본 논문은 다양한 제약 조건이 존재하는 기존의 online test-time adaptation 한계점을 극복하기 위해 Laplacian Adjusted Maximum-likelihood Estimation (LAME) 목적 함수를 제안함. 이는 모델의 parameter를 변경하지 않고, 모델 출력만을 조정하며 concave-convex 절차를 통해 효율적으로 objective function을 최적화 함. 이로 인해 제안된 방법은 기존 방법들보다 다양한 시나리오에서 평균 정확도가 훨씬 높고 속도 면에서 훨씬 빠르며, 메모리 사용량도 현저히 적어지는 결과를 도출함
Introduction
-
GPT-3와 같은 대규모 Foundation model들을 다양한 상황에서 효율적으로 domain adaptation 기술이 중요하며, 이를 위해 Test-time에 새롭게 직면한 scenario에 적응하는 연구가 많이 진행되었음
-
실제 적용에서는 online으로 adaptation을 수행해야 하며, 제한된 양의 데이터로 이를 수행해야하기 때문에 아래와 같은 특성을 가져야 함
- Unsupervied 기반 방법론이어야 함
- Online operation이 가능하고, 잠재적으로 data에서도 작동해야 함
- Train data나 Train 절차에 대한 지식을 가지고 있지 않아야 함
- 특정 모델 구조에 맞춰서 설계되지 않아야 함
-
기존 연구들에서는 여러 시나리오에서 average accuracy를 최대화하는 hyperparameter를 선택하게 되면, adaptation을 사용하지 않는 비교 모델보다 성능이 뒤쳐지는 문제, 성능을 위해 Scenario 별로 hyperparameter를 조정해야하는 문제 등이 있으며, 사전 조건 없이 robust하게 작동할 수 있는 새로운 Adaptation 방법이 필요함
-
이를 위해 본 논문에서는 Pre-trained model의 parameter를 변경하는 대신, 출력만을 adaptation하여 데이터를 설명하는 Manifold-regularized likelihood를 최적화하는 latent assignments를 찾는 방식을 취함
On the Risks of Network adaptation
- Test time에 의 기저 분포를 더욱 잘 근사하기 위해, 기존의 TTA 방법들을 주로 매개변수화된 source model을 직접 수정하는 방법론을 제안함. 이러한 방법론을 본 논문에서는 Network adaptation methods (NAMs)라고 칭하며, 대표적인 방법론은 BN layer의 scale과 bias만을 adaptation하는 TENT와 모델의 convolution filter를 mutual information maximization을 통해 adaptation하는 SHOT가 있음
- 이러한 NAMs는 target sample을 활용하여 모델의 성능을 크게 향상시킬 잠재력을 가지고 있지만, 동시에 성능이 급격히 저하될 위험도 내포하고 있음. Target 분포의 좁은 영역에서 가중치를 연속적으로 업데이트하면 모델이 과도하게 특화될 수 있음. 이러한 현상은 특정 시나리오에서 하이퍼파라미터를 최적으로 선택하지 못한 경우와 Batch level에서 sample의 다양성이 부족한 경우의 조합으로 발생할 수 있음
- 아래 그림에서는 널리 사용되는 entropy minimization의 실패 사례를 보여줌. Batch 내의 다양성이 낮은 상황에서는 entropy minimization 방법이 모델을 점진적으로 손상시킬 수 있음을 보여줌
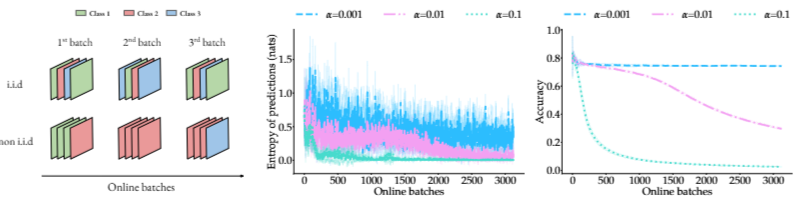
- 일부 연구에서는 최적의 hyperparameter를 선택하면 위의 문제를 해결할 수 있다고 주장함. 그러나, 각 target scenario에 대해 개별적으로 조정하기위해서는 label에 접근해야하며 어떤 scenario가 발생할지 미리 알아야한 다는 점에서 실제 적용이 어려움
LAME method
- 앞서 언급된 한계점을 극복하기 위해 본 논문에서는 네트워크 내부의 parameter를 수정하는 대신, 출력 확률을 보정하는 데에만 초점을 맞춘 방법론을 제안함. 이는 source classifier를 고정함으로써 Batch 간에 지식을 축적하는 것을 방지할 수 있음
- 또한, classifier의 성능 저하 위험을 완화하고 gradient를 계산하거나 저장할 필요가 없기 때문에 계산 요구량을 줄이며, learning rate나 Optimizer의 민감함 hyperparameter를 조정할 필요를 본질적으로 제거함
- Target 분포에서 샘플링된 데이터 batch가 주어졌다고 할 때, 각 데이터 포인트에 대한 latent vector를 찾는 것을 목표로 함. 해당 벡터는 조건부 분포를 근사하려고 하며, 모든 sample에 대해 Simplex 제약 조건을 만족하면서 데이터의 log-likelihood를 최대화하는 vector를 찾고자 함
위의 수식으로 인한 학습이 극단적으로 진행될 경우, 높은 에 아주 높은 를 one-hot vector 식으로 부여하는 문제가 발생할 수 있는데 이를 방지하기 위해 에 대한 entropy maximization loss를 추가로 사용함. 최종적인 loss는 아래와 같음
위 loss는 추가적인 modification이 있으며 아래와 같음
1. Target label의 를 구할 수 없기 때문에 source model prediction의 를 사용함
2. Laplacian regularization을 적용함
- Laplacian regularization은 비슷한 feature를 가진 sample이 비슷한 f를 갖도록 유도하는 역할을 함. 위의 modification이 반영된 최종 loss는 아래와 같음
Efficient optimization via a concave-convex procedure
- 제안 모델인 LAME은 모델의 parameter가 아니라 K-vector latent assignment 만을 학습하기 때문에 별도의 backpropagation없이 convex optimization을 통한 closed form으로 를 update할 수 있음
Experiments
Experimental design
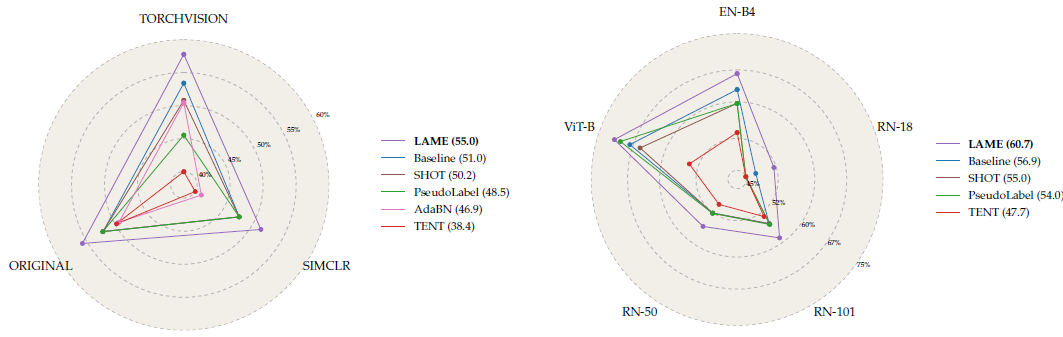
- 위 그림은 각 모델별로 hyperparameter에 대한 성능을 나타낸 것인데, ResNet-50 모델을 각각 방식으로 tuning한 뒤 다른 7개의 test scenario에 적용했을 때의 성능을 평균낸 것임. 실험 결과, LAME이 가장 좋은 성능을 보이며, Backbone 모델을 변경하더라도 가장 우수한 성능을 기록한 것을 볼 수 있음
Runtime per Batch
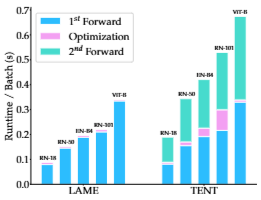
- 위 그림은 제안방법론인 LAME이 기존의 NAMs에서 주로 사용한 TENT 방법론보다 실행 속도가 훨씬 빠르다는 것을 보여주는데, 이는 모델 parameter가 아니라 laten assignment를 최적화하는 것이기 때문에 가능한 것임
Conclusion
- 본 논문은 새로운 모델을 훈련하는 데 드는 높은 비용을 고려하여 훈련 및 테스트 조건에 무관한 새로운 TTA 접근법을 제안함. 기존 TTA 접근법을 평가하면서 기존 방법들은 non-adaptive model보다 성능이 떨어지며, 심지어 치명적인 성능 저하를 초래할 수 도 있음을 확인함. 저자들은 이를 parameter over-adaptation을 주요 원인으로 지목하였고 model의 출력만을 보정하는 보수적인 접근법을 선택함
- 이에 따라 Laplacian Adjusted Maximum-likelihood Estimation (LAME)을 제안함. 이는 사전 학습된 모델의 예측에서 벗어나는 것을 억제하면서, 최적의 latent assignments를 찾는 것을 목표로 함
- 다양한 시나리오에서 비교한 결과, LAME은 모든 기존 방법과 non-adaptaive 모델을 능가하는 성능을 기록하였으며, 동시에 더 적은 계산 자원과 메모리를 요구함. 그러나, LAME은 standard i.i.d. 및 class-balanced 시나리오에서는 다른 방법론들 대비 뚜렷한 성능 향상을 보여주지 못하는 것이 한계점임
