[논문 리뷰] Self-Supervised Contrastive Pre-Training for Time Series via Time-Frequency Consistency
Paper Seminar
목록 보기
2/18
Motivation
- Time series data에 대한 일반화 가능한 Representation을 학습하는 것은 근본적으로 어려운 문제이다. 이러한 Representation을 생성함으로써 얻을 수 있는 많은 즉각적인 이점이 있으며, 그 중 Pre-train 기능이 특히 바람직하며 실질적으로 매우 중요하다. 그러나 Time series 분야에서 Dataset간에 공유되고 지식을 이전할 수 있는 속성에 대한 아이디어에 관한 문제가 있다. 이러한 문제를 완화하기 위해 Self-supervised learning이 해결책으로 떠오르고 있다.
- 이에 따라 본 논문에서는 Time-frequency Consistency을 모델링하는 전략을 소개한다. TF-C는 동일한 Time series sample에서 학습된 Time-based & Frequency-based representation이 서로 다른 Time series sample representation보다 Time-Frequency space에서 서로 더 가까워야 한다고 상정한다.
Contribution
- Time series의 Time-frequency Consistency를 탐구하기 위해 Frequency-based contrastive augmentation 기법을 개발한 첫번째 연구이다.
- 8개의 Dataset을 사용하여 8개의 Baseline과 비교 시, F1 score 기준 모든 Baseline을 능가하는 성능을 보인다.
Methodology
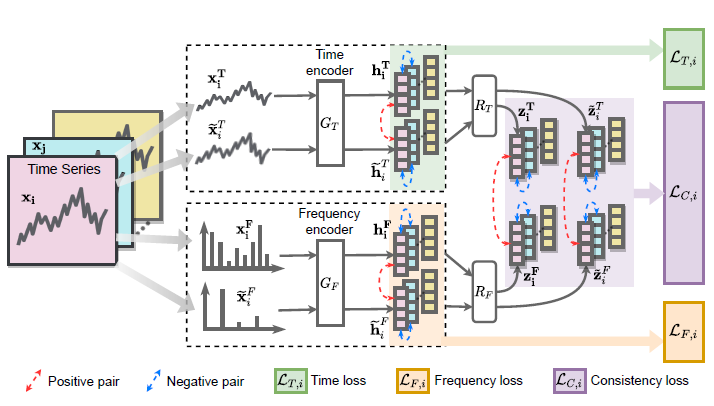
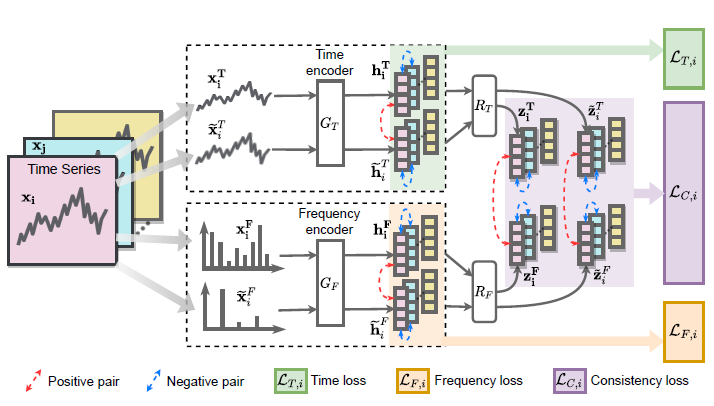
Time-based Contrastive Encoder
Backbone encoder
- Time & Frequency encoder 모두 동일한 구조
- 3개의 Convolutional block으로 구성
Data augmentation
- 모델이 Transformation-invariant representation을 학습하도록 한다.
- Jittering : Noise addition
- Scaling : Pattern-wise magnitude change
- Permutation : Rearranging slices
- 단일 유형의 Augmentation이 아닌 다양한 방식을 사용하여 복잡한 시간 역학에 모델을 노출시켜 보다 강력한 Time-based embedding을 생성한다.
Contrastive time loss
- Augmented data인 Positive pair에 대해서는 유사하도록, 다른 sample인 Negative pair에 대해서는 유사하지 않도록 학습하며, loss function으로는 NT-Xent loss를 사용한다.
NT-Xent loss - Normalized embedding과 적절한 Temperature를 적용한 Contrastive cross entropy loss
Frequency-based Contrastive Encoder
Data augmentation
- Fourier transformation을 사용하여 Ferequency spectrum을 도출한다.
- Budget E를 선택하여 E개의 component에 대해서 Augmentation을 수행한다.
Time-Frequency Consistency
Projector
- 각각의 Encoder에서 추출된 Embedding을 동일한 space로 mapping해주기 위해 Projector를 도입하였다. Projector를 통과한 Time-based & Frequency-based Embedding은 동일한 space인 Time-frequency space로 mapping된다.
Time-Frequency Consistency
- 서로 다른 Domain에서 생성된 Representation간의 Distance를 비교한다.
- Original data의 Time domain representation과 Frequency domain representaion간의 거리는 가깝게, Augmented된 Representation과는 멀게 학습한다.
Conclusions
- TF-C는 Time domain과 Frequency domain에서 각각 Augmentation을 통해 Positive pair를 생성하고, Contrastive learning을 수행한다.
- Frequency domain에서의 Augmentation 방법으로 Fourier component random remove 또는 진폭의 변화를 주는 방법을 사용하였다.
- Time domain에서의 Representation과 Frequency domain에서의 Representation이 Consistency를 갖도록 학습을 진행하였다는 특징이 있다.

Researcher