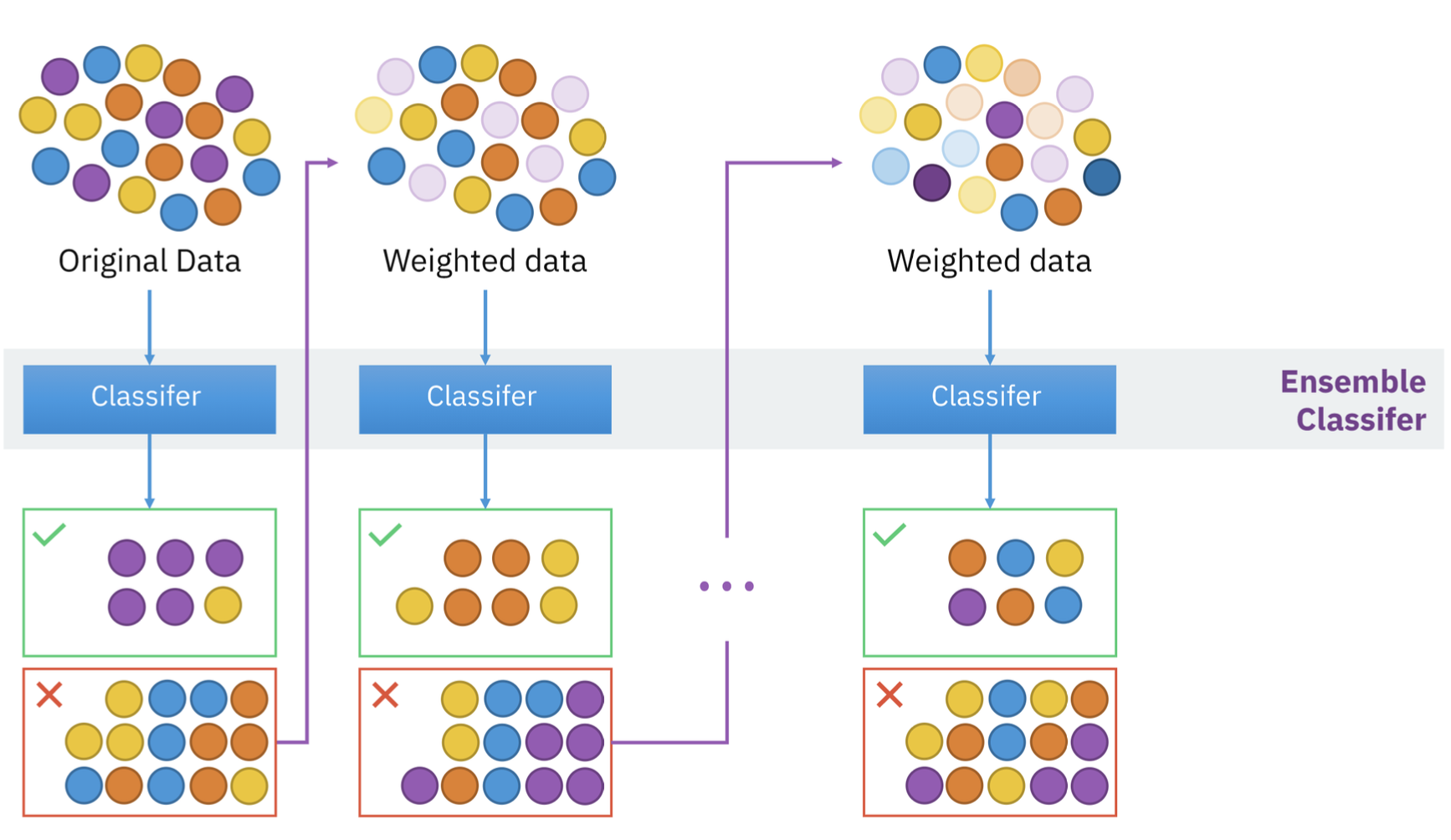
이진트리를 보완하는 방식으로 학습되는 앙상블 기법.(missclassified에 가중치 부여) + sequential(순차적 실행)
- Boosting 모델은 Bagging 방식이 만들어지는 원리가 전체 성능을 향상하는데 직접적인 연관이 없는 것을 보완한 모델(Bagging은 각 학습기가 독립적으로 훈련하고 예측결과 평균화)
- sequential model
- 첫 번째로 만든 DT가 잘못 분류한 친구들을 그 다음 DT가 보완하는 방식으로 순차적으로 Tree를 빌드함.
- 다음 DT는 그 이전에 DT가 잘못 분류한 데이터들에 weight를 주는 것으로 DT가 뽑을 데이터의 sampling을 조절함.
- gradient descent algorithm을 boosting model에 도입해서 다음 DT가 이전 DT와 합쳐져서 더 적은 loss를 가지게 되는 방향으로 DT를 만드는 방법을 Gradient boosting model.
다음은 캐글 1,2짱 introduction
XGBoost(XGB)

Definition
GBDT with System Optimization(하드웨어 최적화)
- Gradient Boosting model + System Optimization
- tree의 best split point를 찾을 때, feature를 정렬하느게 가장 큰 cost를 소모한다는 점을 확인하였음.
- 정렬하는 비용을 block단위로 잘라서 update하는 방식을 제안하여 GBM과 거의 유사한 성능을 내는 방식을 제안
- 훨씬 더 빠르게 정렬한 내용들을 사용할 수있게 시스템 최적화를 함.
- GPU Acceleration, Cache awarenessm I/O performance를 개선하여 훨씬 더 빠르게 학습이 가능한 방식을 제안함( c++로 구현)
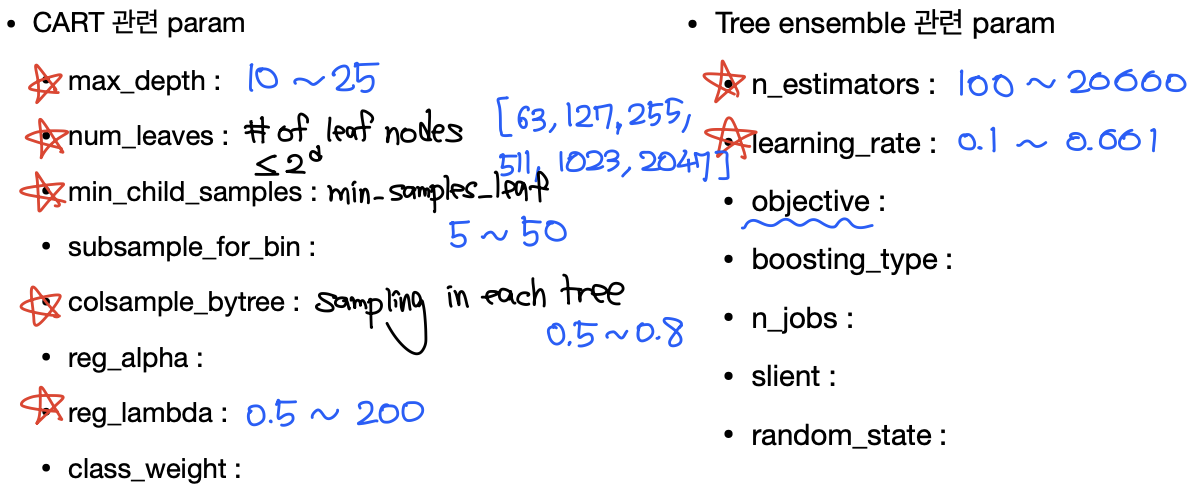
Hyper-patameter Tuning
물론 sklearn 기준

LightGBM(LGBM)
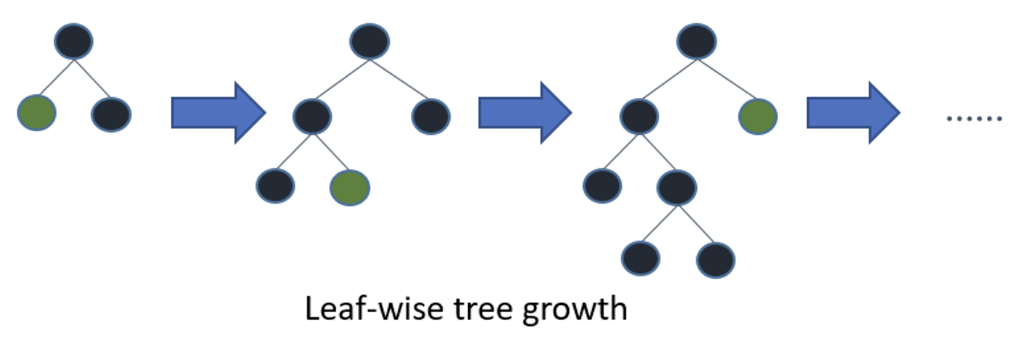
- Leaf wise를 사용한다면, 훨씬 더 빠르게 optimal을 찾을 수 있다는 것이 포인트
- 전체 Loss를 줄어드는 방향으로 node를 선정해서 split함. 이때 level을 유지하려는 경향을 포기
- 필요한 노드들만 split하면 되기 때문에, 기존 GBM들과 비교했을 때 훨씬 빠르게 학습이 가능하다는 장점
- 단, 적은 데이터를 사용하게 되면 overfitting이 될 가능성이 높아짐(10,000 rows 이상일 때만 사용 권장)
- 또, 다른 GBM들에 비해 하이퍼파라미터 sensitive 함(특히 max_depth에 가장 민감)
Hyper-patameter Tuning
물론 sklearn 기준
CatBoost(CAT)
- (역시나) kaggle 같은 실전 데이터 분석 대회에 서 가장 많이 사용하는 모델
- GBDT가 Categorical feature에 대해서 학습 이 잘되도록 설계되어 있음
- 오랜 연구로 default parameter 설계가 잘되 어있어, parameter tuning이 쉬움
- GPU 사용 최적화가 잘 되어있음
Hyper-patameter Tuning
물론 sklearn 기준


Real Cryptocurrency Trader & AI Engineer LV.0