01 Data-Centric AI란?
1.1 데이터의 중요성
AI 시스템을 이루는 두 가지 요소

양쪽 모두 개선 필요(데이터 품질이 좋을 땐: 모델 개선효과가 더 중요 <-> 데이터 품질 안좋을 땐: 데이터 개선이 더 중요)
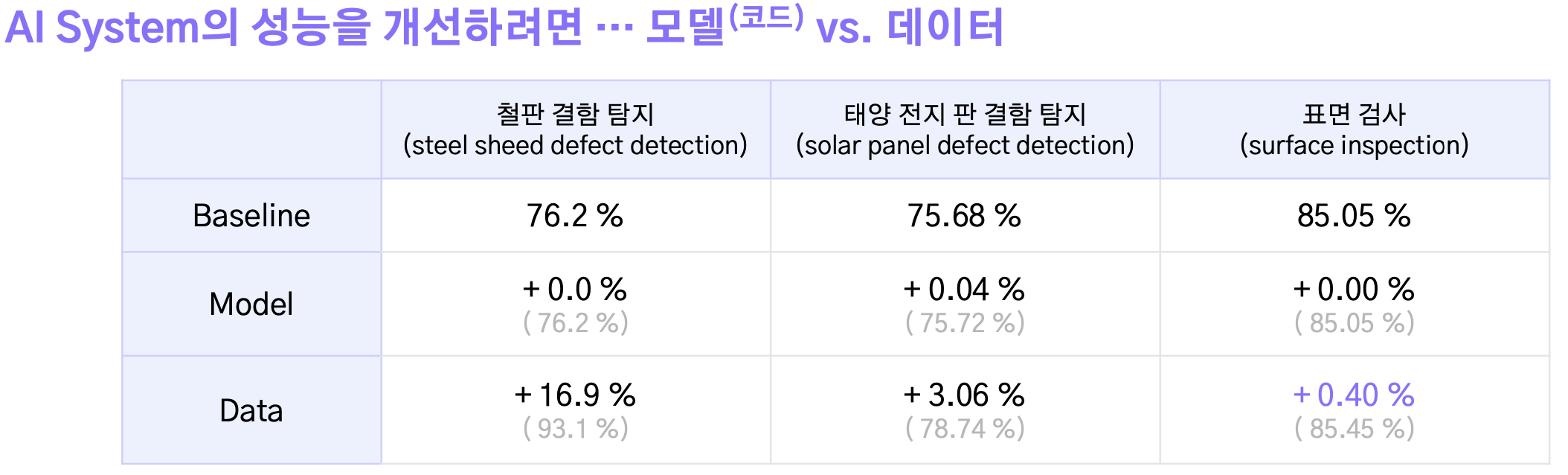
Why?
데이터는 곧 모델을 학습하는 데에 필요한 재료

But
동일한 데이터에 대해 서로 다른 어노테이션/라벨을 다는 경우가 발생 ⇒ 노이즈 발생
예시1) 철판 결함 예측 (39 classes) - Class 23 : Foreign particle defect

AI 프로젝트에서 데이터가 차지하는 비중
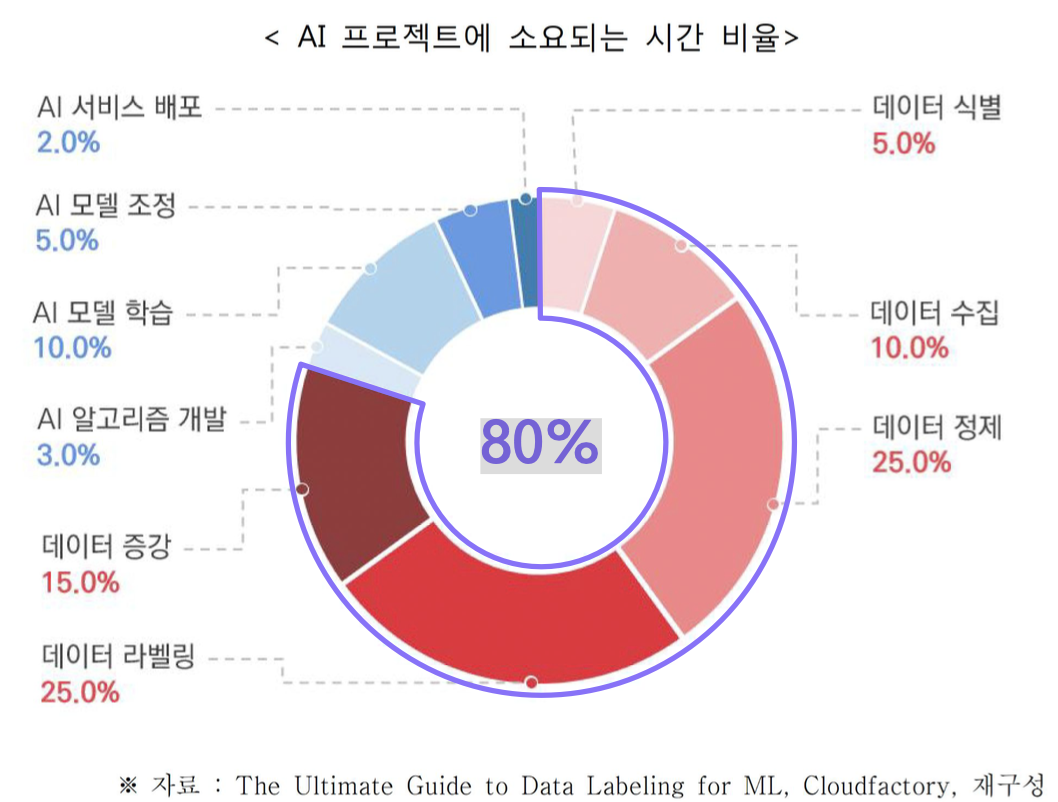
1.2 Data-Centric AI의 정의
Model-Centric AI
과거 그리고 지금도 여전히 가장 주로 사용되는 AI 접근 방식으로, 개발 및 운용의 관점에서 모델을 중심으로 접근하는 방식
Data-Centric AI
2020년대에 들어서 주목받기 시작한 AI 접근 방식으로, 개발 및 운용의 관점에서 데이터를 중심으로 접근하는 방식
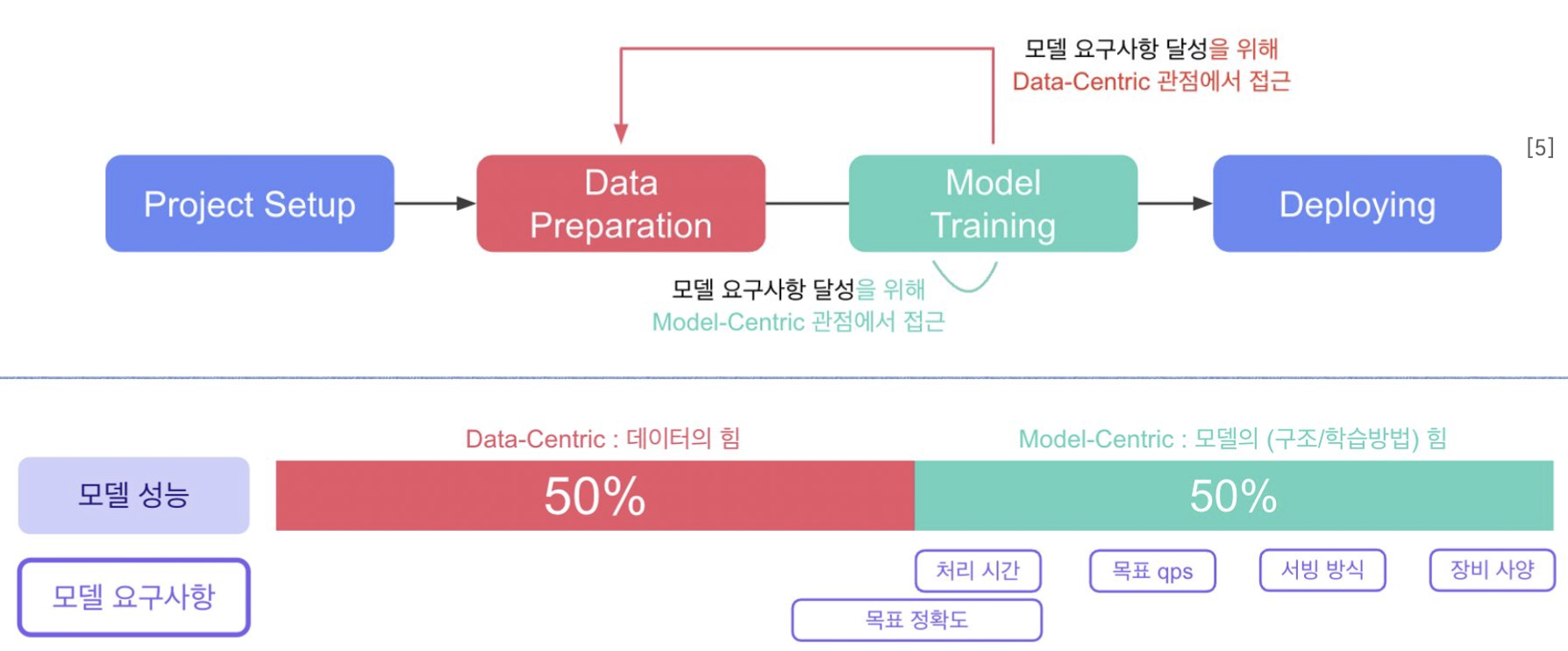
Model-Centric AI vs. Data-Centric AI
코드를 개선하면 Model-Centric AI, 데이터를 개선하면 Data-Centric AI라고 이해할 수 있음
- Model-Centric AI
- 최대한 많은 데이터를 확보한 뒤, 이러한 데이터의 노이즈에 대응할 수 있는 모델을 개발
- 데이터를 고정시킨 상태로 알고리즘/모델을 반복적으로 개선해나감
- Data-Centric AI
- 데이터의 통일성(consistency)를 위해 다양한 도구를 이용하여 체계적으로 데이터의 품질을 향상
- 코드를 고정시킨 상태로 데이터를 반복적으로 개선해나감
AI 서비스 개발 과정
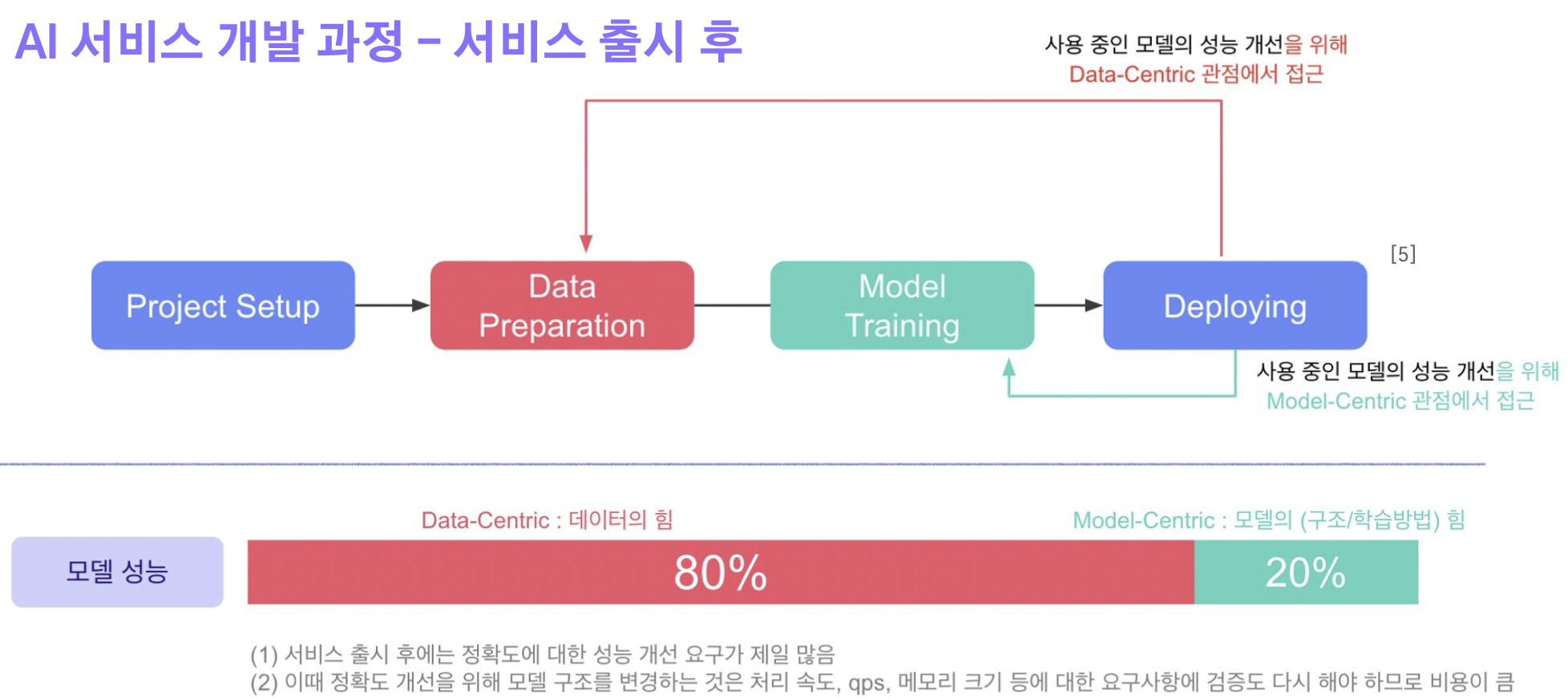
실제 서비스 개발 과정에서는 Data-Centric AI, Model-Centric AI 중 무엇이 더 중요할까
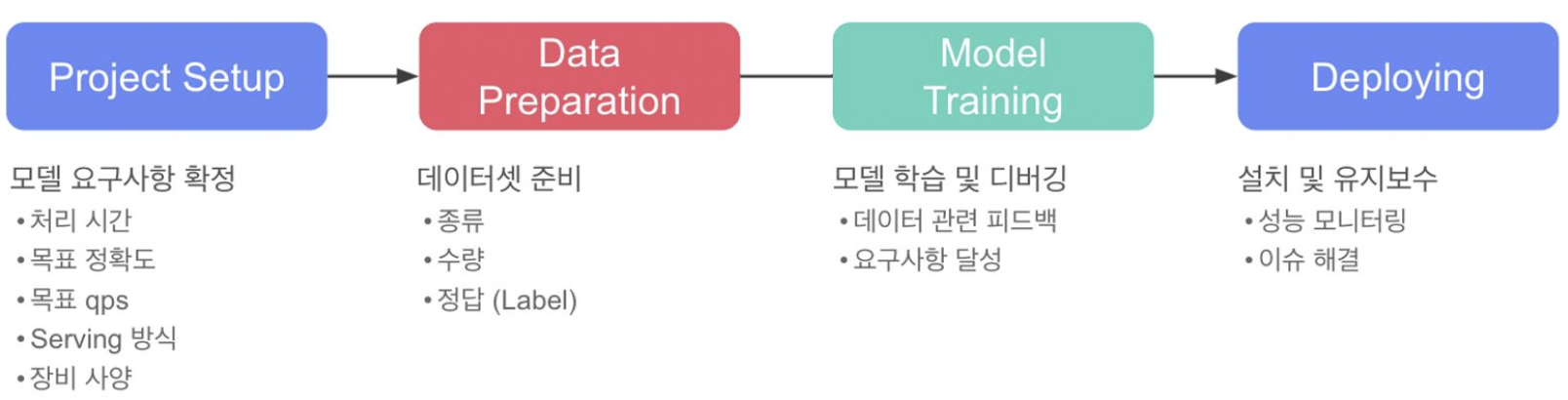
AI 서비스 개발 과정 - 서비스 출시 전
AI 서비스 개발 과정 - 서비스 출시 후
1.3 MLOps
MLOps (Machine Learning Operations) = ML + DevOps
머신러닝 모델을 안정적이고 효율적으로 배포하고 유지 관리하는 것을 목표로 하는 패러다임 + 데이터셋 구축을 위한 인프라를 만들어 데이터를 체계적이고 효율적으로 관리할 수 있는 시스템이기도 함
02 Data-Centric AI가 산업에 미친 영향
2.1 Pretraining & Fine-Tuning
트랜스포머 기반 언어 모델
- 트랜스포머의 인코더/디코더 구조를 이용한 언어 모델이 기존의 LSTM 계열을 압도하는 성능을 보이면서, 웬만한 언어 모델은 모두 트랜스포머 계열로 대체되고 NLP 분야의 연구가 활발히 이루어짐
거대 언어 모델 (Large Language Model, LLM)
- 여러 연구를 통해 트랜스포머 계열은 모델 파라미터가 많을수록 더 일반화된 좋은 성능을 가짐을 실증적으로 보임
- 그러나 이를 위해서 많은 데이터와 연산 자원이 필요하며, 일부 초거대 IT기업만이 이를 가능케 함
돌파구 찾기 ... 파인튜닝 (Fine-Tuning)
일반적인 기업, 개인, 연구자들은 이렇게 사전학습된 LLM을 자신의 태스크에 맞게 리폼하는 파인튜닝을 통해 언어 모델을 이용함
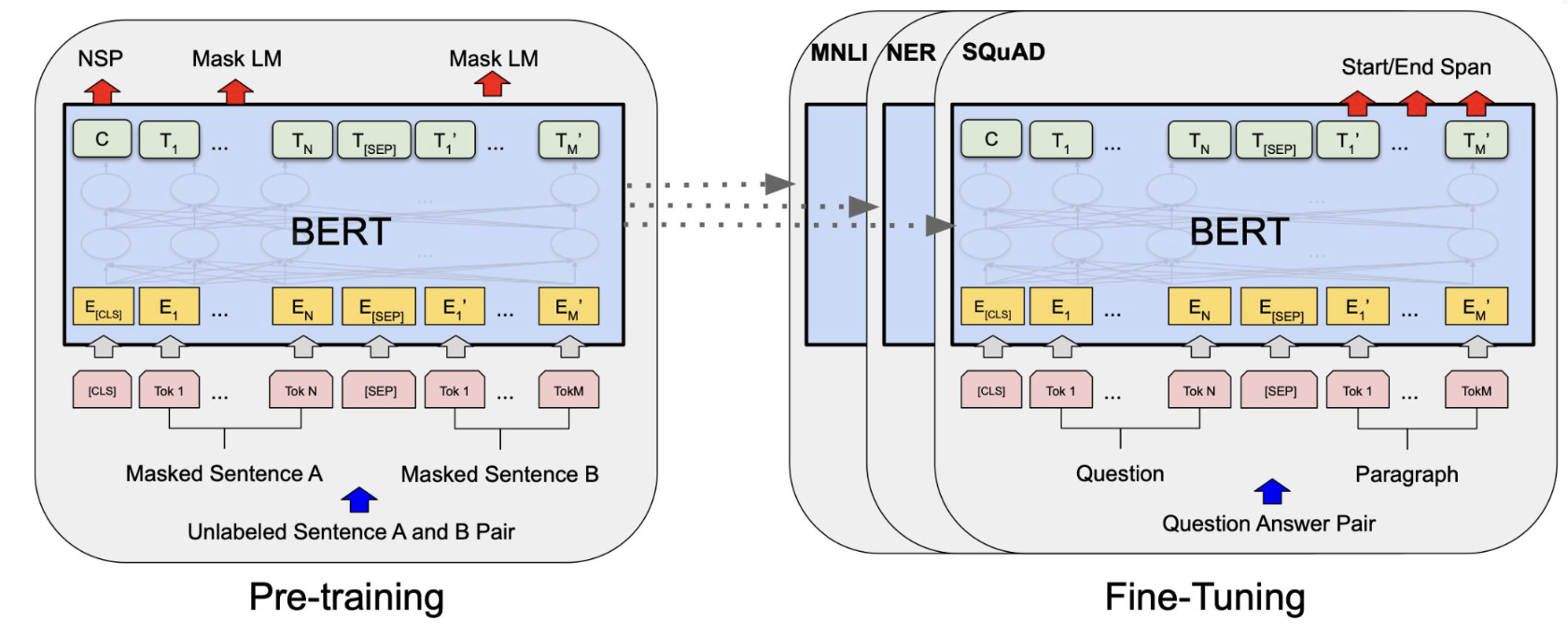
파인튜닝용 데이터의 확보
(사전학습 대비) 소량의 고품질 데이터만 확보하면 원하는 목적에 맞게 LLM을 파인튜닝할 수 있음
파인튜닝의 현주소 ... LoRA (Low-Rank Adaptation)
- 기존의 파인튜닝 기법
- 사전 학습 모델의 파라미터를 일부/전부 재학습하거나
추가적인 레이어를 붙인 뒤 이를 학습
- 사전 학습 모델의 파라미터를 일부/전부 재학습하거나
- LoRA (Low-Rank Adaptation)
- 사전 학습 모델을 완전히 고정(freeze)한 채로 낮은 랭크의 쿼리-값 어텐션 행렬을 추가하여 해당 어텐션 행렬만 학습
- 모델의 크기 및 필요한 데이터 양을 줄일 수 있음
2.2 Prompt Engineering
Prompt Engineering 관련 용어
- 프롬프트(Prompt) : 인공지능이 수행해야 할 작업을 설명하는 자연어 텍스트
- 모델과 최종 사용자 모두가 이해하기 쉽도록 간결하고 명확해야 함
- 지나치게 복잡한 언어를 사용하거나 불필요한 정보를 제공하면 부정확한 결과가 나올 수 있음
- 프롬프트 엔지니어링(Prompt Engineering)
: 생성 모델이 이해할 수 있는 형태로 프롬프트(텍스트)를 구조화하는 과정- text-to-text 및 text-to-image 모델에 주로 사용됨
- In-Context Learning
: 모델이 이전에 배운 정보나 컨텍스트를 활용하여 미래의 작업을 수행하거나 이해하는 것- 예) 이전 대화에서 나온 정보나 질문에 대한 답변을 기억하여 활용하는 것
GPT-3를 통해 알게 된 사실 1) 입력값에 지시문을 포함시키면 그에 맞는 결과를 준다
해결하고자 하는 태스크를 텍스트 형태로 입력값에 넣어주면 태스크의 정답에 해당하는 결과를 리턴함
ex) 1+1= 2인데 16854+ 4864=?
GPT-3를 통해 알게 된 사실 2) 지시가 구체적일수록 의도에 가까운 결과를 준다
모델에게 입력값을 구체적으로 지시할수록 더 정확한/의도에 맞는 결과물을 얻을 수 있음 ⇒ 프롬프트 엔지니어링
03 Data-Centric AI 관련 연구
3.1 Data-Centric AI 연구 사례
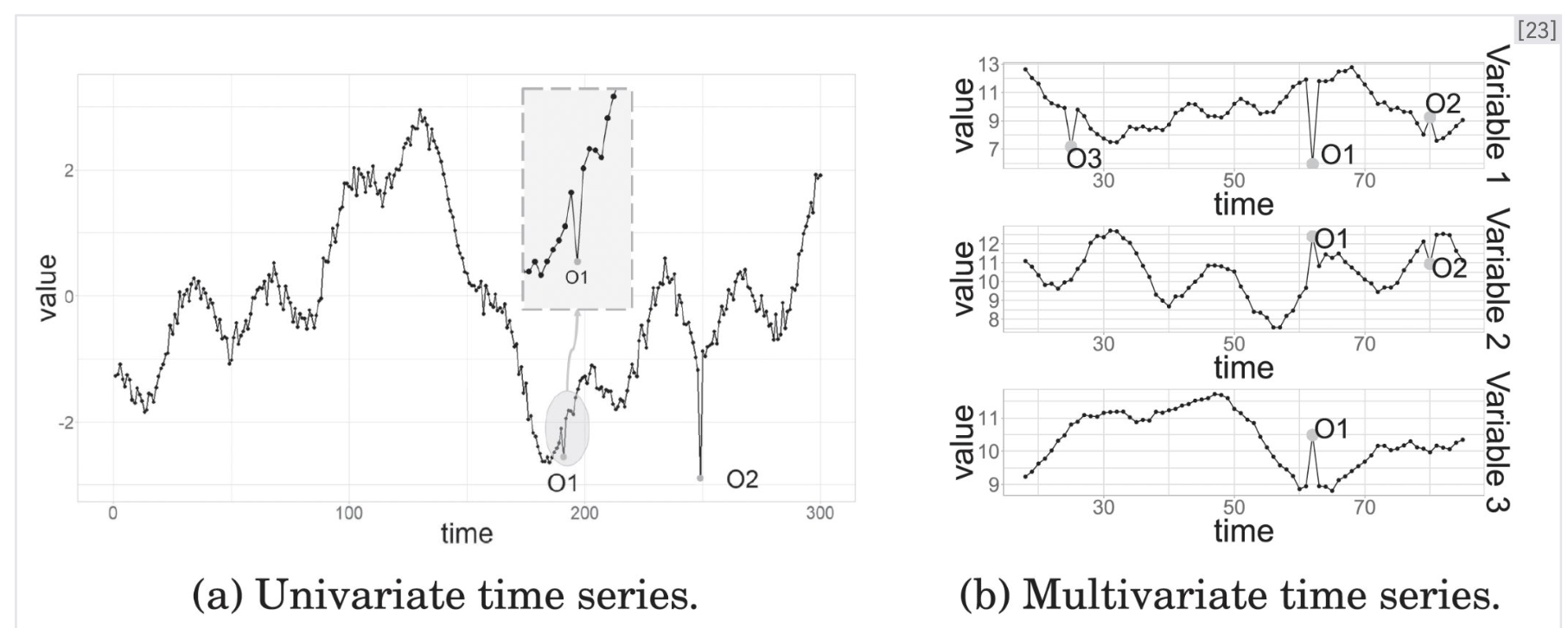
이상 탐지 및 제거 (Anomaly Detection & Removal)
일반적이지 않은(abnormal), 혹은 분포로부터 멀리 떨어진(outlier) 데이터 샘플을 탐지하여 제거하는 방법
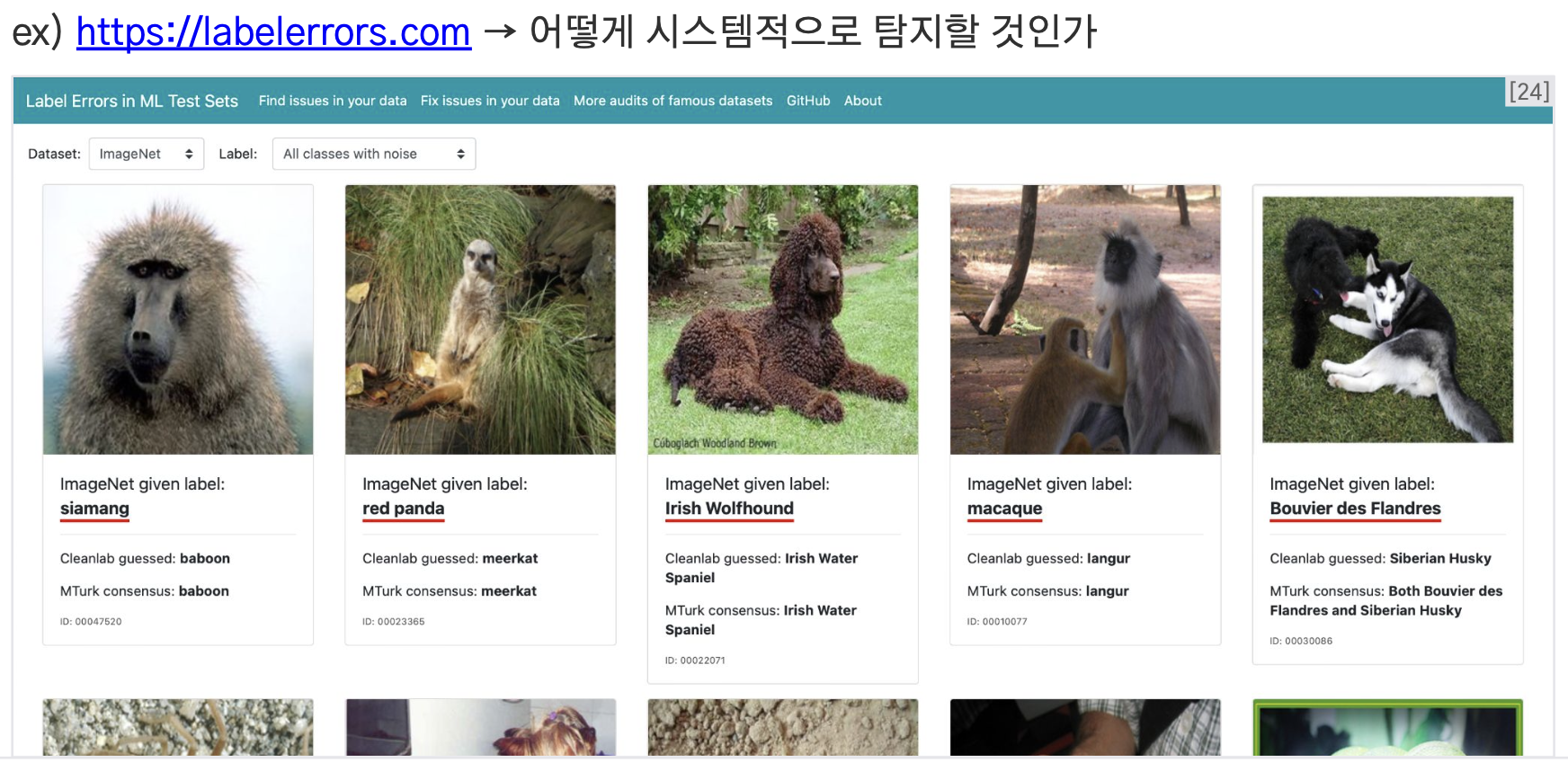
에러 탐지 및 수정 (Error Detection & Correction)
데이터 증강 (Data Augmentation)
기존 데이터를 변형하거나 확장하여 데이터 양을 늘리고, 이를 통해 모델의 성능을 향상시키는 방법
(rotate, crop, flip)

피쳐 엔지니어링 (Feature Engineering)
데이터가 가지고 있는 기존의 피쳐(feature)를 통해 유의미한 새로운 값을 만들어내는 방법
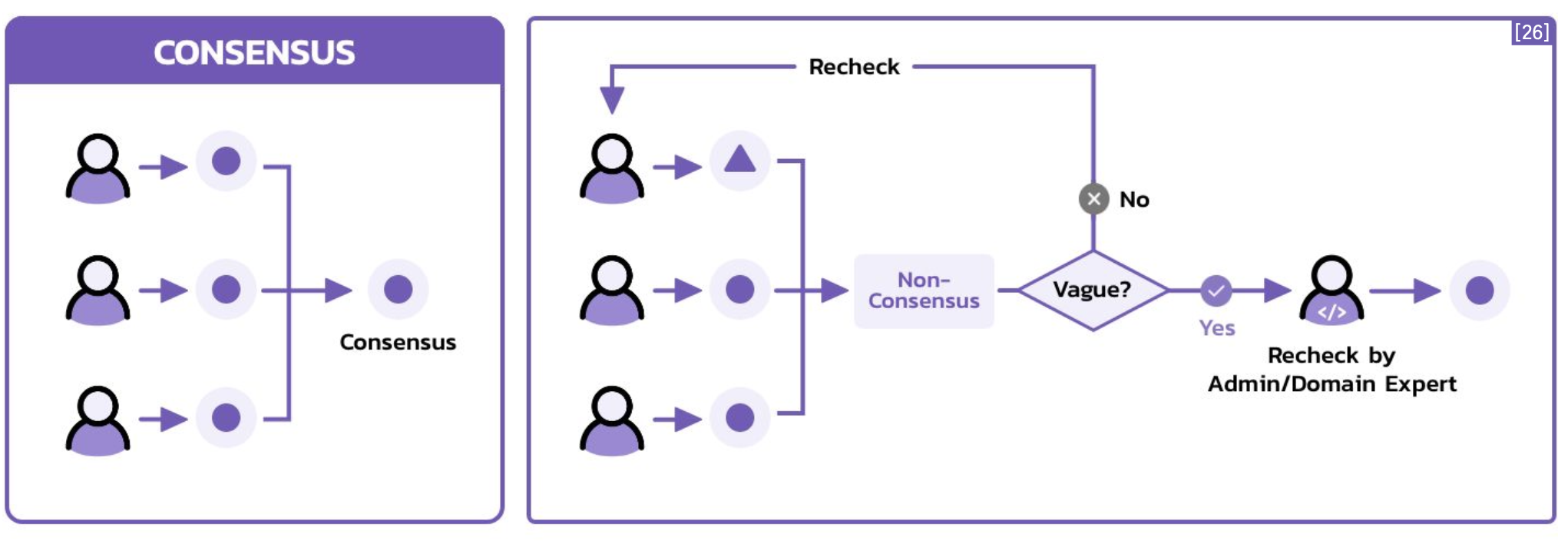
컨센서스 라벨링 (Consensus Labeling)
다수의 어노테이터 혹은 라벨러로부터 얻은 라벨들 중 합의된 라벨을 생성하는 작업 및 방법론
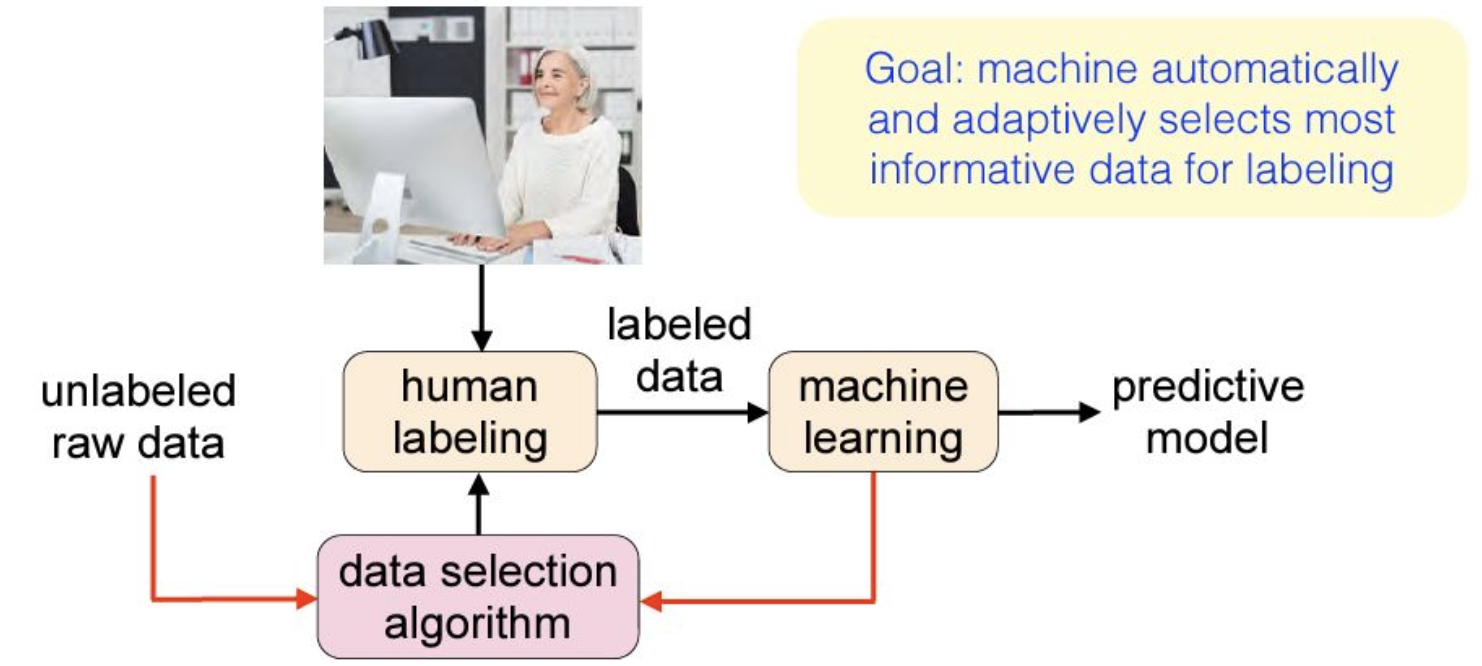
액티브 러닝 (Active Learning)
모델 학습 과정 중에 가장 질적으로 중요한 데이터 샘플을 점진적으로 선택, 또는 라벨을 요청하여 학습하는 방법
커리큘럼 러닝 (Curriculum Learning)
모델이 쉬운 데이터부터 차근차근 학습할 수 있도록 데이터의 학습 순서를 조정하는 방식
